
I. Makhdoom
Department of Statistics, Payame Noor University, P.O. Box 19395-3697, Tehran, Iran
P. Nasiri
Department of Statistics, Payame Noor University, P.O. Box 19395-3697, Tehran, Iran
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 23 | Page No.: 3811-3814







ABSTRACT
This study deals with the estimation of parameters of the weighted exponential distribution with presence of outliers. The maximum likelihood and moment of the estimators are derived. These estimators are compared empirically using monte carlo simulation when all the parameters are unknown. There Bias and MSE are investigated with help of numerical technique.
PDF Abstract XML References Citation
Received: October 24, 2011;
Accepted: December 10, 2011;
Published: January 02, 2012
How to cite this article
I. Makhdoom and P. Nasiri, 2011. Estimation Parameters of Weighted Exponential Distribution with Presence of Outliers Generated from Exponential Distribution. Journal of Applied Sciences, 11: 3811-3814.
DOI: 10.3923/jas.2011.3811.3814
URL: https://scialert.net/abstract/?doi=jas.2011.3811.3814
DOI: 10.3923/jas.2011.3811.3814
URL: https://scialert.net/abstract/?doi=jas.2011.3811.3814
INTRODUCTION
Recently a new class of Weighted Exponential (WE) distribution has been proposed by Gupta and Kundu (2009). Different methods may be used to introduce a shape parameter to an exponential model and they may result in a variety of Weighted Exponential (WE) distribution. For example, the gamma distribution and the generalized exponential distribution are different weighted versions of the exponential distribution.
The random variable X is said to have a Weighted Exponential (WE) distribution with the shape and scale parameters as α>0 and λ>0, respectively, if it has the following probability density (PDF):
| (1) |
The corresponding Cumulative Distribution Function (CDF) for x>0, becomes:
| (2) |
From now on a WE distribution with the shape and scale parameters as α and λ, respectively will be denoted WE (α, λ).
Note that the WE (α, λ) can be obtained exactly the same way Azzalini (1985) obtained the skew-normal distribution from two i.i.d. normal distribution. Suppose X1 and X2 are i.i.d. exp (λ), i.e., an exponential random variable with mean 1/λ, then for α>0 consider a new random variable X = X1, if αX1≥X2. Then X follows WE (α, λ), Dixit et al. (1996), assume that a set of random variables (X1, X2,..., Xn) represent the distance of an infected sampled plant from a plant from a plot of plants inoculated with a virus. Some of the observations are derived from the airborne dispersal of the spores and are distributed according to the exponential distribution. The other observations out of n random variables (say k) are present because aphids which are know to be carriers of Barley Yellow Mosaic Dwarf Virus (BYMDV) have passed the virus into the plants when the aphids feed on the sap. Dixit and Nasiri (2001) considered estimation of parameters of the exponential distribution in the presence of outliers generated from uniform distribution. Also new Makhdoom (2011) obtained the estimation of the parameters of minimax distribution in the presence of one outlier. In this paper, we obtain the maximum likelihood and moment estimators of the parameters of the weighted exponential distribution in the presence of one outlier generated from exponential distribution.
Let the random variable X1, X2,..., Xn-k are independent, each having the probability density function f1 (x):
k random variables (as outlier) are also independent, have the probability density function f2 (x):
The joint density of X1, X2,..., Xn is given as:
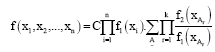 | (3) |
Where:
and:
(Dixit, 1989; Dixit et al., 1996; Dixit and Nasiri, 2001). The main of this paper is to focus on obtaining maximum likelihood estimators and moment estimators of WE (α, λ) with presence of outliers.
JOINT DISTRIBUTION OF (X1,..., Xn) WITH k OUTLIERS
The joint distribution of X1,..., Xn in the presence of k outliers after some computations in Eq. 3 is given by:
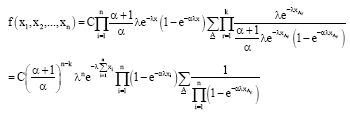 | (4) |
METHOD OF MOMENT
From Eq. 4, the marginal distribution of X is:
| (5) |
where, x>0, λ>0. Consider,
From Eq. 5 we get:
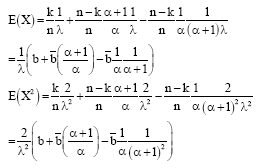 |
Let:
and:
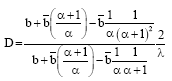 | (6) |
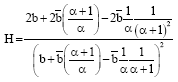 | (7) |
From Eq. 7, we have:
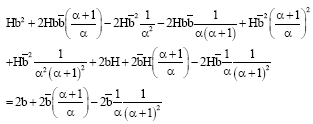 | (8) |
MAXIMUM LIKELIHOOD ESTIMATORS OF (α, λ1, λ2)
The joint distribution of X1,..., Xn in the presence of k outliers after some computations in Eq. 3 is given by:
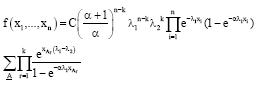 | (9) |
In Eq. 4, if let k = 1(for one outlier), the joint distribution of X1,..., Xn is given by:
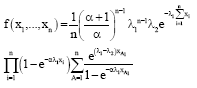 | (10) |
The Log-likelihood function of the observed sample is:
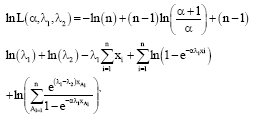 | (11) |
The MLE’s of α, λ1 and λ2 say ![]() and
and ![]() , respectively which is obtained as the solutions of:
, respectively which is obtained as the solutions of:
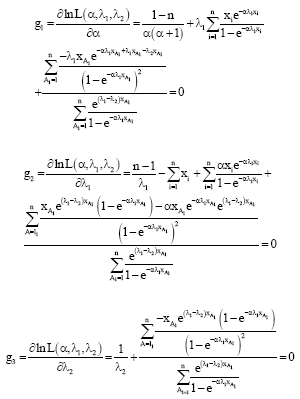 |
There is no closed-form solution to this system of equations, so we will solve for ![]() and
and ![]() iteratively, using the Newton-Raphson method for root finding. In our case we will estimate
iteratively, using the Newton-Raphson method for root finding. In our case we will estimate ![]() iteratively:
iteratively:
where, g and G are the vector of normal equations and matrix of second derivatives, respectively,
 |
The Newton-Raphson algorithm converges, as our estimates of θ, λ1 and λ2 change by less than a tolerated amount with each successive iteration, to ![]() and
and ![]() .
.
MAXIMUM LIKELIHOOD ESTIMATORS OF (α, λ)
Here, without loss of generality we assume λ1 = λ2 = λ. Then the Newton-Raphson method be reduced to estimation of θ = (α, λ) in WE (α, λ) with presence one outlier (k = 1) generate from exponential distribution. In this case the log-likelihood function based on the observed sample {x1,..., xn} is :
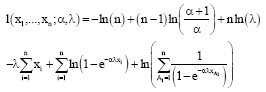 | (12) |
The elements of vector of normal equations (g) and matrix of second derivatives (G) are as following:
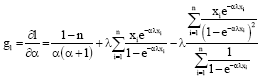 | (13) |
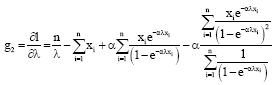 | (14) |
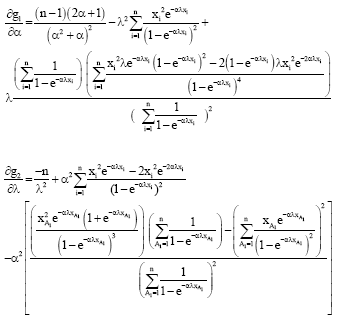 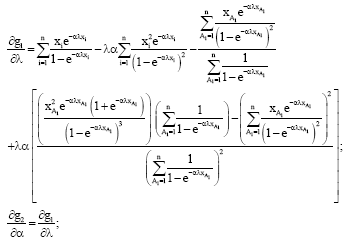 |
The Newton-Raphson algorithm converges, as our estimates of α and λ change by less than a tolerated amount with each successive iteration, to ![]() and
and ![]() .
.
Note in case of no outlier presence, Gupta and Kundu (2009) obtained the estimation of parameters weighted exponential by Maximum likelihood and Moment method.
NUMERICAL EXPERIMENTS AND DISCUSSIONS
In this study, we have addressed the problem of estimating parameters of Weighted Exponential distribution in presence of one outlier. In order to have some idea about Bias and Mean Square Error (MSE) of methods of moment and MLE, we perform sampling experiments using a SAS. The results are given in Table 1 and 2, when α = 3, λ = 0.5, α = 2 and λ = 1. We report the average estimates and the MSEs based on 1000 replications. It is observed that the maximum likelihood estimators are better than the moment estimators; these are true for all values of n.
| Table 1: | α = 3, λ = 0.5 |
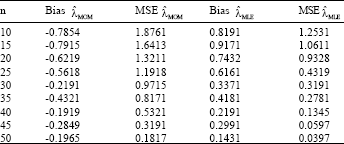 | |
| Table 2: | α = 2, λ = 1 |
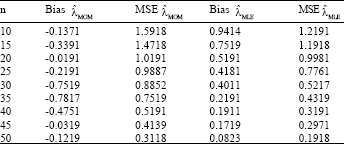 | |
Therefore we suggest using the maximum method for estimating parameters of the weighted exponential distribution in the presence of one outlier.
REFERENCES
- Azzalini, A., 1985. A class of distribution which includes the normal ones. Scand. J. Stat., 12: 171-178.
Direct Link - Gupta, R.D. and D. Kundu, 2009. A new class of weighted exponential distribution. Statistics: J. Theor. Applied Stat., 43: 621-634.
CrossRefDirect Link - Makhdoom, I., 2011. Estimation of the parameters of minimax distribution in the presence of outlier. Int. J. Acad. Res., 3: 500-507.
Direct Link
Parviz Nasiri Reply
I need one copy of this paper.
Thanks