
Zahida Akhtar
Department of Computer Science, Faculty of Basic and Applied Sciences, International Islamic University Islamabad, Pakistan
Information Technology Journal
Year: 2007 | Volume: 6 | Issue: 7 | Page No.: 978-986







ABSTRACT
Gird computing is an emerging science in the field of distributed computing which involves coordinating and sharing computing, application, data, storage, or network resources across dynamic and geographically dispersed organizations. Scheduling and load balancing techniques are critical issues in grid computing for achieving good performance. The goal of load balancing is to minimize the response and execution time of a program by trying to equally spread the load on processors and maximizing their utilization. It has been proven that finding optimal schedules for the load-balancing problem is an NP-complete problem, even when the communication cost is ignorable. Genetic algorithms are a probabilistic search approach, which are founded on the ideas of evolutionary processes. They are particularly applicable to problems that are large, non-linear and possibly discrete in nature; features that traditionally add to the degree of complexity of solution. Present research aims to solve the grid load-balancing problem using Genetic Algorithms. A new Genetic Algorithm based task scheduling technique is introduced, which has been tested on a multi-node grid environment and the experimental results show that this new technique can lead to significant performance gain in various applications.
PDF Abstract XML References Citation
How to cite this article
Zahida Akhtar, 2007. Genetic Load and Time Prediction Technique for Dynamic Load Balancing in Grid Computing. Information Technology Journal, 6: 978-986.
DOI: 10.3923/itj.2007.978.986
URL: https://scialert.net/abstract/?doi=itj.2007.978.986
DOI: 10.3923/itj.2007.978.986
URL: https://scialert.net/abstract/?doi=itj.2007.978.986
INTRODUCTION
Grid computing, as defined by its founders, has emerged as an important new field, distinguished from conventional distributed computing by its focus on large-scale resource sharing, innovative applications and, in some cases, high-performance orientation (Foster et al., 2001).
Grid computing is a new technology that transforms a computer infrastructure into an integrated, pervasive virtual environment for dynamic collaboration and shared resources anywhere in the world providing users, especially in science, with unprecedented computing power, services and information (Reddy, 2004). With the advance in technologies, the cost of computation resources required per operation is continuously decreasing. Grid computing is one of many factors which enable the effective use of wide spread computing resources thereby providing non-trivial services to users. According to the Department of Computer Science at the University of Warwick, with the emergence of grid environments featuring dynamic resources and varying user profiles, there is an increasing need to develop reliable tools that can effectively coordinate the requirements of an application with available computing resources. The ability to predict the behaviour of complex aggregated systems under dynamically changing workloads is particularly desirable, leading to effective resource usage and optimization of networked systems.
Scheduling and load balancing techniques are critical issues in grid computing for achieving optimum performance. The goal of load balancing is to minimize the response and execution time of a program by trying to equally spread the load on processors and maximizing their utilization. Present research aims to solve the grid load-balancing problem using Genetic Algorithms.
Genetic algorithms are based on a biological metaphor: They view learning as a competition among a population of evolving candidate problem solutions. A ’fitness’ function evaluates each solution to decide whether it will contribute to the next generation of solutions. Then, through operations analogous to gene transfer in sexual reproduction, the algorithm creates a new population of candidate solutions (Melanie, 1999; Koza, 1990; Goldberg, 1989; Vose, 1999; Rennard, 2000). Genetic Algorithms are nondeterministic stochastic search/optimization methods that utilize the theories of evolution and natural selection to solve a problem within a complex solution space. They are computer-based problem solving systems which use computational models of some of the known mechanisms in evolution as key elements in their design and implementation (Sandikci, 2000).
BASIC CONCEPT
Recent research studies indicate that genetic algorithms significantly enhance the performance of real time applications. In one such study done by Wu and Chau (2006), authors employ the hybrid genetic algorithm based artificial neural network model for flood prediction. The proposed model is tested against empirical linear regression model, conventional ANN model and a GA model and results reveals that proposed hybrid GA-based ANN algorithm outperforms the conventional models. The limiting factor of this research study is that it requires additional modelling parameters and longer computation time.
In another study, Chau and Albermani (2003) develop the prototype system by coupling the blackboard architecture, an expert system shell VISUAL RULE STUDIO and Genetic Algorithm (GA). Chau and Albermani (2003) proposed the said system for the optimize design of liquid retaining structures which can act as a consultant to assist novice designers in the design of liquid retaining structures. Near-optimal solutions are claimed to be achieved after exploration of small portion of search space at extraordinarily converging speed.
Another example of genetic algorithm in a real time application is, Usage of parallel genetic algorithm for multiple criteria rainfallBrunoff model calibration which is proposed by (Cheng et al., 2005). The method uses the fuzzy optimal model to evaluate multiple alternatives with multiple criteria where chromosomes are the alternatives, whilst the criteria are flood performance measures Cheng et al. ( 2005). The proposed approach produces the similar results when compared with results obtained by using a two-stage calibration procedure but it significantly reduces the overall optimization time and improves the solution quality. The disadvantage of this research study is that it splits the whole procedure into two parts which makes it difficult to integrally grasp the best behaviours of model during the calibration procedure. In Continuation to study Cheng et al. (2005 and 2006) proposed a new method to the multiple criteria parameter calibration problem, which combines GA with TOPSIS for Xinanjiang model. Cheng et al. (2006) removes the disadvantage of their previous research study and integrates the two parts of Xinanjiang rainfall-runoff model calibration together thus simplifying the procedures of model calibration and validation. Comparison of results with two-step procedure shows that the proposed methodology gives similar results to the previous method, is also feasible and robust, but simpler and easier to apply in practice.
In another study, Chau (2004) proposed a two-stage dynamic model to assist construction planners to formulate the optimal strategy for establishing potential intermediate transfer centers for site-level facilities such as batch plants, lay-down yards, receiving warehouses, various workshops, etc. Under the proposed approach, the solution of the problem is split into two stages, namely, a lower-level stage and an upper-level stage. Standard linear programming method is used to solve former stage whereas the latter is solved by a genetic algorithm. The efficiency of the proposed algorithm is demonstrated through case examples.
In this research study the problem area has been described, which is mostly based on the description of Dong and Akl (2006). While different approaches have used GAs for solving load balancing problems yet the issues that remain to be addressed can be broadly categorized as the following:
| • | The execution time for load balancing has not been considered or has not been quantitatively described. |
| • | Most of the algorithms are restricted to static load balancing and as such require prior knowledge of various parameters. While this approach may work in problems of equivalent nature but cannot be broadly applied to different applications. |
| • | A few dynamic load balancing algorithms that have been studied and are also mentioned in the literature review have not been implemented in loosely coupled systems such as grid computing. |
| • | To the best of the author, s knowledge, no algorithm has been designed to prevent resubmission in case of load failure. The algorithms that incorporate fault tolerance use a simple strategy for restarting the task which in some cases requires extensive overheads. |
Efficient execution in a distributed system can require, in the general case, mechanisms for the discovery of available resources, the selection of an application-appropriate subset of those resources and the mapping of data or tasks onto selected resources.
Grid computing has become an increasingly popular solution to optimize resource allocation in highly charged IT environments. In one of the recent research studies done by Wieczorek et al. (2005) three different algorithms (namely HEFT, Genetic and simple Myopic algorithm) are compared in terms of incremental versus full-graph scheduling for balanced versus unbalanced workflows.
Without considering effect of the typical network scenarios Wieczorek et al. (2005) declare HEFT as better algorithm. A multi-tiered framework based on, Globus providers, distribution brokers and local schedulers is used for grid work load management, out of which only lowest tier is primary focused by Spooner et al. (2003). Spooner and his colleague use iterative heuristic algorithm and performance prediction techniques for performance based upon global and local scheduling. The future work of Spooner et al. (2003 ) for examining the other two upper tiers is still on its way. Cao et al. (2005) addresses grid load balancing issues using a combination of intelligent agents and multi-agent approaches. The experimental result of research study of Cao et al. (2005) proves that the use of a distributed agent strategy can reduce the network overhead significantly and make the system scale well??? rather than using a centralized control, as well as achieving a reasonable good resource utilization and meeting application execution deadlines. Abraham et al. (2000) addressed the hybridization of the three popular nature, s heuristics namely Genetic Algorithms (GA), Simulated Annealing (SA) and Tabu Search (TS) for dynamic job scheduling on large-scale distributed systems but did not provide any experimental results for research evaluation. A novel mapping heuristic based on the Cross-Entropy (CE) method, for mapping a set of interacting tasks of a parallel application onto a heterogeneous computing platform, was proposed by Sanyal and Das (2005).
According to their research studies, Cross Entropy methods are inherently slow and this slowness of the CE based methods in generating the appropriate mapping can decrease the performance gain for a large set of tasks. Moreno (2003) proposed new rescheduling policies for job migration under cost constraints after analysing the main tasks that the grid resource broker has to tackle (like resource discovery and selection, job scheduling, job monitoring and migration etc.) in detail. Wagner and Affenzeller (2004) present a new environment for parallel heuristic optimization based upon the already proposed Heuristic-Lab in.
A Formal model which allows multiple schedule optimizations and a new efficient heuristic approach based on genetic algorithms and list scheduling is presented by Grajcar (2000). In spite of the fact that the algorithm contains some programming inefficiencies, it still performs well in terms of running speed and result quality. Zomaya and The (2001) investigate how a genetic algorithm can be employed to solve the dynamic load balancing problem. The dynamic load-balancing algorithm is developed by Zomaya and The (2001) whereby optimal or near-optimal task allocations can “evolve” during the operation of the parallel computing system. A scheduling routine based upon a genetic algorithm is developed (Greene, 2001) which is claimed to be very effective and has relatively low cost. Two important aspects of this research study are: loads on the processors are well balanced and scheduling per se remains cheap in comparison to the actual productive work of the processors. Dynamic Distributed Genetic Algorithm is proposed by Yi et al. (2000). According to the paper, dynamic distributed GA with directed migration has great potential to overcome premature convergence.
The contribution of Song et al. (2005) is two-fold: first the Min-Min and Sufferage heuristics are enhanced under three risk modes driven by security concerns and secondly a new Space-Time Genetic Algorithm for trusted job scheduling is proposed. The results of Song et al. (2005) shows that there is a need of more research study in order to over come the shortcoming of security driven Min-Min and Sufferage heuristics which are unstable when applied to different types of workloads. A novel GA-based approach is proposed by Kim and Weissman (2004) to address the problem of scheduling a divisible Data Grid application while considering communication and computation at the same time in wide area data intensive environment. According to Kim and Weissman (2004) the results from the experiments on GA-related parameters suggest that the initialization of population with chromosomes of good quality is critical to GA-based approach in terms of the quality of solution and the convergence rate. But the problem of multiple jobs competing for shared resources has not been overcome in this study. Five heuristics that have been designed, developed and simulated using the HC environment, are presented by Shivle et al. (2005). Application tasks are composed of communicating subtasks with data dependencies and multiple versions were mapped using the heuristics described by Shivle et al. (2005) and the results can be used in the development of ad hoc grids.
The EVOLVE/G system, which is a Grid tool for developer of evolutionary computation, is proposed by Tanimura et al. (2002). This system consists of an Agent and multiple workers. Since the data can be exchanged between the Agent and Workers freely, any logical models of EC can be integrated. Jing et al. (2004) describes a parallel hybrid-GA (PHGA) for combinatorial optimization using an island model running in a networked computing environment. Jing et al. (2004) opens several issues for future research like extensive study on scalability of parallel GA in a distributed computing framework. Applicability of parallelizing the local search of a serial GA and other heuristics for local search can be explored to enhance the performance of the parallel GA. Cao et al. (2003) developed a GA-based scheduler for fine-grained load balancing at the local level, which was then coupled with an agent-based mechanism that was applied to load balance at a higher level. Future enhancement to the system will include the integration with other grid toolkits (e.g., Globus MDS and NWS).
MATERIALS AND METHODS
In this research work an attempt has been made to increase the efficiency of grid scheduler. GAs based scheduling algorithm named Dynamic Online Scheduling is proposed for better resource optimization and task scheduling. The scheduling process in this algorithm is addressed in two layers namely pre- scheduling and post-scheduling. The newly coming problems from outside grid boundary are scheduled in the first layer which is pre-scheduling. In post- scheduling the load balancing of the already submitted tasks is done, that is if a certain resource is found overloaded with work while some other resources are free then some of the jobs of the overloaded machine are automatically shifted to the free machines while keeping in mind the robustness, reliability and efficiency of the job as well as the time cost, communication cost. Resource cost will also be considered.
Load and time prediction technique: The load on the resources and the execution time of the tasks both are interrelated and depend on each other. Every task has certain execution time and every task puts a certain amount of load on the machine it is executed on. We have developed a mechanism which on the basis of task attributes (e.g., size, type etc.) and resource attributes (e.g., memory, cpu cycles, load) tells the task execution time on that machine. This strategy gives us the advantage of dynamicity in the pool of heterogeneous resources as well as tasks, since both task and resource attributes are not assumed to be fixed. The load and time prediction strategy is based on historical data. Each resource is continuously monitored for its utilization and the data is entered into the log file. This log file helps us to set the threshold for our resources at any particular hour of day. The resource threshold is updated after each hour. At the same time an extensive amount tasks are executed on each resource and the resource utilization is calculated with each task and the log file logs that task = s attributes and resource utilization. After that, we rearrange the task log file according to the task attributes and time of the day they were submitted on. Then we give this data to the genetic algorithms to learn which resource is best suited for which kind of task at any particular given time of the day.
So far time prediction seems enough for load balancing since each task will be assigned on the basis of threshold plus the current situation of resource. But that, s not exactly what happens in the real world. When multiple tasks come the scheduler calculates the task execution time for each task with respect to the current situation of the available resources it is assigned to. Each task will definitely increase some amount of load on a resource. If multiple tasks are assigned to a resource then after one task starts running, the current situation of the resource will change but the scheduler predicts the task execution time according to the pervious resource situation that is before the execution of the previous task began. To cover up this flaw, we developed a Load Prediction strategy. This strategy is also based on history data but this data is required to be generated only once for each different set of attributes of task.
At this point it all seems static at compile time work while its not. Dynamicity comes when a new task arrives, GA scheduler become is activated and it retrieves the required task attributes, lists the currently available resources and predicts the execution time of the task for each resource on the basis of current resource parameters (e.g., memory, cpu cycles, load) or predicted parameters, task attributes and the history data from log file (that how much time the task of given attributes takes to execute with respect to the resource history parameters). The formula used by GAs to calculate the prediction time is explained in a later section.
Dynamic online scheduling: In dynamic online scheduling, scheduling is done on the basis of the current situation of the grid, which takes the current resources states/parameters from the resource collector and task list to be scheduled from the task collector and provides both lists to GA based scheduler as shown in Fig. 1. The Dynamic Online Scheduling procedure works in the following manner.
Pre-scheduling
| • | A list of available resources is generated on the basis of the current situation of resources as well as the history data about resources. |
| • | A list of tasks to be scheduled is generated from the task queue. |
| • | Both lists (Resource list and Task list) are provided to the GA based Analyzer and Load Balancer which will generate the optimized mapping of tasks to resources. |
| • | Mapping Engine assigns the tasks to resources. |
| • | Task Executer executes the task and displays the output. |
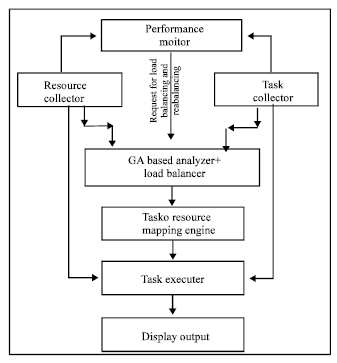 | |
| Fig. 1: | Dynamic online scheduling overview |
 | |
| Fig. 2: | Detailed internal architecture of online scheduling |
Post-scheduling
| • | Post scheduling algorithm becomes active when the performance monitor views that certain resources are being over utilized while some others are being under utilized. |
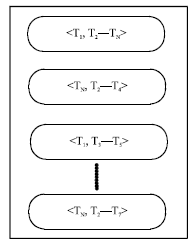 | |
| Fig. 3: | Chromosome representation |
The criteria for the measurement of the resource, s = overload (that is if whether a certain resource is overloaded or not) is its threshold limit.
| • | Each resource has been assigned a certain threshold on the basis of history data. |
| • | If certain resources are overloaded then the performance monitor comes into action. It will place the request to Load Balancer for redistribution of the tasks. |
| • | Load Balancer will activate the Resource Collector to provide the list of overloaded resources and under utilized resources and Task Collector to provide the Task list of overloaded resources. |
| • | Load Balancer will then generate the new mapping. |
Block diagram for pre and post scheduling has provided the detailed internal architecture of system as shown in Fig. 2.
Genetic algorithms for scheduling
Chromosome representation: For applying GAs directly or coupled with other meta-heuristics, problem (chromosome) representation is very important and it directly affects the performance of the proposed algorithm. The first decision a designer has to make is how to represent a solution in a chromosome. We assume that the Tasks and Resources are arranged in an ascending order according to the Task attributes (that is size, type, submission time) and Resource usage (that is least loaded comes first). Figure 3 depicts the chromosome representation which is used in our current strategy. Basically each chromosome in the population contains permutation of tasks and their fitness is calculated according to the resources they were assigned to. Task T1 is allocated to resource R1, T2 to R2 and T3 to R3 and so on. When T1 is completed, resource R1 is empty and task TN is allocated. This procedure goes on until all the tasks are allocated.
GA approach for task scheduling and load balancing
| • | Get the Task List from the Task Collector of length TNT where TNT is the total number of tasks to be scheduled. |
| • | Get the Resource List from the Resource Collector of length TNAR where TNAR is the total number of available resources, if no resource is available then wait until resources become available. |
| • | At t = 0; generate an initial population with P chromosomes Popi(t), where P represents the permutations of tasks and is calculated as: |
P = TNT P TNT |
| • | For each chromosome (I = 1 to P), first allocate the jobs to the available resources based on the FCFS basis. Then calculate the predicted time for each task according to the current parameters of the resource it is assigned to from the task history log. For example if one parameter of a resource say load is used then the task time prediction formula will be as follows: |
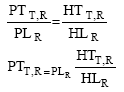 |
Where:
| PTT,R | = | Predicted completion time of task T on resource R |
| PLR | = | Present load on resource R for 1st task and Predicted Load for next assigning tasks (Each task will increase some load on the resource which will be calculated as predicted present load for next task) |
| HTT, R | = | History completion time for task T on resource R (taken from Task Log History). |
| HLR | = | History load on resource R when task T had completion time HTT, R. |
Now the predicted time for each task in the chromosome can be easily calculated using afore mentioned formula.
| • | Fitness value for each chromosome is calculated which will tell us the make-span of the schedule. Fitness value is calculated using following formula: |
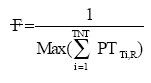 |
| • | The make-span of the schedule is calculated using following formula: |
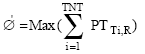 |
Where
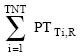 |
represents the total number of tasks assigned to resource R.
| • | Apply Crossover operator on the population according to the probability selected, Crospop(t+1) = recombined chromosomes of the population NewPopi (t+1); |
| • | Apply mutation operator on the population according to the probability selected, MutPop (t+1) = mutated population CrosPop (t+1). |
| • | Evaluate the fitness of each chromosome in the new population and check if the specified fitness value is achieved or not. If not, start the GAs loop again. |
| • | Send the specified schedule generated by GAs to the Mapping Engine which will assign the tasks to the resources. In case of post scheduling the Mapping Engine will migrate the tasks from the overloaded resources to relatively less loaded resources. |
RESULTS AND DISCUSSION
As a fundamental base, we have adopted OpenMosix as the resource monitoring and management tool. OpenMosix provides the update network weather service as well as logging the utilization information of each resource. A Task Management tool is developed which receives task from the users. GA scheduler works at the back end which takes tasks form task management tool and maps them to the available resources (List of available resources is provided by resource management tool i.e., OpenMosix) First we run bunches of tasks on limited resources (2-8 machines) without any involvement of GA scheduler and calculate the execution cost that is the total time it takes to complete all the assigned tasks on all machines and then we perform the same test using GA based scheduler and again calculate the execution cost. We calculate the execution cost for different sizes of schedules by slowly increasing the number of resources (5, 10, 15, 20, 25 and 30 number of machines) both with and without GA and the results shows that performance of system increases when GA base scheduler is used. Figure 4 shows the comparison results of system with proposed GA scheduler and without GA scheduler. Schedule Size vs. Make span is plotted in Fig. 4.
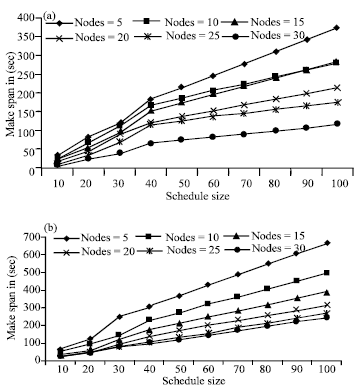 | |
| Fig. 4: | (a) System performance with GAs based scheduler schedule size vs. time (b) System performance without GAs based scheduler schedule size vs. time openmosix dynamic scheduler |
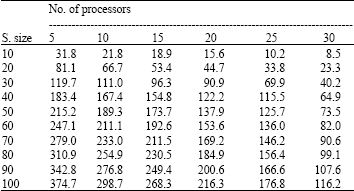
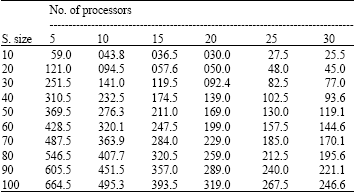
| Table 1: | Make span time in seconds generated by GA on different sizes of schedule and number of processors |
 | |
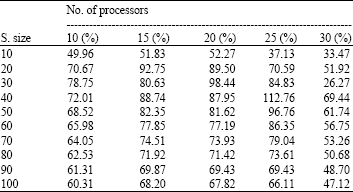
| Table 2: | Make span time in seconds generated by openmosix on different sets of schedule size and number of processors |
 | |
| Table 3: | Performance gain of Genetic algorithms based scheduler over openmosix schedulerf |
 | |
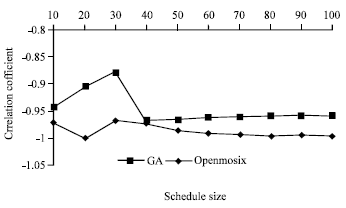 | |
| Fig. 5: | Correlation coefficient of GA scheduler and Openmosix scheduler |
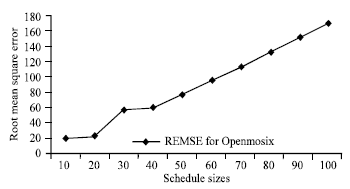 | |
| Fig. 6: | Root mean square error for Openmosix scheduler with respect to GA based for different schedule size |
Table 1 and 2 displays the detailed information of execution time of different sizes of schedules with respect to different number of resources generated by GA scheduler and Openmosix scheduler, respectively. Table 3 indicates the performance gain of GA scheduler over Openmosix scheduler for each set of schedules and resources.
In order to visualize the performance of system more clearly root mean square root error and correlation coefficient is calculated from the results generated by Openmosix scheduler and GA scheduler.
| Table 4: | Improvement in the Make span (Schedule Cost) after each 100 generations for different schedule sizes |
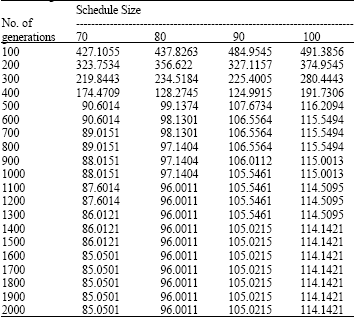 | |
Figure 5 shows the correlation coefficient series, for different sizes of schedules and number of resources, of both GA scheduler and Openmosix Scheduler and it can be clearly seen that GA scheduler is more correlated when we increase the schedule size over time than Openmosix scheduler.
Figure 6 displays the root mean square root error of Openmosix scheduler with respect to GA scheduler and the plot indicates that as the schedule size increases the error generated by Openmosix also increases.
Finer results are obtained when GAs is executed for another 1000-1500 generations but by increasing the number of generations performance gain due to GAs starts compromising in terms of scheduling cost so in order to obtain the best optimal result number of generations for GAs are set to fixed for 500. After running for 1500 generations the results appear more or less the same. Table 4 shows the improvement in Make span ? (schedule cost) after each 100 generations for different sizes of schedules.
CONCLUSIONS AND FUTURE WORK
In this research study we attempt to address the problem of load balancing in grid computing using one of the popular heuristics namely GAs. Genetic Algorithm predicts the execution time for each task with respect to the resource it is assigned to. The prediction time is based on the current attributes of task, current and historical parameters (like load, memory etc) of resources. We have tested this algorithm on a 30 machines heterogeneous grid environment with different schedule sizes and the results show that the proposed strategy can lead to the significant performance gain.
Future work will examine the application of proposed GA based algorithm as parallel genetic algorithms and dynamic distributed algorithms proposed by Yi et al. (2000). In both cases number and size of populations must be carefully determined. Even though significant progress has been made in modelling the infrastructure of grid computing but a close review clearly indicates that not much progress is made in formulating the efficient and globally optimized, grid-scheduling algorithm for allocating jobs (Abraham et al. 2000). Therefore we are planning to investigate this research area in depth using GAs as well as other heuristic algorithms.
REFERENCES
- Abraham, A., R. Buyya and B. Nath, 2000. Nature`s heuristics for scheduling jobs on computational grids. Proceedings of the 8th International Conference on Advanced, December 14-16, 2000, Cochin, India, pp: 1-8.
Direct Link - Cao, J., D.P. Spooner, S.A. Jarvis and G.R. Nudd, 2003. Agent-based grid load balancing using performance-driven task scheduling. Proceedings of the 17th IEEE International Parallel and Distributed Processing Symposium, April 22-26, 2003, Nice, France, pp: 10.
CrossRefDirect Link - Cheng, C.T., X.Y. Wu and K.W. Chau, 2005. Multiple criteria rainfall-runoff model calibration using a parallel genetic algorithm in a cluster of computers. Hydrol. Sci. J., 50: 1069-1087.
CrossRefDirect Link - Chau, K.W. and F. Albermani, 2003. Knowledge-based system on optimum design of liquid retaining structures with genetic algorithms. J. Struct. Eng. ASCE, 129: 1312-1321.
CrossRefDirect Link - Chau, K.W., 2004. A two-stage dynamic model on allocation of construction facilities with genetic algorithm. Autom. Constr., 13: 481-490.
CrossRefDirect Link - Cheng, C.T., M.Y. Zhao, K.W. Chau and X.Y. Wu, 2006. Using genetic algorithm and TOPSIS for Xinanjiang model calibration with a single procedure. J. Hydrol., 316: 129-140.
CrossRefDirect Link - Grajcar, M., 2000. Conditional scheduling for embedded systems using genetic list scheduling. Proceedings of the 13th International Symposium on System Synthesis, September 20-22, 2000 IEEE Computer Society, USA., pp: 123-128.
CrossRefDirect Link - Greene, W.A., 2001. Dynamic load balancing via a genetic algorithm. Proceedings of the 13th International Conference on Tools with Artificial Intelligence, November 7-9, 2001, IEEE Computer Society, USA., pp: 121-128.
CrossRefDirect Link - Kim, S. and J.B. Weissman, 2004. A GA-based approach for scheduling decomposable data grid applications. Proceedings of the International Conference on Parallel Processing, August 15-18, 2004, IEEE Computer Society, Washington DC., USA., pp: 406-413.
CrossRefDirect Link - Moreno, R.A., 2003. Job scheduling and resource management techniques in dynamic grid environments. Proceedings of the 1st European Across Grids Conference, February 13-14, 2003, Santiago de Compostela, Spain, pp: 1-4.
Direct Link - Sanyal, S. and S.K. Das, 2005. MaTCH: Mapping data-parallel tasks on a heterogeneous computing platforms using the cross-entropy heuristic. Proceedings of the 19th International Parallel and Distributed Processing Symposium, April 4-8, 2005, IEEE Computer Society, Washington DC., USA., pp: 64.
CrossRefDirect Link - Song, S., Y.K. Kwok and K. Hwang, 2005. Security-driven heuristics and A FAST genetic algorithm for trusted grid job scheduling. Proceedings of the 19th International Parallel and Distributed Processing Symposium, April 4-8, 2005, IEEE Computer Society, Washington DC, USA., pp: 65-65.
CrossRefDirect Link - Spooner, D.P., S.A. Jarvis, J. Cao, S. Saini and G.R. Nudd, 2003. Local grid scheduling techniques using performance prediction. IEE Proc. Comput. Digital Tech., 150: 87-96.
CrossRefDirect Link - Tanimura, Y., T. Hiroyasu, M. Miki and K. Aoi, 2002. The system for evolutionary computing on the computational grid. Proceedings of the Parallel and Distributed Computing and Systems, November 4-6, 2002, Cambridge, USA., pp: 1-7.
Direct Link - Wu, C.L. and K.W. Chau, 2006. A flood forecasting neural network model with genetic algorithm. Int. J. Environ. Pollut., 28: 261-273.
CrossRefDirect Link - Yi, W., Q. Liu and Y. He, 2000. Dynamic distributed genetic algorithms. Proceedings of the 2000 Congress on Evolutionary Computation, July 16-19, 2000, IEEE Press, California, USA., pp: 1132-1136.
CrossRefDirect Link - Zomaya, A.Y. and Y.H. Tan, 2001. The observations on using genetic algorithms for dynamic load balancing. IEEE Trans. Parallel Distrib. Syst., 12: 899-911.
Direct Link