
Satish Kumar
Department of Mathematics, Geeta Institute of Management and Technology, Kanipla-136131, Kurukshetra, Haryana, India
Arun Choudhary
Department of Mathematics, Geeta Institute of Management and Technology, Kanipla-136131, Kurukshetra, Haryana, India
Trends in Applied Sciences Research
Year: 2012 | Volume: 7 | Issue: 5 | Page No.: 350-369







ABSTRACT
In the present communication, a new generalized parametric R-norm information measure has been defined and its properties, as well as an axiomatic characterization, are given. The measure is extended to conditional and joint measures.
PDF Abstract XML References Citation
Received: November 03, 2011;
Accepted: February 14, 2012;
Published: March 27, 2012
How to cite this article
Satish Kumar and Arun Choudhary, 2012. Generalized Parametric R-norm Information Measure. Trends in Applied Sciences Research, 7: 350-369.
URL: https://scialert.net/abstract/?doi=tasr.2012.350.369
URL: https://scialert.net/abstract/?doi=tasr.2012.350.369
INTRODUCTION
Let us consider the set of positive real numbers, not equal to 1 and denote this by R+ defined as R+ = {R:R>0, R≠1}. Let Δn with n≥2 be a set of all probability distributions:
Boekee and van der Lubbe (1980) studied R-norm information of the distribution P defined for R∈R+ by:
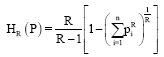 | (1) |
Actually, the R-norm information measure (1) is a real function from Δn→R+ defined on Δn, where n≥2. This measure is different from the entropies of Shannon (1948), Renyi (1961), Havrda and Charvat (1967) and Daroczy (1970). The most interesting property of this measure is that when R→1, R-norm information measure approaches to Shannon’s entropy (Shannon, 1948) and in case R→∞, HR(P)→(1-max pi), i = 1, 2,..., n. The measure (1) can be generalized in so many ways.
Setting r = 1/R in (1), we get:
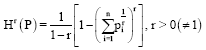 | (2) |
which is a measure mentioned by Arimoto (1971) as an example of a generalized class of information measure. It may be marked that (2) also approaches to Shannon’s entropy (Shannon, 1948), as r→1.
The mathematical theory of information is usually interested in measuring quantities related to the concept of information. Shannon (1948) fundamental concept of entropy has been used in different directions by the different authors such as Stepak (2005), Al-Daoud (2007), Haouas et al. (2008), Rupsys and Petrauskas (2009), Yan and Zheng (2009), Al-Nasser et al. (2010), Kumar and Choudhary (2011a-c) and Wang (2011) etc.
Thus (1) measure can be generalized further parametrically in so many ways and consequently, we consider the following generalized parametric R-norm information measure:
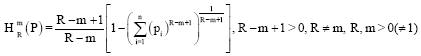 | (3) |
In the present study, we characterize a non-additive generalized R-norm information measure (3) by applying the infimum operation.
CHARACTERIZATION BY APPLYING INFIMUM OPERATION
We can consider the generalized R-norm entropy (3) as weighted arithmetic mean representation of elementary R-norm entropies of type R and degree m of occurrences of various single outcomes.
Theorem 1: Let:
| (4) |
then:
| (5) |
where, the operation infimum is taken over the probability distribution (*p1, *p2,..., *pn)∈Δn
Proof: Let us consider:
| (6) |
we minimize Eq. 6 subject to natural constraint:
| (7) |
For this we consider Lagrangian:
Differentiating with respect to *pi, we have:
| (8) |
For extremum value we put ∂L/∂(*pi) = 0 which gives:
| (9) |
We see that ∂2L/∂(*pi)2>0, when *pi = λ-(R-m+1). (pi)R-m+1. Hence the value of *pi given by Eq. 9 is minimum and using Eq. 7 in 9, we can find the value of λ and consequently, we have:
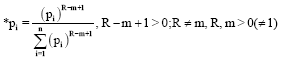 | (10) |
Now we consider R.H.S. of Eq. 5:
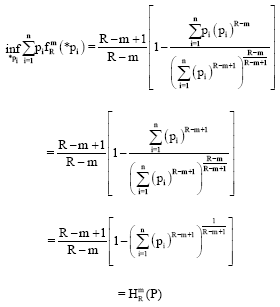 | (11) |
Further without any loss of generality, we may assume that corresponding to the observed probability distribution P∈Δn, there is a prior probability distribution Q∈Δn and replacing ![]() (*pi) by
(*pi) by ![]() (qi) in Eq. 5, we have:
(qi) in Eq. 5, we have:
| (12) |
In case we do not apply the operation of infimum to Eq. 12, then it depends on two probability distributions P and Q. For m = 1, ![]() (qi) is analogous to:
(qi) is analogous to:
which, reduces to log1/qi in case R→1.
Thus (12) becomes:
| (13) |
which, is a generalized inaccuracy measure of degree R characterized by Sharma and Taneja (1975). Therefore, we can represent Eq. 5 via ![]() (qi).
(qi).
Hence:
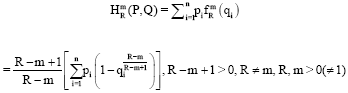 | (14) |
Actually, Eq. 14 can also be described as the average of elementary R-norm inaccuracies ![]() (qi), i = 1, 2,..., n and so can be called as R-normed inaccuracy measure of type m and R. Thus it seems plausible that Eq. 14 may be characterized and then by taking its infimum we can arrive at Eq. 5.
(qi), i = 1, 2,..., n and so can be called as R-normed inaccuracy measure of type m and R. Thus it seems plausible that Eq. 14 may be characterized and then by taking its infimum we can arrive at Eq. 5.
In the next theorem we characterize the elementary information function ![]() (qi) by assuming only two axioms and applying infimum operation.
(qi) by assuming only two axioms and applying infimum operation.
Theorem 2: Let f be a real valued continuous self-information function defined on (0, 1] satisfying the following axioms:
Axiom 1:
Axiom 2:
and n = 2, 3,... is a maximality constant. If ![]() (*pi) is replaced by
(*pi) is replaced by ![]() (qi) in Eq. 11, the result holds.
(qi) in Eq. 11, the result holds.
Proof: By taking:
in axiom 1, we get:
or:
| (15) |
The relation in Eq. 15 is well known Cauchy’s functional equation (Aczel, 1966). The continuous solution of Eq. 15 is φ(x) = xa where a ≠0 is an arbitrary constant. On using axiom 2, we get a = R-m/R-m+1 and hence:
which is exactly of the form of Eq. 4. Next the measure Eq. 5 can be easily obtained by applying the operation infimum on the Eq. (14) on the lines of theorem 1.
Remarks: For an incomplete probability distribution scheme:
associated with individual events may be worked out. Then as in case of Eq. 14, we may define:
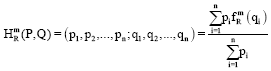 | (16) |
By using the operation infimum with respect to qi’s the Eq. 16 gives:
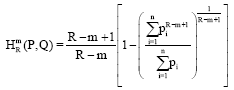 | (17) |
which is the R-norm entropy of type m for incomplete probability distribution. It is also worth mentioning that if we take arithmetic average with weights as continuous function w(.), then we get the general expression:
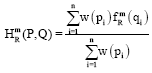 | (18) |
By considering different weight w(.) satisfying the condition w(pq) = w(p) w(q), where w(.)≠0, we can obtain various generalized R-normed entropies by using the operation infimum with respect to qi’s.
In next section we characterize the generalized measure of inaccuracy Eq. 14 for two distribution p and q∈Δn through functional equation.
AXIOMATIC CHARACTERIZATION
Let Sn = ΔnxΔn→R+, n = 2, 3,... and Gn be a sequence of functions of pi’s and qi’s, i = 1, 2, ..., n over Sn satisfying the following axioms:
Axiom 3:
where, a1 and a2 are non-zero constants and p, q∈J = (0,1)x(0,1){(0,y); 0≤y≤1} {(1, y1); 0≤y1≤1}. This axiom is also called sum property.
Axiom 4: For P,Q∈Δn and P’, Q’∈Δm, Gn satisfies the following property:
Axiom 5: h(p,q) is a continuous function of its arguments p and q.
Axiom 6: Let all pi’s and qi’s are equiprobable posterior and perior probabilities of events respectively, then:
where, n = 2, 3,... , R-m+1>0, R,m>0 (≠1), R≠m.
First of all we prove the following three lemmas to facilitate to prove the main theorem:
Lemma 1: From axioms 3 and 4, it is very easy to arrive at the following functional equation:
| (19) |
where, (pi,qi),(p’j,q’j)∈J for i = 1, 2,...,n and j = 1, 2,...,m.
Lemma 2: The continuous solution that satisfies Eq. 19 is the continuous solution of the functional equation:
| (20) |
Proof: Let a, b, c, d and a’, b’, c’, d’ be positive integers such that 1≤a’≤a, 1≤b’≤b, 1≤c’≤c, 1≤d’≤d:
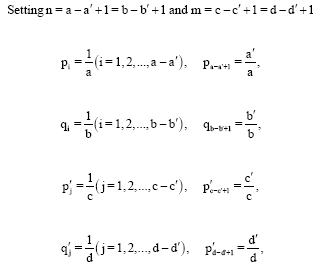 |
From Eq. 19 we have:
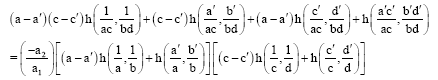 | (21) |
Taking a’ = b’ = c’ = d’ = 1 in Eq. 21, we get:
| (22) |
Taking a’ = b’ = 1 in Eq. 21 and using Eq. 22, we get:
| (23) |
Again taking c’ = d’ = 1 in Eq. 21 and using Eq. 22, we get:
| (24) |
Now Eq. 21 together with Eq. 22, 23 and 24 reduces to:
| (25) |
Putting:
in Eq. 25, we get the required results (20) for rational numbers which by continuity of h holds for all real p, q, p’, q’∈J.
Next we obtain the most general solution of Eq. 20.
Lemma 3: The most general continuous solution of Eq. 20 are given by:
| (26) |
and:
| (27) |
Proof: Taking g(p, g) in Eq. 20, we have:
| (28) |
The most general continuous solution of 28 (Aczel, 1966) is given by:
| (29) |
and:
| (30) |
On substituting: g(p, q) = (-a2/a1) h(p, q) in Eq. 29 and 30, we get Eq. 26 and 27, respectively. This proves the lemma 3.
Theorem 3: The inaccuracy measure Eq. 14 is uniquely determined by the axioms 3 to 6.
Proof: Substituting the solution Eq. 26 in axiom 3 we have:
| (31) |
Using axiom 6 in Eq. 31, we get:
| (32) |
From Eq. 31 we have:
| (33) |
It implies:
or:
Now from Eq. 31 we have:
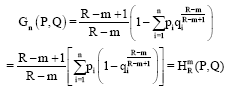 |
Hence, this completes the proof of the theorem 3.
Remarks: In the Eq. 26 if μ = 0 and v =0 then:
which, is a trivial solution and is of no interest. The solution 27 does not even contain any variable and hence it is to be discarded.
PROPERTIES OF ![]() (P)
(P)
This section presents the algebraic and analytical properties of the R-norm information measure ![]() (P) and satisfies the following properties:
(P) and satisfies the following properties:
(1) | |
| (2) | |
| (3) | |
| (4) | |
| (5) |
Proof: Properties 1 to 3 can be verified easily, now we consider 4:
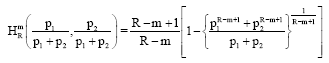 | (34) |
and:
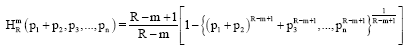 | (35) |
By combining Eq. 34 and 35, we have:
Thus ![]() (p1, p2,...pn) is non-recursive.
(p1, p2,...pn) is non-recursive.
Property 5: Let A1,A2,...,An and B1,B2,...,Bm be the two sets of events associated with probability distributions P∈Δn and Q∈Δm. We denote the probability of the joint occurrence of events Ai = (i = 1, 2,..., n) and Bj = (j = 1, 2,..., m) on P(Ai∩Bj)
Then the R-norm entropy is given by:
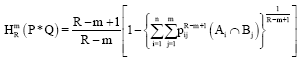 |
Since the events considered here are stochastically independent therefore, we have:
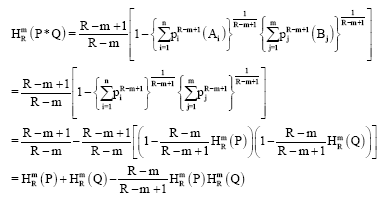 | (36) |
Corollary: The property 5, can also be extended for m stochastically independent distributors P0, P1,..., Pm-1 having n0, n1,..., nm-1 elements respectively. Let ![]() (P0) =
(P0) = ![]() (P1) = ... =
(P1) = ... = ![]() (Pm-1) Then:
(Pm-1) Then:
| (37) |
where, p* stands for the product space of m stochastically independent distributor P0, P1,..., Pm-1.
Proof: In Eq. 36, we have proved the results for product of two probability distributors on similar lines, it is very easy to show that:
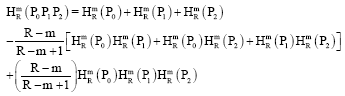 |
Further, by Mathematical Induction, we arrive at:
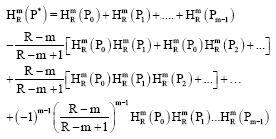 | (38) |
Setting ![]() (p0) =...=
(p0) =...=![]() (pm-1) = w, we have:
(pm-1) = w, we have:
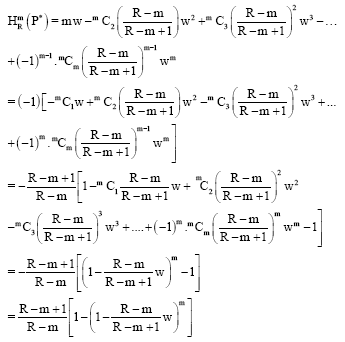 |
which is 37.
This completes the proof of the property 5.
Theorem 4: Let ![]() (P) =
(P) =![]() (p1,, p2,..., pn) be the generalized R-norm information measure. Then for P∈Δn and R∈R+ and m>0 (≠1), we have:
(p1,, p2,..., pn) be the generalized R-norm information measure. Then for P∈Δn and R∈R+ and m>0 (≠1), we have:
| (a) | |
| (b) | |
| (c) | |
| (d) | |
| (e) | |
| (f) | |
| (g) | |
| (h) | |
| (i) |
Proof: To prove that ![]() (P) is non-negative, we consider the following cases:
(P) is non-negative, we consider the following cases:
Case I: When R>m or R-m+1>1 then piR-m+1<pi∀i:
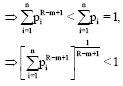 | (39) |
Case II: When 0<R<m or 0<R-m+1<1, then on the same lines, we have:
| (40) |
we know that:
if R>m and:
if R<m
Case III: Property (b) follows if one of the probabilities is equal to 1 and others are equal to zero, Hence from Eq. 39, 40 and property (b), we conclude that ![]() (P)≥0.
(P)≥0.
Property (c) is axiom 2.
Also it is noted that the generalized R-norm information measure is maximal if all probabilities are equal and is minimum if one probability is unit and others are zero.
(d) ![]() (P) is monotonic iff
(P) is monotonic iff ![]() (p, 1-p) is non-decreasing on p∈[0, 1/2].
(p, 1-p) is non-decreasing on p∈[0, 1/2].
From Eq. 35, we have:
| (41) |
Let us define the function G(p) by:
Then:
and:
From Eq. 41, we note that:
which gives:
Thus ![]() (p, 1-p) is a non-decreasing function and hence monotonic.
(p, 1-p) is a non-decreasing function and hence monotonic.
(e) We know that:
is continuous for R∈[0, ∞) and m>0 (≠1), Hence:
is also continuous at R∈R+ where m>0 (≠1) R ≠m.
(f) It is obvious:
| (42) |
Also it is easy to see that:
| (43) |
(g) From Eq. 41 it follows that:
This proves that ![]() (P) is small for small probabilities.
(P) is small for small probabilities.
(h) Let us define the concave function.
Definition 1: A function of over a set S is said to be concave if for all choices of x1, x2,..., xm∈S and for all scalars λ1, λ2,..., λm such that:
the following holders:
| (44) |
Here we consider random variable x taking its values in the set S = (x1, x2,..., xm) and r probability distributions over S on follows:
Let us define another probability distribution over S:
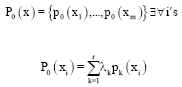 |
where, λk’s are non-negative scalars satisfying:
then we have:
![]() (P) will be concave if D is less than zero for R, m>0 (≠1), R≠m, so we consider:
(P) will be concave if D is less than zero for R, m>0 (≠1), R≠m, so we consider:
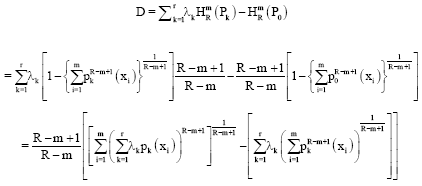 | (45) |
Now using the inequality:
according as ![]() , we have:
, we have:
according as ![]() . Therefore:
. Therefore:
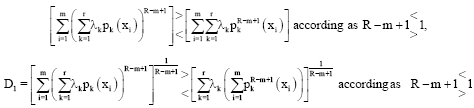 | (46) |
Moreover:
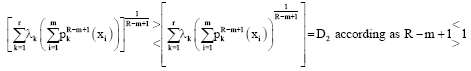 | (47) |
Thus ![]() according as
according as ![]() , which implies that D<0 in view of the sign of R-m+1/R-m according as
, which implies that D<0 in view of the sign of R-m+1/R-m according as ![]() .
.
This proved that ![]() (P) is concave function P.
(P) is concave function P.
We set max. Pi = pk, assuming m0 = 1, 2,..., R>m we find that:
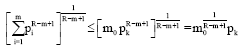 | (48) |
It is also noted that for R>m:
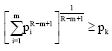 | (49) |
Combing Eq. 48 and 49, we get:
| (50) |
Taking limit for R→∞ in Eq. 50, we have:
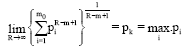 |
and finally:
This completes the proof of theorem 4.
JOINT AND CONDITIONAL GENERALIZED R-NORM INFORMATION MEASURES
In this section, we consider joint and conditional probability distributions of two random variables ξ and η having probability distributions P and Q over the sets X = (x1, x2,..., xn) and Y = (y1, y2,..., ym) respectively. Then the generalized R-norm information measure of type R and degree m of the random variables.
ξ ,η are respectively given by:
where, pi = Pr(ξ = xi), i = 1, 2,..., n and qj = Pr(η = yj), j = 1, 2,..., m are the probabilities of the possible values of the random variables. Similarly we consider a two-dimensional discrete random variable (ξ ,η) with the joint probability distribution π = {π11,..., πnm} where πij = Pr(ξ = xi, η = yj), i = 1, 2,..., n; j = 1, 2,..., m is the joint probability for the values (xi, yj) of (ξ ,η)
We shall denote conditional probabilities by pij and qji such that:
Definition 2: The joint generalized R-norm information measure of type R and degree m for R∈R+ and R-m+1>0, R,m>0(≠1), R ≠m is given by:
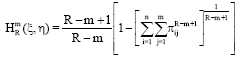 | (51) |
It may be seen that ![]() (ξ ,η) is symmetric in ξ and η If ξ and η are stochastically independent, then the following non-additive property holds:
(ξ ,η) is symmetric in ξ and η If ξ and η are stochastically independent, then the following non-additive property holds:
| (52) |
Definition 3: The average conditional generalized R-norm information measure of type R and degree m for R∈R+ and R-m+1>0, R,m>0(≠1), R≠m is given by:
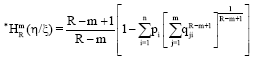 | (53) |
or alternately:
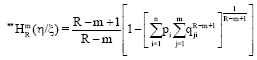 | (54) |
The two conditional measures Eq. 53 and 54 differ according to the probability pi have been taken. The expression Eq. 53 is a true mathematical expression over ξ whereas the expression Eq. 54 is not.
In next theorem, we prove three results for the conditional generalized R-norm information measures given by Eq. 53 and 54.
Theorem 5: If ξ and η are discrete random variables then for R∈R+ and R-m+1>0, R, m>0 (≠1), R≠m then the following inequalities holds:
| (55) |
| (56) |
| (57) |
The equality sign holds iff ξ and η are independent.
Proof: We know (Beckenbach and Bellman, 1961) that for R>m:
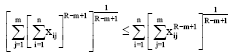 | (58) |
Setting xij = πij≥0 in Eq. 58, we have:
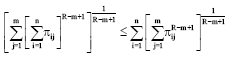 | (59) |
or:
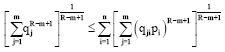 |
or:
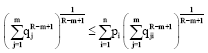 | (60) |
It implies:
Since R-m+1/R-m>0, in view of R>m and m>0(≠1), therefore on multiplication we get:
| (61) |
On the same lines, we can prove that (61) holds for 0<R<m and m>0 (≠1), hence Eq. 55 holds for all R∈R+ and R-m+1>0, R, m>0 (≠1), R≠m. The equality sign holds iff πij is separable in the sense that πij = piqj.
From Jensen’s inequality for R>m and m>0(≠1), we find:
| (62) |
After summation over j and raising both sides to power 1/R-m+1, we have:
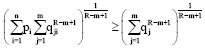 | (63) |
Using R-m+1/R-m>0 as R>m, we get:
| (64) |
Equality holds if for all i, qij = qj, which is equivalent to the independent property.
For 0<R<m, the inequality in Eq. 63 reverses. However, in view of R-m+1/R-m<0, as R<m and m>0(≠1), Eq. 64 still holds.
Hence, result (56) is proved.
Next for the proof of (57) we apply Jensen inequality and obtain:
| (65) |
It implies:
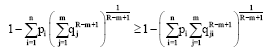 | (66) |
Since R-m+1/R-m>0, in view of R>m and m>0 (≠1), therefore on multiplication we get ![]() , which is the required result.
, which is the required result.
Hence, Eq. 57 is proved for all R∈R+ and m>0(≠1). This completes the proof of theorem 5.
REFERENCES
- Al-Daoud, E., 2007. Adaptive quantum lossless compression. J. Applied Sci., 7: 3567-3571.
CrossRefDirect Link - Al-Nasser, A.D., O.M. Eidous and L.M. Mohaidat, 2010. Multilevel linear models analysis using generalized maximum entropy. Asian J. Math. Stat., 3: 111-118.
CrossRefDirect Link - Boekee, D.E. and J.C.A. van der Lubbe, 1980. The R-norm information measure. Inform. Control, 45: 136-155.
CrossRefDirect Link - Haouas, A., B. Djebbar and R. Mekki, 2008. A topological representation of information: A heuristic study. J. Applied Sci., 8: 3743-3747.
CrossRefDirect Link - Kumar, S. and A. Choudhary, 2011. A coding theorem for the information measure of order α and of type β. Asian J. Math. Stat., 4: 81-89.
CrossRefDirect Link - Kumar, S. and A. Choudhary, 2011. A noiseless coding theorem connected with generalized renyi's entropy of order α for incomplete power probability distribution pβ. Asian J. Applied Sci., 4: 649-656.
CrossRefDirect Link - Kumar, S. and A. Choudhary, 2011. R-Norm Shannon-Gibbs type inequality. J. Applied Sci., 11: 2866-2869.
CrossRefDirect Link - Renyi, A., 1961. On measure of entropy and information. Proc. 4th Berkeley Symp. Maths. Stat. Prob., 1: 547-561.
Direct Link - Rupsys, P. and E. Petrauskas, 2009. Forest harvesting problem in the light of the information measures. Trends Applied Sci. Res., 4: 25-35.
CrossRefDirect Link - Shannon, C.E., 1948. A mathematical theory of communication. Bell Syst. Tech. J., 27: 379-423.
Direct Link - Sharma, B.D. and I.J. Taneja, 1975. Entropy of type (α,β) and other generalized measure in information theory. Metrica, 22: 205-215.
CrossRefDirect Link - Stepak, A.M., 2005. Frequency value grammar and information theory. J. Applied Sci., 5: 952-964.
CrossRefDirect Link - Wang, Y., 2011. Generalized Information theory: A review and outlook. Inform. Technol. J., 10: 461-469.
CrossRefDirect Link - Yan, R. and Q. Zheng, 2009. Using renyi cross entropy to analyze traffic matrix and detect DDoS attacks. Inform. Technol. J., 8: 1180-1188.
CrossRefDirect Link - Arimoto, S., 1971. Information-theoretic considerations on estimation problems. Inform. Control, 19: 181-194.
CrossRef