
M.T. Dastorani
Faculty of Natural Resources, Yazd University, Iran
A. Talebi
Faculty of Natural Resources, Yazd University, Iran
M. Dastorani
Department of Desert Management, Faculty of Natural Resources, Tehran University, Iran
Asian Journal of Applied Sciences
Year: 2010 | Volume: 3 | Issue: 6 | Page No.: 399-410







ABSTRACT
Research on the application of artificial neural networks to the prediction of runoff from ungauged catchments is presented. Available catchment descriptors have been used as input data and the index flood as output. Different types and numbers of catchment descriptors were used to ascertain which gave the best relationship with the hydrological behavior and flood magnitude. Different architectures of ANN were developed and evaluated. Results show that the selection of pooling groups of catchments either randomly or according to geographical proximity does not produce desirable results. Therefore, hydrologically similar catchments were clustered using the Flood Estimation Handbook software and this improved the accuracy of the predictions. Finally, a comparison of the ANN approach and the Flood Estimation Handbook is described that shows the advantages of the ANN approach.
PDF Abstract XML References Citation
How to cite this article
M.T. Dastorani, A. Talebi and M. Dastorani, 2010. Using Neural Networks to Predict Runoff from Ungauged Catchments. Asian Journal of Applied Sciences, 3: 399-410.
DOI: 10.3923/ajaps.2010.399.410
URL: https://scialert.net/abstract/?doi=ajaps.2010.399.410
DOI: 10.3923/ajaps.2010.399.410
URL: https://scialert.net/abstract/?doi=ajaps.2010.399.410
INTRODUCTION
For crop irrigation, water supply for urban communities and more latterly, power generation and industrial supply, human civilisation has always developed along rivers. These advantages have been counterbalanced by the danger of flooding: the regularity of which is indicated by the levees or flood banks built along many major rivers in the past. These and other flood alleviation techniques require knowledge of the hydrology of the catchment area, because, to calculate water levels in a river, it is necessary to obtain estimates of the discharge into the system from runoff. If the catchment under consideration has a history of gauging, as is often found in developed countries, then this can be used. However, in the case of ungauged catchments that are often found in developing countries this is not possible. Many countries that are prone to flooding have not had the infrastructure to collect data in the past and in these cases improved methods for calculating runoff from ungauged catchments are desirable.
The technique of artificial neural networks has been found to be a powerful tool for solving different problems in a variety of applications ranging from pattern recognition to system optimisation. A neural network is an interconnected assembly of simple processing elements, units or nodes, whose functionality is loosely based on the animal neurone. It is based on learning the process from inputs to outputs using a training data set and it mimics these for a new set of inputs to reach corresponding outputs. The ANN technique is widely used as an efficient tool in different areas of water research. It has been used to process rainfall-runoff relationships (Hsu et al., 1995; Minns and Hall, 1996; Dawson and Wilby, 1998); flow prediction based on historical flow data (Karunanithi et al., 1994), rainfall forecasting (Luk et al., 1998), regional flood frequency analysis (Burn, 1990), stage-discharge relationships (Bhattacharya and Solomatine, 2000) and estimation of flood at ungauged catchments (Dawson et al., 2006). A more detailed review can be found elsewhere (Dastorani, 2002).
The present study focuses on the application of artificial neural networks for river flood prediction in ungauged catchments using catchment descriptors (Dastorani and Wright, 2001). In addition, consideration has been given to identifying the factors that have the most significant affect on flood flows from ungauged catchments as well as the most suitable neural network architecture for this particular application (Dastorani, 2002).
In order to evaluate the use of neural networks it is necessary to have a large amount of data for both the inputs and outputs of the neural network. Therefore, although the purpose of the research was to study methods for ungauged catchments, it was necessary to use data from gauged catchments to train and test the method. A comprehensive data set is provided within the Flood Estimation Handbook (FEH) and this was used here. The FEH gives data for the catchment characteristics and flow from each catchment. The former are used as inputs and the latter as outputs for a neural network. In this way the suitability of the ANN for calculations in ungauged catchments can be assessed.
Once this has been carried out and successfully tested it should be possible to use a neural network trained on a gauged catchment to predict flow from other, similar, ungauged catchments. Even where this is not possible the results identifying which and how many catchment characteristics are important gives insight into the behavior of the catchment.
MATERIALS AND METHODS
This study is extracted from a research project which was carried out in 2008. Employed methods and used data are explained below:
Artificial Neural Networks
A neural network consists of a large number of simple processing elements that are variously called neurones, units, cells, or nodes. Each neurone is connected to other neurones by means of direct communication links, each with an associated weight. The weights represent information being used by the network to solve a problem. Neural networks operate on the principle of learning from a training set. They must be trained with a set of typical input/output pairs of data called the training set. The final weight vector of a successfully trained neural network represents its knowledge about the problem. In general, it is assumed that the network does not have any a priori knowledge about the problem before it is trained. At the beginning of training the network weights are usually initialised with a set of random values.
There are a variety of neural network models and learning procedures. Two classes of neural networks that are commonly used for prediction are feed-forward networks and recurrent networks. The neural network approach is a black-box approach and it is therefore not always necessary to have much detail about the physical processes in constructing an ANN. However, some physical understanding can be useful in choosing appropriate inputs.
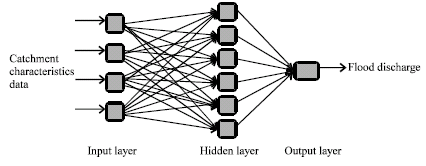 | |
| Fig. 1: | A simple architecture of the MLP neural network |
Neural networks are ideally suited for the modelling of highly non-linear relationships between inputs and outputs. In this research the NeuroSolutions software environment produced by NeuroDimension, Inc. was used to construct the neural network models. Using data from the Flood Estimation Handbook (FEH), ANN models with different architectures were constructed and applied to training and validation sets of data to find the best ANN for this application. Different values for parameters such as learning rate, number of processing elements, number of hidden layers, type of activation and output functions were tested for each architecture as well as for each set of data. This allowed for the selection of appropriate architectures and parameters. It was found that the Multi-Layer Perceptron (MLP) network with three layers, a Tangent Hyperbolic Function in the hidden layer and a Sigmoid function in the output layer was the most accurate network for the work presented here. Figure 1 shows a simple architecture of a typical 3-layer feedforward neural network as has been used in this work. An advantage of the MLP in terms of mapping abilities is its capability of approximating arbitrary functions.
This type of the neural network is normally trained with a backpropagation algorithm. The backpropagation rule propagates the errors through the network and allows adaption of the hidden processing element. It works with error correction learning to update the weights. Full details of this approach can be found elsewhere (Dastorani, 2002).
In this study each set of data was split into training data, cross validation data (to prevent over training) and testing data to evaluate the performance of the trained model. In each pooling group, 60% of the catchments were used for training, 10% for cross validation and 30% for testing.
The number of Processing Elements (PEs) for the hidden layer of the neural network was evaluated. Results were obtained for a pooling group of catchments with seven inputs and an error measure (R2-squared correlation coefficient between predicted and measured values) was calculated for different numbers of PEs (10, 14, 50, 100, 150 and 200). Results showed that the variation of the accuracy for different PEs is not considerable, although there is a decrease when the number of the PEs passes 100. In view of these results, the number of PEs used in this work was taken as 14 which is twice the number of input patterns.
Identification of Appropriate Model Inputs
As mentioned above, catchment descriptors taken from the FEH have been used as inputs to the ANN. The number of input patterns chosen is important in neural network modelling, as it can have considerable influence on the ability of the model. A very small number of inputs may cause the network to insufficiently recognise the nature of the underlying problem when mapping the input/output relationship. Conversely, too large a number of inputs may lead to over-complexity of the relationship and consequent poor performance.
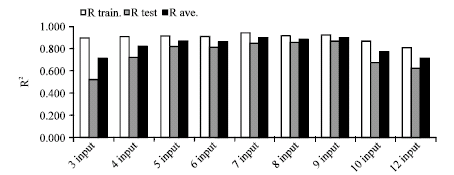 | |
| Fig. 2: | Correlation coefficient (R2) between measured flow and ANN predicted flow by using different numbers of catchment descriptors. Lines are included to show trends |
From a hydrological point of view the optimum state is to use the minimum number of inputs whilst keeping the results to a desirable or acceptable level of accuracy. In addition to the number of descriptors the type of descriptors is also important, as the amount of runoff usually has a stronger relationship with some of the catchment descriptors than others. Identification of these descriptors and the use of them will help to improve the accuracy of the outputs and give insight into the physical processes within the catchment.
For different groups of catchments several simulations were carried out using different numbers and types of descriptors and the results were compared to identify the best combination to use as input to the ANN. Figure 2 shows the correlation coefficient with different numbers of inputs. The correlation coefficient quantifies the difference between the measured values and the outputs from the ANN simulations. From Fig. 2, it is clear that models with 5-9 inputs give the more accurate results. Through a heuristic process, comparing results with different combinations of catchment descriptors, a total of 7 descriptors were selected as the optimum for further simulations. These were:
| AREA | = | Catchment drainage area using an IHTDM-derived boundary (km2) |
| BFIHOST | = | Base Flow Index derived using the HOST classification |
| SPRHOST | = | Standard Percentage Runoff derived using the HOST classification |
| FARL | = | Index of Flood Attenuation attributable to Reservoirs and Lakes |
| SAAR | = | Standard period (1961-1990) Average Annual Rainfall (mm) |
| SMDBAR | = | Mean SMD for the period 1941-70 calculated from MORECS month end values (mm) |
| PROPWET | = | Proportion of time when SMD was ≤6 mm during 1961-90 |
Randomly and Geographically Selected Group of Catchments
At this stage, an initial group, containing 52 catchments (called group 1), was selected randomly from all over the United Kingdom. After the members of the group had been selected, all catchment descriptors were extracted from the data set and prepared for entering into the model. A second group, containing 52 catchments (called group 2), was selected according to an initial consideration of similarity in terms of drainage area and geographical location. All catchments in this group have an area of less than 100 km2. In each group, 60, 30 and 10% of the members were used for training, testing and cross validation purposes, respectively.
Prediction Results for Pooling Groups
The FEH software itself uses a procedure which groups catchments based on hydrological similarities and so it was decided to use this to form pooling groups. The ANN was trained based on these pooling sets with the same split for training, cross-validation and testing (60, 10 and 30%). In this part three pooling groups each one containing 52 catchments were formed which called group 3 to 5.
RESULTS
Figure 3 and 4 show the results obtained from the training and testing phases of the simulation using the random selected group of catchments (group 1). As can be seen from Fig. 3 and 4, the accuracy of the results is not satisfactory, especially in the testing phase which is important in model applicability evaluation. The correlation coefficients (R2) for the training and testing phases for this are 0.96 and 0.67, respectively. The results taken from geographically selected groups (selection of the catchments due to geographical proximity) for training and testing phases are shown in Fig. 5 and 6, respectively. Despite that fact that the second test catchments were selected from same geographical location and the same category of drainage area (all under 100 km2), there is no considerable difference in accuracy relative to the first group where the catchments were selected randomly. For this group the values of R2 for training and testing phases are, respectively 0.82 and 0.62. In Fig. 5 and 6 MAMF is mean annual maximum flood.
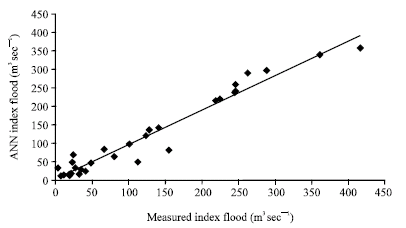 | |
| Fig. 3: | Results obtained from ANN model for group 1against the actual values (training phase) |
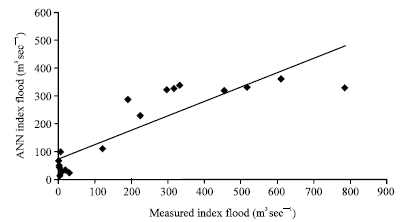 | |
| Fig. 4: | Results obtained from ANN model for group 1 against the actual values (testing phase) |
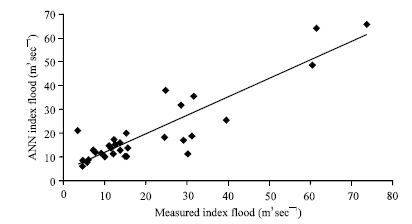 | |
| Fig. 5: | Results obtained from ANN model for group 2 against the actual values (training phase) |
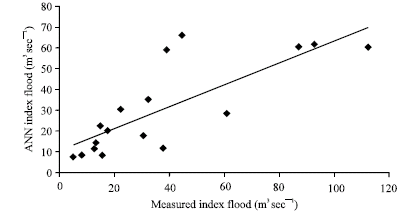 | |
| Fig. 6: | Results obtained from ANN model for a group 2 against the actual values (testing phase) |
Although, in the training phase the predicted flow data and measured flow values show a relatively high correlation coefficient, this is not replicated in the testing phase, which is more important in terms of the evaluation of model performance. This shows that the model cannot learn the process well enough in the training phase to be able to reach appropriate weights for the new set of data in the testing phase.
In view of the poor results and the absence of any improvement through the selection of catchments by relative similarity in drainage area and geographical location, it was decided to pursue a more sophisticated classification method for selecting hydrologically similar catchments. Figure 7 and 8 show the results from group 3 (a pooling group of 52 catchments for the subject site of Tay) in both training and testing phases. For this test R2 was 0.92 and 0.87 for training and testing phases, respectively. For the second pooling group called group 4 (formed for the subject site of Thurso with 52 catchments), the results are shown in Fig. 9 and 10 in training and testing phases. For this test R2 was 0.92 and 0.84 for training and testing phases, respectively.
For these hydrologically similar pooling groups the results were improved by about 20 and 22% for the groups 3, 4 and 5, respectively (Fig. 8-10). The outputs of the model were closer to the measured values than before especially in the testing phase indicating that the pooling allowed the artificial neural networks to produce weights that were more generally applicable across training and testing data.
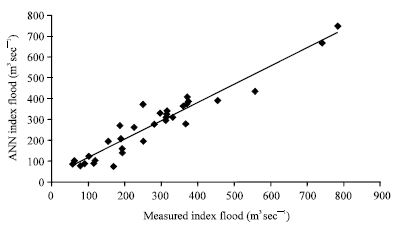 | |
| Fig. 7: | Results obtained from ANN model for group 3 (pooling group) against the actual values (training phase) |
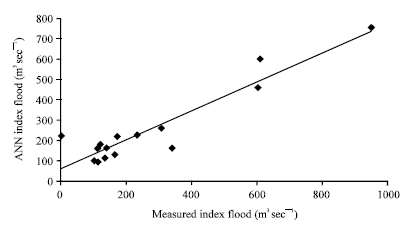 | |
| Fig. 8: | Results obtained from ANN model for group 3 (pooling group) against the actual values (testing phase) |
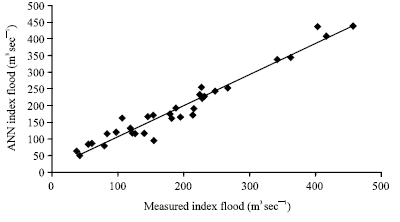 | |
| Fig. 9: | Results obtained from ANN model for group 4 (pooling group) against the actual values (training phase) |
This appears to indicate that hydrological similarity of catchments has a significant effect on the accuracy of the neural network results.
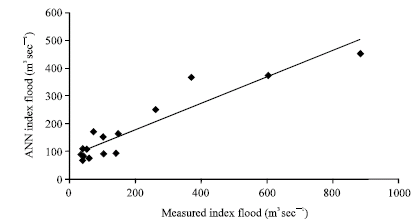 | |
| Fig. 10: | Results obtained from ANN model for group 4 (pooling group) against the actual values (testing phase) |
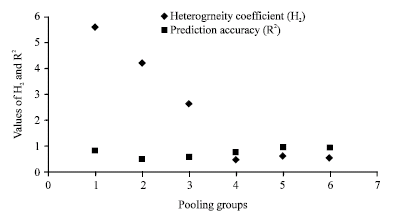 | |
| Fig. 11: | Heterogeneity factor (H2) of WINFAP-FEH and coefficient correlation between predicted and measured peak flow (R2) in testing phase for 6 pooling groups |
Relationship Between Accuracy and Group Homogeneity
Given the considerable improvement in accuracy after forming the groups of hydrologically homogenous catchments, it was decided to analyse the relationship between the accuracy of the model results and the homogeneity of the pooling groups. The purpose was to consider the effects of homogeneity of the formed groups on the outputs of the ANN models. To meet this purpose, more pooling groups for subject sites located in different parts of the UK were formed and used to predict the flow. The R2 was plotted against heterogeneity factor for each pooling group, H2. H2 shows the degree of heterogeneity for the catchments in each group with a higher value of H2 representing a higher degree of heterogeneity.
Initially the number of pooling groups was increased from 2 to 6. The correlation coefficient for each of these is plotted in Fig. 11 and this confirms the clear effect of forming hydrologically similar groups of catchments on the performance of the artificial neural network. It can be seen that for the groups where the homogeneity is poor the model accuracy is also poor. The FEH suggests that a pooling group is homogenous when H2<2, heterogeneous when 2<H2<4 and very heterogeneous when H2 >4. Using this definition, the results presented here show that for homogenous pooling groups there is a good agreement between predicted and measured flow.
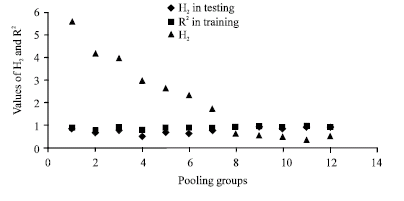 | |
| Fig. 12: | Relationship between the H2 (pooling group heterogeneity factor) and the R2 (squared correlation coefficient between predicted and measured flow) in training and testing phases of ANN for the pooling groups formed by WINFAP-FEH |
The number of pooling groups was extended further to 12 and the results for H2 and R2 are given in Fig. 12. Again, it can be seen that a decrease in the heterogeneity factor leads to an increase in the correlation coefficient. This confirms this trend and demonstrates the importance of pooling in the construction of neural networks for ungauged catchments. Another noteworthy feature in this figure can be seen by comparing the training and testing phases: homogeneity has a greater effect on accuracy in the testing phase than during the training. This demonstrates that whilst a neural network may be able to model heterogeneous data in the training phases, it is to an extent over-trained and unable to reproduce this accuracy on the heterogeneous testing data set. This also emphasises the general point that good performance in the training phase should not be taken as an indication of general suitability of a neural network: the testing phase is still required.
Comparison of the Results to FEH Method
The results presented above show that neural networks can be successfully used to estimate run-off from an ungauged catchment. Further, they demonstrate the importance of pooling hydrologically similar catchments. However, the pooling used was based on the FEH which raises the question of whether the neural network is any better than using the FEH approach alone. The FEH presents a method to estimate annual maximum flood (QMED) for rural catchments (URBEX<0.025) using catchment descriptors. In this method QMED is predicted using following formula (FEH volume 3):
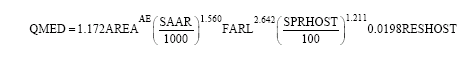 | (1) |
AE is the area exponent calculated by:
| (2) |
RESHOST is a residual soils term obtained from HOST data:
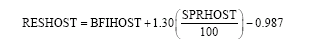 | (3) |
Results using this formula were compared to results from the testing phase of the neural network for four pooling groups. Both groups of catchments (groups 3 and 4) had an urbanisation factor less than 0.025 as stipulated for the above method. R2 for the results of FEH for groups 3 and 4 were, respectively 0.66 and 0.76 while for the results of ANN these were, respectively 0.87 and 0.84. The total number of catchments contributed in this comparison (both groups) was 32.
These results show that the neural network approach is capable of presenting results with higher accuracy in comparison to the FEH method, as for all cases of this research neural networks give significantly improved accuracy.
DISCUSSION
When an ANN model for randomly or geographically formed groups of catchments was constructed the initial results obtained were not satisfactory. However, after employing the FEH to form pooling groups, the accuracy of the results produced by neural networks was improved considerably. This is due to the homogeneity of the catchments selected in pooling groups. In clustering the catchments by this method hydrological factors are considered and hydrological responses through the members of these pooling groups are more similar than the catchments clustered randomly or according to geographical proximity. Using descriptors extracted from hydrologically similar catchments in the ANN model gives a more realistic representation of the whole drainage area. It is interesting to note that, as found in other applications, the ANN, despite being a black-box method, is sensitive to the physical situation in the underlying data. The output of the model in the testing phase compared with the training phase was significantly improved by the pooling, which demonstrates that the neural network has captured the situation applying to the whole pooling group rather than being trained to the specific sub-set chosen for training.
It was also found that specific catchment descriptors have a particularly high influence on flood magnitude. The following descriptors were found to have most influence on the results: AREA, SAAR, BFIHOST, SPRHOST, FARL, SMDBAR and PROPWET. These descriptors represent characteristics such as drainage area, rainfall, river base flow index, lakes and reservoirs and catchment soil property and moisture and can be seen to be the most relevant physically, thereby confirming the ability of the neural network to identify the dominant input parameters. These characteristics are very important in runoff analysis and are generally those used in empirical methods of flood prediction.
Consideration of the pooling group heterogeneity factor and the closeness of the predicted results to the measured values indicate that the forming of the pooling groups is efficient only when the groups have a high enough level of homogeneity. In this study, for the groups with H2 (heterogeneity factor) less than 1, the neural network model produces predictions close to the measured values. It can be said that ANN seems to be an appropriate tool to model river flow and predict peak flows for ungauged catchments or catchments with a short record period when a suitable method is used to identify hydrologically similar catchments in the region. This work has shown that selection of the catchments to form pooling groups based on geographical proximity is not efficient. Homogeneity of the catchments should be considered based on hydrological parameters, which show the general similarity in reaction to precipitation, runoff generation and hydrological responses of the catchments.
By comparing the results of the ANN procedure presented in this research to those produced by the FEH method, it was shown that the accuracy of the outputs presented by ANN is higher.
| Table 1: | Coefficient of efficiency (R2) between the measured flow and predicted flow by ANN (presented in this research) and FEH |
 | |
For both pooling groups considered, R2 for the ANN method is higher than for the FEH method. The difference in R2 is between 21 and 8%, respectively for groups 3 and 4. This comparison shows that ANN can be an appropriate alternative to produce more practical predictions in ungauged catchments.
Finally, it can be summarised that in addition to work on the type of neural networks best suited to this problem, the type and number of catchment descriptors needed to obtain acceptable accuracy was assessed. When choosing the right type and number of catchment characteristics as inputs, this technique gives an efficient tool to solve the problem of sites where the lack of data limits the efficiency of other modelling tools. In terms of flow prediction for such sites, it was found that appropriate selection of the members of the pooling groups was necessary. It is concluded that this should be done using a sophisticated method, which can select the catchments according to their similarity in response to the hydrological events. Other measures such as geographical proximity do not give as good results. In comparison to predictions from the equation given in the FEH, the results obtained from this research were more accurate.
From this work it can be stated that if a suitably pooled group of catchments is found where gauged data is available for a number of the catchments, a neural network can be used to make predictions for the ungauged catchments.
As mentioned earlier, Dawson et al. (2006) used ANN for estimation of floods at ungauged sites in United Kingdom and compared the results of ANN to those of step-wise multiple regression (SWMLR) and also FEH methods. For index flood and in rural condition (which is also the subject of present study), they calculated the coefficient of efficiency 0.88, 0.71 and 0.81, respectively for the mentioned methods. These support the findings of the present research in which ANN can predict floods in ungauged sites and in comparison to most of existing methods, the results of ANN show higher accuracy. Table 1 shows that the results of this study is almost to those of Dawson et al. (2006).
In future work it would be of interest to use neural networks to automatically sort and pool the catchments into groups (Hall and Minns, 1999).
LIST OF SYMBOLS
| ANN | = | Artificial Neural Network |
| FEH | = | Flood Estimation Handbook |
| MLP | = | Multi-Layer Perceptron |
| R2 | = | 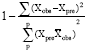 |
| PE | = | Processing Element |
| R2 | = | Squared coefficient of correlation between predicted and measured values, calculated by the following equation: |
| AREA | = | Catchment drainage area using an IHTDM-derived boundary (km2) |
| BFIHOST | = | Base Flow Index derived using the HOST classification |
| SPRHOST | = | Standard Percentage Runoff derived using the HOST classification |
| FARL | = | Index of Flood Attenuation attributable to Reservoirs and Lakes |
| SAAR | = | Standard period (1961-1990) Average Annual Rainfall (mm) |
| SMDBAR | = | Mean SMD for the period 1941-70 calculated from MORECS month end values (mm). |
| PROPWET | = | Proportion of time when SMD was ≤6 mm during 1961-90 |
| MAMF | = | Mean Annual Maximum Flood. |
| UK CEH | = | United Kingdom Centre for Ecology and Hydrology |
| H2 | = | Heterogeneity factor |
| WINFAP-FEH | = | Windows Interface Flood Analysis Program-FEH |
| QMED | = | Annual maximum flood for rural catchments |
| URBEX | = | Urbanisation factor |
| HOST | = | Hydrology of Soil Type. |
| RESHOST | = | Residual Soils term obtained from HOST data |
REFERENCES
- Hsu, K.I., H.V. Gupta and S. Sorooshian, 1995. Artificial neural network modeling of the rainfall-runoff process. Water Resour. Res., 31: 2517-2530.
CrossRefDirect Link - Minns, A.W. and M.J. Hall, 1996. Artificial neural networks as rainfall-runoff models. J. Sci. Hydrol., 41: 399-417.
Direct Link - Dawson, C.W. and R. Wilby, 1998. An artificial neural network approach to rainfall-runoff modelling. J. Hydrol. Sci., 43: 47-66.
CrossRefDirect Link - Karunanithi, N., W.J. Grenney, D. Whitley and K. Bovee, 1994. Neural networks for flow prediction. J. Comp. Civil Eng., 8: 201-220.
Direct Link - Burn, D.H., 1990. Evaluation of regional flood frequency analysis with a region of influence approach. Water Resour. Res., 26: 2257-2265.
Direct Link - Bhattacharya, B. and D.P. Solomatine, 2000. Application of artificial neural network in stage- discharge relationship. Proceedings of the 4th International Conference on Hydroinformatics, July 23-27, 2000. Iowa City, USA., pp: 1-7.
Direct Link - Dawson, C.W., R.J. Abrahart, A.Y. Shamseldin and R.L. Wilby, 2006. Flood estimation at ungauged sites using artificial neural networks. J. Hydrol., 319: 391-409.
Direct Link - Hall, M.J. and A.W. Minns, 1999. The classification of hydrologically homogeneous regions/ Classification en rgions hydrologiques homognes. J. Hydrol. Sci., 44: 693-704.
CrossRef