
Bader Ahmad I. Aljawadi
Institute for Mathematical Research, Universiti Putra Malaysia, Malaysia
Mohd Rizam A. Bakar
Department of Mathematics, Institute for Mathematical Research, Universiti Putra Malaysia, Malaysia
Noor Akma Ibrahim
Department of Mathematics, Institute for Mathematical Research, Universiti Putra Malaysia, Malaysia
Habshah Midi
Department of Mathematics, Institute for Mathematical Research, Universiti Putra Malaysia, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 15 | Page No.: 2861-2865







ABSTRACT
In population based cancer clinical trials, a proportion of patients will never experience the interested event and considered as “cured” or “immunes”. The majority of recent cancer studies focus on the estimation of immune proportion. In this study we investigated the estimation of proportion of patients curd of cancer in case of left censored data based on the Bounded Cumulative Hazard (BCH) model proposed by Chen in 1999. The analysis provided the Maximum Likelihood Estimation (MLE) of the parameters within the framework of the Expectation Maximization (EM) algorithm where the numerical solutions of the estimation equations of the cure rate parameter could be employed.
PDF Abstract XML References Citation
Received: February 25, 2011;
Accepted: May 18, 2011;
Published: July 02, 2011
How to cite this article
Bader Ahmad I. Aljawadi, Mohd Rizam A. Bakar, Noor Akma Ibrahim and Habshah Midi, 2011. Parametric Estimation of the Immunes Proportion based on BCH Model and Exponential Distribution using Left Censored Data. Journal of Applied Sciences, 11: 2861-2865.
DOI: 10.3923/jas.2011.2861.2865
URL: https://scialert.net/abstract/?doi=jas.2011.2861.2865
DOI: 10.3923/jas.2011.2861.2865
URL: https://scialert.net/abstract/?doi=jas.2011.2861.2865
INTRODUCTION
Survival models that incorporate the cure fraction in the analysis are called cure rate models. Recently, survival cure models are being widely used in analyzing data from cancer studies. They are used for analyzing survival data from various types of cancer in which a proportion of patients becomes free of any signs or symptoms of the disease, Amiri et al. (2008). The first created cure rate model is the mixture model which constructed by Boag (1949) and later developed by Berkson and Gage (1952). In this model, a certain proportion π of patients are cured as well as the remain 1-π are not.
In this model the survival function for the entire population can be written in terms of the ‘mixture’ of the cured part plus the uncured part such that:
| (1) |
where, S (t) and Su (t) are the survival functions for the entire population and the uncured patients, respectively. The survival function of uncured patients can be estimated parametrically or non-parametrically which leads to parametric or semi-parametric survival function, respectively, where in the parametric case, a particular distribution for the failure time distribution of uncured patients could be employed such as exponential, Weibull, Gompertz, negative binomial and Generalized F distribution (Savadi-Oskouei et al., 2010).
The literature on mixture cure model could be found in the study of Gamel et al. (1990), Kuk and Chen (1992), Taylor (1995), Peng and Dear (2000), Sy and Taylor (2000), Peng and Carriere (2002), Uddin et al. (2006), Liu et al. (2006a), Yu and Peng (2008) and Abu Bakar et al. (2009).
In Eq. 1, S (t) = 1-F (t), where F (t) is the cumulative distribution function. Furthermore, F (0) = 0 and F (∞) = 1, so that S (0) = 1 and S (∞) = π the plateau value. The hazard function concomitant to this model is:
where, f (t) is the probability density function (p.d.f) attendant to F (t).
Despite the widely used of the mixture model in survival analysis, it has some limitations as was discussed by Chen et al. (1999), some of these drawbacks are:
| • | The proportional hazard structure which is a desirable property for any survival model cannot be constructed in the presence of covariates |
| • | When including covariates through the parameter π via a standard regression model, then mixture model yields improper posterior distributions for many types of non-informative improper priors, including the uniform prior for the regression coefficients |
| • | Mixture model does not appear to describe the underlying biological process generating the failure time, at least the context of cancer relapse, where cure rate models are frequently used |
Chen et al. (1999) proposed the Bounded Cumulative Hazard (BCH) model developed by Yakovlev et al. (1993) as the viable alternative to the mixture model. This alternative model is quite attractive for several aspects:
| • | It is derived from a natural biological motivation |
| • | It has proportional hazard structure through the cure rate parameter |
| • | It is computationally very attractive |
| • | It has a mathematical relationship with the mixture cure rate model |
The bounded cumulative hazard model assumes that for an individual in the population left with N cancer cells after the initial treatment. The cancer cells (often called clonogens) grow rapidly and replace the normal tissue later on (cancer relapse). N may follows Poisson, Bernoulli or negative binomial distribution (Rodrigues et al., 2009). However, in this study we will consider N to follow the Poisson distribution with a mean of θ.
Let Zi, i = 1, 2, þN denotes the time of the ith clonogen to produce detectable cancer mass. Then the time it takes cancer to relapse can be defined by the random variable T = min [Zi, 0≤i≤N], P (Zo = ∞) and Zi's are independent and identically distributed (i.i.d) and that N is independent of the sequence Z1, Z2, þ, ZN. Therefore, the survival function for T and hence for the population, is given by: S (t) = P (T>t) (Probability no cancer by the time t ).
 | (2) |
Since S (∞) = exp (-θ) and F (∞) = 1, then Eq. 2 is an improper survival function. Therefore, the cure fraction π can be defined as follows:
| (3) |
As θ→∞, π→0, whereas as θ→0, π→1 (i.e., 0≤π≤1).
It should be notified that the first derivative of S (t) with respect to t is:
Since 1-S (t) = F (t) and accordingly:
then ds/dt is an improper survival function and therefore, f (t) is an improper probability density function as well.
MATERIALS AND METHODS
Suppose that T is a random variable with probability density function f (t; θ), θ to be estimated and t1, t2, þ, tn is a random sample of size n. We are interesting in the likelihood function using the left censored data, because it gives us the possibility to compute the Maximum Likelihood Estimates (MLE) in order to fit a model for censored data. In order to analyze such data let αi and ci are indicators for the left censoring and cured, respectively where for the ith patient:
If αi = 1, then ci = 1 but if αi = 0, then ci is not observed and it can be either one or zero, assuming that censoring is independent of failure times.
In parametric maximum likelihood method the cumulative distribution function F (.) and the probability density function f (.) for the entire population are known. Thus, given αi and ci (i.e., the complete data are available), then the joint probability density function can be written as:
| (4) |
Consequently, the complete log likelihood function is:
| (5) |
where, fu (ti) and Su (ti) are the p.d.f and the survival function for the uncured patients, respectively.
This study considers the exponential distribution for Su (ti) and fu (ti) such that:
A datum ti is said to be left-censored if the event occurs at a time before a left bound but it is unknown when it happens, for example, when the date of starting a cancer clinical trial is assigned but for a cancer patient we don’t know when the patient has been died. However, in case of left censoring the survival function of the uncured patients becomes Su (t) = 1-e-λτ.
Therefore, the log-likelihood function becomes:
 | (6) |
The solutions of:
and:
are the desired estimates of θ and λ, where,
| (7) |
| (8) |
Solving Eq. 7 implies:
| (9) |
While Eq. 8 can be solved numerically since no explicit solution can be found.
As the cure status ci is not fully observed, the Expectation Maximization (EM) algorithm will employ.
Before implementing the EM algorithm, let’s define gi as the expected value of the ith patient to be uncured conditional on the current estimates of αi and the survival function of uncured patients, Su (ti) (Peng and Dear, 2000):
| (10) |
For censored individuals αi = 0 and hence the equation giving gi can be re-written as follows:
 |
For simplicity, let pi to be the probability of cured patients such that pi = E (1-ct) = 1-gi:
 |
THE EM ALGORITHM
EM algorithm is an iterative optimization method which alternates between performing an Expectation (E) step which computes the expectation of the log-likelihood function using the current estimate for the latent variables and Maximization (M) step which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step. The EM algorithm (and its faster variant ordered subset expectation maximization) is widely used in many different fields, especially in data clustering in machine learning, computer vision and medicine (Liu et al., 2006b; Safarinejadian et al., 2009).
However, suppose that the data vector is in the form of (ti, αi, ci). For i = 1…n, the observed data is the lifetime (ti) and censoring status (αi = 1) for i = 1…n and also the cure status (ci = 1), i = 1…m while the unobserved data is the cure status (ci) for i = (m+1)…n, ∀m<n.
In the presence of unobserved data (ci), only a function of the complete-data vector is observed. However, in the E-Step we find the expected value of the log likelihood function given by Eq. 6 as follows:
|
are the sufficient statistics for the parameters vector (λ, θ)T.
It follows that the log-likelihood based on complete data is linear in complete data sufficient statistics and then the E-step requires the computation of :
and
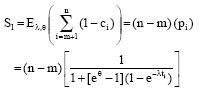 | (11) |
| (12) |
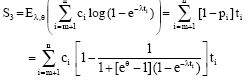 | (13) |
For the M-Step we can use the complete data maximum likelihood estimates of (λ, θ) given by Eq. 8 and 9 and then substituting the expectations derived in the E-step for the complete data sufficient statistics, such that on grounds of the sufficient statistics, the maximum likelihood equation of θ implies:
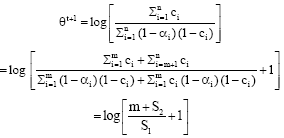 | (14) |
While Eq. 8 could be re-rewritten as follows:
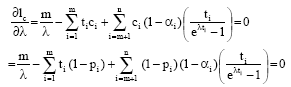 | (15) |
Thus, the E-step involves evaluating the sufficient statistics given by Eq. 11, 12 and 13 and also pi using some initial values for the parameters (θo, λo) followed by M-step involves substituting these values in Eq. 14 and solving Eq. 15 numerically with respect to λ. The convergence tth iteration is our desired estimates of θ and λ and eventually the desired cure fraction is exp (-θt+1).
CONCLUSION
We investigated the maximum likelihood estimation methodology for cure rate estimation based on the bounded cumulative hazard model when the exponential distribution can be used to represent the survival function of the uncured patients. A novel development of the EM algorithm was used to obtain maximum likelihood estimates when the data set has some left censoring observations.
REFERENCES
- Abu Bakar, M.R., K.A. Salah, N.A. Ibrahim and K. Haron, 2009. Bayesian approach for joint longitudinal and time-to-event data with survival fraction. Bull. Malays. Math. Sci. Soc., 32: 75-100.
Direct Link - Amiri, Z., K. Mohammad, M. Mahmoudi, H. Zeraati and A. Fotouhi, 2008. Assessment of gastric cancer survival: Using an artificial hierarchical neural network. Pak. J. Biol. Sci., 11: 1076-1084.
CrossRefPubMedDirect Link - Berkson, J. and R.P. Gage, 1952. Survival curves for cancer patients following treatments. J. Am. Stat. Assoc., 47: 501-515.
Direct Link - Boag, J.W., 1949. Maximum likelihood estimates of the proportion of patients cured by cancer therapy. J. R. Stat. Soc., 11: 15-44.
CrossRefDirect Link - Chen, M.H., J.G. Ibrahim and D. Sinha, 1999. A new Bayesian model for survival data with a surviving fraction. J. Am. Statist. Assoc., 94: 909-919.
Direct Link - Gamel, J.W., I.W. McLean and S.H. Rosenberg, 1990. Proportion cured and mean log survival time as functions of tumour size. Statist. Med., 9: 999-1006.
CrossRefPubMedDirect Link - Kuk, A.Y.C. and C.H. Chen, 1992. A mixture model combining logistic regression with proportional hazards regression. Biometrika, 79: 531-541.
CrossRefDirect Link - Liu, H., H. Zhong, T. Zhang and Z. Gong, 2006. A quasi-newton acceleration EM algorithm for OFDM systems channel estimation. Inf. Technol. J., 5: 749-752.
CrossRef - Peng, Y. and K.C. Carriere, 2002. An empirical comparison of parametric and semiparametric cure models. Biometrical. J., 44: 1002-1014.
CrossRefDirect Link - Peng, Y. and K.B.G. Dear, 2000. A nonparametric mixture model for cure rate estimation. Biometrics, 56: 237-243.
CrossRefDirect Link - Rodrigues, J., V.G. Cancho, M. de Castro and F. Louzada-Neto, 2009. On the unification of long-term survival models. Stat. Probab. Lett., 79: 753-759.
CrossRef - Safarinejadian, B., M.B. Menhaj and M. Karrari, 2009. Distributed data clustering using expectation maximization algorithm. J. Applied Sci., 9: 854-864.
CrossRefDirect Link - Savadi-Oskouei, D., H. Sadeghi-Bazargani, M. Hashemilar and T. DeAngelis, 2010. Symptomatologic versus neuroimaging predictors of in-hospital survival after intracerebral haemorrhage. Pak. J. Biol. Sci., 13: 443-447.
CrossRefDirect Link - Sy, J.P. and J.M.G. Taylor, 2000. Estimation in a Cox proportional hazard cure model. Biometrics, 56: 227-236.
CrossRefDirect Link - Uddin, M.T., A. Sen, M.S. Noor, M.N. Islam and Z.I. Chowdhury, 2006. An analytical approach on non-parametric estimation of cure rate based on uncensored data. J. Applied Sci., 6: 1258-1264.
CrossRefDirect Link - Taylor, J.M., 1995. Semi-parametric estimation in failure time mixture models. Biometrics, 51: 899-907.
PubMedDirect Link - Yakovlev, A.Y., B. Asselain, V.J. Bardou, A. Fourquet, T. Hoang, A. Rochefediere and A.D. Tsodikov, 1993. A Simple Stochastic Model of Tumor Recurrence and its Applications to Data on Pre-Menopausal Breast Cancer. In: Biometrics and Analysis Dormees Spatio - Temporal, Asselain, B., M. Boniface, C. Duby, C. Lopez, J.P. Masson and J. Tranchefort (Eds.). French Society of Biometrics, France, pp: 66-82.
- Yu, B. and Y. Peng, 2008. Mixture cure models for multivariate survival data. Comput. Stat. Data Anal., 52: 1524-1532.
CrossRef
Raed Falah Reply
Very interesting analysis and the implementation of the EM algorithm is so nice, but no real data or simulation has involved. We are interesting to see how we can apply the proposed procedure on some real data.