
H. Noorizadeh
Department of Chemistry, Faculty of Sciences, Arak Branch, Islamic Azad University, Arak, Iran
A. Farmany
Department of Chemistry, Faculty of Sciences, Arak Branch, Islamic Azad University, Arak, Iran
Trends in Applied Sciences Research
Year: 2011 | Volume: 6 | Issue: 12 | Page No.: 1324-1334







ABSTRACT
Genetic Algorithm and Multiple Linear Regression (GA-MLR) and Levenberg-Marquardt Artificial Neural Network (L-M ANN) techniques were used to investigate the correlation between Trolox Equivalent Antioxidant Capacity (TEAC) and descriptors for 16 derivative hydroxy compounds. The applied internal validation method was used for the predictive power of four models. The square correlation coefficient between experimental and predicted TEAC for these data by GA-MLR and were 0.824 and 0.966, respectively. This is the first research on the QSAR of the antioxidant compounds against the TEAC using the L-M ANN.
PDF Abstract XML References Citation
Received: April 15, 2011;
Accepted: August 17, 2011;
Published: September 28, 2011
How to cite this article
H. Noorizadeh and A. Farmany, 2011. Investigation of Capacity Behaviors by Linear and Nonlinear Models Chemometrics. Trends in Applied Sciences Research, 6: 1324-1334.
URL: https://scialert.net/abstract/?doi=tasr.2011.1324.1334
URL: https://scialert.net/abstract/?doi=tasr.2011.1324.1334
INTRODUCTION
The hydroxyl groups attaching to aromatic ring generate a series of compounds that can scavenge radicals by trapping initiating and/or propagating radicals, thus, called antioxidant which attracts more scientific attention by medicinal chemists because the research in this field provides theoretical information for the medicinal development and supplies some in vitro methods for quick-optimizing drugs. Phenolic compounds are widely distributed among vascular plants and are found in numerous fruits, grains, vegetables and other parts of higher plants (Francisco et al., 2009; Luthria, 2008).
As a specific group of secondary metabolites, Phenolic antioxidants play a key role in protecting of organisms against harmful effects of oxygen radicals and other highly active oxygen species (Francisco et al., 2009; Luthria, 2008). Their formation in human body is closely connected with the development of a wide range of degenerative and nondegenerative diseases, mainly arteriosclerosis and other associated complications, cancer, indispositions and last but not least with the accelerated aging of organisms (Huang et al., 2007). Some preventive and defensive systems against the attack of the reactive substances exist in the human organism; however, they cannot eliminate harmful activities of such substances completely, particularly when their production is increased in some metabolic, physiologic, pathologic and other situations. An adequate intake of natural antioxidants in food is therefore, of great importance for protection of macromolecules against oxidative damage (Oke and Aslim, 2011) in cells (mainly unsaturated fatty acids in lipids, cholesterol, different functional polypeptides and proteins and nucleic acids). Antioxidant activity plays, in many cases, a basic role in their pharmacological effects; thus, it can be considered the most important (Meng et al., 2007; Hsu et al., 2006). However, the detailed mechanism underlying the effect of additional hydroxyl moieties on the antioxidant potential has not been studied in any detail.
At this time, various methods are employed for the analysis of antioxidant activity of polyphenols, such as the TEAC (Trolox equivalent antioxidant capacity), DPPH (using diphenyl-p-picrylhydrazyl radical) and FRAP (ferric reducing antioxidant power) methods. A commonly used method in the determination of free radical scavenging activity against the active oxygen species is the determination of the ability of hydrogen-donating antioxidants to scavenge the 2, 20-azinobis (3-ethylbenzthiazoline-6-sulfonic acid) radical cation (ABTS°+) which is expressed in Trolox (a water-soluble vitamin E analog) Equivalent Antioxidant Capacity (TEAC). TEAC is defined as the millimolar concentration of Trolox with the same antioxidant activity as a 1 mM concentration of the substance under investigation. To calculate the TEAC, the gradient of the plot of the percentage inhibition of absorbance vs. concentration plot for the antioxidant in question is divided by the gradient of the plot for Trolox (Obon et al., 2005; Zulueta et al., 2009).
The antioxidant activity of polyphenols can largely be predicted on the basis of their chemical structure. Quantitative Structure-activity Relationship (QSAR) studies have received much attention in chemometrics, biological chemistry, medicinal chemistry and many other fields. QSAR models are mathematical equations relating chemical structure to their biological activity.
In spite of this, only a limited number of studies report on QSAR of benzoic acid focusing on the radical scavenging activity of flavonoid antioxidants (Tyrakowska et al., 1999; Rastija and Medic-Saric, 2009). The QSAR models apply to Multiple Linear Regression (MLR) method and for feature selection, often combined with Genetic Algorithms (GA). Because of the complexity of relationships between the property of molecules and structures, nonlinear models are also used to model the structure activity relationships. Levenberg-Marquardt Artificial Neural Network (L-M ANN) is nonparametric nonlinear modeling technique that has attracted increasing interest (Edriss et al., 2008; Venkatachalam et al., 2008; El-Ramsisi and Khalil, 2007; Terman and Khalafi, 2006; Furferi and Carfagni, 2010; Ozgan and Demirci, 2008; Ghaemi et al., 2008; Prasad et al., 2010). In the present study, GA-MLR and L-M ANN were employed to generate QSAR models that correlate the structure of some compound with observed TEAC. The present study is a first research on QSAR of the antioxidant compounds against the TEAC, using L-M ANN.
MATERIALS AND METHODS
Data set: The data set studied in this work consists of 16 hydroxy benzoic acid compounds which the antioxidant activities were reported as TEAC values were taken from literature (Tyrakowska et al., 1999; Dall’Acqua et al., 2008; Apak et al., 2004; Tung et al., 2009). The structure of these compounds is given in Table 1.
Descriptor generation: The derivation of theoretical molecular descriptors proceeds from the chemical structure of the compounds. In order to calculate the theoretical descriptors, all molecular structures were constructed with HyperChem software (version 6). Optimization of molecular structures was carried out by semi-empirical AM1 method using the Fletcher-Reeves algorithm until the room mean square gradient of 0.01 was obtained by Hemmateenejad et al. (2007). Since the calculated values of the electronic features of molecules will be influenced by the related conformation. In the current research an attempt was made to use the most stable conformations.
| Table 1: | Molecular structure of benzoic compounds |
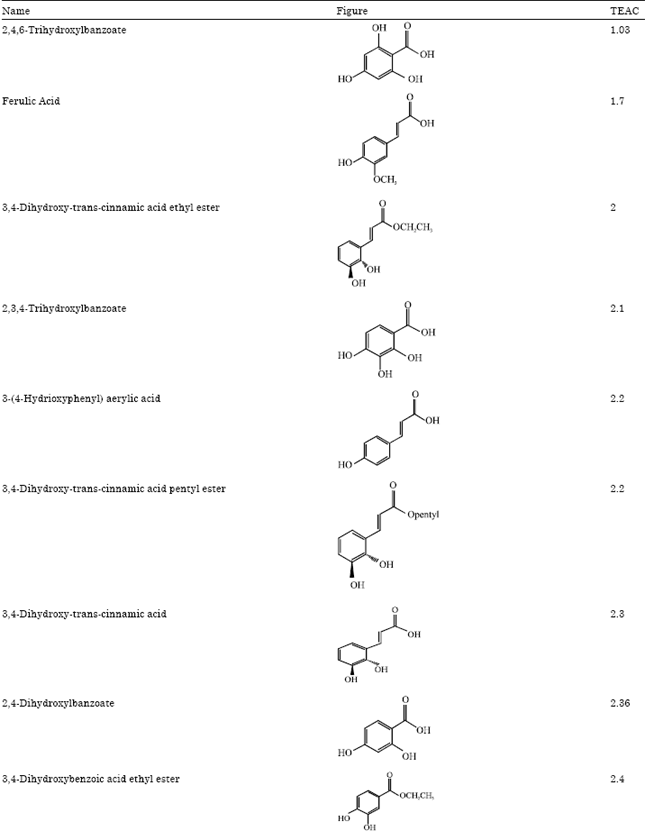 | |
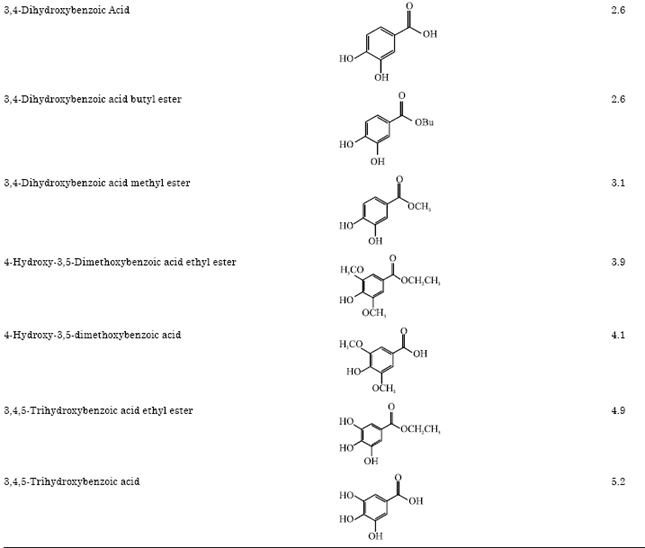 | |
Some electronic descriptors such as dipole moment and orbital energy of LUMO were calculated by using the HyperChem software. Also, optimized structures were used to calculate 1497 descriptors by DRAGON software Version 3 (Todeschini et al., 2003).
Software and programs: A Pentium IV personal computer (CPU at 3.06 GHz) with windows XP operational system was used. Geometry Optimization was performed by HyperChem (Version 7.0 Hypercube, Inc.), Dragon software was used to calculate of TEAC. MLR analysis was performed by the SPSS Software (version 13, SPSS, Inc.) by using enter method for model building. Cross validation, GA-MLR, L-M ANN and other calculation were performed in the MATLAB (Version 7, Mathworks, Inc.) environment.
Genetic algorithm: To select the most relevant descriptors with GA, the evolution of the population was simulated. Each individual of the population, defined by a chromosome of binary values, represented a subset of descriptors. The number of the genes at each chromosome was equal to the number of the descriptors. The population of the first generation was selected randomly. A gene was given the value of one, if its corresponding descriptor was included in the subset; otherwise, it was given the value of zero. The number of the genes with the value of one was kept relatively low to have a small subset of descriptors that is the probability of generating zero for a gene was set greater. The operators used here were crossover and mutation. The application probability of these operators was varied linearly with a generation renewal. For a typical run, the evolution of the generation was stopped, when 90% of the generations had taken the same fitness (Noorizadeh and Farmany, 2010a; Cai et al., 2001; Goldberg, 2000). In this study, size of the population is 30 chromosomes, the probability of initial variable selection is 5:V (V is the number of independent variables), crossover is multi Point, the probability of crossover is 0.5, mutation is multi point, the probability of mutation is 0.01 and the number of evolution generations is 1000. For each set of data, 3000 runs were performed.
Linear model
Multiple linear regressions: A major step in constructing the QSAR model is finding a set of molecular descriptors that represent variation in the structural property of the molecules. The modeling and prediction of the physicochemical properties of organic compounds is an important objective in many scientific fields (Noorizadeh and Farmany, 2010b; Citra, 1999). MLR is one of the most modeling methods in QSAR.
Nonlinear model
Artificial neural network: An Artificial Neural Network (ANN) with a layered structure is a mathematical system that stimulates the biological neural network; consist of computing units named neurons and connections between neurons named synapses (Booth et al., 1997; Noorizadeh and Farmany, 2011). Input or independent variables are considered as neurons of input layer while dependent or output variables are considered as output neurons. Synapses connect input neurons to hidden neurons and hidden neurons to output neurons. The strength of the synapse from neuron i to neuron j is determined by mean of a weight, Wij. In addition, each neuron j from the hidden layer and eventually the output neuron, are associated with a real value bj, named the neuron’s bias and with a nonlinear function, named the transfer or activation function. Because the Artificial Neural Networks (ANNs) are not restricted to linear correlations, they can be used for nonlinear phenomena or curved manifolds (Booth et al., 1997). Back Propagation Neural Networks (BNNs) are most often used in analytical applications (Noorizadeh and Farmany, 2011). The back propagation network receives a set of inputs which is multiplied by each node and then a nonlinear transfer function is applied. The goal of training the network is to change the weight between the layers in a direction to minimize the output errors.
Levenberg-marquardt algorithm: While basic back propagation is the steepest descent algorithm, the Levenberg-marquardt algorithm (Noorizadeh et al., 2011; Salvi et al., 2002) is an alternative to the conjugate methods for second derivative optimization.
RESULTS AND DISCUSSION
Linear model
GA-MLR analysis: To reduce the original pool of descriptors to an appropriate size, the objective descriptor reduction was performed using various criteria.
| Table 2: | Experimental, calculated and relative error values by GA-MLR and L-M ANN |
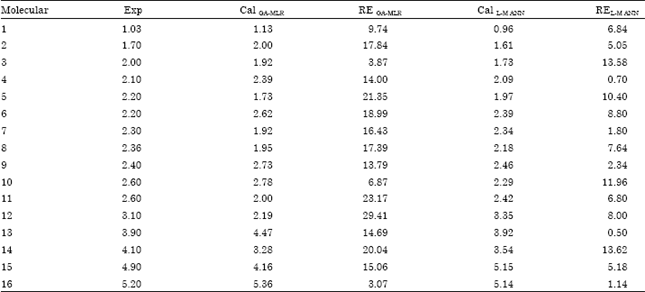 | |
| Table 3: | The statistical parameters of different constructed QSRR models |
 | |
| aAbsolute error | |
Reducing the pool of descriptors eliminates those descriptors which contribute either no information or whose information content is redundant with other descriptors present in the pool. From the variable pairs with r>0.90, only one of them was used in the modeling while the variables over 90% and equal to zero or identical were eliminated. In order to minimize the information overlap in descriptors and to reduce the number of descriptors required in regression equation, the concept of non-redundant descriptors was used in this study. The best equation is selected on the basis of the highest multiple correlation Coefficient Leave-one-out Cross Validation (LOO-CV) (Q2), the least RMSECV and relative error of prediction and simplicity of the model. These parameters are probably the most popular measure of how well a regression model fits the data. Among the models proposed by GA-MLR, one model had the highest statistical quality and was repeated more than the others. This model had four molecular descriptors including RDF descriptors ((Radial Distribution Function -3.5/weighted by atomic masses) (RDF 035 m), WHIM descriptors (2nd component accessibility directional WHIM index/unweighted) (E 2u), atom-centered fragments (phenol/enol/carboxyl OH) (O-057) and electronic descriptor (Lowest Unoccupied Molecular Orbital (LUMO)). The experimental, calculated and relative errors are shown in Table 2 and statistical parameters of this model, constructed by the selected descriptors, are depicted in Table 3. The predicted values of TEAC are plotted against the experimental values in Fig. 1a.
Description of models descriptors: The antioxidant efficiency of hydroxyl benzoic acid has been related to the number of hydroxyl groups in the molecule and also to their hydrogen radical donating abilities. The hydrogen donating substituents (hydroxyl groups), attached to the aromatic ring structures of hydroxyl benzoic acid which enable the flavonoids to undergo a redox reaction that helps them to scavenge free radicals more easily.
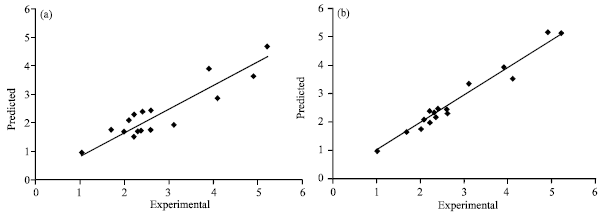 | |
| Fig. 1(a-b): | Plots of predicted TEAC against the experimental values by (a) GA-MLR and (b) L-M ANN models |
The compounds with three hydroxyl groups on the phenyl ring of phenolic acids and hydroxy benzoic acid had the highest antioxidant activities. The loss of one hydroxyl group decreased activity slightly while the loss of two hydroxyl groups decreased activity significantly. Similarly also showed that an increase in the number of hydroxyl groups led to higher antioxidant activities. For these reasons, constitutional descriptors, atom-centered fragments, functional groups and electronic descriptors are very important.
Electronic descriptors were defined in terms of atomic charges and used to describe electronic aspects both of the whole molecule and of particular regions, such atoms, bonds and molecular fragments. This descriptor calculated by computational chemistry and therefore, can be consider among quantum chemical descriptor. LUMO as an electron acceptor represents the ability to obtain an electron. The energy of the LUMO is directly related to the electron affinity and characterizes the susceptibility of the molecule toward attack by nucleophiles. The LUMO energy can be interpreted as a measure of charge transfer interactions and/or of hydrogen bonding effects.
The Radial Distribution Function (RDF) descriptors are based on the distances distribution in the geometrical representation of a molecule and constitute a radial distribution function code. These structural codes are independent from the number of atoms that is, the size of a molecule and invariant against translation and rotation of the entire molecule.
The WHIM descriptors are built in such a way as to capture the relevant molecular 3D information regarding the molecular size, shape, symmetry and atom distribution with respect to some invariant reference frame. WHIM descriptors are based on principal component analysis of the weighted covariance matrix obtained from the atomic cartesian coordinates. In relation to the kind of weights selected for the atoms different sets of WHIM descriptors can be obtained (Todeschini and Consonni, 2000).
Nonlinear model
L-M ANN analysis: With the aim of improving the predictive performance of nonlinear QSRR model, L-M ANN modeling was performed. Descriptors of GA-MLR model were selected as inputs in L-M ANN model. The network architecture consisted of four neurons in the input layer corresponding to the four mentioned descriptors. The output layer had one neuron that predicts the TEAC. The number of neurons in the hidden layer is unknown and needs to be optimized. In addition to the number of neurons in the hidden layer, the learning rate, the momentum and the number of iterations also should be optimized. In this study, the number of neurons in the hidden layer and other parameters except the number of iterations were simultaneously optimized. A MATLAB program was written to change the number of neurons in the hidden layer from 2 to 7, the learning rate from 0.001 to 0.1 with a step of 0.001 and the momentum from 0.1 to 0.99 with a step of 0.01. The root mean square errors were calculated for all of the possible combination of values for the mentioned variables in cross validation. The experimental, calculated and relative errors of this model are shown in Table 2. The statistical parameters for L-M ANN model in Table 3. Plots of predicted TEAC versus experimental TEAC values by L-M ANN are shown in Fig. 1b. Obviously, there is a close agreement between the experimental and predicted TEAC and the data represent a very low scattering around a straight line with respective slope and intercept close to one and zero. The closeness of the data to the straight line with a slope equal to 1 shows the perfect fit of the data to a nonlinear model. It should be noted that the data shown in Fig. 1b are the predicted values according to leave-one-out cross validation and a deviation from the regression line is expected for some points.
These models were validated by calculating q2 values. The q2 values are calculated from Leave-group-out Cross Validation (LGO-CV) for L-M ANN (Noorizadeh et al., 2011). In this study, we use LOO CV for GA-MLR model and LGO CV for L-M ANN model. A data point is removed from the set and the regression recalculated; the predicted value for that point is then compared to its actual value. This is repeated until each datum has been omitted once; the RMSE and sum of squares of these deletion residuals can then be used to calculate q2, an equivalent statistic to R2. The q2 values can be considered a measure of the predictive power of a regression equation: Whereas R2 can always be increased artificially by adding more parameters (descriptors), q2 decreases if a model is over parameterized and therefore, it is a more meaningful summary statistic for QSAR models.
The statistical parameters obtained by LOO-CV for L-M ANN and the linear QSRR model are compared in Table 3. Inspections of the results of the table reveals a higher R2 and Q2 values and lower the RE for L-M ANN model compared with their counterparts for GA-MLR model. This clearly shows the strength of L-M ANN as a nonlinear feature selection method. This capacity offset the large computing time required and complexity of L-M ANN model with respect GA-MLR model.
Model validation and statistical parameters: The applied internal (Leave-group-out Cross Validation (LGO-CV)) and external (test set) validation methods were used for the predictive power of models. In the leave-group-out procedure one compound was removed from the data set, the model was trained with the remaining compounds and used to predict the discarded compound. The process was repeated for each compound in the data set. The predictive power of the models developed on the selected training set is estimated on the predicted values of test set chemicals. The data set should be divided into two new sub-data sets, one for training and the other one for testing.
For the constructed models, some general statistical parameters were selected to evaluate the predictive ability of the models for TEAC values. In this case, the predicted TEAC of each sample in prediction step was compared with the experimental acidity constant. Root Mean Square Error (RMSE) is a measurement of the average difference between predicted and experimental values, at the prediction step. RMSE can be interpreted as the average prediction error, expressed in the same units as the original response values. The RMSE was obtained by the following formula:
| (1) |
The second statistical parameter was Relative Error (RE) that shows the predictive ability of each component and is calculated as:
| (2) |
The predictive ability was evaluated by the square of the correlation coefficient cross validation (Q2 or R2LGO) which is based on the prediction error sum of squares and was calculated by following equation:
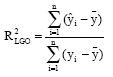 | (3) |
where, yi is the experimental k' in the sample I, ![]() represented the predicted k' in the sample I,
represented the predicted k' in the sample I, ![]() is the mean of experimental k' in the prediction set and n is the total number of samples used in the test set.
is the mean of experimental k' in the prediction set and n is the total number of samples used in the test set.
CONCLUSION
The increasing interest in antioxidant is due to the appreciation of their broad pharmacological activity. Beneficial effects of antioxidant have been described for diabetes mellitus, allergy, cancer, viral infections and inflammations. They can bind to biomolecules, such as enzymes, hormone carriers and DNA, chelate transition metal ions, catalyze electron transport and scavenge free radicals and including superoxide anions. Benzoic acids and vitamin E derivatives and flavonoids have recently gained significant interest among various antioxidants. In this study, an accurate QSAR model for estimating the Trolox Equivalent Antioxidant Capacity (TEAC) of derivative hydroxy benzoic acid compounds was developed by employing the linear model (GA-MLR) and a nonlinear model (L-M ANN). Two models have good predictive capacity and excellent statistical parameters. A comparison between these models revealed the superiority of the L-M ANN model. It is easy to notice that there was a good prospect for the L-M ANN application in the QSAR modeling. This indicates that the TEAC of benzoic acid possesses some nonlinear characteristics. It can also be used successfully to estimate the TEAC for new compounds or for other compounds whose experimental values are unknown.
REFERENCES
- Apak, R., K. Güçlü, M. Özyürek and S.E. Karademir, 2004. Novel total antioxidant capacity index for dietary polyphenols and vitamins C and E, using their cupric ion reducing capability in the presence of neocuproine: CUPRAC method. J. Agric. Food Chem., 52: 7970-7981.
CrossRefDirect Link - Booth, T.D., K. Azzaoui and I.W. Wainer, 1997. Prediction of chiral chromatographic separations using combined multivariate regression and neural networks. Anal. Chem., 69: 3879-3883.
CrossRef - Cai, W., B. Xia, X. Shao, Q. Guo, B. Maigret and Z. Pan, 2001. Molecular interactions of cyclodextrin inclusion complexes using a genetic algorithm. J. Mol. Struct. Theochem, 535: 115-119.
CrossRef - Citra, M.J., 1999. Estimating the pKa of phenols, carboxylic acids and alcohols from semi-empirical quantum chemical methods. Chemosphere, 38: 191-206.
CrossRef - Dall'Acqua, S., R. Cervellati, M.C. Loi and G. Innocenti, 2008. Evaluation of in vitro antioxidant properties of some traditional sardinian medicinal plants: Investigation of the high antioxidant capacity of Rubus ulmifolius. Food Chem., 106: 745-749.
CrossRef - Francisco, M., D.A. Moreno, M.E. Cartea, F. Ferreres, C. Garcia-Viguera and P. Velasco, 2009. Simultaneous identification of glucosinolates and phenolic compounds in a representative collection of vegetable Brassica rapa. J. Chromatogr. A, 1216: 6611-6619.
PubMed - Hemmateenejad, B., K. Javadnia and M. Elyasi, 2007. Quantitative structure-retention relationship for the Kovats retention indices of a large set of terpenes: A combined data splitting-feature selection strategy. Anal. Chim. Acta, 592: 72-81.
PubMed - Huang, Z., B. Wang, D.H. Eaves, J.M. Shikany and R.D. Pace, 2007. Phenolic compound profile of selected vegetables frequently consumed by African Americans in the Southeast United States. Food Chem., 103: 1395-1402.
CrossRef - Hsu, B., I.M. Coupar and K. Ng, 2006. Antioxidant activity of hot water extract from the fruit of the Doum palm, Hyphaene thebaica. Food Chem., 98: 317-328.
CrossRef - Luthria, D.L., 2008. Influence of experimental conditions on the extraction of phenolic compounds from parsley (Petroselinium crispum) flakes using a pressurized liquid extractor. Food Chem., 107: 745-752.
CrossRef - Noorizadeh, H. and A. Farmany, 2010. Exploration of linear and nonlinear modeling techniques to predict of retention index of essential oils. J. Chin. Chem. Soc., 57: 1268-1277.
Direct Link - Noorizadeh, H. and A. Farmany, 2010. QSRR models to predict retention indices of cyclic compounds of essential oils. Chromatographia, 72: 563-569.
CrossRef - Noorizadeh, H., A. Farmany and M. Noorizadeh, 2011. Quantitative structure-retention relationships analysis of retention index of essential oils. Quim. Nova, 34: 242-249.
CrossRef - Noorizadeh, H. and A. Farmany, 2011. Determination of partitioning of drug molecules using immobilized liposome chromatography and chemometrics methods. Drug Test. Analy., (In Press).
CrossRef - Obon, J.M., M.R. Castellar, J.A. Cascales and J.A. Fernandez-Lopez, 2005. Assessment of the TEAC method for determining the antioxidant capacity of synthetic red food colorants. Food Res. Int., 38: 843-845.
CrossRef - Rastija, V. and M. Medic-Saric, 2009. QSAR study of antioxidant activity of wine polyphenols. Eur. J. Med. Chem., 44: 400-408.
CrossRef - Salvi, M., D. Dazzi, I. Pellistri, I. Neri and J.R. Wall, 2002. Classification and prediction of the progression of thyroid-associated ophthalmopathy by an artificial neural network. Ophthalmology, 109: 1703-1708.
Direct Link - Tung, Y.T., J.H. Wu, C.Y. Huang, Y.H. Ku and S.T. Chang, 2009. Antioxidant activities and phytochemical characteristics of extracts from Acacia confusa bark. Bioresour. Technol., 100: 509-514.
CrossRefDirect Link - Tyrakowska, B., A.E. Soffers, H. Szymusiak, S. Boeren and M.G. Boersma et al., 1999. TEAC Antioxidant Activity of 4-Hydroxybenzoates. Free Radical Biol. Med., 27: 1427-1436.
CrossRef - Zulueta, A., M.J. Esteve and A. Frigola, 2009. ORAC and TEAC assays comparison to measure the antioxidant capacity of food products. Food Chem., 114: 310-316.
CrossRefDirect Link - Edriss, M.A., P. Hosseinnia, M. Edrisi, H.R. Rahmani and M.A. Nilforooshan, 2008. Prediction of second parity milk performance of dairy cows from first parity information using artificial neural network and multiple linear regression methods. Asian J. Anim. Vet. Adv., 3: 222-229.
CrossRefDirect Link - Venkatachalam, S., C. Arumugam, K. Raja and V. Selladurai, 2008. Quality function deployment in agile parallel machine scheduling through neural network technique. Asian J. Sci. Res., 1: 146-152.
CrossRefDirect Link - El-Ramsisi, A.M. and H.A. Khalil, 2007. Diagnosis system based on wavelet transform, fractal dimension and neural network. J. Applied Sci., 7: 3971-3976.
CrossRefDirect Link - Terman, M.S. and H. Khalafi, 2006. Analysis of Tehran research reactor dynamics behavior in reactivity insertion accidents by recurrent neural network. Trends Applied Sci. Res., 1: 586-596.
CrossRefDirect Link - Furferi, R. and M. Carfagni, 2010. An as-short-as-possible mathematical assessment of spectrophotometric color matching. J. Applied Sci., 10: 2108-2114.
CrossRefDirect Link - Ozgan, E. and R. Demirci, 2008. Neural networks based modelling of traffic accidents in interurban rural highways, duzce sampling. J. Applied Sci., 8: 146-151.
CrossRefDirect Link - Ghaemi, A., Sh. Shahhoseini, M.G. Marageh and M. Farrokhi, 2008. Prediction of vapor-liquid equilibrium for aqueous solutions of electrolytes using artificial neural networks. J. Applied Sci., 8: 615-621.
CrossRefDirect Link - Prasad, R., D. Krishnaiah, A. Bono, P. Pandiyan, R.B.M. Yunus and N. Lakshmi, 2010. Estimation of carrageenan concentration by using ultra sonic waves and back propagation neural networks. J. Applied Sci., 10: 2729-2732.
CrossRefDirect Link