
H.J. Zainodin
School of Science and Technology, Universiti Malaysia Sabah, Kota Kinabalu, Sabah, 88400, Malaysia
Noraini Abdullah
School of Science and Technology, Universiti Malaysia Sabah, Kota Kinabalu, Sabah, 88400, Malaysia
G. Khuneswari
University of Glasgow, School of Mathematics and Statistics, G12 8QQ Glasgow, United Kingdom
Science International
Year: 2014 | Volume: 2 | Issue: 3 | Page No.: 64-71







ABSTRACT
Background: Market studies on consumer preferences on product items had shown that consumer’s behavioural patterns and intentions are sources of business profit level. In the advent wave of global businesses, the behavioural buying patterns of consumers have to be studied and analysed. Hence, this research illustrated the procedures in getting the best polynomial regression model of the consumer buying patterns on the demand for detergent that had included interaction variables. Methods: The hierarchically multiple polynomial regression models involved were up to the third-order polynomial and all the possible models were also considered. The possible models were reduced to several selected models using progressive removal of multicollinearity variables and elimination of insignificant variables. To enhance the understanding of the whole concept in this study, multiple polynomial regressions with eight selection criteria (8SC) had been explored and presented in the process of getting the best model from a set of selected models. Results: A numerical illustration on the demand of detergent had been included to get a clear picture of the process in getting the best polynomial order model. There were two single independent variables: the "price difference” between the price offered by the enterprise and the average industry price of competitors’ similar detergents (in US$) and advertising expenditure (in US$). Conclusion: In conclusion, the best cubic model was obtained where the parameters involved in the model were estimated using ordinary least square method.
PDF Abstract XML References Citation
How to cite this article
H.J. Zainodin, Noraini Abdullah and G. Khuneswari, 2014. Consumer Behavioural Buying Patterns on the Demand for Detergents Using
Hierarchically Multiple Polynomial Regression Model. Science International, 2: 64-71.
URL: https://scialert.net/abstract/?doi=sciintl.2014.64.71
URL: https://scialert.net/abstract/?doi=sciintl.2014.64.71
INTRODUCTION
Regression analysis allows the researcher to estimate the relative importance of independent variables in influencing a dependent variable. It also identifies a mathematical equation that describes the relationship between the independent and dependent variables. According to Sandy1, simple linear regression is a technique that is used to describe the effects of changes in an independent variable on a dependent variable. However, the Multiple Regression is a technique that predicts the effect on the average level of the dependent variable of a unit change in any independent variable while the other independent variables are held constant. According to Gujarati2, a model with two or more independent variables is known as a multiple regression model. The term “multiple” indicates that there are multiple independent variables involved in the analysis and multiple influences will affect the dependent variable. According to Pasha3 using too few independent variables may give a biased prediction, while using too many independent variables, can cause a varied fluctuation prediction value.
Most cost and production functions are curves with changing slopes and not a straight line with constant slopes4. The polynomial model enables the estimation of these curves5,6. In a polynomial model, independent variables can be squared, cubed or raised to any power or exponential power. The studies of7 is an example of a squared polynomial or quadratic model, while8 fitted a third order polynomial model of the best R2 correlation. The coefficients still appear in the regression in a linear fashion, allowing the regression to be estimated as usual. As in2, for example, the polynomial model is given as:
Since the same independent variables appear more than once in different forms, it will appear to be highly correlated. The effect of multicollinearity may not exist because the independent variables are not linearly correlated.
The main objective of this study is to obtain the best model with a polynomial order which would represent the whole structure of the collected data so that further analysis can be carried out. There is no unique statistical procedure for doing this and personal judgment will be a necessary part of any of the statistical methods discussed.
METHODOLOGY
A Hierarchical Multiple Regression Model relates a dependent variable Y, to several independent variables W1, W2, …, Wk. The model is in the following form:
| (1) |
Basic assumptions of Multiple Regression Models are made about the error terms, ui (for i=1, 2, …, n) and the values of independent variables W1, W2, …, Wk are shown in Table 1 with Ω0 denotes the constant term of the model, Ωj denotes the j-th coefficient of independent variable Wj (for j = 1, 2, …, k) and u denotes the random residual of the model. The k denotes the number of independent variables (k+1) denotes the total number of parameters.
The general Multiple Regression Model with k independent variables is defined in Eq. 1 where Y denotes the dependent variable, Wj denotes the j-th independent variable (which can be single independent quantitative variable, or interaction variable (first-order interaction, second-order interaction, third-order interaction, …), or generated variable (dummy or/and polynomial or/and categorical variables) or transformed variable (Ladder transformation and Box-Cox transformation). The Ω0 denotes the constant term of the model, Ωj denotes the j-th coefficient of independent variable Wj (for j = 1, 2, …, k) and u denotes the random residual of the model. The k denotes the number of independent variables, (k+1) denotes the total number of parameters.
The Multiple Regression Model as defined in Eq. 1 is a hierarchically well-formulated models9 and can be written as a system of n equations, as shown by the following:
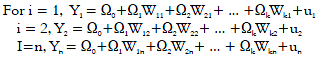 | (2) |
This system of n equations can be expressed in matrix terms as the following:
| (3) |
Where:
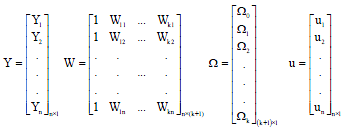 |
The Y, Ω and u are in a form of vectors. The W is in a form of matrix. For example, the regression model for two single independent variables (X1 and X2) with possible interaction variable (X12 is the product of independent variables X1 and X2) can be expressed as follows:
| (4) |
 |
This Eq. 4 can be written in general form as in Eq. 1:
Where:
| Ω0 | = | β0 constant |
| Ω1 | = | β1 and W1= X1 single independent |
| Ω2 | = | β2 and W2= X2 single independent |
| Ω3 | = | β12 and W3= X12= X1X2 (First-order interaction variable) |
| Ω4 | = | β11 and W4= X12= X1X1 (Quadratic variable) |
| Ω5 | = | β22 and W5= X22= X2X2 (Quadratic variable) |
| Ω6 | = | β111 and W6= X13= X1X1X1 (Cubic variable) |
| Ω7 | = | β222 and W7= X23= X2X2X2 (Cubic variable) |
| Ω8 | = | β122 and W8= X1X22= X1X2X2 (interaction variable) |
where, k = 8 and (k+1) = 9.
The variable X1X2 denotes the product of variables X1 and X2. According to Zainodin and Khuneswari10, the variable X1X2 can also be written as X12 and defined it as the first-order interaction variable. In general, the cross product between q single independent quantitative variables, the interaction variable is (q-1)-order interaction variable.
In the development of the mathematical model, there are four phases involved. These phases are possible models, selected models, best model and goodness-of-fit test11. In the beginning, all the possible models are listed. Once this has been done, the next step is to estimate the coefficients for the entire possible model and then carry out the tests to get selected models. All the possible models must be run one by one to obtain selected models. In the process of getting the selected models from possible models, multicollinearity test and elimination procedure (elimination of insignificant variables) should be carried out in order to obtain a selected model. These selected models should be free from the multicollinearity sources and insignificant variables.
Multicollinearity arises when two independent variables are closely linearly related. This is equivalent to saying that a coefficient of determination greater than 0.95 represents a strong linear relation. An absolute correlation coefficient greater than 0.95 (i.e., |r|>0.95) defines a strong multicollinearity. The algorithm for the multicollinearity test procedures have also been described by Zainodin et al.11. The Global test is then carried out as shown by Zainodin and Khuneswari10. If there are no more multicollinearity source variables, then the next step is to carry out the elimination procedures on the insignificant variables. This is done by performing the coefficient test for all the coefficients in the model. According to Abdullah et al.12 the coefficient test is carried out for each coefficient by testing the coefficient of the corresponding variable with the value of zero. The insignificant variables will be eliminated one at a time. Subsequent removals are carried out on all the models until all the insignificant variables are eliminated. The Wald test is then carried out on all the resultant selected models so as to justify the removal of the insignificant variables10.
A best model will be selected from a set of selected models that have been obtained from previous phases in the model-building procedures. The best model will be selected with the help of the eight selection criteria (8SC)13,11. The best model is chosen when a particular model has the most of the least criteria value (preferably all the 8 criteria chose the same model).
Finally, the residual analysis should be carried out on the best model to verify whether the residuals are randomly and normally distributed. Bin Mohd et al.14 stated that randomness test should be carried out to investigate the randomness of the residuals produced. One of the MR assumptions is that the residuals should follow a normal distribution. Besides that, Shapiro-Wilk test is used (for n<50) to check the normality assumption of the residuals. Scatter plot, histogram and box-plot of the residuals are to a get a clear picture of distribution of the residual. These plots are used as supporting evidence in addition to the two quantitative tests.
RESULTS
This section will describe the process in getting the best polynomial regression model by including a numerical illustration. In this study, the data was collected from 30 sale regions of detergent ‘FRESH’ during 1989, as published in Bowerman and O’Connell15.
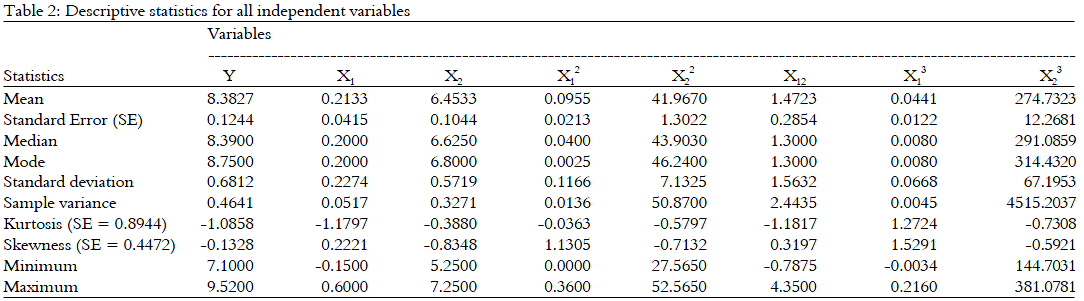
In this study, the variables used are the demand (Y) for the detergent bottles to the factors affecting, such as the "price difference" (X1) between the price offered by the enterprise and the average industry prices of competitors’ similar detergents and advertising expenditure (X2). The aim is to analyse what is the contribution of a specific attribute in determining the demand. Table 2 shows the descriptive statistics for each variable used. As stated by Crawley16, the distribution of a variable is said to be normal if the value of skewness fall within [-0.4472, 0.4472] and kurtosis fall within [-0.8944, 0.8944].
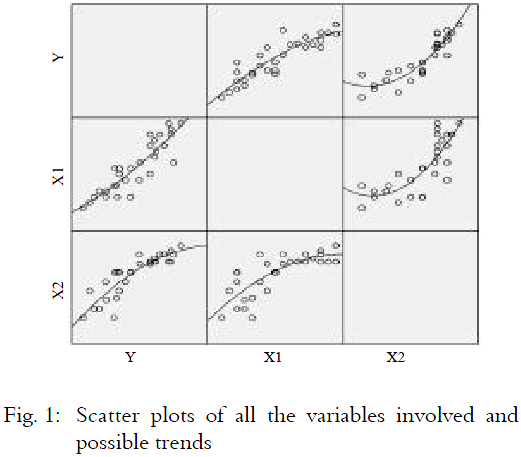
There are two single quantitative independent variables involved in this data in order to determine the demand of detergent bottles. Figure 1 shows the scatter plots of all the variables involved and their possible trends.
Based on the plots in Fig. 1, it could be seen significantly that Y and X2 have a polynomial shaped relationship. The fitted curves show a quadratic line relationship. The linear line between Y and X1 shows a linear relationship and it is supported with the Table 3 that shows Y and X1 is highly correlated. This shows that there exists possible non linear variable that contributes to Y.
 |
 |
 |
All the quadratic and cubic terms introduced in the models are thus shown in Table 3.
Table 3 shows all the possible models with interaction and polynomial variables. There are four all possible models (M1-M4) for two single independent variable (X1 and X2). The polynomial and interaction with polynomial variables are added in model M1 to model M4. Therefore, there are 12 possible models which include quadratic and cubic variables.
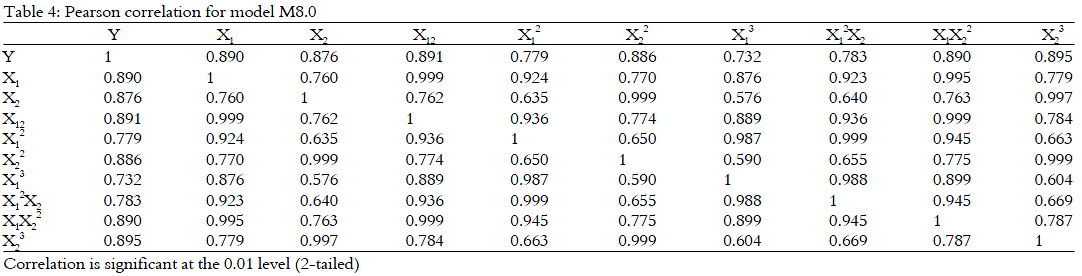
Table 4 shows the Pearson correlations matrix for example, the possible model M8.0. It can be seen that there exists multicollinearity among 9 pairs of independent variables (shaded values). The multicollinearity source variables should firstly be removed according to the Zainodin-Noraini Multicollinearity Remedial Techniques11.
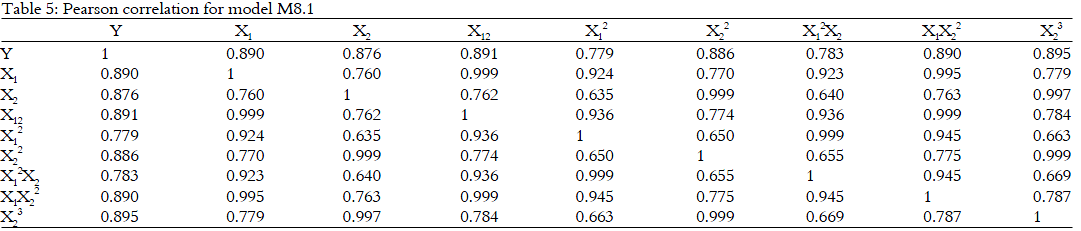
Since there is a tie, the variable X13 (correlation with Y is 0.732) is removed because it has the smallest correlation coefficient with dependent variable (this is a case B of the Zainodin-Noraini multicollinearity remedial technique). After the removal of variable X13, model then becomes model M8.1. The correlation coefficient is recalculated as shown in Table 5. Here, it could be seen that there exists multicollinearity among the 7 pairs of independent variables (shaded values). There exist a tie and the variable X2 (correlation with Y is 0.876) is then removed because it has the smallest correlation coefficient with the dependent variable (this is again a case B).
After removing variable X2, the new model is model M8.2. The correlation coefficient is recalculated as shown in Table 6.
 |
 |
 |
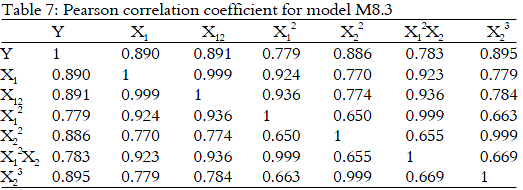 |
Here, it could be seen that there exists multicollinearity among the 5 pairs of independent variables. The most commonly appearing variables are X1, X12 and X1X22. Since there is a tie, the variable X1X22 (correlation with Y is 0.890) is removed because it has the smallest correlation coefficient with dependent variable (this is again a case B). The new model after removing variable X1X22 is model M8.3. Then the correlation coefficient was recalculated as shown in Table 7. From Table 7, it can be seen that there exists multicollinearity among the 3 pairs of independent variables.
There are no common variables among the multicollinearity source variables. Therefore, the variable with the smallest correlation coefficient with dependent variable in each pair should be removed.
 |
The three variables X1, X12 and X22 are removed from the model M8.3 (this is a case C where frequency of all the variables is one).
The new model after removing the variables X1, X12 and X22 is then model M8.6. The correlation coefficient is thus recalculated as shown in Table 8. Based on the highlighted triangle in Table 8, it could be seen that there is no more multicollinearity left in the model.
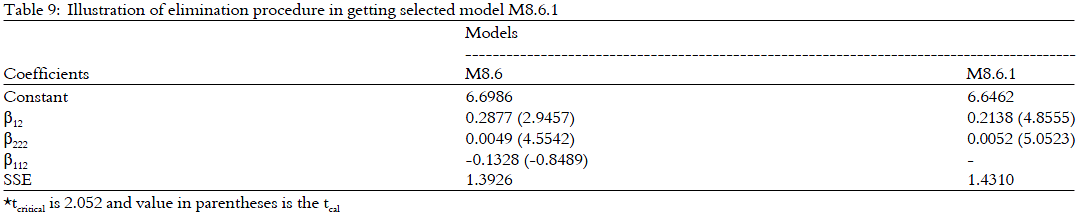
The next step is to carry out the coefficient test of the elimination procedures on the insignificant variables and the Wald test on model M8.6.0. The Wald test is carried out to justify the elimination process. There is only one variable that is omitted from the model M8.6 as shown in Table 9.
Table 10 shows the Wald test for model M8.6.1. From Table 10, Fcal is 0.7103 and FTable = F(1, 26, 0.05) = 4.23 from the F-distribution table.
 |
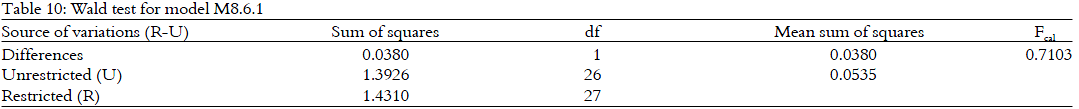 |
 |
Since Fcal is less than Ftable, H0 is accepted. The removal of insignificant variables in the coefficient test is therefore justified. The selected model M8.6.1 is:
Similar procedures and tests (Global test, Coefficient test and Wald test) are carried out on the remaining selected models. There are 8 selected models obtained in this phase. For each selected model, the eight selection criterion (8SC) values are obtained and the corresponding values are shown in Table 11.
It can be seen from Table 11 that all the criteria (8SC) indicate that model M11.3.1 as the best model. Thus, the best model is M11.3.1 is given by:
Referring to Table 4, the Pearson correlation shows the correlation where the "price difference" (X1) (i.e., r =0.890) between the price offered by the enterprise and the average industry price of competitors’ similar detergents, are highly correlated with the demand for detergent bottles (Y). The components of model M11.3.1 further indicate the presence of polynomial-order (cubic) of the significant independent variables. The variable X23 (i.e., r = 0.8949) are highly correlated with the demand for detergent bottles (Y). The interpretations of the coefficients for best model M11.3.1 are depicted in Table 12.
 |
 |
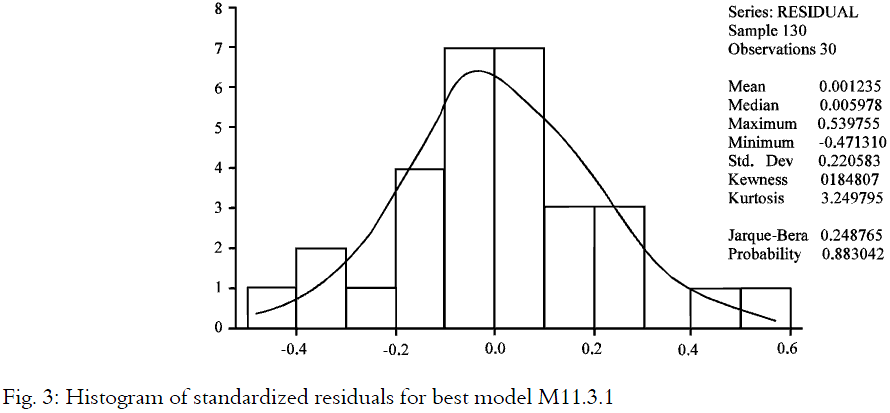
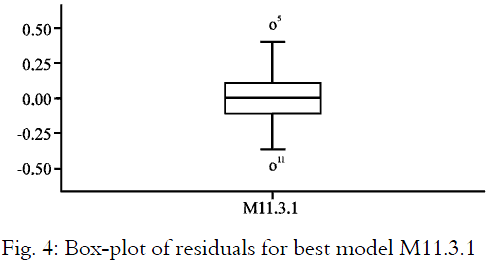
Based on the best model, the residuals analyses are obtained. Several tests on the model’s goodness-of-fit are carried out. It is found that all the basic assumptions are satisfied and the residuals plots are shown in Fig. 2-4. Using the residuals obtained, randomness test and the normality test are carried out. Both randomness test and residuals scatter plot, as shown in Fig. 2 and 3, indicate that the residuals are random, independent and normal.
 |
 |
The total sum of residual of the best model, M11.3.1 is 0.0370 while the sum of square error is 1.4110. The randomness test carried out on residuals shows that resulting error term of best model M11.3.1 is random and independent. This strengthens the belief which is reflected in the residuals plot of Fig. 3 which confirms that no obvious pattern exists. This shows that the best model M11.3.1 is an appropriate model in determining the demand of detergent.
Besides that by taking ±3 standard deviation (i.e., 99.73%) for Upper Control Limit (UCL) and Lower Control Limit (LCL) as in Fig. 2, the residuals are distributed between the ±3 standard deviation lines which indicate that there are no outliers. The Shapiro-Wilk statistics of the normality plot in Fig. 3 shows that the residuals of model M11.3.1 are distributed normally (i.e., statistics =0.9865, df =30 and p-value =0.9603). Figure 4 with its median positioned at the centre of the box further shows that model M11.3.1 is a well represented model to describe the demand of detergents. Thus, the model is ready to be used for further analysis. Now the demand model is ready for use in forecasting or estimating to make a logical decision in determining the appropriate demand of detergent.
DISCUSSIONS
Other goodness-of-fit tests can be used such as the root-mean square error (RMSE), Modelling Efficiency (EF) and many others17,18. However, in this research, the residuals analysis is based on the randomness and normality tests. The numerical illustration of this study shows that polynomial regression model M11.3.1 is the best model to describe the demand of detergent. The "price difference" (=X1) between the price offered by the enterprise and the average industry price of competitors’ with similar detergents is the main factor in determining the demand of detergent and the “advertising expenditure” (=X2) as the cubic factor. The best model M11.3.1 (i.e., ![]() ) in Table 12 shows that constant demand without any contributions of other factors is approximately 7 bottles (since the constant value is 6.6398). Every one unit increase in “price difference” will directly increase the number of detergent by 1.4673 bottles and every one unit increase in advertising expenditure will positively increase the number of detergent by 0.0052 bottles, respectively. This means that if “price difference” and expenditure are increased by one unit, then the number of detergent demanded will be 8 bottles (approximate value).
) in Table 12 shows that constant demand without any contributions of other factors is approximately 7 bottles (since the constant value is 6.6398). Every one unit increase in “price difference” will directly increase the number of detergent by 1.4673 bottles and every one unit increase in advertising expenditure will positively increase the number of detergent by 0.0052 bottles, respectively. This means that if “price difference” and expenditure are increased by one unit, then the number of detergent demanded will be 8 bottles (approximate value).
Similar to Chu19, the cubic polynomial approach is used to forecast the demand of detergent. 20had also attempted the use of price in the consumer purchase decision using price awareness with three distinct factors, namely, price knowledge, price search in store and between stores and the Dickson-Sawyer method21. The effect of advertising tools on the behaviour of consumers of detergents had also been surveyed and compared by Salavati et al.22 in developing countries. Moreover, advance researches on promoting hygiene, such as hand hygiene, with criteria like fast and timely, easy and skin protection, are part of the campaigns involved in advertising expenditure23.
CONCLUSIONS
The consumer buying behaviour will affect the demand for detergents. It is imperative in today’s diverse global market that a firm can identify consumer behavioural attributes and needs, lifestyles and purchase processes and the influencing factors which are responsible for the consumer decisions. Hence, devising good marketing plans is necessary for a firm. While serving its targeted markets, it minimises dissatisfaction and still stay ahead of other competitors. It was seen from the best model that there is conclusive increase in production due to price difference and expenditure. In other words, mathematically, a detergent manufacturing company has to project its marketing and production plans to incorporate the impacts of pricing and expenditure on the consumers. Indirectly, the firm succeeded in meeting the demands of the consumers in a win-win relationship.
REFERENCES
- Beach, E.F., 1950. The use of polynomials to represent cost functions. Rev. Econ. Stud., 16: 158-169.
CrossRef - Al-Hazza, M.H.F., E.Y.T. Adesta, A.M. Ali, D. Agusman and M.Y. Suprianto, 2011. Energy cost modeling for high speed hard turning. J. Applied Sci., 11: 2578-2584.
CrossRefDirect Link - Fonseca, G.G., P.S. da Silva Porto and L.A. de Almeida Pinto, 2006. Reduction of drying and ripening times during the Italian type salami production. Trends Applied Sci. Res., 1: 504-510.
CrossRefDirect Link - Zainodin, H.J. and G. Khuneswari, 2009. A case study on determination of house selling price model using multiple regression. Malaysian J. Math. Sci., 3: 27-44.
Direct Link - Zainodin, H.J., A. Noraini and S.J. Yap, 2011. An alternative multicollinearity approach in solving multiple regression problem. Trends Applied Sci. Res., 6: 1241-1255.
CrossRefDirect Link - Abdullah, N., Z.H.J. Jubok and J.B.N. Jonney, 2008. Multiple regression models of the volumetric stem biomass. WSEAS Trans. Math., 7: 492-502.
Direct Link - Bin Mohd, I., S.C. Ningsih and Y. Dasril, 2007. Unimodality test for global optimization of single variable functions using statistical methods. Malaysian J. Math. Sci., 1: 205-215.
Direct Link - Mohammadi, A., S. Rafiee, A. Keyhani and Z. Emam-Djomeh, 2009. Moisture content modeling of sliced kiwifruit (cv. Hayward) during drying. Pak. J. Nutr., 8: 78-82.
CrossRefDirect Link - Meisami-Asl, E., S. Rafiee, A. Keyhani and A. Tabatabaeefar, 2009. Mathematical modeling of moisture content of apple slices (Var. Golab) during drying. Pak. J. Nutr., 8: 804-809.
CrossRefDirect Link - Chu, F.L., 2004. Forecasting tourism demand: A cubic polynomial approach. Tourism Manage., 25: 209-218.
CrossRefDirect Link - Kenesei, Z. and S. Todd, 2003. The use of price in the purchase decision. J. Empirical Generalisations Market. Sci., 8: 1-21.
Direct Link - Dickson, P.R. and A.G. Sawyer, 1990. The price knowledge and search of supermarket shoppers. J. Market., 54: 42-53.
Direct Link - Pittet, D., 2001. Improving adherence to hand hygiene practice: A multidisciplinary approach. Emerging Inf. Dis., 7: 234-240.
PubMed