
T. Yousefi Rezaii
Faculty of Electrical and Computer Engineering, Tabriz University, Tabriz, Iran
M.A. Tinati
Faculty of Electrical and Computer Engineering, Tabriz University, Tabriz, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 5 | Page No.: 924-930







ABSTRACT
In this study the Regularized and simplified Monte Carlo-Joint Probabilistic Data Association Filter (RMC-JPDAF) is proposed and applied to the classical problem of multiple target tracking in a cluttered area. To encounter with the data association problem that arises due to unlabeled measurements in the presence of clutter, we have used the Joint Probabilistic Data Association Filter (JPDAF). The Monte Carlo methods are used in order to the fact that they have the ability to estimate any general state-space model with nonlinear and non-Gaussian functions for target dynamics and measurements likelihood. The Conventional implementation of Monte Carlo-JPDAF (MC-JPDAF) uses the resampling stage in order to reduce the variance of samples (called degeneracy problem); however this procedure itself causes another problem called sample impoverishment phenomenon, which is unavoidable and the tracking performance will decrease. So, we propose to use the regularized resampling stage instead, to counteract this shortcoming. Finally, the target dynamics model is used as the proposal distribution in MC-JPDAF, in order to decrease the computational cost while the performance of the tracking system is nearly maintained. The simulation results of the proposed system are presented and compared with those of the standard Monte Carlo implementation of FPDAF and the performance improvement of the proposed algorithm is proven.
PDF Abstract XML References Citation
How to cite this article
T. Yousefi Rezaii and M.A. Tinati, 2009. Improved Joint Probabilistic Data Association Filter for Multi-Target
Tracking in Wireless Sensor Networks. Journal of Applied Sciences, 9: 924-930.
DOI: 10.3923/jas.2009.924.930
URL: https://scialert.net/abstract/?doi=jas.2009.924.930
DOI: 10.3923/jas.2009.924.930
URL: https://scialert.net/abstract/?doi=jas.2009.924.930
INTRODUCTION
In state estimation field, many studies have been performed to develop the classical estimation methods for linear and Gaussian models and obtain a robust estimator for the general case of nonlinear and non-Gaussian models. This is because for many application areas, it is becoming important to include elements of nonlinearity and non-Gaussianity in order to model accurately the underlying dynamics of a physical system. Arulampalan et al. (2002) and Chen (2003) introduced several methods to encounter with such models, such as the Extended Kalman Filter, approximate Grid-based methods and Particle filters. They demonstrate that in the case of nonlinear and non-Gaussian models for dynamic and likelihood distributions, the particle filtering method represents the best performance and is most reliable, in spite of its higher computational cost.
Multiple Target Tracking (MTT) is not a trivial extension of single target tracking but rather a challenging topic of research. In MTT scenarios, there is a combinatorial explosion in the space of possible multiple target trajectories due to the uncertainty in the association of observed measurements with known targets in each time step. Theoretically, the standard recursive Bayesian filtering techniques can be applied directly to the joint state-space of the targets, but computing the filtered distribution over the multi-target state and dealing with the combinatorial explosion of possible states due to the data association ambiguity, is difficult in practice (Lio et al., 2007). Therefore, the main challenge of realization of an MTT system is to manage the computational complexity of the problem while still providing the reasonable tracking performance.
Multiple Hypothesis Tracking (MHT) and JPDAF are the two major approaches to deal with MTT problems and were first developed by Reid (1979) and Fortmann et al. (1983), respectively. In this study the JPDAF approach is applied to solve the data association problem due to its lower computational complexity and the ability of online implementation. In this way, at each time step infeasible hypotheses are pruned away using a gating procedure. A filtering estimate is then computed for each of the remaining hypotheses and combined in proportion to the corresponding posterior hypothesis probabilities. The main shortcoming of the JPDAF is that, to maintain the tractability, the final estimate is collapsed to a single Gaussian, thus discarding some useful information. This is due to the fact that the distribution of interest is nonlinear and non-Gaussian in general. The linear and Gaussian models assumption is often made by some researchers to simplify hypotheses evaluation for target originated measurements. The implementation of JPDAF using the Extended Kalman Filter (EKF) is an instance. However, the performance of these algorithms degrades as the non-linearities become more severe. More recently, strategies have been proposed to combine the JPDAF with particle techniques to accommodate general nonlinear and non-Gaussian models (Schuls et al., 2003; Frank et al., 2003; Karlsson and Gustafsson, 2001; Vermaak et al., 2005). The MC-JPDAF developed by Vermaak et al. (2005), can be considered as the first comprehensive algorithm that uses the Monte Carlo methods to implement the MTT while efficiently taking into account the data association problem. So, the MC-JPDAF method could be used for the general case of nonlinear and non-Gaussian dynamics and measurement models. The main shortcoming of the MC-JPDAF is the sample impoverishment due to the resampling stage and high computational complexity.
In this study we have used the regularized resampling, developed by Musso et al. (2001) to overcome the sample impoverishment problem of MC-JPDAF algorithm. Furthermore, in order to reduce the computation complexity of MC-JPDAF, we propose to use the prior density (dynamics model) as the proposal density function instead of the proposal density introduced by Vermaak et al. (2005). This leads to considerable reduction in computational complexity, because in each time instance, the particles are sampled from the simple and known prior distribution and no further computation is needed to construct the proposal distribution for each of the targets in each observer. This simplification is achieved with no considerable reduction in tracking performance.
MODEL DESCRIPTION
Several models used in MTT scenario are described here. The evolution of the joint state space of the K slowly maneuvering targets in the xy plane, is considered to be of the form described by Bar-Shalom and Fortman (1988), (the near constant velocity model). Also the state evolution of each target is assumed to be independent of the others. So, the state of the kth target in the xy plane comprises its position and velocity:
| (1) |
So, the matrix form of the state transition equation is:
| (2) |
where, T is the sampling period, A is the state transition matrix and Vk,t is the process noise and assumed to be zero mean Gaussian distributed with known covariance matrix defined below (Vermaak et al., 2005):
| (3) |
| (4) |
The measurements are assumed to be available from No observer sensors at locations Pio, i = 1, …, No. So, the joint measurement vector from No observers at each time interval is:
| (5) |
where, Mi is the total number of measurements in the ith observer, comprising Mic clutter measurements and MiT measurements arising from the targets to be tracked. In general, Mic and MiT varies from observer to other observer and also in different time instances in the same observer.
To deal with the data association problem, we consider the association variables presented by Vermaak et al. (2005). The measurement to target association hypothesis is defined as λ = λ1…λNo, where, λi = (ri, MiC, MiT) is the measurement to target association hypothesis for the measurements at the ith observer. The elements of the association vector ri are given as:
 |
The target to measurement association hypothesis ![]() is defined in a similar fashion, where,
is defined in a similar fashion, where, ![]() is the target to measurement association hypothesis for the measurements at the ith observer. The elements of the association vector
is the target to measurement association hypothesis for the measurements at the ith observer. The elements of the association vector ![]() are obtained as follows:
are obtained as follows:
 |
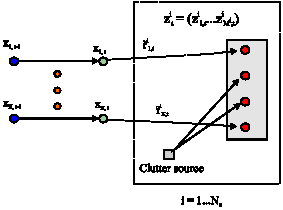 | |
| Fig. 1: | The parameters set for MTT in a single time step where there exist K targets and No observers |
The two set of above hypotheses are equivalent. The parameters set for multi-target scenario for a single time step is shown in Fig. 1. Considering that the observer sensors measure the range Rij and bearing θij from the observer to the target, the individual measurements at the ith observer are zij = (Rij, θij), j = .1,…, Mi. If the range and bearing are assumed to be corrupted by independent Gaussian noise, the likelihood for the target jth measurement, under the hypothesis that it is associated with the kth target, becomes:
| (6) |
where, ![]() is the fixed and known diagonal covariance with the individual noise variances.
is the fixed and known diagonal covariance with the individual noise variances. ![]() is the mean vector of the Gaussian distribution in Eq. 6 and is given by: isjfoieufioweorweuiseuweiu
is the mean vector of the Gaussian distribution in Eq. 6 and is given by: isjfoieufioweorweuiseuweiu
| (7) |
| (8) |
where, Pio = (xio, yio) is the ith observer position.
In order to estimate the unknown association hypothesis within a Bayesian framework, definition of a prior distribution for these hypotheses is necessary. As the prior distribution, the one described by Gordon et al. (1997) and Vermaak et al. (2005) is used. The prior for the association hypothesis is assumed to be independent of the state and past values of the association hypothesis. For the measurement to target association hypothesis we assume that the prior factorizes over the observers, i.e.,
| (9) |
And so for each of the observers, the prior is assumed to be:
| (10) |
| (11) |
| (12) |
| (13) |
As it is clear from Eq. 11 to 13, the prior for the association vector is assumed to be uniform over all valid hypotheses, the number of clutter measurements is assumed to follow a Poisson distribution with rate parameter λiC and the prior for the target measurements is assumed to follow a binomial distribution. PD is the detection probability of each targets in every observer. The prior for the target to measurement association hypothesis follows the same structure. Furthermore, it is possible to obtain a factorization form for target to measurement association hypothesis prior as (Vermaak et al., 2005):
| (14) |
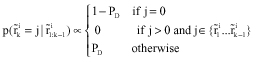 |
Where:
MC-JPDAF framework: As mentioned earlier, JPDAF approach, due to its simplicity and low computational complexity in contrast with MHT approach, is the most widely applied method in MTT problems considering the data association uncertainty. So, we have also chosen this approach to solve the data association problem in this study. Several implementation strategies for JPDAF method have been proposed in literature according to the application area. Since, the target dynamics and measurement likelihood models in target tracking applications are nonlinear and non-Gaussian in general, the selected Bayesian framework should have the ability to estimate and track such nonlinear and non-Gaussian models. For this reason, the Monte Carlo implementation of JPDAF presented by Vermaak et al. (2005) is used in MTT system. Due to the Particle filtering methods used in MC-JPDAF, it has the ability to track the arbitrary proposal distributions.
The main idea of JPDAF is to recursively update the marginal filtering distributions for each of the targets pk(xk,t|z1, t-1), k = 1, …, K through the Bayesian sequential estimation recursion:
| (15) |
Due to the data association uncertainty, the filtering step cannot be performed independently. In JPDAF the likelihood for the kth target is assumed to be:
| (16) |
where, ![]() , is the posterior probability that the kth target is associated with jth measurement in the ith observer with the posterior probability that the kth target is undetected. Furthermore, the likelihood is assumed to be independent over the observers. With the definition of the likelihood as in Eq. 16, the filtering step is as follows:
, is the posterior probability that the kth target is associated with jth measurement in the ith observer with the posterior probability that the kth target is undetected. Furthermore, the likelihood is assumed to be independent over the observers. With the definition of the likelihood as in Eq. 16, the filtering step is as follows:
| (17) |
All that remains is to compute the posterior probabilities of the marginal associations βijk as:
| (18) |
where, ![]() is the set of all joint target to measurement association hypotheses for the data at the ith observer.
is the set of all joint target to measurement association hypotheses for the data at the ith observer.
As discussed by Vermaak et al. (2005), the posterior probability for the joint association hypothesis ![]() can be expressed as:
can be expressed as:
| (19) |
where, the expression ![]() is given from Eq. 14, Vi is the volume of the measurement space for the ith observer defined as:
is given from Eq. 14, Vi is the volume of the measurement space for the ith observer defined as:
Vi = 2πRimax, |
where, Rimax is the maximum range of the ith observer and Ii = {jε{1…Mi}: rij ≠ 0}.
The expression ![]() is the predictive likelihood for the jth measurement at the ith observer using the information from the kth target, given in the standard form by:
is the predictive likelihood for the jth measurement at the ith observer using the information from the kth target, given in the standard form by:
| (20) |
In Monte Carlo frame work, the predictive likelihood in Eq. 20 is approximated using the Monte Carlo samples from the proposal distribution. It is assumed that for the kth target the set of samples ![]() is available, approximately distributed according the marginal filtering distribution at the earlier time step pk(xk,t-1|z1:t-1). At the current time step new samples for the target state are generated from a suitably constructed proposal distribution, i.e.,
is available, approximately distributed according the marginal filtering distribution at the earlier time step pk(xk,t-1|z1:t-1). At the current time step new samples for the target state are generated from a suitably constructed proposal distribution, i.e.,
| (21) |
As mentioned previously, we propose to use the prior distribution as the proposal distribution for kth target, i.e.,
| (22) |
Using these Monte Carlo samples the predictive likelihood in Eq. 20 can be approximates as:
| (23) |
where, the predictive weights are given by:
| (24) |
Considering the proposal distribution given in Eq. 22, the predictive weights will be the same as the importance weights, i.e.,
| (25) |
The approximation to the predictive likelihood can now straightforwardly be substituted into Eq. 19 to obtain the approximation for the joint association posterior probabilities, from which approximations for the marginal target to measurement association posterior probabilities can be computed according to Eq. 18. These approximations can be used in Eq. 17 to approximate the target likelihood. Finally, setting the new importance weights to:
| (26) |
leads to the sample set ![]() being approximately distributed according to the marginal filtering distribution at the current time step pk (xk,t|z1:t).
being approximately distributed according to the marginal filtering distribution at the current time step pk (xk,t|z1:t).
Considering the prior distribution as the proposal distribution Eq. 26 simplifies as follows:
| (27) |
Regularized MC-JPDAF: The resampling stage is introduced to reduce the degeneracy problem, which is prevalent in particle filters. However, the resampling, in turn causes the problem of loss of diversity among the particles, called sample impoverishment. This arises due to the fact that in the resampling stage, samples are drawn from a discrete distribution rather than a continuous one. If this problem is not addressed properly, it may lead to particle collapse, which is a severe case of sample impoverishment, where, all N particles occupy the same point in the state space, giving a poor representation of the posterior density (Arulampalan et al., 2002). The Regularized Particle Filter (RPF) is proposed by Musso et al. (2001) to address this problem. The RPF resamples from a continuous approximation of the posterior density pk (xk,t|z1:t):
| (28) |
where, Kh(x) = 1/hnx K(x/n), is the rescaled kernel density, h>0 is the kernel band-width, nx is the dimension of the state vector x. In the special case of all the samples having the same weight, the optimal choice of the kernel density is the Epanechnikov kernel:
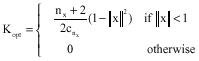 | (29) |
where, cnx is the volume of the unit hypersphere in ![]() nx. Furthermore when the underlying density is Gaussian with a unit covariance matrix, the optimal choice for the band-width is (Musso et al., 2001):
nx. Furthermore when the underlying density is Gaussian with a unit covariance matrix, the optimal choice for the band-width is (Musso et al., 2001):
| (30) |
| (31) |
Although the results of Eq. 29-31 are optimal only in the special case of equally weighted particles and underlying Gaussian density, these results can still be used in the general case to obtain a suboptimal filter.
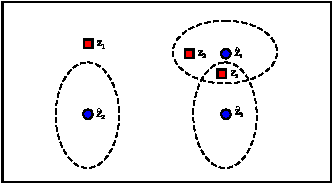 | |
| Fig. 2: | The gating procedure in a sample observer |
Gating procedure: Gating (Bar-Shalom and Fortman, 1988) is one of the most straightforward and effective methods to reduce the number of valid hypotheses in JPDAF framework. In this method, for each target a validation region is constructed from available information. In other words, the state of each target in earlier time step is mapped into the measurement space of each sensor and only measurements that fall within the target validation region are considered as possible candidates to be associated with the particular target. The details of this method are not given here. We have used this procedure in order to further decrease the computational cost of the MTT system. The best value for parameter ε which indicates the radius of the valid measurement space is obtained empirically. For the sake of further clarity, the procedure of gating in a sample observer (e.g., ith observer) is shown in Fig. 2. In Fig. 2 the blue circles stand for the mapping of the previous state of the three targets in the measurement space of the ith observer (![]() ). The validation regions of each target are represented by the dashed ellipses around the targets’ positions. The three measurements at the current time step are indicated as red squares. So, according to gating procedure, the measurements Z2 and Z3 are considered as the possible candidates of association with target 1 and the measurement Z3 is considered as the only possible candidate of association with target 3. According to Fig. 2, target 3 has no possible measurement candidate for association. Also, the measurement Z1 has no chance of association with targets since it lies in any of the validation regions of three targets.
). The validation regions of each target are represented by the dashed ellipses around the targets’ positions. The three measurements at the current time step are indicated as red squares. So, according to gating procedure, the measurements Z2 and Z3 are considered as the possible candidates of association with target 1 and the measurement Z3 is considered as the only possible candidate of association with target 3. According to Fig. 2, target 3 has no possible measurement candidate for association. Also, the measurement Z1 has no chance of association with targets since it lies in any of the validation regions of three targets.
RESULTS AND DISCUSSION
Here, the simulation results for a two target tracking system in the presence of clutter and false alarms, using both the MC-JPDAF and RMC-JPDAF methods, are presented. In the both algorithms, the proposal distribution is assumed to be the prior density function.
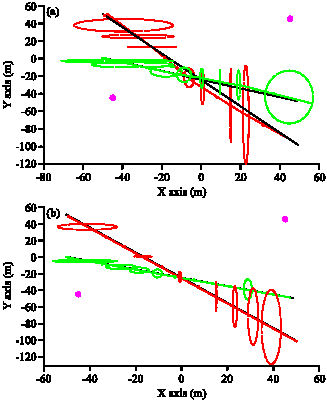 | |
| Fig. 3: | Trajectories for two targets. N = 300, two magenta points are the observers, solid black lines are the true target tracks, solid red and green lines are the estimated trajectories of targets and ellipses are the estimated 2σ confidence regions of the estimate covariances, (a) MC-JPDAF and (b) RMC-JPDAF |
In what follows, all location and distance measures are in meters, all angle measures in radians, all time measures in seconds and all velocity measures in meter per second. As depicted in Fig. 3, two observers are place in locations (-45, -45) and (45, 45) in the xy plane, with σR = 5, σθ = 0.05 and Rmax being the independent Gaussian noise variances for range and bearing measurements and the maximum range of the observers, respectively.
We model the target dynamics with the near constant velocity model (Frank et al., 2003) with σx = σy = 0.05 being the process noise variances along x and y axes. The discretization time step for the system is set to T = 1. The initial states of targets are (-50, 1, 50, -1.5) and (-50, 1, 0, -0.5). Target detection probability for each observer is assumed to be PD = 0.5 and the clutter measurements are assumed to have Poisson distribution with rate λc = 0.8 for both sensors. In order to further reduce the computational cost, a kind of gating procedure is conducted in order to prune away the infeasible hypotheses in each time step. A suitable validation region is obtained by setting ε = 40. Parameter ε is defined by Reid (1979). The simulations are performed for 100 time steps. Figure 1 shows the true and the estimated target trajectories for MC-JPDAF and RMC-JPDAF methods, where the number of particles N is set to 100.
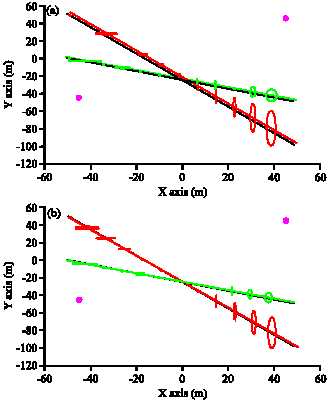 | |
| Fig. 4: | Trajectories for two targets. N = 500, two magenta points are the observers, solid black lines are the true target tracks, solid red and green lines are the estimated trajectories of targets and ellipses are the estimated 2σ confidence regions of the estimate covariances, (a) MC-JPDAF and (b) RMC-JPDAF |
It is obvious that the performance and tracking ability of the proposed RMC-JPDAF method is considerably high due to the regularization stage used, while the computational complexity and so the execution time are significantly reduced. However, due to the fact that the number of particles drawn in each time step from the proposal distribution is finite, the computed 2σ regions are somewhat large. This can be compensated by increasing the number of particles. In Fig. 4, the number of particles is set to 500 and considerable reduction in 2σ regions is obtained. In this case, the higher tracking performance of the proposed method versus MC-JPDAF is apparent.
In Fig. 5, the well known Root Mean Square Error (RMSE), versus different values for particles number is plotted for MC-JPDAF and RMC-JPDAF. As it is obvious, the RMSE and so the estimation variance decrease as the number of particles increases for both methods. Furthermore, the RMSE for the proposed method has smaller values than MC-JPDAF method, for different values for particles number.
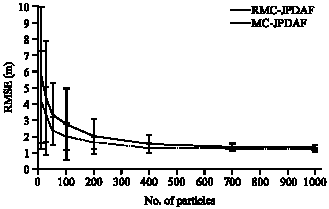 | |
| Fig. 5: | The RMSE in meters for both MC-JPDAF and RMC-JPDAF algorithms |
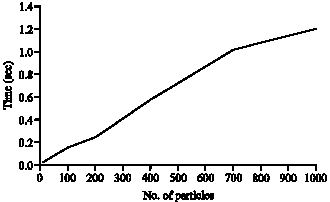 | |
| Fig. 6: | Average execution time for a single time step |
Finally the average execution time for a single time step (cycle) of the simulation program versus the number of particles, is depicted in Fig. 6. As it was expected, the average execution time increases nearly linearly as the number of particles increases and this is nearly the same as for the execution time of the standard MC-JPDAF by Vermaak et al. (2005).
CONCLUSION
In this study, a kind of robust MTT system is implemented using Regularized and simplified MC-JPDAF tracker. The regularization step is performed to overcome the sample impoverishment problem due to the resampling step in MC-JPDAF and the prior distribution in used as the proposal distribution in order to significantly reduce the computational cost of the tracking system. Finally, the simulation results for the proposed method prove the simplicity and robustness of the proposed method versus MC-JPDAF.
ACKNOWLEDGMENT
This study was partially supported by Iran Telecommunication Research Center.
REFERENCES
- Fortmann, T. and Y. Bar-Shalom and M. Scheffe, 1983. Sonar tracking of multiple target using joint probabilistic data association. IEEE J. Oceanic Eng., 8: 173-184.
Direct Link - Frank, O. and J. Nieto and J. Guivant and S. Scheding, 2003. Multiple target tracking using sequential monte carlo methods and statistical data association. Proceedings of the International Conference on Intelligent Robots and Systems, October 27-31, 2003, IEEE Computer Society Washington, DC. USA., pp: 2718-2723.
CrossRefDirect Link - Gordon, N.J. and D.J. Salmond and D. Fisher, 1997. Bayesian target tracking after group pattern distortion. SPIE Proc. Series, 3163: 238-248.
Direct Link - Karlsson, R. and F. Gustafsson, 2001. Monte carlo data association for multiple target tracking. IEE Target Tracking: Algorithms Appl., 1: 13/1-13/5.
Direct Link - Lio, J. and M. Chu and J.E. Reich, 2007. Multi-target Tracking in distributed sensor networks. IEEE Signal Proc. Magazine, 36: 36-46.
CrossRefDirect Link - Reid, D.B., 1979. An Algorithm for tracking multiple targets. IEEE Trans. Automatic Control, 24: 843-854.
CrossRefDirect Link - Schulz, D., W. Burgard, D. Fox and A.B. Cremers, 2003. People tracking with mobile robots using sample-based joint probabilistic data association filters. Int. J. Robot. Res., 22: 99-116.
CrossRefDirect Link - Vermaak, J. and S.J. Godsill and P. Perez, 2005. Monte carlo filtering for multi-target tracking and data association. IEEE Trans. Aerospace Electronic Syst., 41: 309-322.
CrossRefDirect Link - Arulampalam, M.S., S. Maskell, N. Gordon and T. Clapp, 2002. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Processing, 50: 174-188.
CrossRef