
Faisal G. Khamis
Faculty of Economics and Administrative Sciences, AL-Zaytoonah University of Jordan, Jordan
Ghaleb A. EL-Refae
Department of Banking and Finance, Al Ain University of Science and Technology, UAE
Journal of Applied Sciences
Year: 2012 | Volume: 12 | Issue: 15 | Page No.: 1564-1571







ABSTRACT
Although, many studies examined the existence of spatial pattern of Chronic Diseases (CDs) problem in many developed and some developing countries, in improving health status and reducing inequalities between areas of such country, there is still much work to be done. Some of these studies were found spatial pattern for CDs using different statistical techniques and geographical mapping. Question is raised whether the spatial pattern of CDs rate is existed in Iraq? The objective of this study was to investigate the spatial structure of CDs rate across governorates, showing visual picture for health status and to provide implications for policy makers. Both descriptive and inference analysis were done. Study design was a cross-sectional census data for 18 governorates conducted in 2007. Mapping was used as a first step to conduct visual inspection for CDs using quartiles. Two statistics of spatial autocorrelation, based on sharing boundary neighbours, known as global Moran’s I and local Moran’s Ii, were carried out for examining global clustering and local clusters, respectively. Global Moran statistic I = 0.06 wasn’t found significant with z = 0.91, p = 0.365 and permutation p = 0.175. Three local Moran statistics (I1 = 1.40, I5 = 0.71 and I7 = 0.38) were found significant with p-values (0.019, 0.020 and 0.058), respectively. In conclusion, high inequality in CDs was concentrated in eastern-northern and western-southern governorates based on visual inspection of mapping. Global clustering was not found in CDs but local clusters were found. Out of 18, three governorates were found as local clusters in CDs. Further research is needed to understand mechanisms underlying the influence of neighbourhood context.
PDF Abstract XML References Citation
Received: February 09, 2012;
Accepted: July 04, 2012;
Published: August 02, 2012
How to cite this article
Faisal G. Khamis and Ghaleb A. EL-Refae, 2012. Investigating Spatial Clustering of Chronic Diseases at Governorate Level
in Iraq-2007. Journal of Applied Sciences, 12: 1564-1571.
DOI: 10.3923/jas.2012.1564.1571
URL: https://scialert.net/abstract/?doi=jas.2012.1564.1571
DOI: 10.3923/jas.2012.1564.1571
URL: https://scialert.net/abstract/?doi=jas.2012.1564.1571
INTRODUCTION
Areas in close proximity with similar values produce a spatial pattern indicative of positive spatial autocorrelation. Identifying groups of areas in close proximity to one another with high and low values is often of particular interest, suggesting a cluster of elevated risk with perhaps a common source. Many diseases are spatially constrained. Disease clustering is an important issue within public health. Prior researches have produced an incomplete and often counterintuitive picture. A framework has been developed to better understand how CDs is spatially clustered across governorates of Iraq.
Many studies in several countries were shown the prevalence of CDs is very high and there is variation among studies. For example, in U.S. Wilper et al. (2008) reported that 31.3% of uninsured and 43.5% of insured had at least one of the six chronic illnesses. Furthermore, nearly 1 in 5 non-elderly adults 17.5% had a history of at least 2 chronic conditions, whereas 6.0% had 3 or more. In Southeast Michigan, Jamil et al. (2009) reported that prevalence of having any CD was 44% and the prevalence for Chaldeans was 32%, for Arabs 44% and for Whites and Blacks 50% for each group. In Vietnam, Minh et al. (2008) reported that 39% of the respondents had at least one of the studied CDs. A Swedish study by Guez et al. (2002) reported prevalence 43%. It was reported from HSE (2008) that the prevalence of CDs was 6.5% in men and 4.0% in women. Of 402 Tunisians diagnosed with leukemia, 85.6 and 14.4% had chronic leukemia (Haouas et al., 2011). In Sulaimani governorate, Iraq, Al-Windi (2011) stated that more than halve population reported having CD. He found the prevalence of CD higher among females 59.4% as compared to 49.4% in males based on his questionnaire data conducted during May, 2006. Hystad and Carpiano (2012) concluded that community-belonging was strongly related to health-behaviour change in Canada and may be an important component of population health prevention strategies.
In their study in Tilwana village and city of Elmenofia Governorate, Egypt, Ali et al. (2010) concluded that pediatric asthma is considered the most common chronic pediatric chest problem which has its impact on a child’s quality of life. The study conducted in U.S. by Liese et al. (2012) suggested that neighbourhood characteristics related to greater affluence, occupation and education are associated with higher type 1 diabetes risk based on multivariate generalized linear mixed models. Magalhaes and Clements (2011) estimated geographical risk profile of anemia accounting for malnutrition, malaria and helminthic infections in Burkina Faso, Ghana and Mali (2003-2006). They found malnutrition and parasites make to anemia.
To understand the linkage between socioeconomic health indicators, investigation should focus on features of areas rather than on compositional characteristics of residents of the area which cannot fully describe the social environment in which people live (Macintyre et al., 1993). In recent years, a growing interest has been seen in examining the existence of spatial autocorrelation in CD. However, governorates are tightly linked by migration, commuting and inter-governorate trade. These types of spatial interaction are exposed to frictional effects of distance, possibly causing the spatial dependence of governorate conditions. So, the aim of the research is to study spatial autocorrelation and geographical mapping regarding CDs.
Spatial autocorrelation is the term used for the interdependence of lattice data over space. However, it was argued that lattice data are spatially correlated, where Exploratory Spatial Data Analysis (ESDA) was used. The ESDA quantifies the spatial pattern in order to increase the analyst’s knowledge of the spatial system. As well as mapping plays an important role in monitoring health status of people. Maps can reveal spatial patterns that is neither recognized previously nor suspected from the examination of statistical tables. It reveals high risk communities or problem areas (Lawson and Williams, 2001). Findings are expected to enhance health status monitoring and policing interventions across governorates in Iraq.
Reducing inequality in CDs overall is not a primary objective but emergent prosperity. The importance of this research objective emanates the hypothesis stated that CDs can reduce people opportunities in keeping their job or/and getting a high salary job. Also, to authors’ knowledge no studies used spatial analysis techniques and geographical mapping in studying inequality in CDs in Iraq. The importance of mapping was stated by Koch (2005): why make the map if detailed statistical tables carry the same results? Perhaps the most important reason for studying spatial statistics is not only interested in answering the "how much" question but the "how much is where" question (Schabenberger and Gotway, 2005). Often, this question is related to the need for public health authorities to monitor unusual aggregations of diseases in localized areas within their area of authority. These concerns may be routine in that there may be a need to provide surveillance of particular diseases and to be aware of any atypical geographical distributions. Therefore, the usefulness of the paper is to suggest where to intervene geographically. The main purpose of this study is to measure spatial clustering in CDs in Iraq, with a special emphasis on geographic distribution. In light of these: (1) The existence of spatial global clustering and local clusters for CDs were investigated and (2) Mapping was displayed for CDs and its local Moran’s Ii values. The study design is a cross-sectional analysis in a census survey conducted in Iraq in 2007.
MATERIALS AND METHODS
Data: Data were collected from the tabulation report of Iraq household socio-economic survey conducted in 2007. For each of (N = 18) governorates, transformed CDs data were applied. CDs includes diabetes, high blood pressure, chronic inflammation, cancer, psychiatric, nervous and sensory, cardiac, respiratory, digestive, kidney disease, anemia and other. With respect to sex, CDs for males 11.5% was slightly lower than CDs for females 14.6%. However, these percentages vary geographically. In Kurdistan region, Baghdad and other governorates were 19.5, 14.9 and 10.9%.
Analysis: Data analysis involved five steps. In step 1, CDs variable was tested for normal distribution. It wasn’t found to follow normal distribution. Therefore, CDs was transformed to follow normal distribution using LISREL software. LISREL scales normal scores so that transformed variable has the same sample mean and standard deviation as the original variable. Thus, normal score is a monotonic transformation of original score with same mean and standard deviation (this characteristic can be considered as an advantage in this transformation) but with the values of skewness and kurtosis much reduced. In step 2, visual inspection based on quantified gradients for CDs was conducted using quartiles. Step 3 included the calculation of global Moran’s I-statistic for CDs to detect global clustering and the significance of I-statistic using permutation test was examined. Step 4 involved the calculation of local Moran’s Ii for ith governorate and it’s p-value using Monte Carlo simulation to detect local clusters. In step 5, visual inspection for local Moran values was inspected based on choropleth mapping.
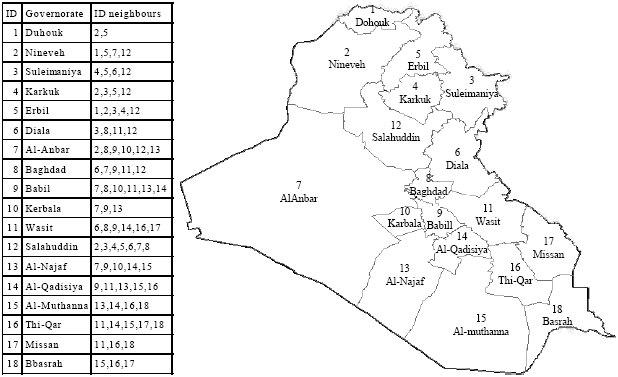 | |
| Fig. 1: | Study area shows all governorates with their ID and the neighbours of each governorate |
Maps showing diseases can help elucidate the cause of disease and may be used to generate hypotheses of disease causation. CD variable was categorized by four intervals. These intervals were used for all maps using darker shade of gray to indicate increasing value. Such approach enables qualitative evaluation of spatial pattern. In neighbourhood researches, neighbours may be defined as areas border each other or within a certain distance of each other. In this research neighbouring structure was defined as governorates shares a boundary. The second order method (queen pattern) which included both the first-order neighbours (rook pattern) and those diagonally linked (bishop pattern) was used. A neighbourhood structure of Iraq’s governorates is explained in Fig. 1, where identification numbers (ID) of neighbours for each governorate are shown.
To construct a choropleth map, data for enumeration governorates are typically grouped into classes and a gray tone was assigned to each class. Although, maps allow visual assessment for spatial pattern, they have two important limitations: their interpretation varies from person to person and there is possibility that a perceived pattern is actually the result of randomness and thus not meaningful. For these reasons, it makes sense to compute a numerical measure of spatial pattern which can be accomplished using spatial autocorrelation.
Identification of global clustering: The goal of a global index of spatial autocorrelation is to summarize the degree to which similar observations tend to occur near to each other in geographic space. In this exploratory spatial analysis, spatial autocorrelation using standard normal deviate (z-statistic) of Moran’s I under normal assumption was tested. Moran’s I coefficient is used to measure the strength of spatial autocorrelation in regional data. The null hypothesis of no spatial autocorrelation or spatially independent versus the alternative of positive spatial autocorrelation is as follows:
H0: No clustering exists (no spatial autocorrelation)
H1: Clustering exists (positive spatial autocorrelation)
Moran’s I is calculated as follows (Cliff and Ord, 1981):
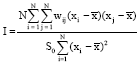 |
and
where, N is 18 is the number of governorates, wij is 1 is a weight denoting the strength of the connection between two governorates i and j, otherwise, wij is zero and xi and xj represents CDs in the ith and jth governorate, respectively.
To test the significance of global Moran’s I, z-statistic which follows a standard normal distribution was applied. It is calculated as follows (Weeks, 1992):
Permutation test was applied. A permutation test tells us that a certain pattern in data is or is not likely to have arisen by chance. The observations of CDs were randomly reallocated 1000 times with 1000 of spatial autocorrelations were calculated in each time to test the null hypothesis of randomness. The hypothesis under investigation suggests that there will be a tendency for a certain type of spatial pattern to appear in data. Whereas the null hypothesis says that if this pattern is present, then this is a pure chance effect of observations in a random order.
The analysis suggests an evidence of clustering if the result of global test is found significant; though it doesn’t identify the locations of any particular clusters. Besides clustering that represents global characteristic of CDs, the existence and location of localized spatial clusters are of interest in geographic sociology. Accordingly, local spatial statistic was advocated for identifying and assessing potential clusters.
Identification of local clusters: A global index can suggest clustering but cannot identify individual clusters (Waller and Gotway, 2004). Anselin (1995) proposed local Moran’s Ii statistic to test local autocorrelation. Local spatial clusters, sometimes referred to as hot spots, may be identified as those locations or sets of contiguous locations for which the local Moran’s Ii is significant. However, Moran’s Ii for ith governorate may be defined by Waller and Gotway as:
where, analogous to global Moran’s I, xi and xj represents CDs in the ith and jth governorate, respectively, Ni = number of neighbours for ith governorate and S is the standard deviation. It is noteworthy to mention that the number of neighbours for ith governorate were taken into account by the amount:
where, wij was measured in the same manner as in Moran’s I statistic. Local Moran statistic was used to test the null hypothesis of no clusters.
The most basic definition of cluster is any area within the study region of significant elevated risk. Cluster could be due to either aggregation of high values, aggregation of low values, or aggregation of moderate values. Thereby, high values of Ii suggesting a cluster of similar (but not necessarily large) values across several governorates and low value of Ii suggesting an outlying cluster in a single governorate i (being different from most or all of its neighbours). A positive local Moran value indicates local stability; such as governorate has high/low value surrounded by governorate has high/low value. A negative local Moran value indicates local instability, such as governorate has low value surrounded by governorate has high value or vice versa. However, each governorate’s Ii value was mapped to provide insight into the location of governorates with comparatively high or low local association with their neighbouring values. In statistical analysis, all programs were performed using SPLUS8 Software.
RESULTS
Descriptive statistics were calculated for transformed CDs. The mean and standard deviation were found 12.72 and 4.08, respectively. Skewness and kurtosis were found 0.00 and -0.10, respectively. The five-number summary of CDs data set consisted of minimum, maximum and quartiles written in increasing order: Min = 4.64, Q1 = 9.83, Q2 = 12.72, Q3 = 15.62 and Max = 20.81. From the five-number summary, the variations of the four quarters were found 5.19, 2.89, 2.90 and 5.19, respectively, where the 1st and 4th quarters have the greatest variation of all.
Figure 2a and b show visual insight for CDs and its local Moran values, respectively. Darkest shade corresponds to the highest quartile. These maps display geographical inequalities across governorates of Iraq. Based on visual inspection taken from Fig. 2a, an overall worsening pattern (higher scores) was found in eastern-northern and western-southern parts. The same was approximately found regarding visual inspection taken from Fig. 2b for local Moran values of CDs that worsening pattern was found in eastern-northern and western parts.
Suggestion of spatial clustering for CDs that follows a visual inspection of mapping was not confirmed by global Moran’s I of .06 with an associated z-statistic of 0.91 and p = 0.365. Although, global clustering was not confirmed, permutation test was done.
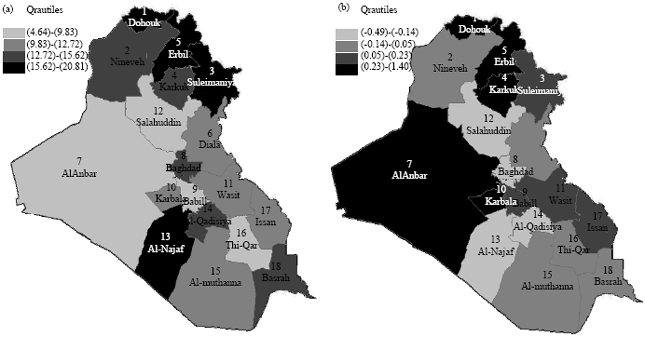 | |
| Fig. 2(a-b): | Choropleth maps show visual insight for: (a) CDs variable and (b) its local Moran values |
| Table 1: | Shows CDs variable, it’s transformed, it’s local Moran’s Ii value and it’s corresponding p-value |
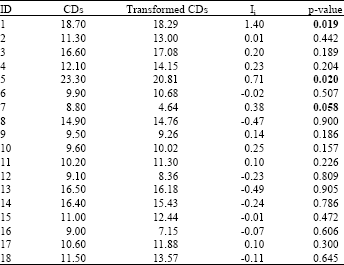 | |
| Bold values are significant at 0.10 level | |
Permutation p = 0.175 wasn’t found significant. Thus, the null hypothesis of no spatial autocorrelation wasn’t rejected accordingly. But, three significant local clusters (hot spots) were found. These clusters: 1, 5 and 7 are located, as shown in Fig. 2b, in northern and western parts. Table 1 shows local Moran values of CDs variable and their p-values.
Simulated data are useful for validating the results of spatial analysis. However, using Monte Carlo simulation, 9 999 random samples, eighteen values for each sample, were simulated. The process of simulation was conducted under standard normal distribution to calculate p-values for local Moran values of CD. When the word simulation is used, it is referred to an analytical method meant to imitate a real-life system, especially when other analyses are too mathematically complex or too difficult to reproduce. While research results were specific to these data, the case study helps to identify general concepts for future studies.
DISCUSSION
The above framework has revealed some noteworthy findings. Such findings allow policy makers to better identify what types of resources are needed and precisely where they should be employed. This study adds to the global body of knowledge on the utilization of spatial analysis to strengthen the research-policy interface in developing countries such as Iraq. Although, this work was conducted as part of a wider study, its immediate implications are more for policy makers and practitioners than for researchers. Spatial patterns had shown concentration of highly CDs in old governorates such as Duhouk, Erbil and Alanbar. The contribution to literature on CDs was shown by explaining where these patterns were located in Iraq. Findings of this study suggest that tackling CDs is a high priority. It should foster efforts to ensure that CDs prevention strategies include urban poor governorates.
Maps provide powerful means to communicate data to others. Unlike information displayed in graphs, tables and charts; maps also provide bookmarks for memories. In this way, maps are not passive mechanism for presenting information. Usually, in the spatial analysis and geographical mapping, small spatial areas should be used such as districts, counties…etc. But, in this research governorates were considered somewhat larger than for example districts due to data were not available for smaller areas. Most often the word ‘neighbourhood’ suggests a relatively small area surrounding individuals’ homes. But researchers commonly make use of larger spatial area such as census tracts (Coulton et al., 2001). Often, choices about neighbourhood spatial definitions were made with respect to convenience and availability of contextual data rather than study purpose (Schaefer-McDaniel et al., 2010). Schaefer-McDaniel et al. (2010) stated that researchers might utilize census data and thus rely on census-imposed boundaries to define neighbourhoods even though these spatial areas may not be the best geographic units for the study topic.
As noted by Waller and Jacques (1995), the test for spatial pattern employs alternative hypotheses of two types; the omnibus not the null hypothesis or more specific alternatives. Tests with specific alternatives include focused tests that are sensitive to monotonically decreasing risk as distance from a putative exposure source (the focus) increases. Acceptance of either types (the omnibus or a more specific alternatives) only demonstrates that some spatial pattern exist and does not implicate a cause (Jacques, 2004). Hence, the existence of a spatial pattern alone cannot demonstrate nor prove a causal mechanism.
It is very well known that employment is considered a major source for household income (HI). Generally, low income leads to several CDs. Iraq before, in and after 2007 faced specific challenges with regard to jobs in its state-owned enterprises. With over 500,000 workers on the payroll, state-owned enterprises are a major source of employment. Analysis of other episodes of conflict in Iraq indicated a very strong reciprocal relationship between the lack of security and high unemployment (World Bank, 2006). While, reconstruction and associated public-sector jobs are important in the initial phase of Iraq’s recovery, they will not create a sufficient number of jobs to meet the population’s needs in the long term; even if recovery is on a massive scale. Most researchers recommend designing global development strategies that focus on job creation and income generation and incorporate elements of basic social protection and social dialogue at the global and local levels as an attempt to reduce inequalities in CDs.
The application of statistical techniques to spatial data faces an important challenge, as expressed in the first law of geography: “everything is related to everything else but closer things are more related than distant things” (Tobler, 1979). The quantitative expression of this principal is the effect of spatial dependence, i.e., when observed values are spatially clustered, the samples are not independent. Increasing in CDs level in governorate i generates increasing in CDs level in governorate j. This mechanism of transmission leads to spatial autocorrelation in CDs.
Anselin (1995) stated that indication of local patterns of spatial association may be in line with a global indication, although this is not necessarily be the case. It is quite possible that local pattern is an aberration that global indicator would not pick up, or it may be that a few local patterns run in the opposite direction of global spatial trend. Local values that are very different from the mean (or median) would indicate locations that contribute more than their expected share to the global statistic. These may be outliers or high leverage points and thus would invite closer scouting. However, this is found in this research. Although, global Moran statistic was not found significant, three local Moran values were found significant. Limitation of this study was that causal relationship can’t be drawn due to this can only be done in prospective studies.
The obvious question after finding significant clusters in CDs is-why? Could this pattern associated by the spatial pattern of socioeconomic indicators such as HI or by the limitation of economic resources? However, further research is required regarding this bivariate spatial association between CDs and other socioeconomic indicators. The lack of adequate health care, health care system and adequate management could also belong to the reasons for poor health. This research will be our interest in Iraq and other developing countries in the near future. As stated by Barkera (2012), prevention of chronic disease and an increase in healthy aging require improvement in the nutrition of girls and young women. Many babies in the womb in the Western world today are receiving unbalanced and inadequate diets. Many babies in the developing world are malnourished because their mothers are chronically malnourished.
In essence, it should be emphasized that CDs problem cannot overcome in the short-run; but long-term efforts are needed to tackle inequalities across governorates. In turn, enabling the economy to create more job opportunities and establish new projects, especially in governorates that are found as hot spots. It means that the place of the problem is now clearly shown. Health inequalities are ubiquitous around the world. Thus, fresh perspectives to tackle inequalities are always welcomed by the research community invested in reducing and eventually eliminating these inequalities. Finally, this kind of studies should be conducted periodically in light of the changing of socioeconomic and political conditions.
CONCLUSIONS
Conclusions are comprehensive in at least four aspects. First, visual inspection shows that high level in CDs was concentrated in eastern-northern and western-southern governorates. While low level in CDs was concentrated in middle and some northern and southern governorates. Second, several governorates such as Alanbar, Kerbela and Babil are not observed visually as hot spots. But, after considering the information of their neighbours, the pattern of their hot spots can be obviously seen. Third, global clustering in CDs was not found significant. However, three governorates: Duhouk, Erbil and Alanbar were found significant local clusters. Forth, from negative local Moran values, looking at the local variation, some governorates were seen as areas of dissimilarity, such as Baghdad and Alnajaf. These conclusions are useful for organization and follow-up of medical care. By providing the necessary knowledge, patients and family are encouraged to effectively manage the disease process and improve their quality of life.
The analytical approach used here delineates governorates of relatively high CDs. This permits policy makers to develop strategies that minimize this inequality. Policy which pays attention to area characteristics will probably reduce CDs inequality. Consequently, this will generally improve population health in affected governorates. In summary, this study supports the hypothesis of spatial clustering in CDs at governorate level that probably reflects inequality distribution in several socioeconomic indicators. Further research is required to investigate spatial clustering in several socioeconomic indicators attempting to explain hot spots in CDs.
REFERENCES
- Ali, A., M.M. Sallam, G.A. Fathy, O.M. El-Din, S.A. Awad and A. Ahmed, 2010. Epidemiological study of the prevalence of bronchial asthma and other atopic diseases among school children in Egypt. Int. J. Acad. Res., 2: 209-217.
Direct Link - Anselin, L., 1995. Local indicators of spatial association-LISA. Geograph. Anal., 27: 93-115.
CrossRefDirect Link - Barkera, D.J.P., 2012. Developmental origins of chronic disease: The Richard Doll lecture. Public Health, 126: 185-189.
CrossRef - Coulton, C.J., J. Korbin, T. Chan and M. Su, 2001. Mapping residents perceptions of neighborhood boundaries: A methodological note. Am. J. Community Psychol., 29: 371-383.
CrossRefDirect Link - Guez, M., C. Hildingsson and M. Nilsson, 2002. The prevalence of neck pain: A population-based study form Northern Sweden. Acta Orthopnea Scandinavian, 73: 455-459.
CrossRef - Hystad, P. and R.M. Carpiano, 2012. Sense of community-belonging and health-behaviour change in Canada. Epidemiol. Community Health, 66: 277-283.
PubMed - Jacquez, G.M., 2004. Current practices in the spatial analysis of cancer: Flies in the ointment. Int. J. Health Geograph., Vol. 3.
Direct Link - Jamil, H., F. Dallo, M. Fakhouri, T. Templin, R. Khoury and H. Fakhouri, 2009. The prevalence of self-reported chronic conditions among Arab, Chaldean and African Americans in southeast Michigan. Ethnic. Dis., 19: 293-300.
PubMed - Liese, A.D., R.C. Puett, A.P. Lamichhane, M.D. Nichols and D. Dabelea et al., 2012. Neighborhood level risk factors for type 1 diabetes in youth: The SEARCH case-control study. Int. J. Health Geographics, Vol. 11.
CrossRefDirect Link - Macintyre, S., S. Maciver and A. Sooman, 1993. Area, class and health: Should we be focusing on places or people? J. Social Policy, 22: 213-234.
CrossRef - Minh, H.V., D.L. Huong and K.B. Giang, 2008. Self-reported chronic diseases and associated sociodemographic status and lifestyle risk factors among rural Vietnamese adults. Scand. J. Public Health, 36: 629-634.
PubMed - Schaefer-McDaniel, N., M.O. Caughy, P. O'Campo and W. Gearey, 2010. Examining methodological details of neighbourhood observations and the relationship to health: A literature review. Social Sci. Med., 70: 277-292.
CrossRefPubMedDirect Link - Waller, L.A. and G.M. Jacquez, 1995. Disease models implicit in statistical tests of disease clustering. Epidemiology, 6: 584-590.
Direct Link - Wilper, A.P., S. Woolhandler and K.E. Laser, 2008. A national study of chronic study prevalence and access to care in uninsured U.S. adults. Ann. Int. Med., 149: 170-176.
Direct Link