
Payam Hassany Shariat Panahy
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Fatimah Sidi
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Lilly Suriani Affendey
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Marzanah A. Jabar
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Hamidah Ibrahim
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Aida Mustapha
Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Selangor 43400, Malaysia
Journal of Applied Sciences
Year: 2013 | Volume: 13 | Issue: 1 | Page No.: 95-102







ABSTRACT
Improving data quality is a basic step for all companies and organizations as it leads to increase opportunity to achieve top services. The aim of this study was to validate and adapt the four major data quality dimensions’ instruments in different information systems. The four important quality dimensions which were used in this study were; accuracy, completeness, consistency and timeliness. The questionnaire was developed, validated and used for collecting data on the different information system’s users. A set of questionnaire was conducted to 50 respondents who using different information systems. Inferential statistics and descriptive analysis were employed to measure and validate the factor contributing to quality improvement process. This study has been compared with related parts of previous studies; and showed that the instrument is valid to measure quality dimensions and improvement process. The content validity, reliability and factor analysis were applied on 24 items to compute the results. The results showed that the instrument is considered to be reliable and validate. The results also suggest that the instrument can be used as a basic foundation to implicate data quality for organizations manager to design improvement process.
PDF Abstract XML References Citation
Received: October 24, 2012;
Accepted: December 22, 2012;
Published: February 01, 2013
How to cite this article
Payam Hassany Shariat Panahy, Fatimah Sidi, Lilly Suriani Affendey, Marzanah A. Jabar, Hamidah Ibrahim and Aida Mustapha, 2013. Discovering Dependencies among Data Quality Dimensions: A Validation of Instrument. Journal of Applied Sciences, 13: 95-102.
DOI: 10.3923/jas.2013.95.102
URL: https://scialert.net/abstract/?doi=jas.2013.95.102
DOI: 10.3923/jas.2013.95.102
URL: https://scialert.net/abstract/?doi=jas.2013.95.102
INTRODUCTION
In the last decades, assessment and improvement of data and information quality issues have been grown quickly (Lee et al., 2002). Moreover, many organizations have invested to gather, store, retrieve, elaborate huge amounts of data (Borek et al., 2011; Carey et al., 2006). There are some problems and difficulties in the nature of the data from the technical (data integration) to the nontechnical (lack of consistent strategy in organization). Assessing and improving the quality of data will improve business process and leads to make smart decisions (Madnick et al., 2009). Missing value, duplicate and inaccurate data are examples of data quality problems that exist in the real world (Scannapieco et al., 2005). Based on the researchers and experts’ understanding; data quality has various definition in different field and period. According to quality management, data quality is “appropriate for use” or “to meet user needs” (Alizamini et al., 2010).
Based on previous studies, data quality dimensions have dependency on each other (Barone et al., 2010). Improving dependency structure among a set of data quality dimensions is referred to dependency discovery. Logical interdependence analysis (Gackowski et al., 2004), tradeoff analysis (Madnick et al., 2009; Scannapieco et al., 2005; Alizamini et al., 2010; Gackowski et al., 2004) and data dependency analysis are examples of researches to discover dependency structure among quality dimensions (Barone et al., 2010). The effectiveness of information systems is related to the quality of information resources for solving problems and making decisions (Barone et al., 2010). However, for improving activities and making correct decision, organizations need enough knowledge about correctness and relationship among data quality dimensions. Dependency model between quality dimensions can be divided to three main categories as: Prefect dependency, partial dependency and independency (DeAmicis et al., 2006). However, there are some deficiencies on one dimension that can effect on another dimension. Relationship between quality dimensions is basically in terms of trade-off. The examples of trade-off are between accuracy and timeliness and completeness and consistency. The first trade off refers if information becomes better over time, it has more accuracy with negatively effect. Another trade-off between completeness and consistency dimensions indicates if data is more complete, its consistency is less. In another word if data is more complete it has more lack of consistency (Han and Venkatasubramanian, 2003; Fisher et al., 2006; DeAmicis et al., 2006). As a result, discovering data quality dependency is a basic step for making decision and developing activity (Lee et al., 2002).
Based on the literature review, there are many data quality dimension that can be assessed and improved (Sidi et al., 2012). In this work, we focus on the four important data quality dimensions which can be measured by standards applied to a database directly (Wang and Strong, 1996; Kahn et al., 2002). The four most important data quality dimensions are: Timeliness, accuracy, consistency and completeness (O’Donoghue et al., 2012). The generally known definitions of these dimensions in the field of data quality are as follows:
| • | Timeliness: To extent which age of data is appropriated for the task at hand (Wang and Strong, 1996) |
| • | Accuracy: To extent, which data is correct, reliable and certified (Wang and Strong, 1996) |
| • | Completeness: To extent to which data are of sufficient breadth, depth and scope for the task at hand (Wang and Strong, 1996) |
| • | Consistency: To extent which data is presented in the same format and compatible with previous data (Wang and Strong, 1996) |
Nevertheless, the progress of some researches is related to use of a standard framework and identifying its validity. Also, the results of one study cannot be generalized without repeating research in different sample and population.
The main objective of this study was, to empirically validate ACCTI (accuracy, completeness, consistency and timeliness, improvement process) framework. The results will provide a set of reliable and valid construct for assessing data quality dimensions which can be used to evaluate relationship among quality dimensions. Generally, applying different statistical methods provides evidence that the proposed framework can be used confidently in the future researches.
PROPOSED DATA QUALITY DIMENSIONS’ FRAMEWORK
Based on the literature, information provider and consumer produce various qualities on the information system. However, quality of information will be judged by information consumers to check if it will be fit for users or not (Katerattanakul and Siau, 1999).
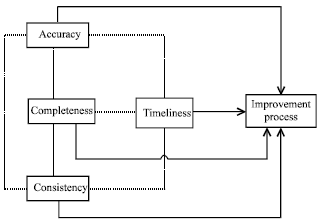 | |
| Fig. 1: | ACCTI framework |
Information quality should be accessed via framework by consumers who utilize the information based on their information quality needs (Katerattanakul and Siau, 1999; Strong et al., 1997).
Moreover, as discussed earlier, data quality has different dimensions and; finding relationship among them is necessary for improving process quality in different application and domains (Sidi et al., 2012). Finding effective dependencies and relationship can be useful and comprehensive for decision making process (Barone et al., 2010). In fact, dependency discovery is consist of measuring attributes of quality dimensions and recovering dependency structure among them for extracting knowledge (Sadeghi and Clayton, 2002; Strong et al., 1997). Selection of appropriate dimensions and analysis correlation among them is one of the ways that led to have high quality process (Katerattanakul and Siau, 1999).
The proposed framework shows dependency structure among following data quality dimensions; accuracy, completeness, consistency, timeliness and their relationship with data quality improvement process. The hypothesis is accuracy, completeness, consistency dimension are related to timeliness. Another hypothesis is all four quality dimension are related to improvement process. Figure 1 shows preliminary framework for four data quality dimensions.
In conclusion, the proposed of this framework is to discover dependent structure for evaluating data quality improvement via questionnaire and validate it in different information system.
METHOD, EMPIRICAL VALIDATION
Survey research has been used widely in the field of information system and there are number of validate quantitative instruments for the researcher in this field (Kock and Verville, 2012). Typically, questionnaire is used for data collections in specific topics with the goal of generalize the result of the sample to a population (Creswell, 2009).
The objective of this research is to validate the propose framework in different information. Qualitative approach was used in this research with the aim of establishing meaning of variable from the view of participants.
Utilized methodology for this research was based on common set of standards measuring for latent variables. The methods to conduct and identify quality dimensions dependency was as follow:
| • | Construct framework among quality dimensions based on literature review for assessing dependency |
| • | To use questionnaire for mentioned dimensions, based on the last standard questionnaire |
| • | To self-develop questionnaire for improvement process based on literature |
| • | To implement a survey for gathering data to test the framework |
| • | To use empirical methods for analyzing and validating the framework |
Based on the proposed research framework, the close ended questionnaire was used and developed. Questions for data quality dimension, were adapted from the latest standard questionnaire (Lee et al., 2002) and the questionnaire for the quality improvement was gained based on the comprehensive literature. The concept of questions for improvement process was related to quality improvement process, user satisfaction and evaluation criteria of individual information systems. All questions for each dependent and independent variable was measured based on the 9 point Likert scale.
The measure for this study was based on MIT research for developing AIMQ methodology (Lee et al., 2002). The Likert scale used to assess each item was rating from 1 to 9, where 1 represented “not at all” and 9 represented “completely”. Although, previous study used 11 scales for four quality dimension variables, due to 11 scales were so confusing for the target respondents, the 1-9 scale was used by confirming with professionals. For the latest variable, which was improvement process, questionnaire was self-developing based on the comprehensive literature review by testing same variable scale 1-9.
The respondent selected randomly by cross sectional methods in the period of 2 weeks. They were users of various information systems in different places and organization. Simple Random Sampling (SRS) was used to select respondent because, besides of its advantages; free of classification error, requires minimum knowledge information of the population and effortless to interpret data collected (http://en.wikipedia.org/wiki/Simple_ random_sample), all predictable statistical techniques can be applied by it (Creswell, 2009). The target respondent were; undergraduate student, postgraduate student, academician, manager and faculty staff. The respondents were likely to possess knowledge about data or information about in information systems area.
There are many ideas for sufficient sample size in Structural Estimating Modeling (SEM). Some researchers recommended; the adequate sample size should be more than 200 (Kline, 2010) but some others argued that minimum size of the sample should be fifth times of the number of variables or each variable should have at least 10 respondent (Hatcher, 1994). So, in this study cause there are five variables 50 respondents or more should be adequate. However, based on >200 samples rules, if there is restriction on population size less sample size does not have any problem (Kline, 2010). From 70 questionnaires, 55 were returned, 3 of them did not understand concept of questions and gave same mark to all questions and 2 questionnaires were deleted based on our predefined rules, as follows:
| • | The questionnaire will be deleted if the respondents answer less than half of the question |
| • | The mean of answers for each item will be used to estimate missing value |
The questionnaire was sent via email or manually and from the 55 returned, responsible rate was 78.57% for 50 usable questionnaires. Approximately, 60% of respondent were female and 40% were male, around 48% of the respondents’ age were between 20-29 whom most of them were “postgraduate” student and around 54% mentioned that they chose “Student Information System” as a considering information system.
An empirical method with using quantitative and descriptive evidence is extensively used in any data quality research to study of real life context with finalizing observable evidence (Lee et al., 2002; Wang and Madnick, 1989).
The questionnaire was developed, validated and used for collecting data on the different information systems.
ACCTI INSTRUMENT DEVELOPMENT
The ACCTI instrument was developed based on the standard methods for questionnaire and testing (Fynes et al., 2005). The constructs was based on the extent literature and adapted to fit by running a pilot study. The proposed framework provides a preliminary assessment of the item’s reliability and validating; four major data quality dimensions and improvement process attributes. In this study, four data quality dimension; (accuracy, completeness, consistency, timeliness) and improvement process variables were measured and validated by gathering answers from the questionnaire’s respondents. Validating this instrument is one step to improve process quality in information systems.
The questionnaire with 29 questions of the ACCTI instrument was printed as a seven-page booklet; first page for introducing researchers, organization, summary and explanation about data, data quality, data quality dimensions, data quality improvement and information systems of data quality; second page, for the demographic question, five pages of questions for each variable which was divided to five sections and a five blank line for respondents’ suggestions. The questionnaire was given randomly to the target sample via email or manually. The questionnaire is as follows:
| Questionnaire; All items are measured on a 1 to 9 scale where 0 refers to “Not at All ” and 9 refers to “Completely”, Items which labels with “(R)” are reverse coded |
 |
 |
Content validity and reliability: The first process in the construct validity is establishing content validity. The six information system was selected as a domain. For data quality improvement, from 8 questions which were developed for these part 2 questions were deleted based on 5 IS expert’s suggestions. Totally, the feedback obtained from 5 experts suggested us that the items were representative of the construct and the measures are suitable for construct validity.
Second process is to test reliability. The test of reliability will be specifying the amounts of random error that exist in the measurement (Nunally and Bernstein, 1994). The scales were used to discover construct’s relationship; if the amount of error is increased the correctness of the result will be decrease (O’Leary-Kelly and Vokurka, 1998). Reliability was assessed by reporting Cronbach alpha reliability coefficient. An instrument is considered to be reliable if Cronbach alpha is at least 0.7. Rule of thumb for Cronbach alpha is as follow; more than 0.9 is considered as “Excellent”, 0.8 is “Good”, more than 0.7 is “Acceptable”, more than 0.6 is Questionable, more than 0.5 is “poor” and <0.5 is considered “Unacceptable” (Gliem and Gliem, 2003). In fact, the numbers of the items will have effect on the value of alpha. So in this study, totally Cronbach alpha of 0.923 was showed “Excellent” result with a good internal consistency of the item for each variable. Furthermore, the value of Cronbach alpha for each variable calculated separately and compared with previous research (Lee et al., 2002). Cause of developing questionnaire for improvement process there wasn’t any result to compare with it.
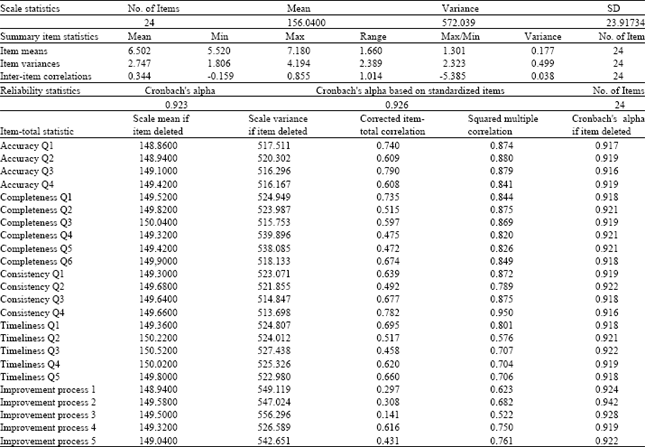
Table 1 shows computed Cronbach alpha of this study and previous study. The results shows alpha for the accuracy was 0.86, which indicate the items from a scale has reasonable internal consistency (excellent result) and it was almost same with 0.91 compare with previous study. Similarly, the alpha 0.88 for both completeness and consistency and 0.84 for timeliness indicate good internal consistency and they were almost same with previous study which was 0.87, 0.83, 0.88 but the 0.69 alpha for the improvement process scales indicated minimally adequate reliability (questionable result). The further result of reliability analyzes in detail is shown in Table 2 which indicate; total Cronbach alpha for 24 items was 0.929 which shows all the items have relatively high internal consistency. Moreover, according to “Corrected item-total correlation” because most correlations are moderately high to high, items will make a good component of a summated rating scale. So in total, obtaining results confirmed the items have relatively high internal consistency.
However, it should be remember that dimensionality of the items cannot be estimated by just having high value of Cronbach alpha and to determine the dimensionality of the items, factor analysis should be used (Gliem and Gliem, 2003) as it was the next process.
Exploratory factor analysis: There are several multivariate statistical techniques that it is used to analyze theoretical model. One of these techniques is factor analysis that attempts to classify any underling factors which have responsibility for the group of independent variable (Walker, 1999). The aim of factor analysis is to reduce the number of the items and shows which variable explain or determine relationship (Leech et al., 2007).
| Table 1: | Comparing Cronbach’s alpha with previous research |
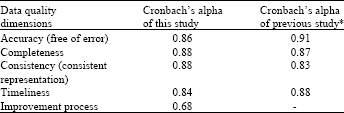 | |
| *Sidi et al. (2012) | |
| Table 2: | Summary items analysis from SPSS |
 | |
| Table 3: | Total variance explained |
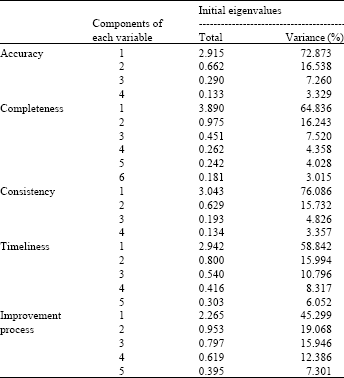 | |
| Extraction method: Principal component analysis | |
Moreover, exploratory factor analysis is determining empirically whether participant’s responses to the each part’s question are more similar to other parts (Leech et al., 2007).
Based on the assumption of exploratory factor analysis that data distribution should be normal (Leech et al., 2007), all the skewness of our data was checked. All skewness was between -2 to 2 that showed all items were distributed normally.
In addition, to transform a group of observed variable into an another group of variable “Principal Component Analysis” method was applied (Kim and Mueller, 1978). It was conducted with choosing scores greater than 0.4 in the factor matrix (it makes factor matrix be more readable) and with Varimax rotation techniques to extract factors with Eigenvalues more than 1, which shows the number of required factors. Eigenvalue<1 indicated that variables cannot contribute with average amount of explaining the variance and solution cannot be found for redundancy problem (Leech et al., 2007). Table 3 shows total variance explained; that indicates how the variance is divided among the items for each factor. The eigenvalues for the first factor of each variable were: accuracy 2.915, completeness 3.890, consistency 3.043, timeliness 2.942 and improvement process 2.265 that were greater than the next factors of related variable. Also, it shows the first factor of each variable accounted total variance of each variable as follow: accuracy 72.783%, completeness 64.836, consistency 76.086%, timeliness 58.842% and improvement process 45.299%.
| Table 4: | Principal component analysis |
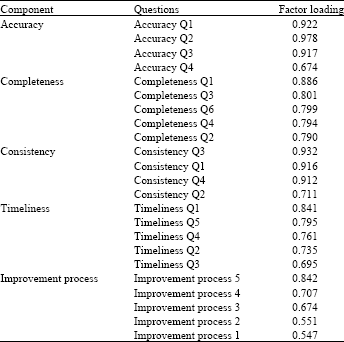 | |
Hence, it can be seen all 5 components of each variable have “total initial eigenvalues” more than 1 and it can be concluded; all items can be matched with their related variable and be grouped on one factor.
Factor loading value is the correlation between a variable and a factor, where only single factor is involved. If variable has higher loading it means that variable is closely at associated with the factor. The items with low loading less than.2 do not have high loading on the same factor (Leech et al., 2007). As it can be seen in Table 4 all components were loaded in the range between 0.547 and 0.932 (the loading was suppressed at 0.4) and factor loading for most components were more than.7 which is considered significant. So, based on these results structure of the construct for the proposed framework was confirmed.
The result of Kaiser-Meyer-Olkin (KMO) and Bartlett’s test which applied to measure sampling adequacy are shown in Table 5.
Researchers believe that if KMO be >0.7 there are sufficient items for each factor which is above of acceptable level of 0.5 that indicates the sample size is inadequate. So, based on KMO; enough items were predicted by each factor. Also, the Bartlett’s test was significant because it was less than 5 which indicates that all variables are highly correlated enough to provide reasonable basis for factor analysis (Walker, 1999).
Furthermore, a graphical representation of incremental variance for each factor in the model which is called Scree plot showed all the number of factors should be remained (Leech et al., 2007).
| Table 5: | KMO and Bartlett's test of the variables |
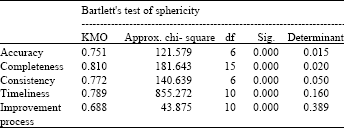 | |
Several assumptions were tested. All variable determinants were more than 0.0001 so a factor analytic solution could be obtained; (KMO) indicated that adequate items were predicted by each factor. Also, the reasonable basis for factor analysis was test by Bartlett test that showed there is high correlation between variables.
CONCLUSION AND FUTURE IMPLICATION
This study initiates that the ACCTI instrument is reliable and valid for the evaluation of the data quality dimensions and improvement process. The developing four major data quality dimension’s framework is important in the field of data quality and for improving quality of data. In this study, a valid and reliable instrument for data quality dimensions was developed. The proposed framework was justified through the empirical methods with the aim of being useful for measuring, assessing and analyzing four major quality dimensions. The construct validity was evaluated based on data that gathered from the questionnaire. Systematically, the content validity, reliability and factor analysis were applied on 24 items. Based on the results, ACCTI instrument factors-Completeness, Accuracy, Timeliness, Consistency and quality improvement-were considered to have construct validity. The values of the Cronbach’s alpha, correlation coefficients and composite reliability were indicated, ACCTI framework is reliable and valid. Factor loading showed that all items were clustered on the same suggested variable. Thus, the overall results indicated that our objective was accomplished and these factors could be confidently adopted for use to discover path relationship in the quality dimensions. Dependency discovery seems an appropriate approach to analyze the data quality dimensions. It can be a new way to study data quality based on their dimensions as well as to analyze the path among dimensions to assess and improve the quality of data in information systems. In this pilot study, based on dependency discovery structure, the framework was validated.
This framework can be used effectively in any information system in organizations and industrials. Several researches can be conducted by the direction of this framework. A possible future application can be the enhancing path analysis via Structural Estimating Modeling (SEM) to find detail relationship between quality dimensions with the objective of improving quality improvement process.
In the future, research can be extended to apply discovery dependency on data quality dimensions on the population. In such a way, the aim will be enhancing existing framework and approaches for improvement process in data quality in information system.
ACKNOWLEDGMENT
This research is supported by the Fundamental Research Grant Scheme (FRGS 03-12-10-999FR) from the Ministry of Higher Education, Malaysia.
REFERENCES
- Alizamini, F.G., M.M. Pedram, M. Alishahi and K. Badie, 2010. Data quality improvement using fuzzy association rules. Proceedings of the International Conference on Electronics and Information Engineering, Volume 1, August 1-3, 2010, Kyoto, Japan, pp: 468-472.
CrossRef - Barone, D., F. Stella and C. Batini, 2010. Dependency discovery in data quality. Proceedings of the 22nd International Conference on Advanced Information Systems Engineering, June 7-9, 2010, Springer, Hammamet, Tnisia, pp: 53-67.
CrossRef - O'Donoghue, J., T. O'Kane, J. Gallagher, G. Courtney and A. Aftab et al., 2012. Modified early warning scorecard: The role of data/information quality within the decision making process. Electron. J. Inform. Syst. Eval., 14: 100-109.
Direct Link - Fynes, B., C. Voss and S. de Burca, 2005. The impact of supply chain relationship quality on quality performance. Int. J. Prod. Econ., 96: 339-354.
CrossRefDirect Link - Gliem, J.A. and R.R. Gliem, 2003. Calculating, interpreting and reporting Cronbach's alpha reliability coefficient for likert-type scales. Proceedings of the Midwest Research-to-Practice Conference in Adult, Continuing and Community Education, October 8-10, 2003, The Ohio State University, Columbus, OH., USA., pp: 82-88.
Direct Link - Kahn, B.K., D.M. Strong and R.Y. Wang, 2002. Information quality benchmarks: Product and service performance. Commun. ACM., 45: 184-192.
CrossRefDirect Link - Kock, N. and J. Verville, 2012. Exploring free questionnaire data with anchor variables: An illustration based on a study of it in healthcare. Int. J. Healthcare Inform. Syst. Inform., 7: 46-63.
Direct Link - Lee, Y.W., D.M. Strong, B.K. Kahn and R.Y. Wang, 2002. AIMQ: A methodology for information quality assessment. Inform. Manage., 40: 133-146.
CrossRef - Madnick, S.E., R.Y. Wang, Y.W. Lee and H. Zhu, 2009. Overview and framework for data and information quality research. J. Data Inform. Qual., Vol. 1, No. 1.
CrossRefDirect Link - O'Leary-Kelly, S.W. and J.R. Vokurka, 1998. The empirical assessment of construct validity. J. Oper. Manage., 16: 387-405.
CrossRef - Scannapieco, M., P. Missier and C. Batini, 2005. Data quality at a glance. Datenbank-Spektrum, 14: 6-14.
Direct Link - Sidi, F., P.H. Shariat Panahy, L.S. Affendey, M.A. Jabar, H. Ibrahim and A. Mustapha, 2012. Data quality: A survey of data quality dimensions. Proceedings of the IEEE International Conference on Information Retrieval and Knowledge Management, March 13-15, 2012, Kuala Lumpur, Malaysia, pp: 300-304.
CrossRef - Strong, D.M., Y.W. Lee and R.Y. Wang, 1997. Data quality in context. Commun. ACM, 40: 103-110.
CrossRef - Han, Q. and N. Venkatasubramanian, 2003. Addressing timeliness/accuracy/cost tradeoffs in information collection for dynamic environments. Proceedings of the 24th IEEE Real-Time Systems Symposium, December 3-5, 2003, Cancun, Mexico, pp: 108-117.
CrossRef - Wang, J.R. and S.E. Madnick, 1989. The inter-database instance identification problem in integrating autonomous systems. Proceedings of the 5th International Conference on Data Engineering, February 6-10, 1989, Los Angeles, CA., USA., pp: 46-55.
CrossRef - Wang, R.Y. and D.M. Strong, 2013. Beyond accuracy: What data quality means to data consumers. J. Manage. Inform. Syst., 12: 5-34.
Direct Link