
Satish Kumar
Department of Mathematics, Geeta Institute of Management and Technology, Kanipla-136131, Kurukshetra, Haryana, India
Arun Choudhary
Department of Mathematics, Geeta Institute of Management and Technology, Kanipla-136131, Kurukshetra, Haryana, India
Asian Journal of Applied Sciences
Year: 2011 | Volume: 4 | Issue: 6 | Page No.: 649-656







ABSTRACT
In this study, a new measure, Lβα called average code word length of order α for incomplete power probability distribution pβ has been defined and its relationship with a result of generalized Renyi's entropy has been discussed. Using Lβα , a coding theorem for discrete noiseless channel has been proved.
PDF Abstract XML References Citation
Received: January 22, 2011;
Accepted: April 21, 2011;
Published: June 29, 2011
How to cite this article
Satish Kumar and Arun Choudhary, 2011. A Noiseless Coding Theorem Connected with Generalized Renyi’s Entropy of Order α for Incomplete Power Probability Distribution pβ. Asian Journal of Applied Sciences, 4: 649-656.
DOI: 10.3923/ajaps.2011.649.656
URL: https://scialert.net/abstract/?doi=ajaps.2011.649.656
DOI: 10.3923/ajaps.2011.649.656
URL: https://scialert.net/abstract/?doi=ajaps.2011.649.656
INTRODUCTION
Throughout the paper N denotes the set of the natural numbers and for NεN we set:
| (1) |
In case there is no rise to misunderstanding we write PεΔN instead of (p1,...,pN) εΔN.
In case N ε N the well-known Shannon entropy is defined by:
where, the convention 0 log (0) = 0 is adapted (Shannon, 1948).
Throughout this study, ∑ will stand for ![]() unless otherwise stated and logarithms are taken to the base D (D>1).
unless otherwise stated and logarithms are taken to the base D (D>1).
Let a finite set of N input symbols:
be encoded using alphabet of D symbols, then it has been shown by Feinstein (1956) that there is a uniquely decipherable code with lengths n1, n2,...,nN if and only if the Kraft inequality holds that is:
| (2) |
where, D is the size of code alphabet.
Furthermore, if:
| (3) |
is the average codeword length, then for a code satisfying Eq. 2, the inequality:
| (4) |
is also fulfilled and equality holds if and only if:
| (5) |
and that by suitable encoded into words of long sequences, the average length can be made arbitrarily close to H (P), (Feinstein, 1956). This is Shannon's noiseless coding theorem.
By considering Renyi's entropy (Renyi, 1961), a coding theorem and analogous to the above noiseless coding theorem has been established by Campbell (1965) and the authors obtained bounds for it in terms of:
Kieffer (1979) defined a class rules and showed Hα (P) is the best decision rule for deciding which of the two sources can be coded with expected cost of sequences of length n when n → ∞, where the cost of encoding a sequence is assumed to be a function of length only. Further, in Jelinek (1980) it is shown that coding with respect to Campbell (1965) mean length is useful in minimizing the problem of buffer overflow which occurs when the source symbol is produced at a fixed rate and the codewords are stored temporarily in a finite buffer.
Hooda and Bhaker (1997) consider the following generalization of Campbell's mean length:
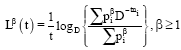 |
and proved:
under the condition:
where, ![]() is generalized entropy of order α = 1/1+t and type β studied by Aczel and Daroczy (1963) and Kapur (1967). It may be seen that the mean codeword length Eq. 3 had been generalized parametrically and their bounds had been studied in terms of generalized measures of entropies. Here, we give another generalization of Eq. 3 and study its bounds in terms of generalized entropy of order α for incomplete power probability distribution pβ.
is generalized entropy of order α = 1/1+t and type β studied by Aczel and Daroczy (1963) and Kapur (1967). It may be seen that the mean codeword length Eq. 3 had been generalized parametrically and their bounds had been studied in terms of generalized measures of entropies. Here, we give another generalization of Eq. 3 and study its bounds in terms of generalized entropy of order α for incomplete power probability distribution pβ.
Generalized coding theorems by considering different information measure under the condition of unique decipherability were investigated by Khan et al. (2005), Parkash and Sharma (2004), Singh et al. (2003), Hooda and Bhaker (1997) and Pereira and Dial (1984).
The mathematical theory of information is usually interested in measuring quantities related to the concept of information. Shannon (1948) fundamental concept of entropy has been used in different directions by the different authors such as Stepak (2005), Al-Daoud (2007), Haouas et al. (2008), Rupsys and Petrauskas (2009), Al-Nasser et al. (2010) and Kumar and Choudhary (2011).
The objective of this paper is to study a coding theorem by considering a new information measure depending on two parameters. The motivation of this study among others is that this quantity generalizes some information measures already existing in the literature such as the Arndt (2001) and Renyi (1961) entropy which is used in physics.
CODING THEOREM
Definition: Let N ε N be arbitrarily fixed, α,β>0, α≠1 be given real numbers. Then the information measure ![]() : ΔN → R is defined by:
: ΔN → R is defined by:
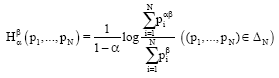 | (6) |
It also studied by Roy (1976).
REMARKS
| • | When β = 1, the information measure |
| • | When β = 1 and α → 1, then the information measure |
| • | When α → 1, the information measure |
Definition: Let N ε N, α, β > 0, α ≠ 1 be arbitrarily fixed, then the mean length ![]() corresponding to the generalized information measure
corresponding to the generalized information measure ![]() is given by the formula:
is given by the formula:
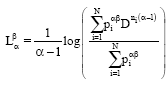 | (7) |
where (p1,..., pN) and D, n1, n2,...,nN are positive integers so that:
| (8) |
Also, we have used the condition Eq. 8 to find the bounds. It may be seen that the case β = 1 inequality Eq. 8 reduces to Eq. 2.
We establish a result, that in a sense, provides a characterization of under the condition of Eq. 8.
Measure of average codeword length of order α for incomplete power probability distribution pβ
Definition: Let us define the average code length:
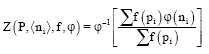 | (9) |
where, f is a non constant positive valued, continuous function defined on (0, 1], φ is a strictly monotonically increasing and continuous real valued function defined on [1, ∞) such that φ-1 exists. From Eq. 9, it is clear that we are defining average code length as a most general quasilinear mean value rather than ordinary average.
The basic requirement which any measure of average code word length should satisfy is that it should be translative for all positive integers mεN+, where, N+ denotes the set of positive integers. In other words, if the length of each code word is increased by a positive integer mεN+ by attaching to the right, sequence of length m constructed by using letter of code alphabet A, then the average code length must increased by m. Thus, we get the functional equation:
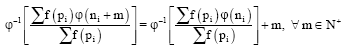 | (10) |
Equation 10 is known as translative equation following Aczel (1974), the following theorem can be proved easily.
Theorem 1: The only quasilinear measure Z (P, ![]() , f, φ) of average code length which are translative ∀mεN+ are:
, f, φ) of average code length which are translative ∀mεN+ are:
| (11) |
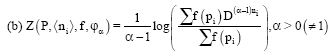 | (12) |
Where, φ1 (x) = bx + α, b > 0 and φα (x) = bD(α-1)x + α, D>1, b>0.
Now, our object is to connect Eq. 12 to entropy of order α for the incomplete power distribution Pβ, we write Eq. 12 as:
| (13) |
we now restrict to α > 0 (≠1) and choose f (pi) in such a way that the last term on the R.H.S. in Eq. 13 becomes Eq. 6:
| (14) |
Equation 14 gives rise to the functional equation:
| (15) |
The only non-constant continuous solution of Eq. 15 refer also to Aczel (1966) are of the form:
| (16) |
Hence:
| (17) |
Where:
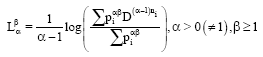 | (18) |
REMARKS
| • | When β = 1, then Eq. 18 reduces to average code word length studied by Nath (1975) |
| • | When β = 1 and α → 1, then Eq. 18 reduces to average codeword length studied by Shannon (1948) |
| • | When α → 1 and β ≠ 1, Eq. 18 reduces to |
In the following theorem, we give a relation between ![]() and
and ![]() (p1,..., pN)
(p1,..., pN)
Theorem 2: Let there be a discrete memoryless source emitting messages x1,x2,...,xN with probabilities P = (p1, p2,...,pN) and ∑pi = 1, if the messages are encoded in a uniquely decipherable way and ni denote the length of code word assigned to the message xi then:
| (19) |
holds with equality iff are of the form:
| (20) |
Moreover:
| (21) |
Proof: By Shisha (1967) Holder’s inequality, we have:
| (22) |
where, p-1+q-1 = 1; p (≠ 0) < 1, q < 0 or q (≠ 0) < 1, p < 0; xi, yi > 0 for each i.
Making the substitutions
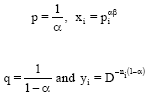 |
in Eq. 22, we get:
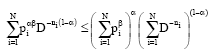 |
using the condition Eq. 8, we get:
| (23) |
it implies:
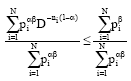 | (24) |
we obtain the result Eq. 19 after simplification as 0 < α < 1.
i.e., ![]() .
.
Similarly, we can prove Eq. 19 for α > 1.
It can be proved that there is equality in Eq. 19 if and only if:
or
We choose the codeword lengths ni as integers satisfying:
| (25) |
From the left inequality of Eq. 25, we have:
| (26) |
taking sum over i, we get the generalized inequality Eq. 8, So there exists a generalized personal code with length ni's.
Let 0< α<1, then Eq. 25 can be written as:
| (27) |
Multiplying Eq. 27 by ![]() throughout, summing over i and we obtain the result Eq. 21 after simplification for 1/α-1 as 0< α<1.
throughout, summing over i and we obtain the result Eq. 21 after simplification for 1/α-1 as 0< α<1.
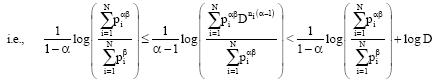 |
![]() which gives Eq. 21.
which gives Eq. 21.
Similarly, we can prove Eq. 21 for α > 1.
REFERENCES
- Aczel, J., 1974. Determination of all additive quasiarithmetic mean codeword lengths. Probability Theory Related Fields, 29: 351-360.
CrossRef - Al-Daoud, E., 2007. Adaptive quantum lossless compression. J. Applied Sci., 7: 3567-3571.
CrossRefDirect Link - Al-Nasser, A.D., O.M. Eidous and L.M. Mohaidat, 2010. Multilevel linear models analysis using generalized maximum entropy. Asian J. Math. Stat., 3: 111-118.
CrossRefDirect Link - Haouas, A., B. Djebbar and R. Mekki, 2008. A topological representation of information: A heuristic study. J. Applied Sci., 8: 3743-3747.
CrossRefDirect Link - Jelinek, F., 1980. Buffer overflow in variable lengths coding of fixed rate sources. Trans. Inform. Theory, 14: 490-501.
Direct Link - Kieffer, J.C., 1979. Variable-lengths source coding with a cost depending only on the codeword length. Inform. Control, 41: 136-146.
CrossRef - Kumar, S. and A. Choudhary, 2011. A coding theorem for the information measure of order α and of type β. Asian J. Math. Stat., 4: 81-89.
CrossRefDirect Link - Nath, P., 1975. On a coding theorem connected with renyi’s entropy. Inform. Control, 29: 234-242.
CrossRef - Pereira, R. and G. Dial, 1984. Pseudo-generalization of Shannon inequality for Mittal's entropy and its application in coding theory. Kybernetika, 20: 73-77.
Direct Link - Renyi, A., 1961. On measure of entropy and information. Proc. 4th Berkeley Symp. Maths. Stat. Prob., 1: 547-561.
Direct Link - Rupsys, P. and E. Petrauskas, 2009. Forest harvesting problem in the light of the information measures. Trends Applied Sci. Res., 4: 25-35.
CrossRefDirect Link - Shannon, C.E., 1948. A mathematical theory of communication. Bell Syst. Tech. J., 27: 379-423.
Direct Link - Singh, R.P., R. Kumar and R.K. Tuteja, 2003. Application of holder's inequality in information theory. Inform. Sci., 152: 145-154.
Direct Link - Stepak, A.M., 2005. Frequency value grammar and information theory. J. Applied Sci., 5: 952-964.
CrossRefDirect Link