
Zhenping Xie
School of Digital Media, Jiangnan University, Wuxi, 214122, China
Shitong Wang
School of Digital Media, Jiangnan University, Wuxi, 214122, China
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 10 | Page No.: 1942-1949







ABSTRACT
Because of its requirement of precisely extracting moving objects, motion segmentation especially for dynamic scenes is more difficult than motion tracking. So, efficient image segmentation methods may be employed to solve above problem, which drives us to develop more novel motion segmentation method for dynamic scenes. In this study, a novel image segmentation method using level set is employed to design a new motion segmentation method for dynamic scenes. From theoretical analysis, level set method and Gaussian Mixture Model (GMM) are two very valuable tools for natural image segmentation. The former aims to acquire good geometrical continuity of segmentation boundaries, while the latter focuses on analyzing statistical properties of image feature data. Derived from this common knowledge, a novel level set image segmentation method integrated with GMM (called as GMMLS) has been proposed in previous studies. Wherein, Gaussian mixture model is used to analyze image feature, moreover the effectiveness and good performance of GMMLS also have been demonstrated. Based on GMMLS, a new motion segmentation method for dynamic scenes is proposed in this study and experimental results on several moving objects in dynamic scenes indicate that new method owns some excellent and particular worthiness on such practical applications.
PDF Abstract XML References Citation
Received: June 28, 2011;
Accepted: September 06, 2011;
Published: September 19, 2011
How to cite this article
Zhenping Xie and Shitong Wang, 2011. A New Motion Segmentation Method for Dynamic Scenes. Information Technology Journal, 10: 1942-1949.
DOI: 10.3923/itj.2011.1942.1949
URL: https://scialert.net/abstract/?doi=itj.2011.1942.1949
DOI: 10.3923/itj.2011.1942.1949
URL: https://scialert.net/abstract/?doi=itj.2011.1942.1949
INTRODUCTION
Motion segmentation is a primary requirement for the comprehensing of video contents and is also a key processing in many applications of computer vision like video surveillance, video indexing, traffic monitoring and so on (Gruber and Weiss, 2007; Hui et al., 2011; Guo-quan and Zhan-ming, 2011). Motion segmentation aims to extract moving objects (foreground) from a video sequence (Zhang and Lu, 2001). Though many researches have been executed in the past decades, however the performances of most algorithms still seriously fall behind the ability of human vision (Gruber and Weiss, 2007). Now, feature-based and dense methods are two types of typical motion segmentation methods. In feature-based methods, a moving object is represented by a certain number of specific points like corner points or salient points, while in dense methods motion segmentation is pixel-wise performed (Kumar et al., 2008).
In early researches, scientists usually borrow motion estimation methods to implement motion segmentation like classical optical flow field methods (Jepson and Black, 1993; Cobos and Monasterio, 2003; Berthold and Schunck, 1993). In those methods, only displacement vectors of moving object are considered in performing segmentation. Although, apparently accurate results can be obtained, however, motion estimation approaches strongly depend on the performance of estimated optical flow field, because that optical flow field can not be reliably evaluated in many cases due to the noise, missing data and the lack of priori knowledge (Zappella et al., 2009). Besides, motion blur will also affect the accuracy of estimated optical flow field especially in dynamic scenes (Stolkin et al., 2008). Consequently, motion estimation based algorithms are doomed to result in imprecise segmentation results especially around the edges of moving objects (Jodoin and Mignotte, 2005). To remedy above problem, spatial constraints are usually considered to achieve more precise motion segmentation results. Jodoin and Mignotte (2005) proposed a K-nearest-neighbor-based fusion procedure in their article where spatial and temporal features of moving object are simultaneously analyzed. Even so, gaining precise optical flow field is very difficult in dynamic scenes which will seriously drop the segmentation accuracy of moving object. In contrast, derived from dense processing, clustering based segmentation methods will be very worthy for such cases. So, a novel level set image segmentation method GMMLS will be employed to explore the problem of motion segmentation in dynamic scenes in this study, wherein some particular and excellent segmentation performances will be indicated.
INTRODUCTION TO GMMLS METHOD
Gaussian mixture model and level set image segmentation methods are two important methods used in image processing field (Devi and Kumaravel, 2008; Zhang et al., 2008; Giridhar Akula et al., 2007; Britto and Ravindran, 2005a, b, 2006a, b). From intuitive thinking, there is a great complementarity between them. Inspired by this recognition, a new level set method integrated with Gaussian mixture model GMMLS has been proposed in previous studies (Xie, 2007).
GMMLS model objective: Let Ω = {1, 2,…,L} denote entire image domain with L regions and Ωl represents the lth segmentation region. Let X = {x1, x2,…,xN} be image feature data set, where xi represents the image feature of ith pixel. Let S (Ω) denote a partition of Ω, θ be the parameter of Gaussian mixture model and M be the number of domain prototypes. Herein, Gaussian mixture model (Bilmes, 1998; Redner and Walker, 1984) is the most practical representative tool among all mixture density models. It principally assumes that, for a dataset X, every sample xi is said to be independent and identically distributed (i.i.d.) and its corresponding distribution can be denoted by π(x) expressed as follows:
where, M is the number of cluster prototypes. ωj is a priori probability with:
g (x;θj) is a multivariate Gaussian function, defined as follows:
where μj, Σj represent the mean and covariance of a multivariate Gaussian function, respectively.
When X is known, the question how to obtain optimal S (Ω) should be an equivalent description of general image segmentation objective, meanwhile optimal model parameter θ should be achieved when Gaussian mixture model is used to represent the data distribution of image feature. Thus, following model objective in GMMLS can be proposed.
Further, if a likelihood function L(p) is introduced, we have:
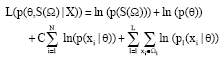 | (1) |
Therefore, we have:
| (2) |
In level set image segmentation methods, S (Ω) could be commonly represented by level set functions, where a level set function φ can divide Ω into two domains. Thus, if the desired number of segmented domains is L, it needs at least [log2 (L)] level set functions. If log2 (L) is not an integer, there must be some empty representative domains, which will result in many undesirable problems in practical applications (Rousson, 2004). So, many studies consider that every desired segmentation domain is represented by independent level set function (Ayed et al., 2006; Brox and Weickert, 2004, 2006). Here, for convenience, the case that there are only two desired segmented domains (L = 2) is firstly consider. When L = 2, to facilitate following discussion, two segmented domains may be denoted as foreground and background (Ω- and Ω+), respectively. Accordingly, p- and p+ are used to represent corresponding data density functions. Thus, Eq. 1 can further be rewritten as follows:
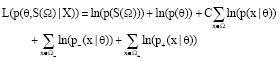 | (3) |
GMMLS algorithm: For GMMLS model objective, following equations must hold when the optimal model objective is reached by means of EM algorithm.
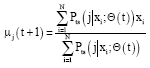 | (4) |
| (5) |
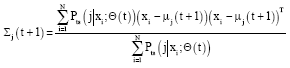 | (6) |
Again, in terms of the well-known whole probability theorem, there have:
| (7) |
Furthermore, following updating equation with respect to φ (y) can be deduced:
| (8) |
where, δε (x) is the derivative of the Heaviside function: ![]() According to above derivations, following GMMLS algorithm is proposed:
According to above derivations, following GMMLS algorithm is proposed:
| GMMLS Algorithm: |
 |
It should be pointed out that, for Step 5 in above algorithm, the update Eq. of φ (y, t+1) might not guarantee to obtain optimal solution of ![]() . Nevertheless, when selecting a suitable Δt, it can be ensured that the objective value of
. Nevertheless, when selecting a suitable Δt, it can be ensured that the objective value of ![]() can increase step by step during iteration procedure. On the other hand, in terms of generalized EM algorithm, in Step M, it is not necessary for each variable to reach their optimal solutions related to maximum objective likelihood. For these variables, it only requires that better result can be obtained than preceding iteration. Therefore, above GMMLS algorithm can guarantee ultimate stable solution corresponds to a maximum of
can increase step by step during iteration procedure. On the other hand, in terms of generalized EM algorithm, in Step M, it is not necessary for each variable to reach their optimal solutions related to maximum objective likelihood. For these variables, it only requires that better result can be obtained than preceding iteration. Therefore, above GMMLS algorithm can guarantee ultimate stable solution corresponds to a maximum of ![]() . Following experimental results also confirm it.
. Following experimental results also confirm it.
MOTION SEGMENTATION IN DYNAMIC SCENES USING GMMLS
One major goal of computer vision is to recover intrinsic knowledge about a scene from a group of images or video sequences (Ranganathan and Shah, 1988), wherein motion is a type of important visual information involved in video sequences for video understanding and processing (Bovik, 2005). Motion not only reflects spatio-temporal relationship of a moving object but also carries a lot of semantic information. So, motion segmentation is one of the very interesting topics in video image processing and its applications. By means of motion segmentation, many applications of machine vision can be implemented in video monitoring.
Here, a new way on extracting moving objects from a dynamic video sequence is proposed, where foreground (moving object) and background are all continually changing. Derived from the combination of clustering analysis and level set method, new method can be less influenced by inaccurate local motion information, inaccurate edge information, inaccurate optimal flow field and other inaccurate spatial information, such that new method can provide more opportunities to gain good segmentation results.
Next, several groups of motion segmentation experiments will be done by GMMLS and compared methods with different settings.
In addition, as noises can not be avoided in recorded video, preprocessing procedure is needed to improve motion segmentation quality. Here, famous Gaussian smoothing operator is used to blur given video images and remove noises. The degree of smoothing is determined by the standard deviation of Gaussian variance. At the same time, Lab color space is used to represent pixel feature for color video images.
Experimental results: Here, the motion segmentation results on several video sequences obtained by GMMLS and compared methods are reported, wherein Matlab@ is used as software platform and .avi video format is adopted. Statistical analysis of original motion segmentation results is done by means of statistical software SPSS version 16.0. There is no special demand for computational hardware but the compatibility with above-mentioned software is required. Of course, a quick CPU and enough memory space will provide more advantages to speed up algorithm performance.
Experiment 1: Here, some motion segmentation results obtained by GMMLS with same video sequence but different parameter M of GMMLS are firstly reported. In this experiment, moving object was a walking person in front of a fixed camera throughout whole video clip. Moreover, the predefined mask was used to delimit the region of interest which would help algorithm to rapidly concentrate on moving object. Otherwise, some unnecessary time would be spent to exclude non-interesting region (or to understand real moving object).
Figure 1 shows continuous and accurate motion segmentation results from the first frame to the last frame obtained by GMMLS with different M- and M+ on same video where corresponding execution times are 150 sec for a-d-g-j (M- = 2 M+ = 2) 192 sec for b-e-h-k (M- = M+ = 3) and 222 sec for c-f-I-l (M- = 2 M+ = 4), respectively.
 | |
| Fig. 1(a-l): | A group of motion segmentation results on a moving person in front of a fixed camera obtained by GMMLS with different M- (foreground) and M+ (background) |
Besides, motion segmentation results are also exhibited using red solid curves and the corresponding tracking results are represented by green solid rectangles in Fig. 1.
From Fig. 1, it can be noticed that the larger value of cluster number of foreground or background will result in longer execution time because the processing of expectation maximization and classification must be performed at every cluster. Another fact also can be found from this experiment is that the value of cluster number of foreground M- is always set as 2. For this, main consideration is that, firstly it should be greater than one and secondly, larger M- will increases more possibility of dividing background areas into foreground which may make desired motion segmentation inaccurate. From our experimental comparisons, M- = 2 is a good default setting if no any reliable prior knowledge is supplied. The motion segmentation results illustrated in Fig. 1 clearly display that GMMLS can excellently perform motion segmentation task on a moving person in front of a fixed camera.
Experiment 2: In this experiment, other three motion video sequences in different dynamic scenes were studied, concretely, (a) a walking person towards a quivering camera, (b) a motion frog in dynamic grasses scene, (c) a surfing person on water scene. Figure 2 gives out segmentation results obtained by GMMLS with same experimental parameters M- = M+ = 2 and same processing program where detailed motion segmentation and tracking results are also illustrated using similar method like experiment 1.
 | |
| Fig. 2(a-c): | Several different moving object segmentation results obtained by GMMLS: (a) a person towards a quivering camera in indoor scene, (b) a frog in dynamic grasses scene and (c) a surfer on dynamic water surface |
The motion segmentation results illustrated in Fig. 2 demonstrate that GMMLS has effectively accomplished motion segmentation task on these three different dynamic scenes which accords with the results indicated in experiment 1. Especially, for the first video sequence, walking person (foreground) was moving towards the camera and the background was also continually changing, so exact motion segmentation was difficult because image feature of moving object was also continually changing. Even so, GMMLS still gained perfect segmentation results.
 | |
| Fig. 3(a-d): | Two groups of motion segmentation results obtained by two comparative methods: GMMLS in (a) and (c) and motion velocity-based tracking method in (b) and (d) |
At the same time, moving objects in other two-video sequences were continually varying as well and accurate segmentation results were also achieved by GMMLS. Above experimental results demonstrate that GMMLS has good performance on motion segmentation in dynamic scenes.
Experiment 3: In this experiment, the segmentation performance of GMMLS using same experimental method was further examined, wherein motion velocity-based tracking method proposed by Peddireddi (2008) was used as comparison, which is an excellent representative of motion tracking methods. Figure 3 illustrates corresponding segmentation results obtained by GMMLS and above compared method. Concrete results clearly show that GMMLS gains good segmentation results and better performance than compared method. For example, if only motion velocity or optimal flow field is considered, inaccurate motion status may be estimated as illustrated in tracking sequences (b) and (d) in Fig. 3. In summary, GMMLS is very valuable for practical motion segmentation or tracking in dynamic scenes.
Computational efficiency: In the field of information processing; computation complexity is an important index in determining the effectiveness and the performance of an algorithm. Accordingly, some statistic analysis on execution speed of proposed method are performed, wherein the affective factors of execution effectiveness also is explored by means of motion segmentation experiments on several different types of video sequence.
Firstly, four video sequences are used same as in preceding experiments and named as a, b, c and d, respectively. The first one (a) contains a motion frog in dynamic grasses scene, the second (b) contains a walking person towards a fixed camera, the third (c) contains a walking person towards a quivering camera and the last (d) contains a surfing person on water scene. Their major differences are moving content (person or animal) and environments (corridor, open-air area, water, or grasses). Secondly, the examined video frames are fixed at 15, 30, 45, 60, and 75. Finally, total execution time at each examined video frame is recorded with second.
All experiments were done three times, and corresponding mean, 95% confidence interval, minimum and maximum of execution time are reported in Table 1.
| Table 1: | Total execution time at different fixed frame number executed by GMMLS on different videos |
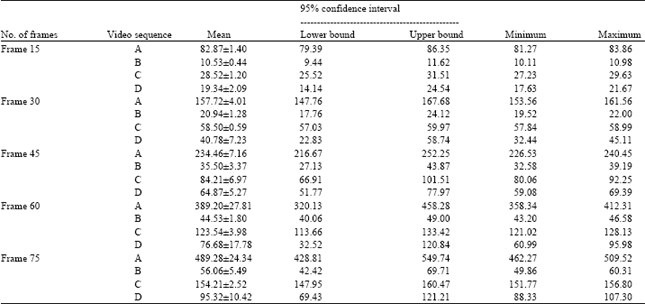 | |
Concretely, Mean denotes the mean execution time at corresponding. Number of frames for given video sequence, similarly, Minimum and Maximum record the minimum and maximum of execution time at same case and 95% Confidence Interval record the Lower Bound and Upper Bound within 95% confidence interval. Herein, the performance indices Mean and Confidence Interval are two very valid statistical quantities for discriminating the properties of the experimental results.
From Table 1, it can be found different moving objects or video scenes will result in different execution times. And if moving objects or background scenes are rapidly varying, more execution time is required to adapt more differences between two contiguous video frames, so more execution time is demanded to gain accurate motion segmentation results. The detailed experimental results listed in Table 1 also approve our theoretical explanation.
CONCLUSION
Although, motion tracking has been widely exploited in past tens of years, however motions segmentation especially in dynamic scenes still remains vast un-reached domains faced in practical applications. In this study, a novel level set image segmentation method GMMLS is employed to perform above task, experimental results demonstrate that GMMLS can gain good motion segmentation performance and own some specific merits for such type of motion segmentation problems.
REFERENCES
- Ayed, I.B., A. Mitiche and Z. Belhadj, 2006. Polarimetric image segmentation via maximum-likelihood approximation and efficient multiphase level-sets. IEEE Trans Pattern Anal Mach Intell., 28: 1493-1500.
CrossRef - Brox, T. and J. Weickert, 2004. Level set based image segmentation with multiple regions. Lect. Notes Comput. Sci., 3175: 415-423.
CrossRef - Brox, T. and J. Weickert, 2006. Level set segmentation with multiple regions. IEEE Transac. Image Process., 15: 3213-3218.
CrossRef - Cobos, P. and F. Monasterio, 2003. FPGA implementation of Santos-victor optical flow algorithm for real-time image processing: A useful attempt. VLSI Circuits Syst., 5117: 23-32.
CrossRef - Devi, S.N. and N. Kumaravel, 2008. Comparison of active contour models for image segmentation in X-ray coronary angiogram images. J. Med. Eng. Technol., 32: 408-418.
PubMed - Giridhar Akula, V.S., P. Chandrasekhar Reddy, V. Rajaraman and A.V. Sasidhar, 2007. An enhanced procedure for image segmentation and smoothing. J. Applied Sci., 7: 1452-1455.
CrossRefDirect Link - Gruber, A. and Y. Weiss, 2007. Incorporating non-motion cues into 3D motion segmentation. Comput. Vision Image Understanding, 108: 261-271.
CrossRef - Berthold, K.P.H. and B.G. Schunck, 1993. Determining optical flow: A retrospective. Artif. Intelligence, 59: 81-87.
CrossRef - Jepson, A. and M. Black, 1993. Mixture models for optical flow computation. Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, June 15-17, 1993, New York, USA., pp: 760-761.
CrossRef - Jodoin, P.M. and M. Mignotte, 2005. Motion Segmentation using a K-Nearest-Neighbor-Based fusion procedure of spatial and temporal label cues. Image Anal. Recog., 3656: 778-788.
CrossRef - Kumar, M.P., P.H. Torr and A. Zisserman, 2008. Learning layered motion segmentations of video. Int. J. Comput. Vision, 76: 301-319.
CrossRef - Britto, A.P. and G. Ravindran, 2005. Comparison of boundary mapping efficiency of gradient vector flow active contours and their variants on chromosome spread images. J. Applied Sci., 5: 1452-1460.
CrossRefDirect Link - Britto, A.P. and G. Ravindran, 2005. A review of deformable curves from the perspective of chromosome image segmentation. J. Med. Sci., 5: 363-370.
CrossRefDirect Link - Britto, A.P. and G. Ravindran, 2006. Discrete cosine transform based gradient vector flow active contours-a suitable tool for chromosome image classification. J. Med. Sci., 6: 262-274.
CrossRefDirect Link - Britto, A.P. and G. Ravindran, 2006. Evaluation of standardization of curve evolution based boundary mapping technique for chromosome spread images. Inform. Technol. J., 5: 94-107.
CrossRefDirect Link - Ranganathan, N. and M. Shah, 1988. A VLSI architecture for computing scale space. Comput. Vision, Graphics Image Proc., 43: 178-204.
CrossRef - Redner, R.A. and H.F. Walker, 1984. Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev., 26: 195-239.
Direct Link - Stolkin, R., A. Greig, M. Hodgetts and J. Gilby, 2008. An EM/E-MRF algorithm for adaptive model based tracking in extremely poor visibility. Image Vision Comput., 26: 480-495.
CrossRef - Hui, S., S. Kai and H. Qing-Yu, 2011. Fast moving small target tracking based on local background gaussian mixture model. Inform. Technol. J., 10: 1381-1387.
CrossRefDirect Link - Zappella, L., X. Llado and J. Salvi, 2009. Enhanced model selection for motion segmentation. Proceedings of the 16th IEEE international conference on Image processing, November 7-10, 2009, IEEE Press Piscataway, NJ., USA., pp: 4001-4004.
CrossRef - Zhang, D. and G. Lu, 2001. Segmentation of moving objects in image sequence: A review. Circ. Sys. Sig. Proc., 20: 143-183.
CrossRef - Guo-Quan, Z. and L. Zhan-Ming, 2011. Research on color image segmentation based on RS for intelligent vehicle navigation. Inform. Technol. J., 10: 1432-1436.
CrossRef - Zhang, M., Z. Shang and J. Shen, 2008. Research on the image segmentation necessity for regions-based image processing. Inform. Technol. J., 7: 269-276.
CrossRefDirect Link