
Teh Chao Ying
Department of Multimedia, Faculty of Computer Science and Information Technology, University Putra Malaysia, Serdang, 43400, Malaysia
Shyamala Doraisamy
Department of Multimedia, Faculty of Computer Science and Information Technology, University Putra Malaysia, Serdang, 43400, Malaysia
Lili Nurliyana Abdullah
Department of Multimedia, Faculty of Computer Science and Information Technology, University Putra Malaysia, Serdang, 43400, Malaysia
Journal of Applied Sciences
Year: 2015 | Volume: 15 | Issue: 2 | Page No.: 289-294







ABSTRACT
Music documents are often classified based on genre and mood. In recent years, features from lyrics text have been used for classification of musical documents and the feasibility of lyrics features to classify musical documents has been shown. In this study an approach to lyrics based musical genre classification was presented which utilizing mood information. From the analysis of the lyrics text in the data collection, correlation of terms between genre and mood was observed. Based on this correlation of terms, new weighting equation with combine weights from genre and mood was introduced and implemented in two different ways. Ten musical genre and mood categories were selected respectively based on a summary from the literature. Musical genre classification experiments were performed using a test collection consists of 1000 English songs. To confirm present approach can improve the genre classification, experiments were conducted using similar weighting metric from previous study. Experimental results with new weighting equation reveal improvement in musical genre classification.
PDF Abstract XML References Citation
Received: March 28, 2014;
Accepted: November 10, 2014;
Published: December 06, 2014
How to cite this article
Teh Chao Ying, Shyamala Doraisamy and Lili Nurliyana Abdullah, 2015. Lyrics-Based Genre Classification Using Variant tf-idf Weighting Schemes. Journal of Applied Sciences, 15: 289-294.
DOI: 10.3923/jas.2015.289.294
URL: https://scialert.net/abstract/?doi=jas.2015.289.294
DOI: 10.3923/jas.2015.289.294
URL: https://scialert.net/abstract/?doi=jas.2015.289.294
INTRODUCTION
With the advances in computers and network technology, a great amount of digital music documents are being createdand stored. Managing these large collections requires effective Music Information Retrieval (MIR) systems where documents relevant to a user query can be retrieved. Users commonlyaccess and retrieve musical document using queries such as musical excerpts, lyrics text, musical genre or musical mood.
Musical genres such as pop, country and soul are labels created and used by human for describing music(Tzanetakis and Cook, 2002). One other way in musicalclassification is to classified musical documents based on mood such as sad, happy and angry. Users often want tosearch for music, based on certain genre or mood. Therefore, many studies have been conducted in the area of musical genre and mood classification (Hu et al., 2009; Laurier et al., 2008; Neumayer and Rauber, 2007).
Musical genre and musical mood classification in MIR has been widely based on audio features extracted from digital musical recordings. In recent years, a combination of lyrics text and audio features are used for musical classification (Hu and Downie, 2010a; Laurier et al., 2008; Mayer et al.,2008a; Yang and Lee, 2004). Researchers start to classify musical documents based on the features extracted from lyrics text (Kim and Kwon, 2011; Van Zaanen and Kanters, 2010). To date, most musical classification task are solely based on either genre or mood. However, researchers have started to exploit musical classification by looking at the correlation between genre and mood (Lin et al., 2009).
The work presented in this study was premised on the belief that genre and mood would be complementary. A new approach on musical genre classification based on the correlation between genre and mood using lyrics text was proposed. As correlated terms were found to exist in the lyrics text, new weighting equations to improve the performance of musical genre classification were introduced in this study. Inpresent study by experiments using these proposed weighting equations the classification results were significantly outperforms the traditional genre classification which used solely genre information.
One of the earliest studies in mood classification that combined the used of lyrics text and audio features in MIR was carried out by Yang and Lee (2004). However, they only carried out the experiment with significant small dataset which was 145 songs with lyrics. Laurier et al. (2008, 2010) study had confirmed the relevance of the lyrics to convey emotions or at least that the mood expressed in music and acoustical data is correlated with information contained in the text. Their study had shown that the combination of audio and lyrics features offer an improvement in the classification performance.
Hu et al. (2009), used only lyrics features to classify 18 mood categories derived from user tags. They examined the role that lyrics text can play in improving audio musical mood classification. Hu and Downie (2010a), studied that mood classification in music can be significantly improved when combining lyrics and audio features. Van Zaanen and Kanters(2010) experimental results based on lyrics, show that word metrics (lyrics text) provide a valuable source of information for automatic mood classification of music. In their research, metrics such as term frequencies and Term Frequency Times Inverse Document Frequency (tf-idf) values are used to measure relevance of words to the different mood categories. Brilis et al. (2012) presented a case-study evaluation of different classification algorithms for songs represented by audio and lyrics features and achieved accurate results in their experiments. However, their research only involved Modern Greek music. Kumar and Minz (2013) had introduced the use of Senti Word Net for mood classification of lyrics text data. Oh et al. (2013) propose music mood classification using intro and refrain parts of lyrics. However, for both of these studies, the dataset included were very limited i.e., 145 songs and followed by 100 songs.
As for genre classification Neumayer and Rauber (2007) studied for genre classification investigated the correlation of the combinational approach using and audio features. In depth studies using lyrics features in genre classification were performed by Mayer et al. (2008a) and Mayer and Rauber, (2010). Lyrics features that used in their study includes rhyme pattern, part of speech characteristic and text statistic features. In their study, lyrics texts were processed using the Bag-of- Words features and then weighted by tf-idf.
According to Lin et al. (2009) musical genre and mood have been studied widely in MIR field; however, the intrinsic correlation between them seldom explored. Therefore, using digital music document they present a statistical association analysis to examine and exploit the correlation between musical genre and mood. In this study, correlation between musical genre and mood will be study closely using lyrics text. Based on the analysis of the lyrics text in the data collection,correlation of terms between genre and mood will be observed and utilized in improving musical genre classification.
APPROACHBag-of-Words (BOW) are collections of unordered words disregarding grammar. Each word or term is assigned with a value as their weights according to their importance or significance for the classification with the process called “term-weighting”. Term weights can be calculated in many ways. The term weighting strategies based on Term Frequency Times Inverse Document Frequency (tf-idf) schemes and other weighting schemes will be discuss.
The tf-idf weighting scheme for lyrics text: According to the study Van Zaanen and Kanters (2010), tf-idf was used to describe the relative importance of a term for a particular musical mood class. Therefore, the relative importance of a term for a particular mood class will be similarly used but it is for musical genre class. The tf-idf value of each term in the lyrics text is used as weights to indicate relevance with respect to genre class. With this method, genres are described by the combined lyrics of all songs that having that particular genre class assigned.
The approach described have indicated that lyrics of all songs of a particular genre are taken and combine as if they are one genre document, i.e., when there are 100 lyrics under genre reggae, this 100 lyrics will be combine and become one document, name as “Reggae document”. This “Reggaedocument” will now only describing a particular genre which is reggae. This means that each genre class will corresponds to one document.
The tf-idf consists of two components which are term frequency (tf) and inverse document frequency (idf). The tf measures the importance of term t in document, i.e., genre, d with n occurrences of the term in document d, divided by h, total number of occurrences of all terms in document d:
| (1) |
One of the problem commonly encounter when using tfis that most terms that having high frequency are usually function words, such as “that”, “is” or “and”. These function words do not really help in classifying lyrics to genres as they do not carry any meaning that can represent a particular genre class. What are required to be taken into consideration are terms that occur in one or more genre classes:
| (2) |
where, idf measures the importance of atermin a document. In Eq. 2, the total number of documents, representing genres, N is divided by document frequency dft, the number of documents in the collection that contain term t and taking the logarithm of that quotient. In this study for music lyrics situation, when a term is found in the lyrics text of one or only a few genres, the idf will be high. The idf value by itself is not particularly useful as it is too coarse-grained especially when there are only a few of genre classes, however idf can be combine with tf to produce a composite weight for each term, resulting in the tf-idf:
tf - idf t,d = tft,d × idft | (3) |
where, tf-idf is used to calculate the relevance of a term for a particular genre: High tf-idf values indicate high relevance of the term to the genre.
The tf-idf provides for one particular term, a weight for each of the genre classes. A song lyrics is always contain more than one word, which allows for a more robust computation of the relevance of the genre document for the lyrics. According to Van Zaanen and Kanters (2010), tf-idf values of all the terms in the lyrics text for classification can be combined by adding the values of the separate terms.
As ten genre classes are included in this study, combining the lyrics of all songs of a particular genre as one document results in having ten genre documents. Ten documents are obviously less than the amount of documents normally under consideration in a tf-idf setting. It is noteworthy that, many terms will found in all genres, which means that in those cases the idf will be zero which results in a zero tf-idf for all genre classes for that particular term. This becomes a very useful aspect of tf-idf weights in a small document collection. Specifically, terms that do not related in deciding the correct genre of lyrics, such as function words, are automatically filtered out, as they are having zero tf-idf value.
Based on Eq. 3, Van Zaanen and Kanters (2010) evaluated the effects of adding additional tf to tf-idf in classifying moods. A modified tf-idf function: Linearly combining the tf metric to tf-idf was introduced, resulting in tf+tf-idf. The results of their experiment using tf+tf-idf in musical mood classification had shown improvement in accuracy.
Sublineartf scaling: For assigning a weight for each term in the document, a number of alternatives to tf-idf have been considered. According to Manning et al. (2008), it seems unlikely twenty occurrences of a term in a document truly carry twenty times the significance of a single occurrence. There has been considerable research into variants of term frequency that go beyond counting the number of occurrences of a term. The modification proposed is sublinear tf scaling where we use instead the logarithm of the term frequency (tf), which assigns a weight given by:
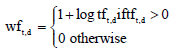 |
As defined by Manning et al. (2008), the weighting equation will be modified by replacing tf-idf by wf-idf as shown in Eq. 2:
(4) |
Where:
| wft,d | = | Weight of term t in document d |
| idft | = | Inverse document frequency of a term t (log N/dft) |
| N | = | Total number of documents in a collection |
| dft | = | Number of documents in the collection that contain a term t |
Wf-idf weighting scheme for lyrics text: Musical genre and mood provide complementary descriptions of music content and often correlate with each other (Lin et al., 2009). For example, a punk rock song is often aggressive or angry and a blues song is more likely to be sad. From the analysis of the lyrics text in the data collection, correlation of terms between genre and mood was observed. Based on this correlation of terms, new weighting equations with combine weights from genre and mood were introduced and implemented in two different ways.
In Eq. 2, wft,d refers to the weight of term t in document d. In the new weighting equations, wft,dwill be continue to used, however d will be denoted for genre document, “dg”. Therefore, the weight for a term in genre document would be given by:
| (5) |
Where:
| wft,dg | = | Weight of term t in document genre document dg |
| idft | = | Inverse document frequency of a term t (log N/dft) |
| N | = | Total number of documents in a collection, |
| dft | = | Number of documents in the collection that containa term t |
By considering correlation between genre and mood, given a term t in document dg, t would also appear in one or more mood documents, dm. When a few of mood documents are having term t, the total number of these mood documents was need to know. Therefore, M as the total number of mood documents that contain term t is introduced. In order to emphasis the correlated terms, wf-idft,d would be confined to the correlated terms and therefore be denoted as:
Using the tf+tf-idf notion as proposed by Van Zaanen and Kanters (2010), wf-idft,dg is combine linearly with resulting in Eq. 6. In addition to linearly combining this correlated term weights, the effects of non-linearly adding is also investigated in Eq. 7:
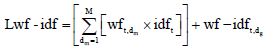 | (6) |
| (7) |
Where:
| wft,dm | = | Weight of term t in mood document dm thatcontains term t |
| wft,d | = | Weight of term t in genre document d, |
| M | = | Total number of mood documents that containterm t |
| idft | = | Inverse document frequency of a term t (log N/dft) |
| N | = | Total number of documents in a collection |
| dft | = | The number of documentsin the collection thatcontain a term t |
MATERIALS AND METHODS
The test collection and data preprocessing was used, followed by illustration of musical genre and mood categories in this study. Then the results of present classification experiments, were presented where the performance of musical genre classification using various weighting equations was compared.
Test collection: Music information retrieval research in general suffers from a lack of a commonly acknowledged test collection due to different reasons. Nonetheless, some collections were available to the public such as uspop 2002 collection (Berenzweig et al., 2003). However, the genres of the songs in this collection i.e., Rock, Rap, Electronica and Country were different with the genre categories in this study. Due to the unavailability on getting a standardized test collection, Test collection i.e., 1000 English songs selected randomly from a private collection for the classification experiments was designed.
Data preprocessing: Lyrics text has unique structures and characteristics. Most lyrics consist of sections such as intro, verse, chorus and instrument. Repetitions of words and sections are very common. However, very few available lyrics texts were found as verbatim transcripts, i.e., a full transcript of converting spoken word into text such that a message is captured exactly the way it has been spoken (in our case, full transcript of converting the word sang in the song into lyrics text). Instead, repetitions were annotated as instructions like “repeat choru 2x” and “back to intro” (Hu et al., 2009).
In order to get the proper lyric texts in our test collection, the collected lyrics were manually cleansed, which first involves checking whether the fetched lyrics match the song, followed by comparing three different versions of song in term of spelling, lyrics structure (paragraphing) and the words used. In this study, the lyrics preprocessing steps were done similarly to other studies (Hu et al., 2009; Mayer and Rauber, 2010). Instructions such as “chorus” and “fade out” were removed as they are not properly part of the lyrics and replaced with the word itself to get the complete lyrics text document.
Musical genre categories: Musical genre classification have been focused in many MIR studies (Li and Tzanetakis, 2001; Neumayer and Rauber, 2007). From the widely used websites which categorized music by genre, allmusic.com and last.fm refer to the genres categories in Mayer and Rauber (2010). A total number of 10 genre types including pop, blue, country, folk, R and B, reggae, grunge, punk rock, soul and metal in test collection were selected.
For each song in the test collection, the genre was determined using the social tag labeled by the listener from the website stated above. Only those songs that have the same genre tag from these two website were selected.
Musical mood: Various mood categories were used in previous study in this field. The number of categories in general range from four to twenty three categories (Laurier et al., 2008; Hu et al., 2009; Yang and Lee, 2004; Hu and Downie, 2010b). As ten genres were chosen, ten mood categories were also chosen. These mood categories are happy sad, angry, relaxed, calm, gloomy, romantic, confident, disgusted and aggressive.
In this study, the relevancy of the mood of the songs in the test collection was done in several steps. Five under-graduate students were first invited to label the mood of the songs in present test collection. Given the song lyrics, they were asked to read through the lyrics and label the mood of each of the song using the mood categories used in this study including happy, sad, angry, relaxed, calm, gloomy, romantic, confident, disgusted and aggressive. The mood of the song in present test collection was further verified using Conceptnet, a freely available common sense knowledge base and natural language processing toolkit with mood guessing functions. Summarizing the result obtains from the under-graduate student and conceptnet a comparison of mood relevancy was then performed. If the mood of a song differed widely, another judgment was performed to decide the relevant mood for the song.
RESULTS AND DISCUSSION
Classification accuracy was used as the performance measure in this study. The WEKA4 machine learning toolkit was employed for this purpose. Three learning algorithms, k-Nearest-Neighbour (kNN), Naïve Bayes (NB) and Support Vector Machines (SVM) were chose similarly to the study by Mayer et al. (2008b). The experiments were run based on a ten-fold cross-validation and further averaged over five repeated runs.
Five set of experiments were conducted with the baseline i.e., tf-idf weighting equation and another four variant tf-idf weighting equations. In Table 1, the average results using three differing learning algorithms for genre classification was described. First, it can be noted that, the classification results with different weighting equation are varies. When using tf-idf weighting equation, the results ranges from 47.2222 to 65.5152. Country and Reggae achieved higher accuracy compared to other genre type, while Metal had the lowest accuracy.
| Table 1: | Average results of genre classification using different weighting equation |
 | |
In Country songs, some typical terms such as“road”, “cowboy”, “house”, “highway”, “American” and “Whiskey” could be identified while in Reggae songs, words like “dem”, “mi”, “haffi”, “fi”, “inna” and “jah” happen in a high frequency. The occurrence of these typical terms contributes to the higher classification accuracy in both of the genre.
When using wf-idft,dg weighting equations the classification experiment, the results ranges from 61.3494 to 75.4841. It is clear from the results that classification performance was improved. Reggae achieved the highest accuracy again under this weighting scheme. The same scenario as described i.e., the occurrence of typical words is highly likely the reason why reggae still performed better compared to other genre categories.
When combining the weight of mood with weight of genre, it can be observed that better results than with the using solely genres weights was achieved. Especially for Lwf-idf weighting equation, those improvements are statistically significant when compared to tf-idf weighting equation. The result ranges from 70.9742 to 79.1412 with Lwf-idf whereby with NLwf-idf the result ranges from 63.1864 to 75.7179. The biggest improvement of classification accuracy was achieved by Punk Rock which improved from 47.2222 to 75.3806. Other genres that improve greatly were Pop and R and B.
To confirm present approach where Lwf-idf and NLwf-idf weighting equations can improve musical genre classification accuracy, experiments using tf+tf-idf metric as introduced was also performed by Van Zaanen and Kanters (2010). Compared to Lwf-idf and NLwf-idf weighting equations, tf+tf-idf metric yields worsen performance with the results ranges from 56.1030 to 77.3169. With Lwf-idf, nine out of ten genres achieve higher accuracy compared to tf+tf-idf, while with NLwf-idf; eight out of ten genres outperform tf+tf-idf. It is interesting to note that tf+tf-idf metric achieves better results in reggae compared to both Lwf-idf and Nlwf-idf. Regarding the better results in reggae using tf+tf-idf metric, the contribution of typically terms found in Reggae songs was thought. As discussed earlier, Reggae songs contain terms such as “dem”, “mi”, “haffi” etc. in a high frequency. Those wordsrender to well distinguishable a Reggae song withoutconsidering the underlying mood of that specific song.
Compared to the baseline results achieved with tf-idfweighting equation, all four variant tf-idf weighting equationsyield better performance. It can be noted that, higher resultsespecially for Lwf-idf, followed by Nlwf-idf was achived. Theimprovements thus indicate that the Lwf-idf and NLwf-idfweighting equations well classified genre.
CONCLUSION
Music Information Retrieval is focus on solely genre classification. However, researchers have revealed that this narrow focus has limited the possibilities in enhancing the performance of classification task. In fact, genre and mood provide complementary descriptions of music and correlatewith each other.
In this study, A new approach on musical genre classification based on the correlation between genre and mood using lyrics text was presented. The aim of this study is to improve the performance of lyrics-based musical genre classification. From the analysis of the lyrics text in the data collection, correlation of terms between genre and mood was observed. Based on this correlation of terms, new weighting equation with combine weights from genre and mood was introduced and implemented in two different ways: Linear and non-linear. The performance of linear (Lwf-idf) andnon-linear (NLwf-idf) weighting equations clearly indicates that adding additional weights when classify genre is a promising approach. Musical genre classification with Lwf-idf and NLwf-idf weighting equations reveals improvement in accuracy and Lwf-idf equation showed the best results.
REFERENCES
- Brilis, S., E. Gkatzou, A. Koursoumis, K. Talvis, K. Kermanidis and I. Karydis, 2012. Mood Classification Using Lyrics and Audio: A Case-Study in Greek Music. In: Artificial Intelligence Applications and Innovations, Iliadis, L., I. Maglogiannis, H. Papadopoulos, K. Karatzas and S. Sioutas (Eds.). Springer, Boston, USA., ISBN: 9783642334115, pp: 421-430.
- Hu, X. and J.S. Downie, 2010. Improving mood classification in music digital libraries by combining lyrics and audio. Proceedings of the 10th Annual Joint Conference on Digital Libraries, June 21-25, 2010, Gold Coast, Australia, pp: 159-168.
CrossRef - Hu, X. and J.S. Downie, 2010. When lyrics outperform audio for music mood classification: A feature analysis. Proceedings of the 11th International Society for Music Information Retrieval Conference, August 9-13, 2010, Utrecht, Netherlands, pp: 619-624.
Direct Link - Kim, M. and H.C. Kwon, 2011. Lyrics-based emotion classification using feature selection by partial syntactic analysis. Proceedings of the 23rd IEEE International Conference on Tools with Artificial Intelligence, November 7-9, 2011, Boca Raton, FL., USA., pp: 960-964.
CrossRef - Laurier, C., J. Grivolla and P. Herrera, 2008. Multimodal music mood classification using audio and lyrics. Proceedings of the 7th International Conference on Machine Learning and Applications, December 11-13, 2008, San Diego, CA., USA., pp: 688-693.
CrossRef - Laurier, C., O. Meyers, J. Serra, M. Blech, P. Herrera and X. Serra, 2010. Indexing music by mood: Design and integration of an automatic content-based annotator. Multimedia Tools Appl., 48: 161-184.
CrossRefDirect Link - Lin, Y.C., Y.H. Yang, H.H. Chen, I.B. Liao and Y.C. Ho, 2009. Exploiting genre for music emotion classification. Proceedings of the IEEE International Conference on Multimedia and Expo, June 28-July 3, 2009, New York, pp: 618-621.
CrossRef - Mayer, R., R. Neumayer and A. Rauber, 2008. Combination of audio and lyrics features for genre classification in digital audio collections. Proceedings of the 16th ACM International Conference on Multimedia, October 26-31, 2008, Vancouver, Canada, pp: 159-168.
CrossRef - Oh, S., M. Hahn and J. Kim, 2013. Music mood classification using intro and refrain parts of lyrics. Proceedings of the International Conference on Information Science and Applications, June 24-26, 2013, Suwon, South Kore, pp: 1-3.
CrossRef - Tzanetakis, G. and P. Cook, 2002. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process., 10: 293-302.
CrossRef