
M. A. Ayoub
Department of Petroleum Engineering, Faculty of Geosciences and Petroleum Engineering, Universiti Teknologi Petronas, Tronoh, Malaysia
K. A. Elraies
Department of Petroleum Engineering, Faculty of Geosciences and Petroleum Engineering, Universiti Teknologi Petronas, Tronoh, Malaysia
Journal of Applied Sciences
Year: 2014 | Volume: 14 | Issue: 23 | Page No.: 3220-3227







ABSTRACT
This study presents a universal pressure drop model in pipelines using the Group Method of Data Handling (GMDH)-type neural networks technique. The model has been generated and validated under three phase flow conditions. As it is quite known in production engineering that estimating pressure drop under different angles of inclination is of a massive value for design purposes. The new correlation was made simple for the purpose of eliminating the tedious and yet the inaccurate and cumbersome conventional methods such as empirical correlations and mechanistic methods. In this study, GMDH-type neural networks technique has been utilized as a powerful modeling tool to establish the complex relationship between the most relevant input parameters and the pressure drop in pipeline systems under wide range of angles of inclination. The performance of the model has been evaluated against the best commonly available empirical correlations and mechanistic models in the literature. Statistical and graphical tools were also utilized to show the significance of the generated model. The new developed model reduced the curse of dimensionality in terms of the low number of input parameters that have been utilized as compared to the existing models.
PDF Abstract XML References Citation
Received: April 25, 2014;
Accepted: July 25, 2014;
Published: September 13, 2014
How to cite this article
M. A. Ayoub and K. A. Elraies, 2014. Development of a Universal Pressure Drop Model in Pipelines Using Group Method of Data Handling-Type Neural Networks Model. Journal of Applied Sciences, 14: 3220-3227.
DOI: 10.3923/jas.2014.3220.3227
URL: https://scialert.net/abstract/?doi=jas.2014.3220.3227
DOI: 10.3923/jas.2014.3220.3227
URL: https://scialert.net/abstract/?doi=jas.2014.3220.3227
INTRODUCTION
Two phase flow phenomenon; namely liquid and gas or what is synonymously called multiphase flow (MPF), occurs in almost all upstream oil production, as well as in many surface downstream facilities. It can be defined as a concurrent flow of a stream containing a liquid hydrocarbon phase, a gaseous phase, a produced water phase and solids phase. The phenomenon is governed mainly by bubble point pressure, whenever the pressure drops below bubble point in any point, gas will evolve from liquid resulting in a multiphase gas-liquid flow. Additional governing factor is the gas-liquid components and their changing physical characteristics along the pipe length and configuration with the change of temperature. Furthermore, certain flow patterns will develop while, the pressure decreases gradually below the bubble point. The flow patterns depend mainly on the relative velocities of gas and liquid and gas/liquid ratio. Needless to mention that sharp distinction between these regimes is quite intricate (Ayoub, 2004).
The pressure drop (DP) mainly occurs between wellhead and separator facility. It needs to be estimated with a high degree of precision in order to execute certain design considerations. Such considerations include pipe sizing and operating wellhead pressure in a flowing well; direct input for surface flow line and equipment design calculations (Ayoub, 2004). Determination of pressure drop is very important because it provides the designer with the suitable and applicable pump type for a given set of operational parameters. Generally, the proper estimation of pressure drop in pipeline can help in design of gas-liquid transportation systems.
In this study, a Group Method of Data Handling (GMDH) or Abductory Induction Mechanism (AIM) approach has been utilized. The approach has been developed by a Ukraine scientist named Alexy G. Ivakhnenko which has gained wide acceptance in the past few years (Abdel-Aal, 2002).
The overall objective of this study is to minimize the uncertainty in the multi-phase pipeline design by developing representative models for pressure drop determination in downstream facilities (gathering lines) with the use of the most relevant input variables and with a wide range of angles of inclination. The proposed GMDH model’s performance will be thoroughly analyzed and compared against the one for Beggs and Brill (1973) model, Gomez et al. (1999) model and Xiao et al. (1990) model.
MATERIALS AND METHODS
GMDH approach is a formalized paradigm for iterated (multi-phase) polynomial regression capable of producing a high-degree polynomial model in effective predictors. The process is evolutionary, in nature, using initially simple regression relationships to derive more accurate representations in the next iteration. To prevent exponential growth and limit model complexity, the algorithm only selects relationships having good predicting powers within each phase. Iterations will stop when the new generation regression equations start to have poor prediction performance than those of previous generation. The algorithm has three main elements; representation, selection and stopping. It applies abduction heuristics for making decisions concerning some or all of these three steps (Abdel-Aal, 2002).
The proposed algorithm shown by Eq. 1 is based on a multilayer structure using the general form which is referred to as the Kolmogorov-Gabor polynomial (Volterra functional series):
| (1) |
where, the external input vector is represented by X = (x1, x2 …), y is the corresponding output value and a is the vector of weights and coefficients. The polynomial equation represents a full mathematical description. The whole system of equations can be represented using a matrix form as shown in Eq. 2:
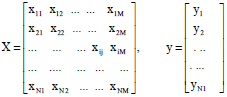 | (2) |
Equation 1 can be replaced by a system of partial polynomial for the sake of simplicity as shown in Eq. 3:
| (3) |
where, i, j = 1, 2, …, M; i ≠ j.
The inductive algorithm follows several systematic steps to finally model the inherent relationship between input parameters and output target (Madala and Ivakhnenko, 1994). Data sample of N observations and M independent variables (Eq. 2) corresponding to the system under study is required; the data will be split into training set A and checking set B(N = NA+NB).
Firstly, all the independent variables (matrix of X represented by Eq. 2) are taken as pair of two at a time for possible combinations to generate a new regression polynomial similar to the one presented by Eq. 3 where p and q are the columns of the X matrix.
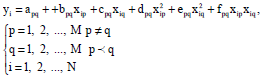 | (4) |
A set of coefficients of the regression will be computed for all partial functions by a parameter estimation technique using the training data set A and Eq. 4.
The new regression coefficients will be stored into a new matrix CAS shown in Eq. 5:
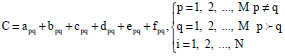 | (5) |
According to the mathematical law, the number of combinations of input pairs is determined by:
| (6) |
The polynomial at every N data points will be evaluated to calculate a new estimate called zpq as:
| (7) |
The process will be repeated in an iterative manner until all pairs are evaluated to generate a new regression pairs that will be stored in a new matrix called Z matrix. This new generation of regression pairs can be interpreted as new improved variables that have a better predictability than the original set of data X (Eq. 9).
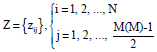 | (8) |
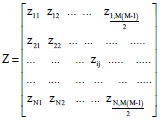 | (9) |
Quality measures of these functions will be computed according to the objective rule chosen using the testing data set B. This can be done through comparing each column of the new generated matrix Z with the dependent variable y. The external criterion may somewhere be called regularity criterion (root mean squared values) and defined as following Eq. 10:
| (10) |
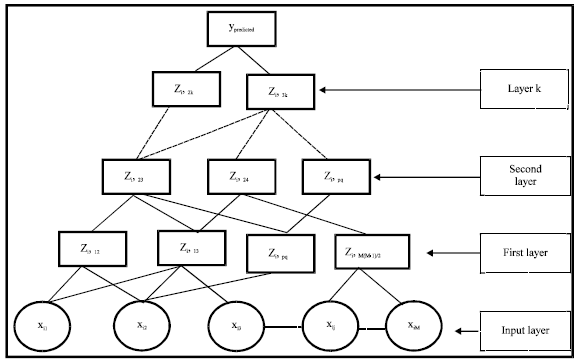 | |
| Fig. 1: | Schematic diagram of Self-Organizing Algorithm with M inputs and K layers (Madala and Ivakhnenko, 1994) |
The whole procedure is repeated until the regularity criterion is no longer smaller than that of the previous layer. The model of the data can be computed by tracing back the path of the polynomials that corresponds to the lowest mean squared error in each layer.
The best measured function will be chosen as an optimal model. If the final result is not satisfied, F number of partial functions will be chosen which are better than all (this is called “freedom-of-choice”) and do further analysis. Schematic diagram of self-organizing GMDH algorithm is depicted in Fig. 1.
The research methodology involves filling the gap exists in the literature by assessing and evaluating the best multiphase flow empirical correlations and mechanistic models. The assessment will be dealing with their performance in estimating pressure drop whilst using available statistical and graphical techniques. The performance of the developed models will be compared against the best available correlations used by the industry (Madala and Ivakhnenko, 1994).
Network performance comparison: Pressure drop calculation for Beggs and Brill (1973) correlation, Gomez et al. (1999) model and Xiao et al. (1990) model had been conducted using the freeware DPDLSystem. The software allows great flexibility in selecting PVT methods, type of pressure drop correlation (vertical, inclined and horizontal), operating conditions and flow-rate type data. Only test data had been chosen for comparison for each selected model against the proposed GMDH model. The network performance comparison had been conducted using the most critical statistical and analytical techniques. Trend analysis, group error analysis and graphical and statistical analysis are among these techniques.
Trend analysis: A trend analysis was performed for each generated model to check whether it was physically correct or not. Interchangeably, this analysis is the synonyms of sensitivity analysis. This analysis aids in fully understanding the relationship between input variables and output and increases the robustness of the generated model. For this purpose, synthetic sets were prepared where in each set only one input parameter was varied between the minimum and maximum values while other parameters were kept constant at their mean (base) values.
Group error analysis: To demonstrate the robustness of the developed model, another statistical analysis was conducted which was group error analysis. The purpose of this analysis was to quantify the error produced by each input when grouped to a number of classes based on the average absolute relative error as an indicator. The reason for selecting average absolute relative error is that it is a good indicator of the accuracy of all empirical correlations, mechanistic model as well as for the new developed models.
Statistical error analysis: This error analysis had been utilized to check the accuracy of the models. The statistical parameters used in the present study were, average percent relative error, average absolute percent relative error, minimum and maximum absolute percent error, root mean square error, standard deviation of error and the correlation coefficient. Those statistical parameters are well known for their capabilities to analyze models’ performances and have been utilized by several authors (Ayoub, 2004; Osman, 2001; El-Sebakhy et al., 2007). This will be considered as the main criterion in statistical error analysis throughout this study. AAPE or MAPE (mean absolute error) has invaluable statistical properties in that it makes use of all observations and has the smallest variability from sample to sample (Levy and Lemeshow, 1991).
Graphical error analysis: Graphical tools aid in visualizing the performance and accuracy of a correlation or a model. Only one graphical analysis techniques was employed which is cross-plot.
Cross-plots: In this graphical based technique, all estimated values had been plotted against the measured values and thus a cross-plot was formed. A 45° straight line between the estimated versus actual data points was drawn on the cross-plot which denoted a perfect correlation line. The tighter the cluster about the unity slope line, the better the agreement between the actual and the predicted values. This may give a good sign of model coherence.
Building GMDH model and limitations: The process of generating the GMDH Model had started by selecting the relevant input parameters. Free software was used for this purpose (Jekabsons, 2010). This source code was tested with MATLAB version 7.1 (R14SP3). Despite the software allows great flexibility in selecting the model parameters, it also provides ample interference. The results of the generated model may be limited in their nature due to data attributes range. The assigned results may suffer degradation due to type of data used in generating GMDH model. However, the accuracy obtained by GMDH model depends on the range of each input variable and the availability of that input parameter (parameters). Although, the main purpose was to explore the potential of using GMDH technique, optimum performance can be obtained using this limited data range in attributes and variables. Care must be taken if obtained results applied for data type and range beyond that used in generating GMDH model.
RESULTS
As described initially, a code was utilized for building the final GMDH model. The constructed model consists of two layers. Twenty eight neurons were tried in the first layer, while only two neurons were included at the end of the trial. Only one neuron had been included for the second layer which was the pressure drop target. However, three input parameters had shown pronounced effect on the final pressure drop estimate which were; wellhead pressure, length of the pipe and angle of inclination. The selection of these three inputs had been conducted automatically without any from the user’s intervention. They were selected based on their mapping influence inside the data set on the pressure drop values.
This topology was achieved after a series of optimization processes by monitoring the performance of the network until the best network structure was accomplished. Figure 2 shows the schematic diagram of the proposed GMDH topology.
Summary of model’s equation: It is described that the model consists of two layers as follows:
Total No. of layers is 2 which is described as:
Layer No. 1: No. of neurons: 2 (neurons x9 and x10)
x9 = -428.130594 84218+3.32804279 841806 x (x8)-
0.39589437 5895042x(x7)+ 0.00219488
561608562x(x7)x(x8)-0.00470613 525745107x(x8)x(x8)-
0.00081380 1551583036
x10 = -404.104040 068822+3.28280927 457335x(x8)-
0.00560599 702533417 x (x5) +1.73958945 39217e-
0.005x(x5)x(x8) -0.00474009 259349089x(x8)x(x8)
+3.53811231 021166e -008x(x5)x(x5)
Layer No. 2: Number of neurons: 1
y = 38.6163548 411764 -0.35723855 0745703x(x10)
+0.34927960 7055502x(x9)+0.04773877 21448686x(x9)x(x9)
Where:
| x5 | = | Length of the pipe (ft) |
| x7 | = | Angle of inclination (degrees) |
| x8 | = | Wellhead pressure (psia) |
| y | = | Simulated pressure drop by GMDH Model |
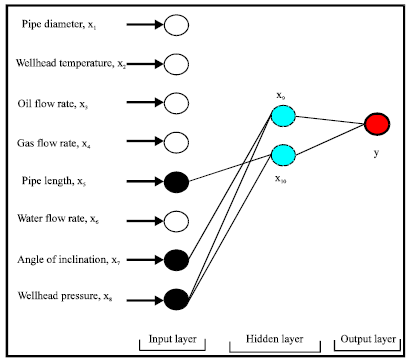 | |
| Fig. 2: | Schematic diagram of the proposed GMDH topology |
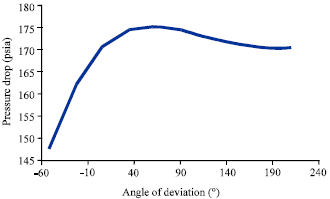 | |
| Fig. 3: | Effect of angle of inclination on pressure drop |
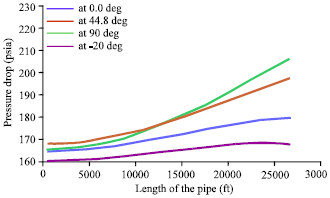 | |
| Fig. 4: | Effect of Pipe Length on Pressure Drop at four Different Angles of Inclination |
Trend analysis for the GMDH model: A trend analysis was conducted for every model’s run to check the physical accuracy of the developed model.
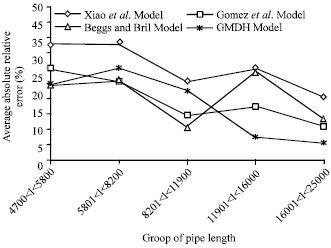 | |
| Fig. 5: | Statistical accuracy of pressure drop for the polynomial GMDH model and other investigated models grouped by pipe length (with corresponding data points) |
Figure 3 shows the effect of angle of inclination on the pressure drop. The effect of angle of inclination was investigated where all range of angles of inclination was plotted against pressure drop. Figure 4 shows the relationship between the pressure drop and length of the pipe.
Group error analysis for the gmdh model against other investigated models: To demonstrate the robustness of the developed model, group error analysis was performed. Average absolute relative error is utilized as a powerful tool for evaluating the accuracy of all models.
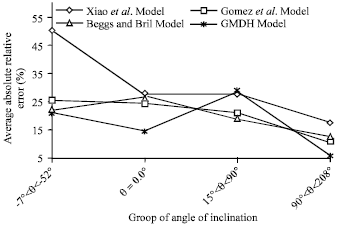 | |
| Fig. 6: | Statistical Accuracy of Pressure Drop for the Polynomial GMDH Model and other Investigated Models Grouped by Angle of Inclination (With Corresponding Data Points) |
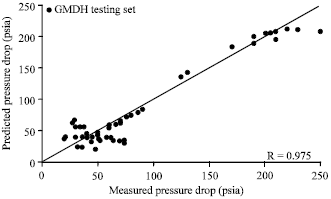 | |
| Fig. 7: | Cross-plot of predicted vs. Measured pressure drop for testing set (polynomial gmdh model) |
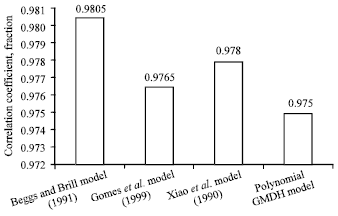 | |
| Fig. 8: | Comparison of Correlation Coefficients for the Polynomial GMDH Model against All Investigated Models |
Figure 5 and 6 present the statistical accuracy of pressure drop correlations and models under different groups. Figure 5 shows the statistical accuracy of pressure drop grouped by length of the pipe.
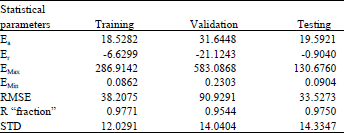
| Table 1: | Statistical analysis results of the polynomial GMDH model |
 | |
Length of the pipe had been partitioned into five groups and plotted against the respective average absolute percent relative error for each group.
Furthermore, the statistical accuracy of pressure drop estimation for the polynomial GMDH model against other investigated models grouped by the angle of inclination is plotted in Fig. 6. Data was partitioned into four categories to include all possible inclination (downhill, horizontal, uphill and vertical).
Statistical and graphical comparisons of the polynomial GMDH model
Statistical error analysis: The same statistical parameters were adopted for comparison for all types of models. Summary of statistical comparisons between all sets (training, validation and testing) of the polynomial GMDH model is presented in Table 1.
Graphical error analysis of the polynomial GMDH model: The graphical analysis techniques (cross-plots) was employed to visualize the performance of the Polynomial GMDH Model and other investigated models.
Cross-plots of the polynomial GMDH model: Figure 7 presents cross-plots of predicted pressure drop versus the actual one for polynomial GMDH Model (testing sets only). As shown by the respective graph, a correlation coefficient of 0.975 was obtained by the GMDH model. Figure 8 shows a comparison of correlation coefficients for GMDH model against all investigated models. Comparison between the performance of all investigated models plus the polynomial GMDH model is provided in Table 2. Other additional criteria for evaluating model’s performance are Standard Deviation, Root Mean Square Error (RMSE), Minimum Absolute Percent Relative Error and Maximum Absolute Percent Relative Error. Figure 8 shows a comparison of correlation coefficient for the polynomial GMDH model against all investigated models. Also, Fig. 9 shows a comparison of Average Absolute Percent Relative Error (AAPE) for the polynomial GMDH model and other models.
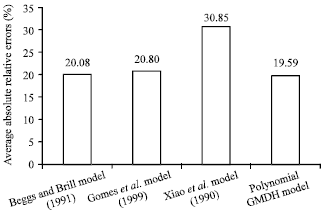 | |
| Fig. 9: | Comparison of Average Absolute Percent Relative Errors for the Polynomial GMDH Model against All Investigated Models |
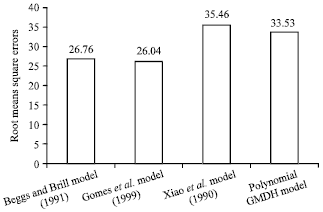 | |
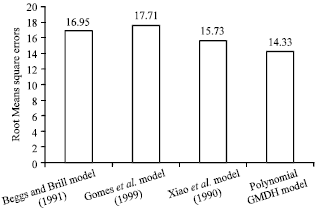
| Fig. 10: | Comparison of root mean square errors for the polynomial GMDH model against all investigated models |
 | |
| Fig. 11: | Comparison of standard deviation for the polynomial GMDH model against all investigated models |
Root Mean Square Error (RMSE) is used to measure the data dispersion around zero deviation. Figure 10 shows a comparison of root mean square errors for the polynomial GMDH model against all investigated models.
Figure 11 shows a comparison of standard deviation for the polynomial GMDH model against the rest of the models. Comparison between the performance of all investigated models as well as GMDH model is provided in Table 2.
DISCUSSION
The main purpose of utilizing this technique is to explore the potential of using GMDH as a tool, for the first time, to predict the pressure drop under wide range of angles of inclination. The exploration includes finding the most influential input parameters in estimating the pressure drop under wide range of angles of inclination. For this reason, statistical and graphical analyses were conducted extensively to show the cons and pros of the generated model against the investigated models. From Fig. 3, it is clear that the model was able to generate the sound track since the pressure drop is known to be an increasing function up to 90° and beyond that angle it’s a decreasing function. Additionally and as shown in Fig. 4, the model produced an expected behavior where the length of the pipe was plotted against the simulated pressure drop at four different angles of inclination. The GMDH Model was able to predict the correct phenomenon where the pressure drop is known to be an increasing function with respect to pipe length. Also it is clear that with increasing angle of inclination from downhill to uphill the pressure drop is an increasing function.
For group error analysis, Polynomial GMDH model was found superior in obtaining the lowest average absolute percent relative error for range of one pipe length groups (11901<L<16000), as shown in Fig. 5. However, Figure 6 shows the group error analysis for the pressure drop against different angles of inclination. The GMDH model’s performance was superior especially for horizontal pipes (0°) and achieved the lowest average absolute percent relative error for the range of angle of inclination between 90 and 208 (uphill angles only).
The model achieved reasonable correlation coefficient between estimated and actual values where a value of 0.975 was obtained. Bear in mind that the obtained correlation coefficient was achieved with only three input parameters which are angle of inclination, wellhead pressure and length of the pipe. In addition, the performance of the GMDH may be improved further if more data sets have been introduced with a wide range of tested variables. This may give an indication that most of the input variables used for other investigated model may serve as noise data.
| Table 2: | Statistical analysis results of empirical correlations, mechanistic models, against the developed GMDH model |
 | |
The GMDH model showed good agreement between actual and estimated values especially at the middle range (from 70-150 psia). However, this measure (correlation coefficient) was not taken as a main criterion for evaluating models performance since it will not give clear insight into the actual error trend while points under the 450 may be recovered by others under the same line. Beggs and Brill (1973) model achieved the highest correlation coefficient as shown by Fig. 8. However, the main criterion for evaluating model’s performance which is the Average Absolute Percent Relative Error, revealed that the GMDH test set outperformed all investigated models in AAPE with a value of approximately 19.6%, followed by Beggs and Brill (1973) model as shown in Fig. 9. The comparison of root mean square errors for the polynomial GMDH model against all investigated models was shown in Fig. 10. This time, the lowest RMSE is achieved by Gomez et al. (1999) model (26.04%) while the GMDH model ranked third before the worse model (Xiao et al., 1990) model with a value of 33.53%.
Standard Deviation (STD) was used to measure model advantage. This statistical feature is utilized to measure the data dispersion. A lower value of standard deviation indicates a smaller degree of scatter. As shown in Fig. 11, GMDH model achieves the lowest STD with a value of 14.33%, followed by Xiao et al. (1990) Model (15.73%).
As seen from Table 2, the GMDH model failed to provide low maximum absolute percent relative error where a value of 130.6% is obtained. On the other hand, Xiao et al. (1990) model achieved the lowest maximum absolute percent relative error that reaches (71.4%).
If this criterion was selected to evaluate models performance, the GMDH model will be considered as the worst among the rest of investigated models. On contrary, if the minimum absolute percent relative error is considered as the only parameter for evaluating models performance, the GMDH will be ranked second after the Xiao et al. (1990) model with a value of 0.0904.
ACKNOWLEDGMENTS
The authors would like to express their deepest gratitude to Universiti Teknologi Petronas for providing all necessary help to accomplish this study. Special thanks go to Mr. Gints Jekabsons for his invaluable support during the early stages of model generation.
REFERENCES
- Beggs, D.H. and J.P. Brill, 1973. A study of two-phase flow in inclined pipes. J. Pet. Technol., 25: 607-617.
CrossRef