
V.A.J. Adekunle
Department of Forestry and Wood Technology,
Federal University of Technology, P.M.B. 704, Akure, Nigeria
Research Journal of Forestry
Year: 2007 | Volume: 1 | Issue: 2 | Page No.: 40-54







ABSTRACT
Tree species diversity was assessed and the efficiency of nonlinear regression models for timber volume estimation in a complex natural forest ecosystem is established in this study. The study was carried out in the tropical rainforest ecosystem of southwest Nigeria using two forest reserves with the same logging history and management practice. Eight plots of equal size (50x50 m) were selected using systematically cluster sampling technique and complete enumeration was carried out in each plot. All trees encountered in each plot were identified with their scientific names and measured. Four non linear models were developed for each forest reserve separately while five were developed for data involving the two reserves together. The results revealed that there were 61 important tropical timber species distributed among 24 families in the two reserves. The most abundant tree species is Strombosia pustulata while the family with the highest number of species is Sterculiaceae with seven species. The mean dbh and height are 39.12 cm and 18.77 m, respectively and highest percentage of the trees belong to the least diameter class (20-29 cm). The assessment criteria (correlation coefficient (R), coefficient of determination (R2), Standard error of estimate (SE) and F-ratio) with the validation results (using simple linear regression equation, percentage bias and probability plots of residuals) show that all the models were of good fit. Very high R and R2 values, small SE and percentage biases and significant F-ratio were obtained. All the models were discovered to be very adequate for tree volume estimation in the study area. They were therefore recommended for further use in this ecosystem and in any other forest ecosystem with similar site condition.
PDF Abstract XML References
How to cite this article
V.A.J. Adekunle, 2007. Non-Linear Regression Models for Timber Volume Estimation in Natural Forest Ecosystem, Southwest Nigeria. Research Journal of Forestry, 1: 40-54.
URL: https://scialert.net/abstract/?doi=rjf.2007.40.54
URL: https://scialert.net/abstract/?doi=rjf.2007.40.54
INTRODUCTION
The main reason for conducting forest inventory either in the plantations or natural forest ecosystem is to estimate timber volume of the plots installed in the entire stand. The timber volume in a plot is the sum of the volumes of the trees within it. During forest inventory especially in the tropical natural forest ecosystem characterized by dense canopy closure, lianas and thickets, it is practically difficult, inefficient and costly to measure all predictor variables for every tree in each plot. To overcome this problem, the use of volume equation with dbh (diameter at breast height) and h (tree height - total or merchantable height) as predictor variables is developed. This is possible because tree stem volume is a function of dbh, height and form i.e., v = f (dbh, h, f). Secondly, volume is linearly related to tree dbh or basal area. This relationship has also been observed to be curvilinear (Akindele and LeMay, 2006).
While dbh could be obtained at little expense in almost any forest type, height measurements are considerable more expensive to collect. Riesco and Diaz-Maroto (2004) reported that measurement of height in all tall dense stands can be very difficult. Therefore plot volumes are generally obtained by measuring all trees in the sample plots for dbh and sub samples for height and other variables needed to compute volume with Newton’s formula of Husch et al. (2003) like diameter of tree at the base, middle and top. The relationship between volume and dbh can now be expressed in mathematically using regression analysis. After estimating the regression coefficients from the sample tree data, volume of other trees in the stand can be estimated by substituting their respective predictor variable in the equation.
Generally, models in forestry constitute recruitment, growth and mortality models. They have been traditionally classified as stand models, individual tree models and stand or diameter class models (Misir, 2003). Individual tree models are further classified as distance-dependent (spatial) or distance-independence (non-spatial) models. Spatial models include a spatial competition measure, which is often expressed as a function of the distance between the subject tree and its neighbours (Misir et al., 2004). Non-spatial models do not use spatial information to express competition but they use predictors (e.g., stand basal area, mean dbh) that are measures of stand density (Vanclay, 1994; Van Laar and Akca, 1997; Misir et al., 2004). Stand models are very useful in estimating growth and yield of any stand and also for projecting values of other parameters like basal area, mean dbh, height and number of trees per hectare.
The roles of models in tree volume estimation especially in tropical natural forest ecosystem cannot be overestimated. Models are veritable tools for effective management of any forest stand. Models in forestry are tools for providing long-term decision-making in forest management, estimation of growing stock, timber valuation and allocation of forest areas for harvest. Unfortunately models for yield estimation in tropical natural forest ecosystem are very scarce today because of the complexities and heterogeneity of the ecosystem. The types of models that can be used in natural forest ecosystem to estimate yield where age of trees cannot be determined are very limited. Authors who have constructed yield models for natural forest surrogate age with diameter or basal area. Although some ecologists have criticized this approach, but studies of some herbaceous and woody perennials have shown that plant size as measured by height was good enough as predictor of reproductive performance. Saksa et al. (1995) and Laiho et al. (1995) reported that size variation of trees could be estimated from heights or more commonly from diameter because the age distribution of trees is hardly ever known in natural forest stands. The growth of trees has also been reported to depend more on size than age (Sarvas, 1951; Vaartaja, 1951).
FORMECU (1997) developed some linear regression equations for Nigeria natural forest data. All the species encountered were classified into eleven groups with k-cluster algorithm. Four sets of logarithm-transformed models were tried with volume as dependent variable and basal area and height as independent variables for each group and all species together. Osho (1988) used population growth matrix and successional markov models for his study at Idanre forest reserve by replacing age with diameter. Moser and Hall (1969) applied the differential equation technique to uneven-aged hardwood stands by deriving time-dependent non-linear yield models that did not have age as an independent variable. Ek and Monserud (1974) models were one of the first spatial models for mixed forest. Their models used height rather than diameter as independent variable (Vanclay, 1994).
The main objective of this study is to develop volume models for tropical natural forest ecosystem in southwest Nigeria using some non-linear models and also to assess the diversity of tree species in the ecosystem. According to Avery and Burkhart (2002), volume equations can be used to estimate the average content of standing trees of various sizes and species. Akindele and LeMay (2006) reported that growing stock in forestry is usually expressed in terms of timber volume and the most common procedure of obtaining this is the use of volume equation based on relationship between volume and variables such as diameter and height.
MATERIALS AND METHODS
Study Area
The study area is the tropical rainforest ecosystem of southwest Nigeria. This ecological zone forms a continuous belt around the world between latitude 24°S and 24°N and longitude 10°E and 20°W. In southwest Nigeria, it is located a few kilometers inland along the coast and forms a continuous strip of green belt separating the coastal vegetation from the derived and Guinea savanna vegetation. Two forest reserves were randomly selected for data collection. The reserves are Omo and Ala forest reserves in Ogun and Ondo States of southwest Nigeria, respectively. Even though these forest reserves fall within two States, yet they are within the same ecological zone; the State boundaries being merely administrative/political boundaries. It is common knowledge that vegetation zones (being natural phenomenon) transcend political boundaries. The first reserve (Omo forest reserve) is located in area J4, Ijebu East Local Government Area of Ogun State, Nigeria on latitude 6°50’N and longitude 4°22’ E. It covers an area of 460 km2. The second one (Ala forest reserve) is located in Akure North Local Government Area of Ondo State, Nigeria. It lies between latitude 7°N and 6°45"N and longitude 5°E and 5°10"E. It is 166 km2 in size.
Method of Data Collection
The sampling technique adopted for plot location in each of the two sites was systematic cluster sampling. 1000x200 m (20 ha)-land area referred to as cluster was centrally located and divided into two tracts of 600 m apart. This was further divided into plots of equal size (50x50 m or 0.25 ha). Four plots were therefore selected at the end of southwest and southeast corners of each tract as shown in Fig. 1 (FORMECU, 1997). The following tree data were collected in each sample plot: dbh (stem diameter at a position of 1.3 m above the ground level), diameters over bark at the base, middle and merchantable top, total height using Spiegel relaskop and dominant height (i.e., height of four largest trees in a plot representing 100 largest trees per hectare).
Data Analysis
Basal Area Calculation
The basal area of all trees in the sample plots was calculated using the formula:
BA = (π D2)/4 |
Where:
| = | Basal area (m2) | |
| D | = | Diameter at breast height (cm) |
| π | = | Pie (3.142) |
The total BA for each plot was obtained by adding all trees BA in the plot. Mean BA for the plot was calculated with the formula:
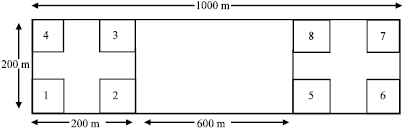 | |
| Fig. 1: | Systematic cluster sampling technique adopted for sample plot location (plot size = 50x50 m) |
Where:
| = | Mean Basal area per plot | |
| n | = | Number of plots or sampling unit. |
Basal area per hectare was obtained by multiplying mean basal area per plot with number of plots in a hectare (4 plots)
Volume Calculation
The volume of each tree was calculated in every plot using the Newton’s formula of Husch et al. (2003):
V = (h/6) ( Ab + 4 Am + At). |
Where:
| V | = | Tree volume ( in m3), |
| Ab, Am, At | = | Tree cross-sectional area at the base, middle and top of merchantable height, respectively (in m2) h = Total height (in meters) |
The plot volumes were obtained by adding the volumes of all the trees in the plot (Vp) while mean plot volume was estimated by dividing the total plot volume by number of sample plots. Mean volume for the sample plots was calculated:
The volume of trees per hectare (Vha) was subsequently estimated by multiplying this mean by the number of sampling units in a hectare (4).
Confidence limit (Upper and Lower values): This is the range of values within which one might expect to find the parameter with same degree of assurance and is estimated as:
CL = Estimate (Volume/ha) ± tα/2(SE) |
Where, SE is the standard error of estimate and is obtained as:
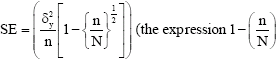 |
is the finite population correction factor and δy2 is the estimated variance of individual value of y and is given as:
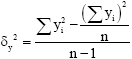 |
n is the number of sampling units (plots) used while N is the total number of plots (total population), tα/2 is Student t-test value at 0.025 level. Students’t-test is a value establishing a level of probability and the value was obtained from statistical table.
Correlation Coefficient Calculation
Pairing of the growth parameters to examine the type of linear relationship between them was carried out with spearman correlation.
Volume Model Generation
For the purpose of modeling, individual tree growth variables across all sample plots in each of the two sites were used. The tree growth variables from both sites were also pooled together to generate models that could be used for volume estimation in tropical rainforest ecosystem of southwest Nigeria and in other places with similar vegetation and environmental factors. The Von Betalanffys growth model adopted by Richard (1959) and Chapman (1961) termed as Chapman-Richard growth model was modified and used in this study. The original model is of the form:
V = a{1-e-bA}(1-c)-1 |
This original model was modified and age was replaced with basal area. This is because tree age is very difficult to determine in natural forests. So the non-linear models adopted in this study are:
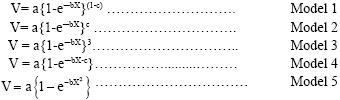 |
Where:
| A | = | The original model is Age a, b |
| c | = | Regression constants to be estimated |
| e | = | The exponential constant (Euler’s value = 2.71) |
| X | = | Basal area (m2) |
| V | = | Tree volume (m3). |
All these models are intrinsically nonlinear regression models. In order to estimate the parameters (regression constants a, b and c) of the function, the nonlinear estimation module of Statistica software using the user-defined option and a non-linear least square estimation procedure was adopted (Statistica, 1995). This was with the aim of minimizing the sum of squared deviations of the observed values for the dependent variable from those predicted by the models.
Assessment of the Models
The volume models were assessed with the view of recommending those with good fit for further uses. The following statistical criteria were used:
Significance of Regression (F-ratio)
This is to test the overall significance of the regression equations. The critical value of F (i.e., F-tabulated) at p<0.05 level of significance was compared with the F-ratio (F-calculated). Where the variance ratio (F-calculated) is greater than the critical values (F-tabulated) such equation is therefore significant and can be accepted for prediction.
Multiple Correlation Coefficient (R)
This measures the degree of association between two variables i.e., Y- dependent variable and X- independent variable (Mead et al., 1994). The R-value must be high (>0.50) for models to have good fit.
Coefficient of Determination (R2)
This is the measure of the proportion of variation in the dependent variable that is explained by the behaviour of the independent variable (Thomas, 1977). For the model to be accepted, the R2 value must be high (>50%). Other criteria used include Bias (Error) and Mean Square Error (MSE). These values must be relatively small for the models to be valid.
Validation of the Models
This was achieved by comparing the models’ output with values observed on the field. The validation process examines the usefulness or validity of the models (Marshall and Northway, 1993). The entire field data were divided into two sets. The first set (calibrating set), comprised tree data from 194 trees in Ala, 149 trees in Omo forest reserves and 338 trees when data from both reserves were pooled. These were used for generating the models. The second set (validating set) comprised tree data from 40 trees in Ala, 39 trees in Omo and 83 trees for both reserves. These were used for validating the models (Cooper and Weekes, 1983). The models outputs were individually compared with observed values using simple linear regression equation. The observed volume was the dependent variable while the models output was the independent variable. For models with good fit, the intercept must be close to 0 and the slope close to 1, the model must be significant, with highly correlated, coefficient of determination value must be very high and the standard of error of estimate must be small values (Onyekwelu and Akindele, 1995; Adekunle et al., 2004). Residual plots and frequency distribution of residuals for the models that involved data from both reserves were also obtained to further confirm the usefulness and suitability of the models for tree volume estimation. One-way Analysis of Variance (ANOVA) was also adopted to test for the presence of significant differences in the models output and where significant difference occurred, mean separation was done with fishers Least Significant Difference (LSD).
Percentage Bias Estimation
The absolute percentage difference (% bias) was determined by dividing the difference between volumes obtained with Newtons formula (observed volume) and models output by the same observed volume and multiplied by 100.
Where:
| Vo | = | The observed volume |
| Vp | = | The predicted volume (models output). |
The value must be relatively small for the model to be acceptable for management purpose.
RESULTS
The species and family names of trees encountered in the sample plots with their respective relative abundance are shown in Table 1. Table 2 shows the various families and number of species in each of the families. On the whole, 61 Nigerian tropical tree species distributed among 24 families and 421 individuals were present in the study areas as represented by the sample plots. The most abundance species is Strombosia pustulata. This is followed by Cordia milenii. These species have 49 and 36 individual trees, respectively. The family with the highest number of species is Sterculiaceae (7 species). This is followed by Moraceae and Caesalpiniodeae with six species each. The family, Leguminosae, is a large family with three sub-families namely Caesalpiniodeae, Mimosoideae and Papilionoideae. The number of species in these sub-families is 6, 4 and 2, respectively. The summary of tree growth variables obtained for Ala, Omo and when data from the two reserves were pooled together is shown in Table 3. Table 4 reveals the results of the descriptive statistics of dbh and heights for all the trees.
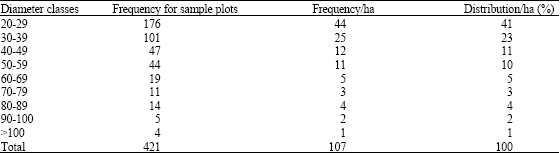
Generally, higher values were recorded for Ala forest reserve when compared with Omo forest reserve. The mean dbh and height is 39.12 cm and 18.37 m for Ala and Omo forest reserves, respectively, the volume and basal area per hectare is 16.06 and 129.01 m3, respectively. The maximum dbh of tree is 200 cm and that of height is 36 m with a range of 180 for dbh and 31.7 for height. For diameter distribution, highest proportion (41%) of the trees per hectare belong to the least dbh class (20-29 cm) while only 1% were found to be greater than 100 cm (Table 5).
Correlation Coefficient of the Various Growth Parameters
There is generally more positive linear relationship between the variables. The highest correlation coefficient value was obtained between the square of basal area and volume (0.843) and negative but high correlation exists between dominant height and logarithm of mean diameter (-0.82).
| Table 1: | Species encountered in the study area and their relative abundance in sample plots |
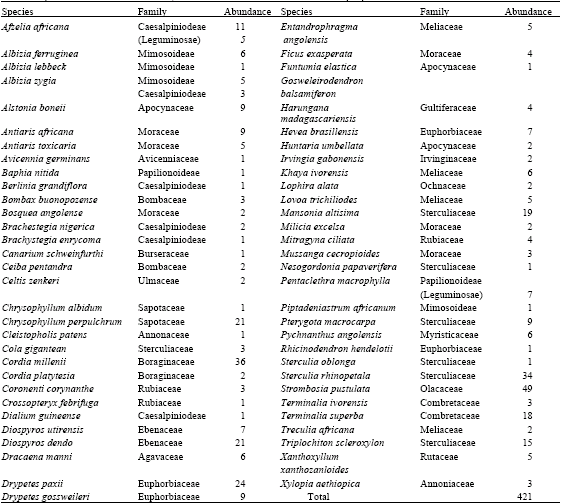 | |
| Table 2: | Tree species distribution into families in the study area |
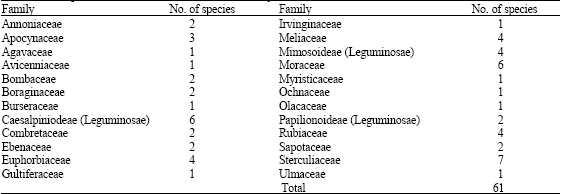 | |
| Table 3: | Tree growth variables in Ala and Omo Forest Reserves |
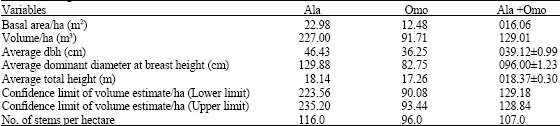 | |
| Table 4: | Descriptive statistics of dbh (cm) and total height (m) for all trees in the study areas |
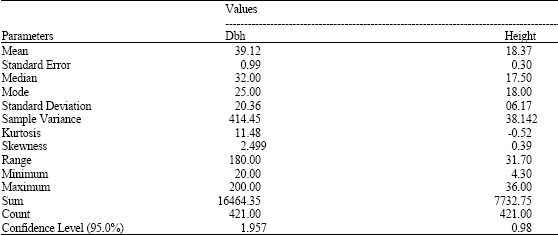 | |
| Table 5: | Diameter distribution into diameter classes in the study areas |
 | |
The value (0.77) obtained between basal area and volume is also very high and positive. Very weak correlation was observed to exist between number of stem/ha and all the other tree growth variables. This could be attributed to the fact that number of trees, in actual sense, is not necessarily a tree growth variable (Table 6).
| Table 6: | Correlation matrix for tree growth variables in the study area |
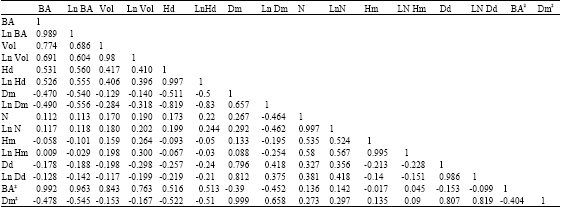 | |
| BA = Basal area/ha (m2), Vol = Volume/ha (m3), Hd = Dominant height (m), Dm = Mean dbh (cm), N = Number of stems/ha, Hm = Mean total height (m), Dd = Dominant dbh (cm), Ln = Natural logarithm | |
Result of the Non-Linear Models
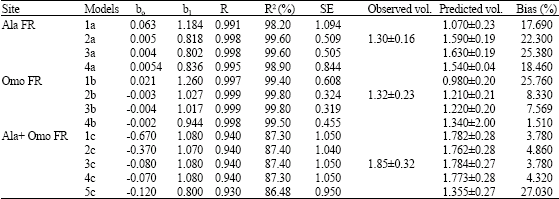
The results of the non-linear models with their assessment criteria are presented as follows for Ala Forest Reserve:
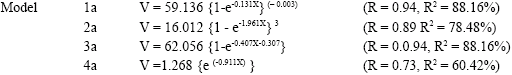 |
The results of the non linear models with their assessment criteria for Omo Forest Reserve are presented as follows:
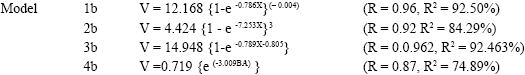 |
The results of the non-linear regression models for tree volume estimation when data from both forest reserves were combined are:
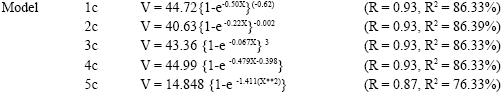 |
Exponential model was also used to generate tree volume equation for the study area with dominant height (Hd) in meter as independent variable. The equation obtained is:
All the non-linear models were discovered to have good fit and as a result, they are very adequate for tree volume estimation even when age was surrogated with basal area as the independent variable. This is because of the high correlation coefficient (R) and coefficient of variation (R2) values, small standard error of estimate and significant f-ratio (p<0.05). The R-values ranged between 0.73 and 0.94 for the non-linear regression models 1a to 4a generated for Ala Forest Reserve. The R2 values for the models in this reserve (Ala) are 88.162, 78.48, 88.16 and 60.42% for models 1a, 2a, 3a and 4a, respectively. In Omo Forest Reserve, the R and the R2 values obtained are 0.962 and 93%, respectively for model 1b, 0.918 and 84% for model 2b, 0.962 and 92% for model 3b and 0.865 and 75% for model 4b. The results of the correlation coefficient when data from the two reserves were pooled together were 0.93 for models 1c to 4c and 0.87 for model 5c. The coefficient of determination (R2) value is about 83% for models 1c to 4c and 76% for model 5c. Exponential model obtained with dominant height as independent variable has a small R2 (22.313%) and R-value (0.473).
The mean predicted volume (models’ outputs) obtained by substituting the validating set into the equations is shown in Table 7. Table 8 shows that all the models have good fit. This is because the intercept coefficients (bo) are close to zero while the slope coefficients (b1) are close to one, the correlation coefficients (R) and coefficient of determination (R2) are very high, the standard error of estimates are very small and all the equations are significant (F<0.05).
Generally, the percentage biases when the output of each model was compared with the observed volume are very small (less than 30%) for all the models. The values in Ala forest reserve are 17.69% for model 1a, 22.30% for model 2a, 25.38% for model 3a and 18.46% for model 4a. For Omo forest reserve, the percentage biases are 25.76, 8.33, 5.57 and 1.51% for models 1b, 2b, 3b and 4b, respectively. For the combined data, the percentage biases are 3.78% for model 1c, 4.86% for model 2c, 3.78% for model 3c, 4.32% for model 4c and 27.03% for model 5c. The results of the one-way analysis of variance show that there were no significant differences (p>0.05) in the models output (Table 9). But the results of the assessment and validation reveal that models 1a and 1b are the best for Ala and Omo forest reserves respectively and model 3c for the two reserves together. The fitness and validity of all these models were further confirmed by obtaining the residual plots (i.e., residual values against predicted volume). Figure 2-6 represented residual plots for models 1c to 5c, respectively.
| Table 7: | Mean observed volume and models outputs |
 | |
| *: n = 40 (± Standard error) **: n = 39 ***: n = 83 (± Standard error) | |
| Table 8: | Validation results and % bias of the non-linear models with simple linear regression model |
 | |
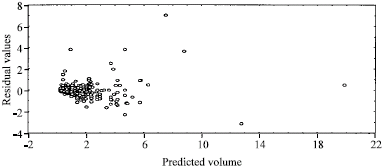 | |
| Fig. 2: | Residual plot of model 1 for the study area |
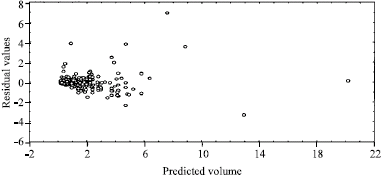 | |
| Fig. 3: | Residual plot of model 2 for the study area |
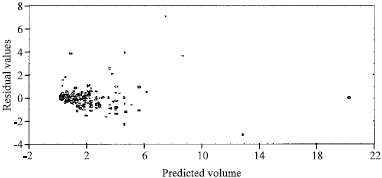 | |
| Fig. 4: | Residual plot of model 3 for the study area |
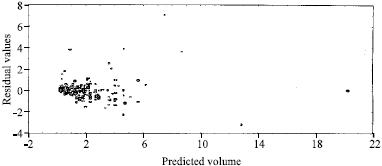 | |
| Fig. 5: | Residual plot of model 4 for the study area |
 | |
| Fig. 6: | Residual plot of model 5 for the study area |
| Table 9: | ANOVA table showing the level of significant differences between observed volume and models outputs |
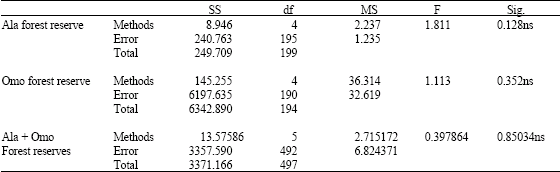 | |
| ns: No significant difference (p≥0.05) in the tree volume non-linear models | |
DISCUSSION
Tree species diversity obtained in this study area is typical of tropical rainforest ecosystem. Sixty-one Nigerian tropical timber species distributed among 24 families were encountered. This ecosystem has been adjudged the richest single ecosystem of the world due to species richness and diversity (Adekunle, 2002 and 2006). Species in this ecosystem are very useful as timber, enrichment of soil fertility, creation of microclimate and the supply of many non timber forest products. Tree species in the three sub-families under Leguminosae also encountered are noted for their ability to fix nitrogen thereby increasing soil fertility. The number of individual observation per species is generally low. About 15 of the tree species occurred only once (i.e., n = 1) and nine species have n = 5. This finding is similar to the observation of Akindele and LeMay (2006). Clark and Clark (1999) noted that in spite of the high level of tree species diversity in tropical natural forest, most tree species are generally few. For tree growth variables, the mean dbh value was 39.12 cm for the forest stands (Table 3). This shows that most of the trees in these forest reserves are below the minimum merchantable size of 48 cm stipulated by logging policy of southwestern Nigeria. The basal area per hectare in each of the forest reserves is also less than 24 m2 prescribed for a well stocked forest (Alder and Abayomi, 1994). The commonest diameter at breast height and height are 25 cm and 18 m, respectively. But in an even-age forest stand, dbh distributions usually follow a normal distribution. There is a wide range in diameter distribution (180 cm) and the skewness and kurtosis values for the dbh distribution are 2.50 and 11.64, respectively.
The efficacy of non-linear models for estimating volume in tropical rainforest ecosystem was obtained in this study. Generation of the non linear models involved the specification of the non linear functions and a loss function. The specified values of the loss function were computed for each case in the data set. This estimation procedure found parameters that minimize the sum of those values across all cases. The default loss function is the least square loss function which is expressed as L = (Obs-Pred)**2, where Obs and Pred are observed and predicted values respectively of the dependent variable in the non-linear function (Staistica, 1995). After specification of the functions, the quasi-Newton estimation method was selected for the iterations. The second order derivatives of the loss function were asymptotically estimated and used to determine the movement of parameters from iteration to iteration. At least thirty iterations were involved for model convergence.
The assessment criteria revealed that all the models are very suitable for tree volume estimation in natural forest ecosystem. These models were similar to those used by Adegbehin (1985) for Pinus caribaea, Eucalyptus cloeziana and E. tereticomis stands and Nokoe (1980) for some plantation species also. In their studies, age was used as independent variable while in this present study, age was surrogated with basal area. This is because the natural forest is composed of tree species of different ages (uneven-aged) and these ages are very difficult to determine. Laiho et al. (1995) noted that the age structure of an uneven-aged stand is highly heterogeneous and so its determination in practical forestry is not meaningful and also very rear on research plots. FORMECU (1997), Osho (1988) and Daniel et al. (1979) also replaced age with diameter during model generation in their studies. The indices of fit, which are the coefficient of multiple correlation and coefficient of determination (R and R2, respectively), for all these categories of models were very high. During validation with simple linear regression equations (comparison of models outputs with observed volume), the intercepts (bo) were very close to zero while the slope coefficients were very close to 1. Also, the index of fit, R and R2 values were high and significant F-ratio at p≤0.05 was obtained.
Avery and Burkhart (2002) reported that merchantable volume prediction usually gives negative intercept. This is in line with what was obtained for most of the models for validation in this study. The standard error of estimate is a good measure of overall predictive value of regression equations (Akindele and LeMay, 2006). It is also a common measure of goodness of fit in nonlinear regression models (Glantz and Slinker, 2001), with low values indicating better fit. In this study, the SE ranged between 0.91 for model 1a and 1.32 for model 4a, 0.82 for model 1b and 1.22 for model 4b and between 0.002 for model 2c and 0.29 for model 5c. Also, the percentage biases were relatively low for all these models. These results suggest that all these non linear models have good fit within the context of the field data used.
In view of the above, models 3a and 3b gave the best volume when compared with observed volume in Ala and Omo forest reserves respectively while model 3c ranked the best out of the five models generated when data from both reserves were combined. But the results of one way analysis of variance show that there was no significant difference (p>0.05) in the models’ outputs (Table 7). The residual plots (Fig. 2-6 for models 1c to 5c, respectively) generally indicate an even spread of residuals above and below the zero line with no systematic trend. The positive and negative sides of the plots have a constant breadth and are horizontal. The deviation of the predicted values from the observed values is random. This indicates that the assumption of normality in the distribution of residuals is not violated.
All the non-linear models developed in this study were discovered to be very adequate for yield estimation in lowland rainforest ecosystem and they are recommended for further use. Models with dominant height, as independent variable does not have good fit therefore, it was not adequate for yield prediction. This is because dominant height, as tree variable, does not affect other growth variables. Its use is often limited to site index determination in plantation species.
CONCLUSION
This study assessed tree species diversity and also tested the efficacy of nonlinear regression equations for tree volume estimation in tropical natural forest ecosystem. Four hundred and twenty one trees comprising 61 species distributed among 24 families were involved in model generation. The frequencies and yield predicted with the models are not significantly different from their observed values according to the validation results with ANOVA and simple linear regression equation. So, non-linear models are very suitable for yield estimation in tropical lowland rainforest ecosystem by replacing age in the original model with either dbh or basal area. Therefore all the categories of nonlinear models generated in this study are recommended for tree volume estimation in tropical natural forest ecosystem of southwest Nigeria and in any other similar ecosystem. Simulations involving nonlinear models are now facilitated and made easy by the availability of modern computer software that can handle complex mathematics.
ACKNOWLEDGMENT
I wish to thank the African Academy of Sciences (African Forest Research Network) Nairobi, Kenya, who provided the research grant used for this study under the Capacity Building for Forestry Research.
REFERENCES
- Adekunle, V.A.J., S.O. Akindele and J.A. Fuwape, 2004. Structure and yield models for tropical lowland rainforest ecosystem of South West Nigeria. Food. Agric. Environ., 2: 395-399.
Direct Link - Adekunle, V.A.J., 2006. Conservation of tree species diversity in tropical rainforest ecosystem of Southwest Nigeria. J. Trop. For. Sci. (Malaysia), 18: 91-101.
Direct Link - Akindele, S.O. and V.M. LeMay, 2006. Development of tree volume equations for common timber species in the tropical rain forest area of Nigeria. For. Ecol. Manage., 226: 41-48.
CrossRefDirect Link - Clark, D.A. and D.B. Clark, 1999. Assessing the growth of tropical rainforest trees: Issues for forest modeling and management. Ecol. Applied, 9: 981-997.
Direct Link - Husch, B., T.W. Beers and J.A. Kershaw Jr., 2003. Forest Mensuration. 4th Edn., Wiley, New Jersey, USA, ISBN: 978-0-471-01850-6, Pages: 456.
Direct Link - Misir, N., M. Misir and H. Yavuz, 2004. A yield prediction model for crimean pine plantations: The economics and management of high productivity plantations. Proceedings of the International IUFRO Meeting of the WP4.04.06 on Planning and Economics of Fast-Growing Plantation Forests, September 27-30, 2004, Lugo, Galicia, pp: 12.
- Moser, J.W. and J.B. Hall, 1969. Deriving growth and yield functions for uneven-aged forest stands. For. Sci., 15: 183-188.
Direct Link - Richard, F.J., 1959. A flexible growth function for empirical use. J. Exp. Biot., 10: 290-300.
CrossRefDirect Link - Riesco, M.G. and H.I.J. Diaz-Maroto, 2004. Variation with age-height diameter models in Pinus radiata (D. Don) in Galicia: The economics and management of high productivity plantations. Proceedings of the International IUFRO Meeting of the WP4.04.06 on Planning and Economics of Fast-Growing Plantation Forests, September 27-30, 2004, Lugo, Galicia, pp: 12.
Egbewole zaccheaus Tunde Reply
The write up is good, it has a lot to contribute to the body of knowledge