
Mena Patummasut
Department of Statistics, Faculty of Science,Kasetsart University, Lat Yao, Chatuchak, Bangkok, 10900, Thailand
John J. Borkowski
Department of Mathematical Sciences, Montana State University,Bozeman, Montana, 59717, United States of America
Journal of Applied Sciences
Year: 2014 | Volume: 14 | Issue: 20 | Page No.: 2516-2522







ABSTRACT
This study proposed the use of adaptively adding secondary units in adaptive cluster sampling when the primary units are formed by a spatial cluster of secondary units. Adaptive cluster sampling with this recommended approach of adaptively adding units is called adaptive cluster sampling with spatially clustered secondary units. The purpose of adaptive cluster sampling with spatially clustered secondary units is to provide efficient estimators and to save time and cost of travelling and observing units in the sample. For this sampling design, each primary unit is divided into four secondary units. An initial sample of primary units is selected and then secondary units are adaptively added to the sample instead of neighboring primary units. This study offers an unbiased estimator of the mean and its variance and shows the advantages and disadvantages of adaptive cluster sampling with spatially clustered secondary units in comparison to the ordinary adaptive cluster sampling based on a simple random sample.
PDF Abstract XML References Citation
Received: February 01, 2014;
Accepted: April 09, 2014;
Published: June 28, 2014
How to cite this article
Mena Patummasut and John J. Borkowski, 2014. Adaptive Cluster Sampling with Spatially Clustered Secondary Units. Journal of Applied Sciences, 14: 2516-2522.
DOI: 10.3923/jas.2014.2516.2522
URL: https://scialert.net/abstract/?doi=jas.2014.2516.2522
DOI: 10.3923/jas.2014.2516.2522
URL: https://scialert.net/abstract/?doi=jas.2014.2516.2522
INTRODUCTION
Adaptive Cluster Sampling (ACS) was proposed by Thompson (1990) with the purpose of estimating the abundance of a rare and clustered population. For instance, if a researcher wishes to estimate the population size for a rare animal or plant species in a study area, then ACS can be an appropriate and efficient sampling design use (Thompson and Seber, 1996). Assume that a population study area is divided into a set of geographic units or plots of the same size. In ACS, an initial sample of units is selected by implementing a conventional sampling design, such as simple random sampling or systematic sampling. Whenever the value of the variable of interest of a unit in the sample satisfies some desirable condition determined by the researcher, its neighboring units are recursively added to the sample until there is no sampled unit satisfies the condition. The condition C is typically defined to be an interval in the range of the variable of interest. For example, if y is the observed species count for a sampled unit, then continue sampling if y>0 or, in other words, C corresponds to continued sampling if the species is present. The set of all units that satisfy the condition C in the neighborhood of each other is called a network. That is, sampling any network unit will lead to adaptively sampling every unit in the network. The units that were adaptively sampled but did not satisfy the condition are called edge units. A network and its corresponding edge units is called a cluster. Units that do not satisfy the condition, including edge units, are considered networks of size one.
It was shown that ACS will be less efficient than (non-adaptive) simple random sampling for a population having a low abundance and with individuals that are not spatially clustered (Christman, 1997; Brown, 2003). On the other hand, the advantage of ACS is its flexibility because the researcher can determine the initial sample size, the size of the sampling unit, the definition of a neighborhood and the condition defining when to adaptively sample (Turk and Borkowski, 2005). The most common neighborhood defined for a unit is the set of four adjacent units (above, below, left and right).
The researcher must also select the initial sampling plan. In addition to ACS with an initial simple random sample, systematic ACS and strip ACS were introduced by Thompson (1991). For these sampling designs, an initial sample of units is taken using systematic sampling and strip sampling before adaptively sampling. Stratification in ACS was also discussed by Thompson (1991).
Many scientific studies have applied ACS. For example, ACS was applied in subtidal microalgae to estimate the abundances of three algal species at three islands and two levels of wave exposure (Goldberg et al., 2007). Moreover, a two-stage sampling procedure was applied to estimate the total for a spatially aggregated, moving animal population in a large study are (He et al., 2013). For this study, ACS was considered in the first stage and capture-recapture sampling was used in the second stage.
The estimators developed for adaptive cluster sampling with an initial sample taken with or without replacement of sampled units are based on Hansen-Hurvitz and Horvitz-Thompson estimation (Thompson, 1990). Moreover, these estimators can be applied to systematic, strip and stratified ACS. Dryver and Thompson (2005) proposed an improved unbiased estimator in ACS which is derived by taking the expectation of the usual estimator conditional on a sufficient statistic which is not minimal sufficient. In addition, Dryver and Chao (2007) introduced new ratio estimators under ACS.
Note that, in ACS, when a selected unit satisfies the condition C, all units within its neighborhood are added to the sample. Notice that if a sampling unit is physically large, it can take long time to determine the response of interest, as well as be expensive in cost, when considering the neighboring network and edge units. This study proposes an adaptive strategy of adding “smaller” secondary neighboring units. That is, some part of each neighboring primary unit will be observed instead of the entire primary unit as is done in most ACS plans. ACS with this proposed approach of adaptively adding secondary units is called Adaptive Cluster Sampling with a Spatial Cluster of Secondary Units (ACS-SCSU).
ADAPTIVE CLUSTER SAMPLING WITH SPATIALLY CLUSTERED SECONDARY UNITS AND TECHNICAL NOTATION
The population is assumed to consist of N equal-sized rectangular primary units ui (i = 1, 2, 3,…, N) and each ui is divided into two rows and two columns forming four equal-sized rectangular secondary units uij (j = 1, 2, 3, 4). Thus, the study region contains 4N secondary units. The value of the population variable of interest corresponding to each secondary unit uij is denoted as yij. The parameter of interest in this study is the population mean:
![]()
or the population total τ = 4 Nμ.
Adaptive cluster sampling with spatially clustered secondary units design: In ACS-SCSU, an initial sample of primary units of size n is selected by simple random sampling without replacement. Then for each sampled primary unit ui (i = 1, 2,…, n), neighboring secondary units are added to the sample and observed whenever the variable of interest yij of a secondary unit uij satisfies a criterion C. This procedure continues until no adaptively sampled secondary units satisfy C. The set of all secondary units satisfying C as a result of uij being in the initial sample form a network while the secondary units that were adaptively sampled but did not satisfy C are edge units. Together these units form a cluster. For example, suppose a population consists of 20 primary units, each with 4 secondary units as shown in Fig. 1. To illustrate the ACS-SCSU scheme, suppose n = 2 primary units are selected by simple random sampling without replacement. These are shaded grey in Fig. 1a. Let the condition C correspond to yij>0 (i.e., the variable of interest being positive for secondary unit uij). Because the leftmost primary unit contains four secondary units with yij = 0, C is not satisfied for any secondary unit. Thus, no additional unit will be adaptively added to the sample about this primary unit. On the other hand, the rightmost primary unit does contain a secondary unit satisfying C with yij = 103. Thus, its two neighboring secondary units are adaptively sampled which have yij-values of 10 and 150 as shown in Fig. 1b. These two secondary units also satisfy condition C, so their neighboring secondary units are sampled as shown in Fig. 1c. The procedure continues, as shown in Fig. 1d but sampling terminates because no neighboring secondary units satisfy the condition. The final sample consists of 19 secondary units and is shown in Fig. 1e. In Fig. 1f, the network consists of the 5 dark grey secondary units with the 14 light grey secondary units being edge units or units in the original sample not satisfying C.
Estimation: For the ACS-SCSU design, the Horvitz-Thompson estimator (Horvitz and Thompson, 1952) is used, but it is based on network inclusion probabilities which are determined post data collection and only for the networks observed in the final adaptive cluster sample. Let αk be the probability that network k is included in the final sample. The αk is called the inclusion probability of network k.
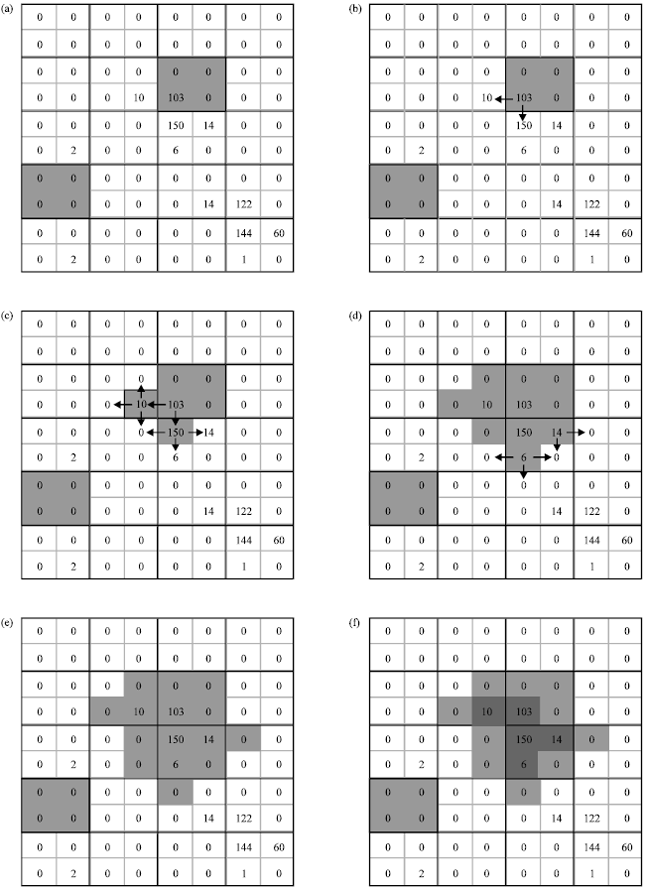 | |
| Fig. 1(a-f): | Adaptive cluster sampling with spatially clustered secondary units sampling scheme |
For ACS-SCSU, αk is the probability at least one of the n primary units in the initial sample intersect network k. Let, xk be the number of primary units in the population of n primary units which intersect network k. Using complementary probability, the probability that network k is included in the final sample is:
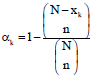 | (1) |
Let, Ai be the event that network i is included in the final sample. Thus, P(Aj) = αj and P(Ak) = αk for network j and k, respectively. Let, αjk be the probability that distinct networks j and k are both included in the final sample and it is also called the joint inclusion probability of networks j and k. It can be written as:
![]()
Thus:
| (2) |
where, P(Aj∪Ak) is the probability that at least one of networks j and k is included in the final sample. Using complementary probability:
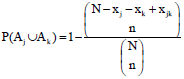 | (3) |
where, xjk is the number of primary units in the population which intersect both networks j and k. Hence, substitution yields:
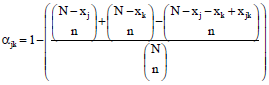 | (4) |
Let, Ik be the indicator variable such that Ik = 1 if at least one primary unit in the initial simple random sample intersects network k and Ik = 0 otherwise. Using calculated inclusion probabilities, the Horvitz-Thompson estimator is applied in the ACS-SCSU design and the unbiased estimator of the population mean μ is:
| (5) |
where, K is the total number of networks in the population. If network k is not included in the final sample, then Ik = 0 and it contributes zero to Eq. 5. Thus, the value of k does not need to be known to calculate ![]() . Also note that although different primary units in the initial sample might intersect the same network, only the distinct networks observed in the final sample are utilized in the equation.
. Also note that although different primary units in the initial sample might intersect the same network, only the distinct networks observed in the final sample are utilized in the equation.
Applying the results of Horvitz and Thompson (1952), the variance of ![]() is:
is:
| (6) |
Note that αkk = αk. An estimator of this variance is:
| (7) |
and is unbiased if all joint inclusion probabilities αjk are greater than zero.
SIMULATION STUDY
Data from the blue-winged teal study (Smith et al., 1995) was used in a simulation to investigate the performance of ACS-SCSU compared to ordinary adaptive cluster sampling of primary units. The simulation consisted of 1000 iterations. For the ith iteration, the value for the relevant estimator ![]() and the effective (final) sample size υi were calculated. The formulas used to estimate an estimator variance and the estimated expected effective sample size of secondary units are:
and the effective (final) sample size υi were calculated. The formulas used to estimate an estimator variance and the estimated expected effective sample size of secondary units are:
| (8) |
where, ![]() is the sample mean of the 1000
is the sample mean of the 1000 ![]() values (Dryver and Thompson, 2005). The blue-winged teal study area as shown in Fig. 2, consists of 50 primary units with each containing 4 secondary units. The simulation was considered for condition C to compare conventional ACS to ACS-SCSU: adaptively sample if yij>0. For the 1000 simulated samples and for the condition C,
values (Dryver and Thompson, 2005). The blue-winged teal study area as shown in Fig. 2, consists of 50 primary units with each containing 4 secondary units. The simulation was considered for condition C to compare conventional ACS to ACS-SCSU: adaptively sample if yij>0. For the 1000 simulated samples and for the condition C, ![]() and υ for ACS and ACS-SCSU were compared.
and υ for ACS and ACS-SCSU were compared.
The simulation results were presented in Table 1.
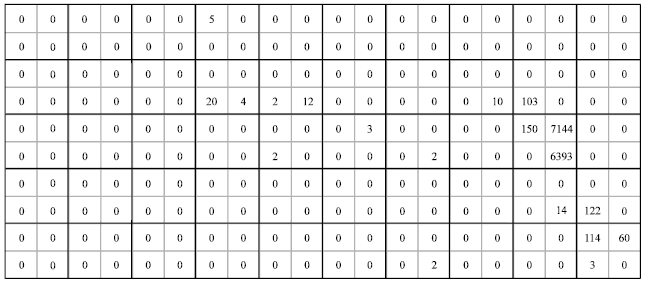 | |
| Fig. 2: | Blue-wing teal population data (Smith et al., 1995) |
| Table 1: | Results from the simulation study on the blue-winged teal data under the condition y>0 and the estimated relative efficiencies |
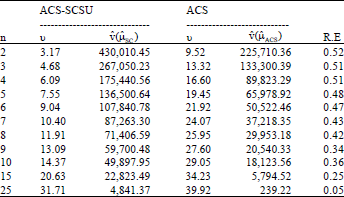 | |
These results indicated that conventional ACS had a smaller average estimated variance than ACS-SCSU for each initial sample size n and the estimated relative efficiencies (ratio of the estimated variances: R.E.) were less than one. Hence, ACS is more efficient than ACS-SCSU when considering the same value of the initial sample size. This, however, is misleading, because the effective sample sizes can be very different. The effective sample size υ reflects the true sampling effort incurred by the researcher (and not n). Thus, it is typical in ACS simulation studies to compare variances when υ is similar between two ACS plans (Turk and Borkowski, 2005). Note now that for the same initial sample size n, υ is smaller for ACS-SCSU than ACS. Thus, ACS-SCSU will, on average, be more efficient in terms of cost and for the time consumed travelling to observe the units in the final sample.
The average estimated variances presented in Table 1 were plotted against the estimated expected effective sample size in the graphs in Fig. 3. The graph of variances for ACS-SCSU was below the graph for ACS.
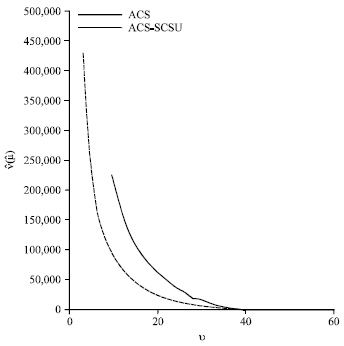 | |
| Fig. 3: | Average estimated variances from the simulation study on the blue-winged teal data |
This implies that estimated variances of the estimator of the mean for ACS-SCSU are smaller, on average, than the estimated variances under ACS for the same average effective sample size. Thus, when considering the same final sample size as the important sampling requirement, ACS-SCSU is more efficient than ACS for estimating the population mean.
DISCUSSION
Adaptive cluster sampling designed with spatially clustered secondary units can be time and cost-effective when the population of interest is spatially aggregated into relatively few networks and be more efficient that ordinary ACS with a simple random sample of primary units. Under ordinary ACS, the final sample size varies from sample to sample because units are adaptively added until no unit meets the criterion C (Thompson, 1990). Because the final sample size is not controlled, the final sample size can be quite large (Thompson, 2006). This can lead to a high cost of travelling within the study area and take much time to observe the sampled units. In comparison, ACS-SCSU will yield a smaller final sample size because secondary units are adaptively added in the sample instead of primary units and the secondary unit is one-fourth the size of a primary unit. Thus, the overall cost and time spent collecting the data is reduced. This was demonstrated by the results of the simulation study on the blue-winged teal population. ACS-SCSU has a smaller final sample size than ACS given the same initial sample size n.
The Horvitz-Thompson estimator based on partial inclusion probabilities is applied to ACS-SCSU for estimation of the population mean. Many sampling designs use the Horvitz-Thompson estimator because the inclusion probabilities can be obtained (e.g., path sampling (Patummasut and Dryver, 2012), simple latin square sampling±k designs (Borkowski, 2003), ACS (Thompson, 1990), inverse sampling (Mohammadi and Salehi, 2012), line-intercept sampling (Lucas and Seber, 1977). For ACS, the partial inclusion probabilities are used instead of actual inclusion probabilities since not all of the inclusion probabilities are known from the sample data. Similarly, under ACS-SCSU, partial inclusion probabilities are calculated and utilized in the Horvitz-Thompson estimator.
It is known that an improved unbiased estimator in adaptive cluster sampling exists and which can be derived by taking the expected value of the estimator conditional on a sufficient statistic which is not minimal sufficient (Dryver and Thompson, 2005). This idea can be used to find an improved unbiased estimator for ACS-SCSU data.
Estimation using ACS-SCSU may be improved by applying ratio estimation because, in general, the ratio estimator is often more precise (Dryver and Chao, 2007). The researcher, however, would need an appropriate auxiliary variable that is correlated with the response variable of interest. This is a problem being currently researched.
CONCLUSION
A new approach of adaptively adding units in the sample under adaptive cluster sampling was presented in this study. For ordinary adaptive cluster sampling, the whole region of a neighboring primary unit is added to the sample if the primary unit satisfies condition C. If a primary unit is large, it may take a long time and incur a high cost to observe all neighboring network units. Thus, adaptive cluster sampling of spatially clustered secondary units (ACS-SCSU) was proposed. In this sampling design, the primary unit is partitioned into four secondary units and secondary units are adaptively added to the sample instead of primary units. This leads to a smaller final sample size, so it will take less time and cost to travel and observe units in the final sample. The Horvitz-Thompson estimator based on partial inclusion probabilities was applied to estimate the population mean. In this study, ACS-SCSU and ACS were compared in a simulation study. According to the simulation results, for the same initial sample size, ACS-SCSU had a smaller expected effective sample size than that of ACS. Thus, ACS-SCSU would have lower cost and shorter time spent travelling and observing units in the final sample. ACS-SCSU estimators had smaller variances than ACS estimators for the same expected effective sample size. Thus, ACS-SCSU was more efficient than ACS for the same final sample size.
ACKNOWLEDGMENT
We are grateful to the Institute for Promotion of Science Teaching, Thailand, for financial support.
REFERENCES
- Brown, J.A., 2003. Designing an efficient adaptive cluster sample. Environ. Ecol. Stat., 10: 95-105.
CrossRef - Christman, M.C., 1997. Efficiency of some sampling designs for spatially clustered populations. Environmetrics, 8: 145-166.
CrossRef - Dryver, A.L. and S.K. Thompson, 2005. Improved unbiased estimators in adaptive cluster sampling. J. R. Stat. Soc.: Ser. B (Stat. Methodol.), 67: 157-166.
CrossRefDirect Link - Dryver, A.L. and C.T. Chao, 2007. Ratio estimators in adaptive cluster sampling. Environmetrics, 18: 607-620.
CrossRefDirect Link - Goldberg, N.A., J.N. Heine and J.A. Brown, 2007. The application of adaptive cluster sampling for rare subtidal macroalgae. Mar. Biol., 151: 1343-1348.
CrossRef - Horvitz, D.G. and D.J. Thompson, 1952. A generalization of sampling without replacement from a finite universe. J. Am. Stat. Assoc., 47: 663-685.
Direct Link - Lucas, H.A. and G.A.F. Seber, 1977. Estimating coverage and particle density using the line intercept method. Biometrika, 64: 618-622.
CrossRefDirect Link - Mohammadi, M. and M.M. Salehi, 2012. Horvitz-thompson estimator of population mean under inverse sampling designs. Bull. Iran. Math. Soc., 38: 333-347.
Direct Link - Patummasut, M. and A.L. Dryver, 2012. A new sampling design for a spatial population: Path sampling. J. Applied Sci., 12: 1355-1363.
CrossRef - Smith, D.R., M.J. Conroy and D.H. Brakhage, 1995. Efficiency of adaptive cluster sampling for estimating density of wintering waterfowl. Biometrics, 51: 777-788.
Direct Link - Thompson, S.K., 1991. Adaptive cluster sampling: Designs with primary and secondary units. Biometrics, 47: 1103-1115.
Direct Link - Turk, P. and J.J. Borkowski, 2005. A review of adaptive cluster sampling: 1990-2003. Environ. Ecol. Stat., 12: 55-94.
CrossRef