
Anmar Abuhamdah
Department of Computer Science, College of Computer Science and Engineering, Taibah University, Madinah, KSA
Rawnaq Kittaneh
Department of Computer Science, College of Computer Science and Engineering, Taibah University, Madinah, KSA
Jawad Alkhatib
Department of Computer Science, College of Computer Science and Engineering, Taibah University, Madinah, KSA
Mohd Zakree Ahmad Nazri
Data Mining and Optimisation Research Group (DMO), Center for Artificial Intelligence Technology, Universiti Kebangsaan Malaysia, 43600, UKM, Bangi, Selangor, Malaysia
Journal of Applied Sciences
Year: 2014 | Volume: 14 | Issue: 5 | Page No.: 426-435







ABSTRACT
Clustering problem is an important area of data mining. The goal of the clustering is to partitioning N objects into K clusters with similar characteristics for one cluster and dissimilar to other clusters by using any algorithm to generate the initial clusters partition. This initial clusters quality will be measured based on a certain distance (or object) function. The initial partitioning can be improve by iteratively explores its neighbor solutions looking for a better one by any algorithm. The neighbor’s solutions are achieved by reallocating some patters (objects) by using any neighborhoods structures. However, the way of employing the neighborhoods structures will affects the solution quality. Therefore, in this work, a swap mechanism is proposed to increase the diversification for the neighborhood structure. The proposed mechanism tested on two algorithms previously implemented over six medical clustering problem (that are available in UCI Machine Learning Repository) by using two way of the distance calculation. This work, also present a third distance calculation to minimize the distances between the clusters. Experimental results show that, using the swap mechanism and the third distance function on the algorithms is able to produce significantly better quality solutions than not using it on all datasets.
PDF Abstract XML References Citation
Received: November 06, 2013;
Accepted: January 04, 2014;
Published: February 10, 2014
How to cite this article
Anmar Abuhamdah, Rawnaq Kittaneh, Jawad Alkhatib and Mohd Zakree Ahmad Nazri, 2014. Swap Mechanism for Medical Clustering Problems. Journal of Applied Sciences, 14: 426-435.
DOI: 10.3923/jas.2014.426.435
URL: https://scialert.net/abstract/?doi=jas.2014.426.435
DOI: 10.3923/jas.2014.426.435
URL: https://scialert.net/abstract/?doi=jas.2014.426.435
INTRODUCTION
Clustering is the process of grouping a set of physical data (objects) into classes of similar data, which is consider as unsupervised data mining technique (Brucker, 1978; Jain et al., 1999). Clustering is dividing the input space based on some similarity measures to number of clusters (Saha et al., 2010). A cluster is a collection of similar objects within the same cluster that can be treated as one group and dissimilar to the objects in other clusters (groups) (Brucker, 1978; Saha et al., 2010). Clustering is considered as NP-hard problem, when the number of clusters exceeds three clusters (Saha et al., 2010) or two clusters (Dasgupta and Freund, 2009; Mahajan et al., 2009). All clusters are categorized depending on a certain distance function (that calculate the minimal distance) used to achieve the similarity/dissimilarity condition of data representation, so that the cluster contains most “similar” objects and different clusters enclose “dissimilar” patterns in terms of the data set attributes (Saha et al., 2010). Clustering approaches are used to partition the objects into clusters (Holland, 1975) to generate an initial clusters partition (or initial solution) such as K-Means approach and Multi K-Means approach (Davidson and Satyanarayana, 2003), the Fuzzy C-Means approach (Hong, 2006) and many more. For further information please refer to (Berry and Linoff, 1997).
Clusters quality measured by calculating the minimal distance (that calculates based on the distance function) quality (Saha et al., 2010). The smaller value overall the minimal distance values indicates better clustering quality (Hong, 2006). Finding a good clustering (solution) quality depends on the methodology used and the problem representation employed during the search (Jain et al., 1999). Optimization algorithms are used in clustering problems in order to minimize the minimal distance quality (Jain et al., 1999), which starts with an initial clusters partition generation and iteratively explores its neighbor solutions (partition), seeking a better one. Recently, there are many optimization algorithms were applied to improve the current solution in order to minimize the differences (or minimal distances) within the same cluster and to maximize the differences between the set of clusters, such as Tabu Search (Liu et al., 2008), Artificial bee colony (Zhang et al., 2010) and many more. However, these algorithms are employing neighborhood structures, which reallocate the neighbors on the clusters and affect the solution quality (Hong, 2006; Liu et al., 2008).
Therefore, in this study, we propose a swap mechanism as a neighborhood structure to increase the diversification of the neighborhood structures, which may help in improving the solutions (or minimal distances) qualities. In order to evaluate the performance of the swap mechanism, the swap mechanism is embedded with two algorithms previously implemented for the medical clustering problem, to compare their performances. The algorithms are the Modified Great Deluge algorithm (MGD) (Abuhamdah, 2012) and hybridize Modified Great Deluge and Iterative Simulated Annealing (ISA-MGD) (Abuhamdah et al., 2012). In both algorithms, the initial solutions (or clusters) are generated by using Multi K-Means algorithm (Davidson and Satyanarayana, 2003) and iteratively improve the current solutions by using two neighborhood structures. Both algorithms measures the solution qualities by using two ways (i.e., between objects and between centers) of the cluster distance (or minimal distance) calculation over six medical benchmark datasets clustering problem (which are available in UCI Machine Learning Repository). However, the two ways are aims to minimize distances between the same clusters and maximize the distances between the set of clusters. Where, in the between object calculation is calculates the distances between the patterns in the same cluster and maximize the dissimilarity in the other clusters, while in the between centers calculation is calculates the distances between each pattern and its center in the same cluster to group the patterns around the center and achieve similar objects and maximize the distances between patterns.
Therefore, in this study, we present a third distances function calculation by using the combination of between centers and objects to produce better clustering that minimize the distances between the patterns with similar objects. Results demonstrate that, using the swap mechanism is able to produce better cluster quality than not using it, in addition that, using the third calculation way is also produce a good cluster with better similarity.
MATERIALS AND METHODS
Problem description: In this study, six well-known benchmark datasets are used as a test domain (which are summarize in Table 1 to test the performance of the propose swap mechanism. These datasets are available in UCI machine learning repository (http://archive.ics.uci.edu/ml/index.html). These datasets are varied in terms of the number of records and attributes to show a different complexity for the tested data. All of the information for these datasets are about the diseases that taken from a real infected patients and denoted for research purposes.
For example, Table 1 shows that Dataset 1 is Wisconsin Breast Cancer Database (B.C), Dataset 2 is Lung Cancer Database (L.C), Dataset 3 is BUPA Liver Disorders Database (B.L.D), Dataset 4 is Pima Indian Diabetes Database (P.I.D), Dataset 5 is Haberman’s Survival Database (H.S) and Dataset 6 is Thyroid gland data Disease Database (T.D).
In cluster analysis, it is very important issue to evaluate the clustering results quality that is produced by a certain measure. Those measures can be used to compare solutions obtained from different algorithms and also can be used to guide some optimization search processes to find the best partitioning procedure which fits the underlying dataset (Halkidi et al., 2001). In this work, three different ways (i.e., between objects, or centers, or their combinations) of the distance function (or the minimal distance) calculations are used to measure the clusters and their centers. These measurement on the cluster objects and/or changes on the cluster centers have the direct effect to the cluster quality. The three ways of the distance function calculations are portrayed as follow:
Between objects: This method depends on the calculation on the distance (cluster quality) between each data pattern.
Between centers: This method depends on calculating the distance (cluster quality) using the sum of distance between each data pattern and the cluster center that it belongs to.
| Table 1: | Six benchmark datasets |
 | |
Combination of “between Centers and between Objects”: This is a combination between the previous two above function. This will finally direct the cluster objects to be highly compressed on itself and at the same time it will be more distinct from the other clusters. It is the idea of running the algorithm with two objective functions rather that only one, where the first objective function is to minimize the distance between data patterns and clusters centers and the second objective function is to minimize the distances between the data patterns themselves in the same cluster.
SWAP MECHANISM
In this study, a propose swap mechanism motivated by the neighborhood selection and its effect on the solution quality (Hong, 2006; Halkidi et al., 2001). The main aim of proposing the swap mechanism (N3 neighborhood structure) is to improve the minimal distance quality for the clustering problem or a similar optimization problem, which can be applied to any algorithm. So the discussion below is for the swap mechanism idea and not for the algorithm process.
In clustering problems, we minimize or improve the minimal distance by explores the current solution neighbor solutions (other solution), looking for a better one by any algorithm (Hong, 2006). The neighbor solution is accomplished by restructure the current solution (or partition) using some neighborhood structures. However, the way of employing the neighborhoods structures will affects the solution quality (Hong, 2006). Therefore, in this work, a swap mechanism is propose as a neighborhood structure (i.e., N3) to increase the diversification and the neighbor solutions selection.
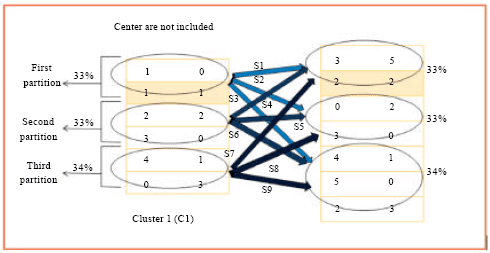
In the swap mechanism, we randomly select two different patterns and swap their data. Where, each cluster is divided into 3 partitions, i.e., the first 33% of the cluster patterns goes to the first partition, the second 33% of the cluster patterns goes to the second partition and the rest of the percentage goes the third partition (which is 34%). Whereas, some solution corresponding between these clusters.
The reason behind choosing that percentages is refer to the smallest medical dataset i.e., the Lung Cancer dataset out of the six test datasets. This dataset contains only 32 rows, with 56 columns of attributes, with donor recommendation to be distributed as follows; the first cluster contains 9 patterns, the second cluster contains 13 patterns and third cluster contains 10 patterns. Where 33% of the first cluster (i.e., 9 patterns) is 3 patterns. The idea of the swap mechanism is to check the solution in different level of the same cluster and try to diversify the search.
For example in Fig. 1, we have two clusters (i.e., cluster 1 and 2) and there are nine solutions obtained, as follow:
| • | Randomly select a pattern (R1) from the first partition (33%) in cluster 1, a pattern (R2) from the first partition (33%) in cluster 2 and then swap R1 data with R2 data, in which consider as solution-1 (S1). Repeat the same process between the first partition (33%) in cluster 1 and the second partition (33%) in cluster 2 to obtain solution-2 (S2). After that, repeat the same process between the first partition (33%) in cluster 1 and the third partition (34%) in cluster 2 to obtain solution-3 (S3) |
| • | Repeat as in (i) between the second partition (33%) in cluster 1 and the first, second and third partitions in cluster 2 to obtain S4, S5 and S6 |
| • | Repeat as in (i) between the third partition (34%) in cluster 1 and the first, second and third partitions in cluster 2 to obtain S7, S8 and S9 |
Then, the best solution between S1 to S9 will be selected as candidate solution (working solution). Meanwhile, the centers of the clusters are prevent to swap, so if the random number (when we select the pattern) hit the center pattern, then we ignore it and generate another random number.
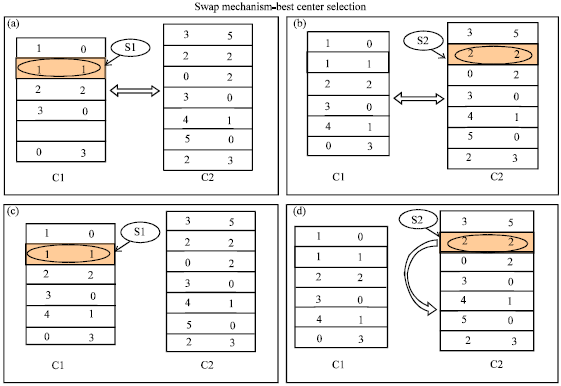
The explanation of the propose swap mechanism above prevents the swapping process that involves the center of the cluster, where the solution quality depends on the good center for each cluster. Meanwhile, we are dealing with different calculation (i.e., between object) that not take into consideration the cluster center and calculated based on distance between patterns. Therefore, a modification on the idea is done to handle the centers and object calculations by swapping the center of a cluster by any patterns of other cluster as in Fig. 2a,b. Figure 2a show that two clusters (i.e., C1 and C2) and their centers (i.e., S1 and S2) are chosen to swap their data with other patterns in the other cluster (i.e., S1 with any pattern in C2 and S2 with any pattern in C1) in case of an improvement is achieved (better minimal distance). However, after some preliminary experiments, we found out the swapping the center to other cluster sometimes is considered hard to obtain an improvement in terms of the quality of the solution. Therefore, we decided to alter the centers by internally swap the center within the cluster itself to achieve better improvement (or better minimal distance) as in Fig. 2c (i.e., S1 with any pattern in C1) and Fig. 2d (i.e., S2 with any pattern in C2), which we termed as swap mechanism (N3).
The idea of the swap mechanism is to check the solution in different level of the same cluster with different solutions level in other cluster, which may prevent repeating the swapping with the same solution and try to evaluate the solutions in other levels.
 | |
| Fig. 1: | N3 Swap mechanism, where the centers of the clusters are prevent to swap |
 | |
| Fig. 2(a-d): | Handling the centers in N3 swap mechanism, (a) Swap C1 center with any pattern in C2, (b) Swap C2 center with any pattern in C1, (c) Swap C1 center with any pattern within C1 and (d) Swap C2 center with any pattern within C2 |
However, we can decrease the percentage of the division if we are dealing with a bigger number of rows of the smallest cluster.
In order to evaluate the performance of the proposed swap mechanism (N3), then we need to compare the results obtained by any algorithm to the results of the same algorithm using N3. Therefore, in this work to test the propose N3, two algorithms are used; the Modified Great Deluge Algorithm (MGD) (Abuhamdah, 2012) (as in Fig. 1) and the hybridize Modified Great Deluge and Iterative Simulated Annealing (ISA-MGD) (Abuhamdah et al., 2012) (Fig. 2), where both of them are tested over the six datasets discussed above. MGD (Abuhamdah, 2012) and ISA-MGD (Abuhamdah et al., 2012) algorithms use two (i.e., N1 and N2) neighborhood structures for medical clustering problems as follows:
| • | N1: Randomly selects one pattern from each cluster to swap their data as in Wang (2006) |
| • | N2: Randomly select two different patterns from the same cluster and swap their data as in Wang (2006) |
 | |
| Fig. 3: | Pseudo code for modified great deluge algorithm for medical data clustering problems (Abuhamdah, 2012) |
Both MGD and ISA-MGD starts with a given Multi K-Means partitions (Davidson and Satyanarayana, 2003) i.e., the initial solution (Sinitial) is generated by K-Means algorithm (constructive method) and then iteratively improve the constructed solution by generating a neighbor solution (candidate solution) by using neighborhood structure(s). In addition, both of them are employ N1 and N2 neighborhood structure. Again, we our discussion in this study is to apply N3 over any algorithm and not discuss the algorithm process. For any further information about MGD or ISA-MGD algorithms, the please see their implementations (i.e., MGD in (Abuhamdah, 2012) and ISA-MGD in Abuhamdah et al. (2012).
Figure 3 shows MGD pseudo code, the algorithm starts by initializing the required parameters as in Step-1 by setting the stopping condition (N.iters), estimated quality of the final solution (est.q), the initial water level (level), decreasing rate (β), maximum number of not improving solutions (not_improving_length_GD).
 | |
| Fig. 4: | Pseudo code for hybridize modified great deluge algorithm with iterative simulated annealing for medical data clustering problems (Abuhamdah et al., 2012) |
Again, note that the initial solution is generated using K-Means (So). In the improvement phase (i.e., Step-2), N1and N2 neighborhood structures are applied to generate candidate solutions (i.e., 5 candidate solutions) and the best candidate is selected as the candidate solution (Sworking) as shown in Step-2.1. There are two cases to accept the solution, the first case (i.e., Case 1), If f (Sworking) is better than the best solution found f (SArrange), then Sworking is accepted as a current solution (Ssource←Sworking) and the best solution is updated (SArrange←Sworking) as shown in Step-2.2. Then the level will be updated by the decreasing value β (i.e., level = level-β). While in case 2 (i.e., Case 2), If f (Sworking) is less than f (SArrange), then the quality of Sworking is compared against the level. If it is less than or equal to the level, then Sworking is accepted and the current solution is updated (SsourceβSworking). Otherwise, Sworking will be rejected. The level will be updated by the decreasing value β (i.e., level = level-β). The counter for the non-improving solution is increased by 1. If this counter is equal non_improving_length_GD, then the process terminates. Otherwise, the process continues the stopping condition is met (i.e., Iterations>N.iters) and return the best solution found SArrange. (Step-2).
From Fig. 4 show ISA-MGD pseudo code, the algorithm starts by initializing the required parameters as in Step-1 by setting the stopping condition (N.iters), the temperature (Temp) is equal to the initial temperature (To), initialize the decreasing temperature rate (α), initialize the estimated quality of the final solution (est.q), the initial water level (level), decreasing rate (β), maximum number of not improving solutions (not_improving_length_GD) and a list of LL size to store the value of the level. Again, note that, the initial solution is generated using K-Means (So). In the improvement phase (Step-2), basically the initial solution is iteratively improved by employing the hybridization method (ISA-MGD) until the stopping condition is met. In Step-2.1, the neighborhood structures N1 and N2 are applied similar to MGD. There are two cases to be taken into account similar to MGD except that in the first case LL is updates (FIFO) by level (LL←level). The Temp will be decreased by the value α (i.e., Temp = Temp-Temp*α) and the level will be updated by the value β (i.e., level = level-β). In the other case, if Sworking accepted, then the difference between the quality of Sworking and Ssource is calculated. A random number [0, 1], RN, is generated. If the probability (i.e., e-δ/Temp, where δ = f (Sworking)-f(Ssource)) is less than or equal to RN) then Sworking is accepted. Otherwise, the quality of Sworking is compared against the level same as MGD. Otherwise, Sworking will be rejected. The level will be updated similar to MGD and thecounter for not improving solution is increased by 1. If this counter is equal non_improving_length_GD, then we reinitialize the temperature (Temp) equal to the initial temperature (To) and the level is updated by a new level that is randomly selected from the list (where the size of the list is set to 10 based on preliminary experiments). Otherwise, the process continues until the stopping conditions are met (i.e., Iterations>N.iters && Temp <Tf ) and return the best solution found SArrange (Step-2). Note that in this work the est.q is set to 0 and non_improving_length_GD is set to 10 (after some preliminary experiments).
The process will continue until the termination conditions are met (Iterations>N.iters && Temp <Tf) and return the best solution found so far SArrange (Step-3).
RESULTS AND DISCUSSION
In this study, we ran the algorithms 20 times across 6 datasets as in MGD (Abuhamdah, 2012) and ISA-MGD (Abuhamdah et al., 2012) with the same parameters setting. Also, the algorithms were programmed using Java language and were tested on a PC with a CPU of Intel dual core 1800 MHz and 2 GB RAM. In the analysis part, the terms were used as follows:
| • | N-NI: Number of not improved iterations |
| • | N-I: Number of improved iterations |
| • | Std: Standard deviation |
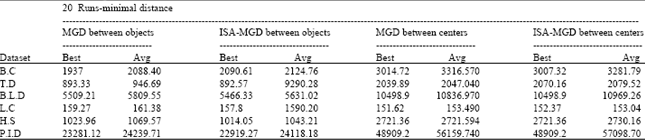
Table 2 shows the results obtained based on the minimal distance calculation (i.e., between objects and between centers) for Modified Great Deluge algorithm (MGD) (Abuhamdah, 2012) and hybridize Modified Great Deluge and Iterative Simulated Annealing (ISA-MGD) (Abuhamdah et al., 2012) by using N1 and N2. The “Avg” represents the average results out of 20 runs. The best results “Best” are presented in bold.
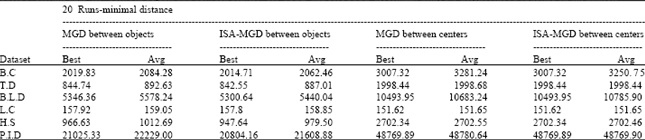
Table 3 shows MGD and ISA-MGD algorithms using N3 (swap mechanism) neighborhood structure based on the minimal distance calculation (i.e., between objects and between centers). Again, the best results are presented in bold.
| Table 2: | Results “between objects and between centers” obtained from MGD (Abuhamdah, 2012) and ISA-MGD (Abuhamdah et al., 2012) algorithms using N1 and N2 neighborhood structures on six datasets |
 | |
| Table 3: | Results analysis “between objects and between centers” for MGD and ISA-MGD algorithms using N3 neighborhood structure on six datasets |
 | |
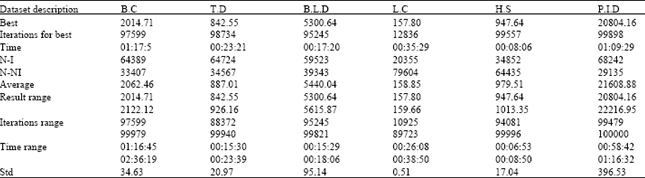
| Table 4: | Results analysis “between objects” for ISA-MGD algorithm using N3 neighborhood structure on six datasets |
 | |
| Table 5: | Results analysis combination of “between centers and between objects” for MGD and ISA-MGD algorithms using N3 neighborhood structure on six datasets |
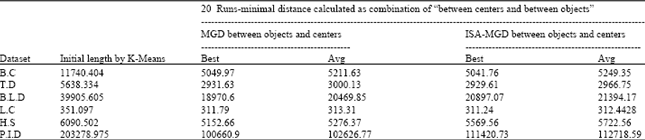 | |
Table 3 with referring to Table 2 shows that, the best results and average score using N3 neighborhood structure obtained indicate that, if MGD or ISA-MGD algorithm is using N3 neighborhood structure, then it will outperformed the same algorithm using N1 and N2 neighborhood structures in all or some datasets in both calculation way, which indicate that using N3 is better in exploring the search space than using N1 and N2, except in one dataset (i.e., B.C) GD were better in the calculation between objects. Table 3 also shows that ISA-MGD outperformed MGD between objects using N3 in all datasets, where in between centers they obtain equal results. Table 4 shows a further analysis on ISA-MGD using N3 neighborhood structure between Objects over all tested datasets. For example, the best results for H.S dataset is 947.64 that is obtained within 8 minutes 6 seconds under 99557 iterations. Meanwhile, the range for minimum and maximum iterations is in between 94081 and 99996. In most of the cases, the results are obtained between 6 min 53 sec to 8 min 50 sec that are considered acceptable. Figure 5 shows a 3D scatter graph for K-Means, MGD algorithms using N3 neighborhood structure over H.S dataset. Two clusters are represented by two colors. Figure 5a shows that, the two clusters (colors) are mixed with initial minimal distance “between centers” obtained by K-Means is 3626.530 as shown in Fig. 5a-c shows that, the initial minimal distance “between objects” obtained by K-Means is 2463.972. Whereas, Fig. 5b shows that, there is an improvement in terms of the minimal distance of between objects which is equal to 966.63 and between centers 2702.34 in Fig. 5d after employing the MGD algorithm. Meanwhile, MGD results obtain by referring to Fig. 5, we can see that the dispersion of the colors in MGD is less (more concentrated) shows it is better clustered than MGD in Abuhamdah (2012) (which is more scattered).
Since, ISA-MGD and MGD algorithm using N3 outperformed ISA-MGD and MGD using N1 and N2 neighborhood structures in both calculation (i.e., between objects and between centers) as shown in Table 2 and 3, then Table 5 shows MGD and ISA-MGD algorithms using N3 neighborhood structures based on the minimal distance calculation (i.e., Combination of “between Centers and between Objects”). Again, the best results are presented in bold.
Table 5 shows, the best results and average score using N3 neighborhood structure for MGD and ISA-MGD algorithms in all datasets for the combination of “between Centers and between Objects” calculation way. The best minimal distance obtained in Table 5 shows that the results obtained by MGD algorithm has outperformed ISA-MGD algorithm in three datasets (i.e., BL.D, H.S and P.I.D datasets), whereas, ISA-MGD algorithm has outperformed MGD algorithm in the other three datasets (i.e., B.C, T.D and L.C datasets).
Table 6 shows a further analysis on ISA-MGD using N3 neighborhood structure for the combination of “between Centers and between Objects” over all tested datasets.
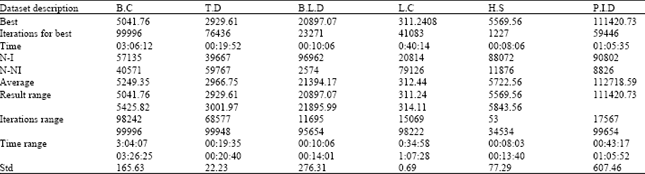
| Table 6: | Results analysis for the combination of “between centers and between objects” for ISA-MGD algorithm using N3 neighborhood structure on six datasets |
 | |
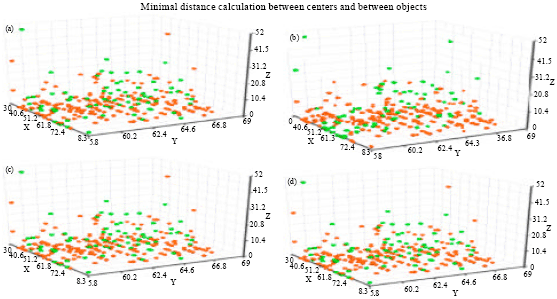 | |
| Fig. 5(a-d): | Scatter graph for K-Means, MGD algorithm over H.S dataset for minimal distance calculation between centers and between objects using N3 neighborhood structure, (a) Initial length by K-Means = 2463.972, (b) Best length found between objects by MGD = 966.63, (c) Initial length by K-Means = 3626.530, (d) Best length found between centers by MGD = 2702.34 |
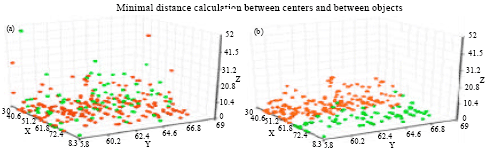 | |
| Fig. 6(a-b): | Scatter graph for K-Means, MGD algorithm over H.S dataset for minimal distance calculation of the combination of between centers and between objects using N3 neighborhood structure, (a) Initial length by K-Mean = 6090.502 and (b) Best length found by MGD = 5152.66 |
For example, the best results for T.D dataset is 2929.61 that is obtained within 19 min 52 sec under 76436 iterations. Meanwhile, the range for minimum and maximum results is in between 2929.61 and 3001.97. In most of the cases, the results are obtained between 19 min 35 sec to 20 min 40 sec that are considered acceptable. Figure 6 shows a 3D scatter graph for K-Means, MGD algorithms using N3 neighborhood structure of the calculation between centers and between objects over H.S dataset.
CONCLUSION
This study proposed swap mechanism (N3) to increase the search diversification and improve the minimal distances quality. Two algorithms previously proposed were utilized for medical clustering problem for a comparison need, the Modified the Great Deluge algorithm (MGD) and hybridize Modified Great Deluge and Iterative Simulated Annealing (ISA-MGD). The comparison made between those algorithms employing N1 and N2 neighborhood structures to those algorithms employing N3 neighborhood structure based on the minimal distance that is calculated based on (i) Between objects and (ii) Between centers. Then, present a different minimal distance calculation using the combination of the between centers and objects to produce better clustering quality. The algorithms have been tested over six well known real medical clustering datasets.
Experimental results show that, when we use N3 in MGD or ISA-MGD algorithms will performs better than using N1 and N2 neighborhood structures in both minima distance calculations (i.e., i and ii), which indicates that using the swap mechanism (N3) is better in exploring the search space than using N1 and N2. Meanwhile, ISA-MGD algorithm has outperformed MGD algorithm using N3 in all datasets using between objects calculation, where they obtain same results in between centers calculation. This motivates to extend the test to use the third calculation (i.e., iii) using N3. The experimental results using iii calculation show that, MGD and ISA-MGD algorithms can produce cluster with more concentrated than using other calculations. Meanwhile, both MGD and ISA-MGD algorithms has outperformed each other in some datasets. Generally, it can be concluded that, the algorithms behave differently due to the different measurements imposed during the search process.
REFERENCES
- Abuhamdah, A., B.M. El-Zaghmouri, A. Quteishat and R. Kittaneh, 2012. Hybridization between iterative simulated annealing and modified great deluge for medical clustering problems. World Comput. Sci. Inform. Technol. J., 2: 131-136.
Direct Link - Dasgupta, S. and Y. Freund, 2009. Random projection trees for vector quantization. IEEE Trans. Inform. Theory, 55: 3229-3242.
CrossRefDirect Link - Halkidi, M., Y. Batistakis and M. Vazirgiannis, 2001. On clustering validation techniques. J. Intell. Inform. Syst., 17: 107-145.
Direct Link - Jain, A.K., M.N. Murty and P.J. Flynn, 1999. Data clustering: A review. ACM Comput. Surv., 31: 264-323.
CrossRefDirect Link - Saha, I., D. Pewczynski, U. Maulik and S. Bandyopadhyay, 2010. Consensus Multiobjective Differential Crisp Clustering for Categorical Data Analysis. In: Rough Sets and Current Trends in Computing, Szczuka, M., M. Kryszkiewicz, S. Ramanna, R. Jensen and Q. Hu (Eds.). Springer, USA., ISBN: 978-3-642-13528-6, pp: 30-39.
- Liu, Y., Z. Yi, H. Wu, M. Ye and K. Chen, 2008. A tabu search approach for the minimum sum-of-squares clustering problem. Inform. Sci., 178: 2680-2704.
CrossRef - Zhang, C., D. Ouyang and J. Ning, 2010. An artificial bee colony approach for clustering. Exp. Syst. Appl., 37: 4761-4767.
CrossRef