
Adnan Kharrousheh
Data Mining and Optimisation Research Group (DMO), Center for Artificial Intelligence Technology, Universiti Kebangsaan Malaysia, Bangi 43650 Selangor, Malaysia
Salwani Abdullah
Data Mining and Optimisation Research Group (DMO), Center for Artificial Intelligence Technology, Universiti Kebangsaan Malaysia, Bangi 43650 Selangor, Malaysia
Mohd Zakree Ahmad Nazri
Data Mining and Optimisation Research Group (DMO), Center for Artificial Intelligence Technology, Universiti Kebangsaan Malaysia, Bangi 43650 Selangor, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 19 | Page No.: 3447-3453







ABSTRACT
Clustering is a data mining technique used to classify a number of objects into k clusters without advance knowledge such that the distance between objects within a same cluster and its center is minimised. The modelling for such problems is quite complex and searching for optimal solution usually impractical in term of computation times. Therefore, metaheuristic methods are used to find an acceptable solution within reasonable computational time. The problem addressed here provides the motivation for this work to develop a metaheuristic method to solve clustering problems. Most of previous techniques are based on K-means algorithm. However, K-means algorithm is highly depends on the initial state and very fast to get trap in local optimal solution. This work presents a modified tabu search approach to solve clustering problems that consists of two phases i.e., a constructive phase to generate an initial solution using K-means algorithm and an improvement phase, where a modified tabu search is employed with an aim to enhance the solution quality obtained from the first phase. In this study, a double tabu lists is introduced where the first tabu list is used to keep the neighbourhood structures and the second tabu list is used to keep the moves that are involved in that particular neighbourhood structure. The performance of the proposed algorithm is tested on five well-known datasets. Preliminary computational experiments are encouraging and compare positively with both the K-means and a standard tabu search alone.
PDF Abstract XML References Citation
Received: March 18, 2011;
Accepted: October 01, 2011;
Published: November 19, 2011
How to cite this article
Adnan Kharrousheh, Salwani Abdullah and Mohd Zakree Ahmad Nazri, 2011. A Modified Tabu Search Approach for the Clustering Problem. Journal of Applied Sciences, 11: 3447-3453.
DOI: 10.3923/jas.2011.3447.3453
URL: https://scialert.net/abstract/?doi=jas.2011.3447.3453
DOI: 10.3923/jas.2011.3447.3453
URL: https://scialert.net/abstract/?doi=jas.2011.3447.3453
INTRODUCTION
Clustering problem can be defined as the process to organise objects into a number of clusters, such that the objects in each cluster share a high degree of similarity, while being very dissimilar to objects in a different cluster. This problem is defined as NP-hard optimisation problems (Maroosi and Amiri, 2010).
The existing clustering algorithms can be simply classified into two types: hierarchical clustering and partitional clustering (Niknam and Amiri, 2010). Hierarchical clustering algorithms group objects into a sequence of partitions, either from singleton cluster to a cluster including all individuals or vice versa. Hierarchical procedures can be either agglomerative or divisive. Agglomerative algorithms begin with each object as a separate cluster and merge them in successively larger clusters. Divisive algorithms begin with the whole objects and proceed to divide it into successively smaller clusters (Niknam and Amiri, 2010).
This study concentrates on the partitional clustering, where objects are divided into several subsets. One the most popular class of partitional clustering methods is the center-based clustering algorithms (Gungor and Unler, 2007).
K-means clustering algorithm which is developed five decades ago is one of the most popular partitional clustering algorithm that is used in a variety of domains due to its simplicity and efficiency (Jain, 2010). However, the K-means algorithm highly depends on the initial state and easily to get trap into a local optimal solution (Selim and Ismail, 1984). Thus, in order to overcome this limitation, numerous of heuristic based algorithms have been introduced. For example, a Genetic Algorithm (GA) has been proposed by Maulik and Bandyopadhyay (2000) to solve the clustering problem and experiment on synthetic and real life datasets, where a basic mutation operator called a distance-based mutation is defined. Results showed that GA-based method improved the final output of K-means. Shelokar et al. (2004) introduced an Ant Colony Optimisation (ACO) algorithm to solve clustering problems. The algorithm employs distributed agents that mimic the real ants in finding a shortest path from their nest to the food source and back to the nest again. Fathian et al. (2007) proposed a Honey-Bee Mating Optimisation (HBMO) algorithm for the same problem. Gungor and Unler (2007) proposed a simulated annealing based K-harmonic means clustering algorithm to tackle clustering problems. This method is superior compared to K-means and the K-harmonic means algorithm alone in most of the tested cases. Liu et al. (2008) proposed a tabu search based clustering approach, called TS-Clustering that deals with the minimum sum of squares clustering problem. In the TS-Clustering algorithm, five improvement operations and three neighbourhood structures are employed. Kao et al. (2008) proposed a hybrid method that is based on the combination of K-means algorithm, nelder-mead simplex search and particle swarm optimisation (called K-NM-PSO) to cluster data vectors. Niknam et al. (2009) presented a hybrid evolutionary algorithm based on Particle Swarm Optimisation (PSO) and Simulated Annealing (SA) to find optimal cluster centers. Zhang et al. (2010) proposed an artificial bee colony algorithm for solving clustering problems which is inspired by the bees’ forage behaviour. The algorithm can be applied when the number of clusters is known in priori and are crisp in nature. Other examples of clustering approaches can be found by Ouadfel and Batouche (2007), Mahi and Izabatene (2011), Jaradat et al. (2009), Niknam et al. (2008), Abed and Zaoui (2011) and Shitong et al. (2006).
In this study, a modified tabu search approach is proposed to solve clustering problem. The main contribution of this paper is the presentation of two tabu list, where the first tabu list is used to keep the neighbourhood structures and the second tabu list is used to keep the moves that are involved in the selected neighbourhood structure.
CLUSTER ANALYSIS PROBLEM
Clustering is an unsupervised learning procedure in which there is no prior knowledge of data distribution (Liu, 2007). It is a process of recognizing natural groups or clusters in a multidimensional data based on some similarity measures. Distance measurement is commonly used for evaluating similarities between objects (Jain et al., 1999).
The most popular class of partitional clustering methods is based on the center clustering algorithms (Gungor and Unler, 2007). K-means algorithm is one of the most commonly used center based clustering algorithms (Forgy, 1965). To find “k” centers, the problem is defined as a minimisation of a performance function f (O, G). For this, a measure of adequacy for the partition must be defined. A popular function used to quantify the goodness of a partition is the total intra-cluster variance or the total mean-square quantization error (MSE) (Gungor and Unler, 2007):
| (1) |
The most used similarity metric in clustering procedure is a Euclidean distance which is derived from the Minkowski metric as in Eq. 1 and 2 Zhang et al. (2010):
| (2) |
In this study, we use a Euclidean metric as a distance metric. The standard K-means algorithm is summarized as follows (Kaufman and Rousseeuw, 2005):
| Step 1: | Randomly initialize the k cluster centroid vectors |
| Step 2: | Repeat |
| • | For each data vector, assign the vector to the cluster with the closest centroid vector, where the distance to the centroid is determined by Eq. 3: |
| (3) |
where, xp denotes the Pth data vector, Cj denotes the centroid vector of cluster j and d subscripts the number of features of each centroid vector.
| • | Recalculate the cluster centroid vectors, using Eq. 4: |
| (4) |
where, nj is the number of data vectors in cluster j and Cj is the subset of data vectors that form cluster j.
| Step 3: | If termination criterion is satisfied, then stop, otherwise continue with step 2 |
The process of K-means clustering algorithm stops when one of the following criteria is satisfied i.e., (1) if the maximum number of iterations has been exceeded; (2) if there is no change in the centroid vectors over a number of iterations; or (3) if there are no cluster membership changes. For the purpose of this research, the algorithm ends when a user-specified maximum number of iteration has been exceeded.
STANDARD TABU SEARCH
Tabu Search (TS) is a meta-heuristic method that is originally proposed by Glover (1986). TS has primarily been proposed and developed for combinatorial optimisation problems and has been proved to deal with various problems (Rego and Alidaee, 2005). The main feature of TS is the use of an adaptive memory and responsive exploration. Simple TS combines a local search procedure with anti-cycling memory-based rules to prevent the search from getting trapped in local optimal solutions. Specifically, TS avoids returning to recently visited solutions by constructing a list which is a called a Tabu List (TL). TS generates many trial solutions in a neighbourhood of the current solution and select the best one among all. The process of generating trial solutions is composed to avoid generating any trial solution that has already been visited recently. The best trial solution in the generated solutions will become a current solution. TS can accept downhill movements to avoid getting trapped in local optimal. TS can be terminated if the number of iterations without any improvement exceeds a predetermined maximum number of iteration.
Glover (1990), more details on the tabu search technique as well as a list of successful applications.
MODIFIED TABU SEARCH
Modified tabu search based on the standard tabu algorithm for clustering problems proposed by Al-Sultan (1995) was used. Some notations are introduced here before the explanation of the algorithm is stated.
Let A be an array of dimension n whose 1th element (Ai) is a number represents the cluster to which the 1th object is allocated. Obviously, given A, all (wij) are defined in the following manner:
| (5) |
for all i = 1, 2…., n and j = 1, 2…., k. For example, consider the following array (A) for n = 10, k = 3. Note that n is a number of data objects and k is a number of clusters.
The first data object is assigned to the second cluster (e.g., w11 = 0, w12 = 1, w13 = 0) and the second object is assigned to the third cluster (e.g., w21 = 0, w22 = 0, w23 = 1) and so on.
Given a set of all (wij), the center of each cluster (Cj) can be computed as the centroid of the data objects allocated to that cluster:
| (6) |
Given the array (A) and the centers (Cj), the objective function J (w, C) can be defined as:
| (7) |
Thus, it is clear that for the array A (solution), a specific value is the objective function which, for simplicity, is denoted by J. Let Ab, At and Ac denote the best, trial and current solutions and Jb, Jt and Jc denote the corresponding best, trial and current objective function values, respectively. The algorithm works with a current solution Ac and then by applying neighbourhood structures, we generate a trial solution At. The best solution found so far which is denoted by Ab will always be kept throughout the searching process. Two tabu lists are employed to prevent a cycle (get stuck with the same solution) throughout the search process.
CREATION OF THE NEIGHBOURHOOD STRUCTURES
Based on the literature review, there are several strategies for generation the trial solution. In this study, three different neighbourhood methods were used i.e.:
Swap method: Select an object randomly from one cluster and another object from another cluster and then swap between them. It is described as follows: Given a current solution Ac, select two objects randomly Ac(i) and Ac(j) which are not in same cluster, then assign Ac(i) to the cluster of Ac(j) belongs to and vice versa.
Single method: This is the simplest mode. One object is moved at each time from one cluster to another cluster. It is described as follows: Given a current solution Ac, select randomly Ac(i), assign X which defined as an integer randomly generated in the range [1, k], (k = number of clusters) and not equal to the cluster that of element Ac(i) belongs to. Then let Ac(i)= X.
Threshold method: The probability threshold mode is commonly used to establish the neighbouring (trial) solutions in the tabu search based on the clustering method (Al-Sultan, 1995; Liu et al., 2008). It moderates the shake-up on the current solution. The higher the value of the probability threshold, the less shake-up is allowed and therefore, the trial solutions more similar to the current one and vice versa. The probability threshold mode can be described as follows: Given a current solution Ac and a probability threshold P, for (I=1,..., n where n = number of objects), generate a random number R~u (0, 1). If R<P, then At(i) = Ac(i) i.e. no changes is made; otherwise randomly generate an integer (L) in the range [1, k] which is not equal to the cluster of element Ac (i), then let Ac (i) = L.
THE IMPLEMENTATION OF THE MODIFIED TS ALGORITHM
The pseudo code for the modified tabu search is presented in Fig. 1.
 | |
| Fig. 1: | Pseudo code of the modified tabu search |
| Step 1: | Initialisation: Set Ac as an initial solution obtained from K-means algorithm and Jc be the corresponding objective function value computed using Eq. 7. Then let Ab = Ac and Jb = Jc. Set values of the following parameters: NeiMeth (Neighbourhood method), MTLS (tabu list size), P (probability threshold), NTS (number of trial solutions) and let ITMAX be the maximum number of iterations which is set as a termination criterion. Let TLL (tabu list length) = 0 and go to Step 2 |
| Step 2: | Choose NeiMeth (Neighbourhood method): Select NeiMeth at random. If NeiMeth is tabu, repeat Step 2, otherwise go to Step 3 |
| Step 3: | Using Ac to generate a number of trial solutions At1, At2,..., AtNTS and evaluate their corresponding objective function values jt1, jt2, ..., jtNTS. Go to Step 4 |
| Step 4: | Order the quality of the solutions in an ascending order (jt1, jt2,..., jtNTS): If jt1 is not tabu, or if it is tabu but j1t < Jb, then let Ac = At1 and jc = jt1 and go to Step 4; otherwise let Ac = AtL, Jc = jtL, where jtL is the best objective function of [ jt2, jt3,..., jtNTS] that is not tabu and go to Step 4. If all the trial solutions are tabu, then go to Step 3 |
| Step 5: | Insert Ac at the bottom of the second tabu list (which keep the moves) and let TLL = TLL + 1 (if TLL = MTLS +1, delete the first element in the list and let TLL = TLL-1). If Jb>Jc, let Ab = Ac and Jb = Jc. If there is no improvement in the solution after a number of iteration (in this work we set to 5 which is based on our preliminary experiments), then insert the NeiMeth into the first tabu list (that keep the neighbourhood structures) and go to Step 2 |
| Step 6: | Check the termination criterion: If the termination criteria is satisfied, then stop (Ab is the best solution found and Jb is the corresponding best objective function value); otherwise, go to Step 2 |
EXPERIMENT STUDY
In this study, computer simulations are programmed in Java on an Intel CORE 2 Duo CPU 3.0 GHZ with 3 GB RAM.
In order to test the performance of our algorithm, five datasets are used as presented in section Test Problem. The results are evaluated and compared, respectively in term of the objective function, with K-means and standard tabu search algorithm alone.
TEST PROBLEM
We test our algorithm on five well-known datasets, i.e. (Iris, Wine, WBC, Glass, CMC) datasets that are available at the University of California at Irvine (UCI) Machine Learning Repository which cover low, medium and high dimensions (Blake and Merz, 1998). They have been considered by many researchers to study and evaluate the performance of their algorithms. These datasets can be described as follows (where n = number of objects, d = number of features, k = number of clusters):
Dataset 1: Iris data (n = 150, d = 4, k = 3). This is the iris dataset. These dataset has 150 random samples of iris flowers i.e. iris setosa, iris versicolor and iris virginica collected by Anderson (1935). From each species there are 50 observations for sepal length, sepal width, petal length and petal width in cm. This dataset was used by Fisher (1936) in his initiation of the linear-discriminant function technique (Niknam and Amiri, 2010).
Dataset 2: Wine data (n = 178, d = 13, k = 3). This is the wine dataset which is the result of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars. The analysis determined the quantities of 13 constituents found in each of the three types of wines. There are 178 instances with 13 numeric attributes in wine dataset. All attributes are continuous. There is no missing attribute value (Niknam and Amiri, 2010).
Dataset 3: Wisconsin Breast Cancer (WBC) (n = 683, d = 9, k = 2). This is the WBC dataset which consists of 683 objects characterised by nine features i.e., clump thickness, cell size uniformity, cell shape uniformity, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatic, normal nucleoli and mitoses. There are two categories in the data: malignant (444 objects) and benign (239 objects) (Niknam and Amiri, 2010).
Dataset 4: Ripley’s glass (n = 214, d = 9, k = 6). This is the Ripley’s glass dataset which consists of 214 objects and data were sampled from six different types of glass i.e. building windows float processed (70 objects), building windows non-float processed (76 objects), vehicle windows float processed (17 objects), containers (13 objects), tableware (9 objects) and headlamps (29 objects), each with nine features which are refractive index, sodium, magnesium, aluminium, silicon, potassium, calcium, barium and iron (Niknam and Amiri, 2010).
Dataset 5: Contraceptive Method Choice (CMC) (n = 1473, d = 10, k = 3). This is the CMC dataset which is a subset of the 1987 National Indonesia Contraceptive Prevalence Survey. The samples are married women who were either not pregnant or do not know if they were at the time of interview. The problem is to predict the current contraceptive method choice (no use, long-term methods, or short-term methods) of a woman based on her demographic and socioeconomic characteristics (Niknam and Amiri, 2010).
PARAMETER SETTINGS
The parameters used in this work are described as follows:
Tabu list size: In this study, a short term memory (tabu list) is used which keep track of a recent move for a certain number of iteration (tabu tenure) whereas the goal is to prevent cycling. The size of tabu list will control the exploration and exploitation stage. A large tabu list size allows more exploration or in other words, forcing new moves to be generated which take solution to far points. On the other hand, a small tabu list size increases the algorithm exploitation and therefore allows the algorithm to focus on current. Glover (1990) suggests using a tabu list size in the range [1/3 n, 3n], where n is related to the size of the problem.
We have two tabu lists in our algorithm: First one for the neighbourhood methods and three neighbourhood methods are adopted to improve the clustering solution obtained in the process of iterations. We considered the size of the first tabu to be 2 (which was based on our preliminary experiments). The second tabu list is used to keep the move. The size of the second tabu list is set to 20 as recommended by Liu et al. (2008).
Probability threshold (P): This parameter controls the shake-up that is performed on a certain solution to produce the trial solution (use in threshold neighbourhood method). If the value of P is high, that’s mean, less shake-up is allowed, consequently the trial solution is closer to the current solution and vice versa. In this work, P is set to 0.95 as recommended by Al-Sultan (1995).
Number of trial solution (NTS): This parameter controls the number of trial solutions to be generated from the current solution. Obviously, the higher the value of NTS is the better, because we have more choices to select from. However, this comes at the expense of more computational effort. In this work, NTS is considered to be 20, as recommended by Liu et al. (2008).
RESULTS AND DISCUSSION
To evaluate the performance of the modified tabu search approach, we compare the obtained results with K-means and standard tabu search algorithm (Maroosi and Amiri, 2010; Niknam and Amiri, 2010; Kao et al., 2008).
The sum of the intra-cluster distances, i.e. the distances between data vectors within a cluster and the centroid of this cluster, as defined in Eq. 1 is used to measure the quality of a clustering. Clearly, the smaller the sum of the distances is the higher the quality of clustering.
It is known that the effectiveness of the K-means algorithm and the tabu search algorithm are all dependent greatly on initial solutions (Maroosi and Amiri, 2010).
| Table 1: | The result among K-means, TS and Modified TS |
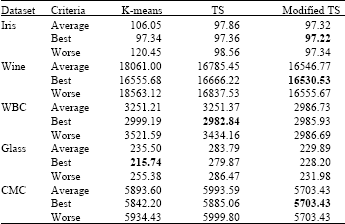 | |
| Bold values show best results | |
Therefore, for every dataset, those algorithms are performed 10 times individually for their own effectiveness tests. Each time with a new initial solution generated randomly from the dataset.
Table 1 summarizes the intra-cluster distances obtained from the three clustering algorithms. The values reported are given in terms of the averages of the sums of intra-cluster distances, the worse and the best solutions which can indicate the range of values that the algorithms span.
From the above results, we can see that the modified tabu search algorithm performs better than other compared algorithms in terms of intra-cluster distance. We are able to obtain three best results (denoted in bold) when compared to K-means and Tabu Search alone. That is the case i.e. on Glass dataset where K-means is better than our approach and Tabu Search algorithm outperforms our approach on WBC dataset. In all the tested datasets, our proposed approach can increase the solution in between 2.5 to 16.5% when compared against the K-means algorithm and in between 2.5 to 18.5% when compared against the Tabu Search algorithm. Its superiority is evident and can be considered as a viable and an efficient heuristic to find optimal or near optimal solutions to clustering problems of allocating n objects to k clusters. We believe that by proposing two tabu lists help the algorithm to better explore the search space (diversification), where non explored regions are tried to be visited and evenly explored. This helps to not easily revisit the same moves and neighbourhood methods in the process of obtaining better solutions.
CONCLUSION
The clustering problem is an important problem and has attracted much attention of many researchers. The K-means algorithm is a simple and efficient method that has been applied for clustering problem. However, it suffers from several drawbacks due to its choice of initialisations. This study developed the modified tabu search approach for solving the clustering problem, where two tabu lists are employed to keep neighbourhood method and the move. The algorithm has been implemented and tested on five well known real datasets. Preliminary computational experience is very encouraging in terms of the quality of solution found.
ACKNOWLEDGMENTS
We have learnt a great deal from those who have worked with us over the years and gratefully acknowledge our debt to them, especially Mr. Nasser R. Sabar for the care with which he reviewed and criticized the original manuscript. Support from the Universiti Kebangsaan Malaysia and Ministry of Higher Education Malaysia are gratefully acknowledged.
REFERENCES
- Maroosi, A. and B. Amiri, 2010. A new clustering algorithm based on hybrid global optimizationbased on a dynamical systems approach algorithm. Exp. Syst. Appl., 37: 5645-5652.
CrossRefDirect Link - Niknam, T. and B. Amiri, 2010. An efficient hybrid approach based on PSO, ACO and k-means for cluster analysis. Applied Soft Comput., 10: 183-197.
CrossRef - Gungor, Z. and A. Unler, 2007. K-harmonic means data clustering with simulated annealing heuristic. Applied Math. Comput., 184: 199-209.
CrossRef - Jain, A.K., 2010. Data clustering: 50 years beyond K-means. Pattern Recogn. Lett., 31: 651-666.
CrossRefDirect Link - Forgy, E., 1965. Cluster analysis of multivariate data: Efficiency vs. interpretability of classifications. Biometrics, 21: 768-780.
Direct Link - Selim, S.Z. and M.A. Ismail, 1984. Soft clustering of multidimensional data: A semi-fuzzy approach. Pattern Recognition, 17: 559-568.
CrossRef - Maulik, U. and S. Bandyopadhyay, 2000. Genetic algorithm-based clustering technique. Pattern Recogn., 33: 1455-1465.
CrossRefDirect Link - Shelokar, P.S., V.K. Jayaraman and B.D. Kulkarni, 2004. An ant colony approach for clustering. Anal. Chim. Acta, 509: 187-195.
CrossRef - Fathian, M., B. Amiri and A. Maroosi, 2007. Application of honey-bee mating optimization algorithm on clustering. Applied Math. Comput., 190: 1502-1513.
CrossRef - Liu, Y., Z. Yi, H. Wu, M. Ye and K. Chen, 2008. A tabu search approach for the minimum sum-of-squares clustering problem. Inform. Sci., 178: 2680-2704.
CrossRef - Kao, Y.T., E. Zahara and I.W. Kao, 2008. A hybridized approach to data clustering. Expert Syst. Applic., 34: 1754-1762.
CrossRefDirect Link - Niknam, T., B. Amiri, J. Olamaei and A. Arefi, 2009. An efficient hybrid evolutionary optimization algorithm based on PSO and SA for clustering. J. Zhejiang Univ.-Sci. A, 10: 512-519.
CrossRefDirect Link - Zhang, C., D. Ouyang and J. Ning, 2010. An artificial bee colony approach for clustering. Exp. Syst. Appl., 37: 4761-4767.
CrossRef - Jain, A.K., M.N. Murty and P.J. Flynn, 1999. Data clustering: A review. ACM Comput. Surv., 31: 264-323.
CrossRefDirect Link - Glover, F., 1986. Future paths for integer programming and links to artificial intelligence. Comput. Operat. Res., 13: 533-549.
CrossRef - Glover, F., 1990. Artificial intelligence, heuristic frameworks and tabu search. Managerial Decision Econ., 11: 365-375.
Direct Link - Al-Sultan, K., 1995. A tabu search approach to the clustering problem. Pattern Recognition, 28: 1443-1451.
CrossRef - Blake, C.L. and C.J. Merz, 1998. UCI Repository of Machine Learning Databases. 1st Edn., University of California, Irvine, CA.
Direct Link - Ouadfel, S. and M. Batouche, 2007. AntClust: An ant algorithm for swarm-based image clustering. Inform. Technol. J., 6: 196-201.
CrossRefDirect Link - Mahi, H. and H.F. Izabatene, 2011. Segmentation of satellite imagery using RBF neural network and genetic algorithm. Asian J. Applied Sci., 4: 186-194.
CrossRefDirect Link - Jaradat, A., R. Salleh and A. Abid, 2009. Imitating K-means to enhance data selection. J. Applied Sci., 9: 3569-3574.
CrossRefDirect Link - Niknam, T., J. Olamaei and B. Amiri, 2008. A hybrid evolutionary algorithm based on ACO and SA for cluster analysis. J. Applied Sci., 8: 2695-2702.
CrossRefDirect Link - Abed, H. and L. Zaoui, 2011. Partitioning an image database by K_means algorithm. J. Applied Sci., 11: 16-25.
CrossRefDirect Link - Shitong, W., F.L. Chung, G. Wei and H. Bin, 2006. Visual sampling based clustering algorithm VSC. Inform. Technol. J., 5: 779-791.
CrossRefDirect Link - Fisher, R.A., 1936. The use of multiple measurements in taxonomic problems. Ann. Eugen., 7: 179-188.
CrossRefDirect Link