
Dursun Aydin
Department of Statistics, Mugla University, 48000, Mugla, Turkey
Trends in Applied Sciences Research
Year: 2009 | Volume: 4 | Issue: 3 | Page No.: 126-137







ABSTRACT
In this study, we will investigate and compare the performance of some forecasting methods for time series with both trend and seasonal patterns. The forecasting performance has been compared with six models and these include: Auto Regressive Integrated Moving Average (ARIMA), Smoothing Spline Model (SSM), Regression Spline Model (RSM), Additive Regression Model (ARM), Multi-Layer Perceptron (MLP) and Radial Basis Function (RBF) network models. The SSM, RSM and ARM are called as non-parametric regression models, whereas MLP and RBF are known as artificial neural network models. For these models, we conducted a comparison based on actual data sets, the number of tourist coming to Turkey. The empirical results obtained have shown that MLP performed better than other models. In addition, the SSM can be considered as an alternative to MLP.
PDF Abstract XML References Citation
How to cite this article
Dursun Aydin, 2009. A Comparative Study of Neural Networks and Non-Parametric Regression Models for Trend and Seasonal Time Series. Trends in Applied Sciences Research, 4: 126-137.
URL: https://scialert.net/abstract/?doi=tasr.2009.126.137
URL: https://scialert.net/abstract/?doi=tasr.2009.126.137
INTRODUCTION
The ARIMA models is also called as Box-Jenkins models, are the most general class of models for forecasting a time series (Box and Jenkins, 1976). A restrictive aspect of these models is that, they have linear structured models. The relationship between the variables is never linear in real life in general for most problems (Granger and Terasvirta, 1993) and using linear models is not efficient for such problems.
Artificial Neural Networks (ANN) are a class of flexible nonlinear models that can discover patterns adaptively from the data. Theoretically, it has been shown that given an appropriate number of nonlinear processing units, ANN can learn from experience and estimate any complex functional relationship with high accuracy. Recently, numerous successful applications have established their role time series forecasting problems such as prediction of electric demand, prediction of breast cancer survivability, future evolution of electricity markets, modeling rainfall-runoff process (Abraham and Nath, 2001; Delen et al., 2005; Gareta et al., 2006; Srinivasulu and Jain, 2006). One of the main reasons that ANN models can produce more effective results in classification, sample recognition and forecasting problems than linear models. The ANN also does not require any knowledge nor prior information about systems of interest. Therefore, using of the ANN models affecting the nonlinear structure in data may be helpful (Zhang et al., 2001).
Latterly, non-parametric regression methods have become a very useful tool for non-linear data such as time series (Ferreira et al., 2000). However, these approaches do not perform well when trend and seasonality is present. To overcome this problem, we considered two alternatives methods proposed in study. In both approaches the trend is specified as non-parametric, but the seasonal component specification is different. First, we take into account a partial linear model where the parametric part is a dummy-variable specification for the seasonality. Secondly, we consider the seasonal component to be a smooth function of time and, the model falls within the class of additive models. The non-parametric regression models are discussed in detail by Hastie and Tibshirani (1999), Wahba (1990), Hardle (1991), Green and Silverman (1994) and Hardle et al. (2004).
There are some forecasting techniques used to forecast data time series including trend and seasonality. We considered the ones which is more flexible than linear models. One of these techniques is non-parametric regression models analyzed by Ferreira et al. (2000). The other technique is ANN models used for time series forecasting. The purpose of this study is to compare some forecasting models and to examine the issue whether a more complex model work more effectively in forecasting a trend and seasonal time series.
MATERIALS AND METHODS
The monthly arrival data of tourist coming to Turkey has been used for model estimation and evaluation. The artificial neural networks and non-parametric regression called as semi-parametric and additive regression models are discussed follows, respectively.
ARTIFICIAL NEURAL NETWORK (ANN) APPROACH
Multi-Layer Perceptrons (MLPs)
The MLP models used in this study are the standard three-layer MLP called as the feed-forward neural networks models with only one output node and with nodes in adjacent layers fully connected. The activation function for hidden nodes is the logistic function fh(x) = 1/(1+exp(–x)) and for the output node, the linear function. Bias (or intercept) terms are used in both hidden and output layers. MLP model can be expressed by:
| (1) |
where, yk represents the kth output value, ![]() denote the weights for the connections between the ith input and jth hidden units,
denote the weights for the connections between the ith input and jth hidden units, ![]() denotes the weights for the connections between the jth hidden and kth output units,
denotes the weights for the connections between the jth hidden and kth output units, ![]() denote the bias for jth hidden unit,
denote the bias for jth hidden unit, ![]() denote the bias for kth output unit, fh(.) is activation function applied to the hidden units and fo(.) is the activation function applied to the output units.
denote the bias for kth output unit, fh(.) is activation function applied to the hidden units and fo(.) is the activation function applied to the output units.
Back-Propagation (BP) is the widespread approximation for training of the multi-layer feed-forward neural networks based on Widrow-Hoff training rule (Bishop, 1995; Haykin, 1999). The main idea here is to adjust the weights and the biases that minimize the sum of square error by propagation the error back at each step, namely:
over the first of time series, called the training set in neural networks. To minimize the sum of square error, different BP algorithms are constructed by applying different numeric optimization algorithms among gradient and Newton methods class. Conjugate Gradient (CG) algorithms provided by the Statistica Neural Network (SNN) is also employed in training of MLP networks. Another algorithm of CG algorithms is Scaled Conjugate Gradients (SCG) algorithm (Moller, 1993). The basic idea of SCG is to combine the model trust region approach with the CG approach (Bishop, 1995; Nocedal and Wright, 1999).
Radial Basis Function Networks (RBF)
The RBF is composed of three layers: an input layer, a hidden layer and an output layer. The hidden layer of an RBF is non-linear, whereas the output layer is linear. In the RBF, one hidden layer with required number of units is enough in order to model a function. The activations of hidden (radial) units are defined depending on the distance of the input vector and the center vector. Typically, the radial layer has exponential activation functions and the output layer a linear activation function. Appropriate y output vector for the x input vector is calculated as follows for n input, m output and p radial units for the RBF:
| (2) |
where, wkj, j = 1, 2,..,p are the appropriate weights for kth output unit, φj(x), j = 1, 2,..,p, is the basis function of jth radial unit, wko, k = 1, 2,...,m are the appropriate deviations for kth output unit, φ0 is an extra basis function with activation value fixed at φ0 = 1. Usually, more attention paid for the following Gaussian basis function:
| (3) |
where, μj = (μj1, μj2...,μjn) vector is center for φj(x) and σj is deviation (or width) parameters of that function. The basis function of the unit is defined using those two parameters. Equation 2 can be written in matrix notation as:
y (x) = Wφ | (4) |
where, W = (wkj) and φ = (φj). As can be seen from Eq. 2, the linear activation function is used in the RBF for output layer. Education is made in three stages in the RBF. In the first stage, by unsupervised education, radial basis function centers (in other words μj) are optimized using all {x(i)}, i = 1, 1,...,N, education data. Centers can be assigned by a number of algorithms: Sub-sampling, K-means, Kohonen training, or Learned Vector Quantization. In the second stage σj, j = 1, 2,...,p, parameters can be assigned by algorithms explicit, isotropic and K-nearest neighbor. In the third stage of education, the basis functions that are obtained for adjusting the appropriate weights for output units are taken as fixed and deviation parameters are added to linear sum. Optimum weights are obtained by minimization of the sum of square errors:
| (5) |
In Eq. 14, ![]() is the target value for output unit k when the network is presented with input vector x(i), i = 1, 2,...,N. Since, the equality in Eq. 4 is the quadratic function of the weights, optimum weights can be found as the solution of the linear equations system. The output layer is usually optimized using the pseudo-inverse technique.
is the target value for output unit k when the network is presented with input vector x(i), i = 1, 2,...,N. Since, the equality in Eq. 4 is the quadratic function of the weights, optimum weights can be found as the solution of the linear equations system. The output layer is usually optimized using the pseudo-inverse technique.
The MLP with a defined architecture, is given by the appropriate weights and the biases of the units, but in the RBF, it is given by the center and the deviation of the radial units and by the weights and biases of the output units. As the point is given by n coordinates in n dimensional space, the number of the coordinates are equal to the linear input units n. Hence, in SNN software, the coordinates of the center radial unit are taken as weights and the deviation of the radial unit is taken as bias. As a result, radial weights denotes the center point, radial bias denotes the deviation.
THE ANN APPROACH TO TIME SERIES MODELING
The feed-forward ANN method is usually used for time series modeling and forecasting (Zhang et al., 1998). For one hidden layer network architecture n:p:1 (n, number of inputs, p, number of hidden units and 1, number of outputs), inputs are the observed values of nth previous time points and outputs (targets) are (n+1)th observed value. When the network square error function is examined, it can be seen that ANN are a nonlinear functions of previous observations (yt–1, yt–2,...,yt–n) to future observations yt (Zhang, 2003):
where, (yt–1, yt–2,...,yt–n) denote input values, yt denotes target (or output) value, w denote the weights of the network, εt denote the vector of network error at time point t. The predicted ![]() is calculated as follows:
is calculated as follows:
If N number of y1, y2,...,yN observations are used for a time series and 1-step forward forecast is made, the number of training samples are N–n. (y1, y2,...,yn) is taken as first input training sample and yn+1 is accepted as the target. The second training pattern will contain y2, y3,...,yn+1 as inputs and yn+2 as the second target output. Finally, (yN–n, yN–n+1,...,yN–1) and yN will be the last inputs pattern and target correspondingly. In training procedure, with the help of different BP algorithms, the parameters (weights and biases) of the network is obtained by getting closer to the minimum value of Sum of Square Error (SSE):
THE NON-PARAMETRIC APPROACH IN TIMES SERIES PREDICTION
The following basic model form has been considered as:
| (6) |
where, ti’s are spaced in [a, b], s(ti) denotes the seasonal component, z(ti) represents the trend and e(ti) indicates the terms of error with zero mean and common variance ![]() . The model 6 can be also written as:
. The model 6 can be also written as:
| (7) |
It is assumed that the following model structure for the trend:
| (8) |
where, f is a smooth function in [a, b] and εi’s are assumed to be with zero mean and common variance ![]() , which is different from ei’s.
, which is different from ei’s.
The main idea is to estimate the functions f and s. The function f is estimated as a smooth function, but the estimation of the function s is different due to seasonality (Ferriera et al., 2000). Therefore, it is considered two alternative models for the estimation of the s. Firstly, it is treated a semi-parametric model where parametric component is dummy variable for the seasonality. Secondly, it is discussed the seasonal component to be a smooth function of time and use a non-parametric method.
Semi-Parametric Regression Model
It is assumed that the seasonality is built as follows:
| (9) |
where, r is the number of annual observations (r = 12) and vi’s are assumed to be with zero mean and common variance ![]() and different from the errors in Eq. 7 and 8.
and different from the errors in Eq. 7 and 8. ![]() 's are dummy variable that denotes the seasonal effects and βk’s are parametric coefficients. Dummy variables are denoted by
's are dummy variable that denotes the seasonal effects and βk’s are parametric coefficients. Dummy variables are denoted by ![]() (where, Dki = 1 if i observation correspond to the kth month of year and Dki = 0 otherwise) for cancels the seasonal effects when a year is completed (Ferriera et al., 2000). By substitution Eq. 9 and 8 in Eq. 7, it is obtained as:
(where, Dki = 1 if i observation correspond to the kth month of year and Dki = 0 otherwise) for cancels the seasonal effects when a year is completed (Ferriera et al., 2000). By substitution Eq. 9 and 8 in Eq. 7, it is obtained as:
| (10) |
where, ui’s are the sum of the random errors with zero means and constant variance ![]() .
.
Model 10 is called as a semi-parametric model due to consist of a parametric linear component and only a non-parametric component. The main purpose is to estimate the parameter vector β and function f at sample points t1,...,tn. For this aim, two estimation methods, called as smoothing spline and regression spline, have been considered.
Estimation with Smoothing Spline Method (SSM)
Estimation of the parameters of interest in Eq. 10 can be performed using smoothing spline. Mentioned here the vector parameter β and the values of function f at sample points t1,...,tn are estimated by minimizing the penalized residual sum of squares:
| (11) |
where, f ∈ C2[0, 1] and di is the ith row of the matrix D. When the β = 0, resulting estimator has the form ![]() , where, Sλ a known positive-definite (symmetric) smoother matrix that depends on λ and the knots t1,...,tn (Wahba, 1990; Eubank, 1999).
, where, Sλ a known positive-definite (symmetric) smoother matrix that depends on λ and the knots t1,...,tn (Wahba, 1990; Eubank, 1999).
For a pre-specified value of λ the corresponding estimators for f based on Eq. 10 can be obtained as follows (Wahba, 1990). Given a smoother matrix Sλ, depending on a smoothing parameter λ, construct ![]() . Then, by using penalized least squares, mentioned here estimator are given by:
. Then, by using penalized least squares, mentioned here estimator are given by:
| (12) |
| (13) |
Evaluate some criterion function (such as cross validation, generalized cross validation) and iterate changing λ until it is minimized.
Estimation with Regression Spline Method (RSM)
Smoothing spline become less practical when sample size n is large, because it uses n knots. Regression spline is a more general approach to spline fitting. Smoothing spline require many parameters to be estimated, typically at least as many parameter as observations. A regression spline is a piecewise polynomial function whose highest order nonzero derivative takes jumps at fixed knots. Usually, regression splines are smoothed by deleting nonessential knots. When the knots are selected, regression spline can be fitted by ordinary least squares. For further discussion on selection of knots, see study of Ruppert and Carrol (2000).
f(ti) in equality (Eq. 10) is approximated by:
| (14) |
where, p≥1 is an integer (order of the regression spline and usually chosen a priori), b1,...,bK are independently and identically distributed (i.i.d) with ![]() , (t)+ = t if t>0 and 0 otherwise and κ1<...,κk are fixed knots (min(ti) < κ1,....,< κk< max(ti)).
, (t)+ = t if t>0 and 0 otherwise and κ1<...,κk are fixed knots (min(ti) < κ1,....,< κk< max(ti)).
Using vector and matrix notation model 10 can be expressed as:
| (15) |
Where:
 |
and
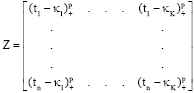 |
where, b = (b1,...,bK)T is the vector of coefficients and η = (η1,...,ηn)T is a vector of the random error. Predicted value of ![]() in Eq. 10 is given by:
in Eq. 10 is given by:
| (16) |
Regression spline estimators
![]() of (β, f) are defined as the minimizer of:
of (β, f) are defined as the minimizer of:
| (17) |
where, λ>0 is a smoothing parameter such as in Eq. 11. As λ→∞, the regression spline converges to a pth degree polynomial fit. As λ→0}, the regression spline converges to the Ordinary Least Squares (OLS) fitted spline. For a pre-specified value of λ the corresponding estimators for β and f based on Eq. 15 can be obtained as follows (Ruppert et al., 2003):
| (18) |
where, ![]() .
.
| (19) |
The smoothing parameter λ and the number of knots K must be selected in implementing the regression spline. However, λ plays a more essential role. See for a detailed discussion of the knot selection (Ruppert, 2002). The solution can be obtained in S-Plus.
Additive Regression Model (ARM)
The semi-parametric model has been used for estimation of the parameters in Eq. 10. However, there are situations in which a dummy variable specification does not capture all fluctuations because of existing any seasonal effect. Therefore, here, a more general case for seasonal component has been considered as follows:
| (20) |
where, g ∈ C2[a, b], vi's denote the terms of random error with zero mean and common variance ![]() . By substitution of the Eq. 8 and 20 in Eq. 7, yi is obtained as:
. By substitution of the Eq. 8 and 20 in Eq. 7, yi is obtained as:
| (21) |
where, ui's are the terms of random error with zero mean and constant variance ![]() .
.
The model presented in Eq. 21 has a fully non-parametric model because parametric component is missing. These models are called as additive non-parametric regression models. In order to estimate the model in Eq. 21, the criterion Eq. 11 and 21 can be generalized in an obvious way. Estimator of the model 21 is based on minimum of the penalized residual sum of squares (Hastie and Tibsirhani, 1999):
| (22) |
where, the first term in Eq. 22 denotes the Residual Sum of the Squares (RSS) penalizing the lack of fit, the second term multiplicand by λ1 denotes the roughness penalty for the f and the third term multiplicand by λ2 denotes the roughness penalty for g Firstly, Eq. 22 can be written as:
| (23) |
where, Kf is a penalty matrix for f and Kg is a penalty matrix for g. Then, by differentiating according to f and g and afterwards, by setting to zero, the estimators of f and g are defined as:
| (24) |
| (25) |
MEASURING MODEL PERFORMANCE METHODS
In order to evaluate the predictions of a model with observations, the following statistical performance measures, which include the Mean Square Error (MSE), the Root Mean Square Error (RMSE), the Mean Absolute Error (MAE) and the Mean Absolute Percentage Error (MAPE) have been used (Carey and Rob, 2002). Forecast evaluation measurements are defined as following:
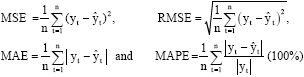 |
where, yt is represent the observed values, ![]() is indicate the forecasted values and Mean is the arithmetic mean value.
is indicate the forecasted values and Mean is the arithmetic mean value.
A perfect model would have MSE or RMSE, MAE and MAPE ≅ 0.00. Of course, because of the influence of random errors, there is no such thing as a perfect model in time series modeling.
EXPERIMENTAL EVALUATIONS
Here, a real data sets occurred in Turkey is discussed as experimental. Appropriate non-parametric regression and ANN models were chosen by doing experiments to forecast and these models are also compared with each other. To conduct these experiments, SNN, S-Plus and R-Programs are used.
Data Set
The real data set is from Turkish Statistical Institute (TÜİK) analyzed by Aslanargun et al. (2007). The data can be found in http://www.tuik.gov.tr and represent the number of monthly tourist coming to Turkey between January 1984 and December 2003. The data set is divided into two parts for the use in training and forecasting. In the first part, 216 monthly data are taken into account for the period of the January 1984-December 2001 period. These data are used in training to construct the models. In the second part, with the help of the models constructed in the first part, the performances of those models are calculated using the 24 monthly data for the January 2002-December 2003 period.
Selection of the Appropriate ANN Models
The 216 monthly data were used in training of the network. An evaluation of the model was made depending on the forecasts of the 24 monthly data. The best model have been selected by scores obtained from MSE, RMSE, MAE and MAPE. As the initial weight and bias values of the network were random, experiments with 150 replications were made for the same network structure and the models giving the best forecasts were determined. Because of the monthly tourist arrival data included seasonality, the number of input units was determined as 12. During these experiments, various neural network algorithms with single layer, with one or two hidden layers, MLP and the RBF models were applied on the data set. As the initial 12 data were lost because of the seasonality, 204 from the 216 data were used to adjust the weights. In the training stage of the network, data were divided into two parts: 132 of the 204 data were used for training and 72 data were used for validation. This division was used to restrict memorization of the network and provided for better forecasts (Bishop, 1995; Haykin, 1999).
Among the ANN models, the MLP (12:3:1) model have indicated the best performance. The CG algorithm indicated the best performance on the 51th epoch. A hyperbolic tangent function is applied in the hidden unit and the linear activation function is applied in the output unit. The weights and biases of the MLP (12:3:1) model are shown in Table 1.
Constructing the Appropriate Non-Parametric Models
The 216 monthly data set including January 1984-December 200 period were used in training the models called as semi-parametric and additive regression model. For estimation of these models, we need to select smoothing parameter λ. In general, the λ can be selected by using automatic selection methods such as Cross Validation (CV), Generalized Cross Validation (GCV). In practice, it is reasonable to select the λ by specifying degrees of freedom (df = trace (Sλ)) for the non-parametric components (Hastie and Tibshirani, 1999). Therefore, the df is used to select the smoothing parameter λ in smoothing spline. On the other hand, both the smoothing parameter λ and the number of knots K must be selected in implementing the regression spline. The solution is obtained by S-Plus and R programs.
| Table 1: | The weights and biases of the MLP (12:3:1) |
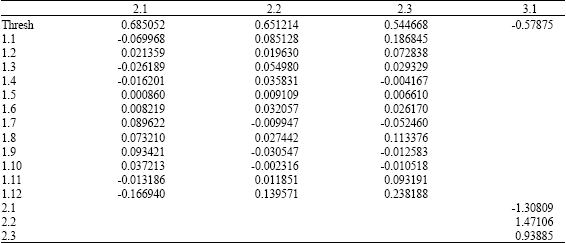 | |
| The row and column header numeric terminology first lists the layer, then the unit number within the layer. For example, 2.1 stands for unit 1 in layer 2 | |
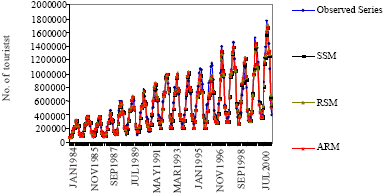 | |
| Fig. 1: | Observed number of tourists and their estimation values obtained by appropriate SSM, RSM and ARM |
Secondly, we consider an additive regression model where both the seasonal and the trend components are unknown smooth functions of time. So, we have chosen λ1 and λ2 parameters by specifying the df. Observed number of tourist for the January 1984-December 2001 period and the tourist estimation results obtained by appropriate non-parametric models are shown in Fig. 1.
Figure 1 shows that the data have an upward trend together with seasonal variation. In these series, the main advantage of the non-parametric regression models that perform prediction by means of the models without data loss. In other words, as the initial 216 data are used to estimate the model, 216 residuals are obtained for each of non-parametric model. Consequently, 216 data was used to estimate non-parametric regression models called as smoothing spline, regression spline and additive regression models.
COMPARISONS OF THE MODELS
An evaluation of the non-parametric regression models obtained by using S-Plus and R programs was made depending on the forecasts for the January 2002-December 2003 period. Namely, we calculated the performance values of the non-parametric regression and ANN models for the mentioned period. Table 2 shows for each model, the values of the MSE, RMSE, MAE and MAPE called as performance indicators. The scores of the MSE, RMSE, MAE and MAPE belong to MLP model are lower than the ones of the concurrent specifications. In that sense, the MLP model outperforms the other formulations. Furthermore, as shown Table 2, the SSM model has indicated better performance than the RSM and ARM since SSM has had the lowest scores of the model evaluation criteria among the non-parametric models.
For test data composed of the 24 values, the observed and forecasted values obtained by different models are calculated, but they are only given as graphically since they would occupy very much place. Observed and their forecasted values by the models are shown in Fig. 2.
As shown in Fig. 2, the output from the MLP model shows that predicted and observed values very close to each other. However, the output from the RBF model presents that there is big difference between actual and predicted observations.
| Table 2: | Performance values for the selected models |
 | |
| *The model having best performance | |
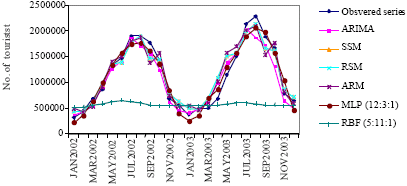 | |
| Fig. 2: | Observed and their forecasted values by the models |
The outputs shown in Fig. 2 support the ideas advanced in the Table 2.
RESULTS AND DISCUSSION
It is proved that the ANN model gives a comparable performance to the ARIMA model for longer time horizons (Zhang, 2003). There have a great deal of studies comparing various neural network and some non-parametric methods for time series. For example, Sallur-Ruiz et al. (2008) indicated that MLP model outperformed than other methods. Different ANN and non-parametric methods have been applied to time series data set in the study. However, most of them are designed to predict the time series. In this study, these methods mentioned here are considered as a comparative on aspect of forecasting performance.
It is known that neural networks very good performance in time series forecasting problems. As can be seen from Table 2, the MLP (12:3:1) have performed very good performance, while the RBF have not performed well enough. This case supports the idea that the RBF is usually unsuccessful in extrapolation problems (Bishop, 1995). On the other hand, as shown Fig. 2, the values forecasted by ARIMA, SSM, RSM, ARM and MLP (12:3:1) are closely following the real observed values, whereas the values forecasted by the RBF is not proper the observed series. It is also seen that RBF is not good predictor for such time series.
Non-parametric regression models can be considered as alternative method to ANN models. The SSM indicated a good empirical performance among the non-parametric models, while another non-parametric model called as ARM showed the worst performance. As a result, our opinion is that MLP can be useful in time series forecasting problems included seasonality and trend. We propose to use the MLP, especially on these type series. Furthermore, the SSM model can be used as an alternative method to the MLP.
REFERENCES
- Abraham, A. and B. Nath, 2001. A neuro-fuzzy approach for modeling electricity demand in Victoria. Applied Soft Comput. J., 1: 127-138.
CrossRefDirect Link - Aslanargun, A., M. Mammadov, B. Yazıcı and S. Yolacan, 2007. Comparison of ARIMA, neural networks and hybrid models in time series: Tourist arrival forecasting. J. Stat. Comput. Simulat., 77: 29-53.
CrossRefDirect Link - Bishop, C.M., 1995. Neural Networks for Pattern Recognition. 1st Edn., Oxford University Press, USA., ISBN-13: 978-0198538646,.
Direct Link - Carey, G. and L. Rob, 2002. Modeling and forecasting tourism demand for arrivals with stochastic nonstationary seasonality and intervention. Tourism Manage., 23: 499-510.
CrossRef - Delen, D., G. Walker and A. Kadam, 2005. Predicting breast cancer survivability: A comparison of three data mining methods. Artif. Intell. Med., 34: 113-127.
CrossRefDirect Link - Ferreira, E., V. Nunez-Antona and J. Rodriguez-Poob, 2000. Semi-parametric approaches to signal extraction problems in economic time serie. Comput. Stat. Data Anal., 33: 315-333.
Direct Link - Gareta, R., L.M. Romeo and A. Gil, 2006. Forecasting of electricity prices with neural networks. Energy Convers. Manage., 47: 1770-1778.
CrossRef - Moller, F.M., 1993. A scaled conjugate gradient algorithm for fast supervised learning. Neural Networks, 6: 525-533.
CrossRefDirect Link - Ruppert, D., 2002. Selection the number of knots for penalized spline. J. Comput. Graphical Stat., 11: 735-757.
CrossRefDirect Link - Sallur-Ruiz, E., B.J. Ordiers, E.P. Vergara and S.F. Capuz-Rizo, 2008. Development and comparative analysis of tropospheric ozone prediction models using linear and artificial intelligence-based models in Mexicali, Baja California (Mexico) and Calexico, California (US). Environ. Modell. Software, 8: 1056-1069.
Direct Link - Srinivasulu, S. and A. Jain, 2006. A comparative analysis of training methods for artificial neural network rainfall-runoff models. Applied Soft Comput., 6: 295-306.
CrossRefDirect Link - Zhang, G., B.E. Patuwo and M.Y. Hu, 1998. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast., 14: 35-62.
CrossRefDirect Link - Zhang, G.P., G.E. Patuwo and M.Y. Hu, 2001. A simulation study of artificial neural networks for nonlinear time-series forecasting. Comput. Operat. Res., 28: 381-396.
CrossRefDirect Link - Zhang, G.P., 2003. Time series forecasting using a hybrid arima and neural network model. Neurocomputing, 50: 159-175.
CrossRef