
L. Suanmali
Faculty of Science and Technology,Suan Dusit Rajabhat University, Dusit, Bangkok, 10300, Thailand
N. Salim
Faculty of Computer Science and Information Systems, Universiti Teknologi Malaysia, 81310 Skudai, Johor, Malaysia
M.S. Binwahlan
Faculty of Applied Sciences,Hadhramout University of Science and Technology, Seiyun, Hadhramout, Yemen
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 3 | Page No.: 166-173







ABSTRACT
Sentence extraction techniques are commonly used to produce extraction summaries. The goal of text summarization based on extraction approach is to identify the most important set of sentences for the overall understanding of a given document. One of the methods to obtain suitable sentences is to assign some numerical measure of a sentence for summary called sentence weighting and then select the best ones. In this study, we propose Semantic Role Labeling (SRL) approach to improve the quality of the summary created by the general statistic method. We calculate a couple of sentence semantic similarity based on the similarity of the pair of words using WordNet thesaurus to discover the word relationship between sentences. We perform text summarization based on General Statistic Method (GSM) and then combine it with the SRL method. We compare our results with the baseline summarizer and Microsoft Word 2007 summarizers. The results show that SRL-GSM and GSM give the best average precision, recall and f-measure for creation of summaries.
PDF Abstract XML References Citation
How to cite this article
L. Suanmali, N. Salim and M.S. Binwahlan, 2010. SRL-GSM: A Hybrid Approach based on Semantic Role Labeling and General Statistic
Method for Text Summarization. Journal of Applied Sciences, 10: 166-173.
DOI: 10.3923/jas.2010.166.173
URL: https://scialert.net/abstract/?doi=jas.2010.166.173
DOI: 10.3923/jas.2010.166.173
URL: https://scialert.net/abstract/?doi=jas.2010.166.173
INTRODUCTION
Text summarization has become an important and timely tool for helping and interpreting large volumes of text available in documents. One of a natural question to ask in summarization is what are the properties of text that should be represented or kept in a summary?.
Text summarization addresses both the problem of finding the most important subset of sentences in text which in some way represents its source text and the problem of generating coherent summaries. This process is significantly different from that of human based text summarization since human can capture and relate deep meanings and themes of text documents while automation of such a skill is very difficult to implement. The goal of text summarization is to present the most important information in a shorter version of the original text while keeping its main content and helps the user to quickly understand the large volume of information. Automatic text summarization researchers since Luhn (1958) are trying to solve or at least relieve that problem by proposing techniques for generating summaries. A number of researchers have proposed techniques for automatic text summarization which can be classified into two categories: extraction and abstraction. Extraction summary is a selection of sentences or phrases from the original text with the highest score and put it together to a new shorter text without changing the source text. Abstraction summary method uses linguistic methods to examine and interpret the text for generative of abstracts. Most of the current automated text summarization systems use extraction method to produce summary (Ko and Seo, 2008; Yulia et al., 2008; Suanmali et al., 2009; Aliruliyev, 2009).
Sentence extraction techniques are commonly used to produce extraction summaries. One of the methods to obtain suitable sentences is to assign some numerical measure of a sentence for the summary called sentence weighting and then select the best sentences to form document summary based on the compression rate. In the extraction method, compression rate is an important factor used to define the ratio between the length of the summary and the source text. As the compression rate increases, the summary will be larger, more insignificant content is contained. While the compression rate decreases the summary will be short and more information is lost. In fact, when the compression rate is 5-30% the quality of the summary is acceptable (Fattah and Ren, 2009; Yeh et al., 2005; Mani and Maybury, 1999; Kupiec et al., 1995).
In this study, we focus on sentence based extraction summarization. We propose the generic text summarization method which is based on statistic methods and sentence similarity using the Semantic Role Labeling (SRL). The propose of this study is to show that the summarization results not only depend on main content generated by statistic method or sentence relationship generated by similarity method, but also depend on both of them.
SUMMARIZATION APPROACHES
In early classic summarization system, the important summaries were created according to the most frequent words in the text (Luhn, 1958). Rath et al. (1961) proposed empirical evidences for difficulties inherent in the notion of ideal summary. Both studies used thematic features such as term frequency, thus they are characterized by surface-level approaches. In the early 1960s, new approaches called entity-level approaches appeared; the first approach of this kind used syntactic analysis (Mani and Maybury, 1999). The location features were used in (Edmundson, 1969), where key phrases are used dealt with three additional components: pragmatic words (cue words, i.e., words that have positive or negative effect on the respective sentence weight like significant or key idea); title and heading words and structural indicators (sentence location, where the sentences appearing in initial or final of text unit are more significant to include in the summary.
In statistical methods, summarization sentences (Kupiec et al., 1995) were described using a Bayesian classifier to compute the probability that a sentence in a source document should be included in a summary. Yulia et al. (2008) proposed a language- and domain-independent statistical-based method for single-document extraction summarization. They shown that maximal frequent sequences, as well as single words that are part of Bigrams repeated more than once in the text, are good terms to describe documents. Gong and Liu (2001) proposes generic text summarization methods that create text summaries by ranking and extracting sentences from the original documents using latent semantic analysis to select highly ranked sentences for summarization.
In context relation method, cohesive properties consist of relations between expressions of the text is used. Lexical chains method, which was introduced in Barzilay and Elhadad (1997) uses the WordNet thesaurus for determining cohesive relations between terms (i.e., repetition, synonymy, antonymy, hypernymy and holonymy) and composes the chains of related terms. Text summarization based on Latent Semantic Analysis (LSA) technique (Gong and Liu, 2001; Yeh et al., 2005; Steinberger and Karel, 2006) was proposed to identify semantically important sentences. The basic idea is that the aggregate of all the word contexts in which a given word does and does not appear provides mutual constraints that determine the similarity of meanings of words and sets of words to each other.
Extraction methods can be unsuccessful to capture the relations between concepts in a text if a sentence is extracted without the previous context of the summary. We investigate an advantage of SRL that can capture the relationship between sentences and adapt it into our text summarization.
DATA SET AND PREPROCESSING
We used test documents from DUC2002 collection provided by DUC (2002) to create automatic single document summarization. Each document in DUC2002 collection is supplied with a set of human-generation summaries provided by two different experts. While each expert was asked to generate summaries of different length, we use only generic 100-word variants.
Currently, input document are of plain text format. There are four main activities performed in this stage: sentence segmentation, tokenization, stop word removal and word stemming. Sentence segmentation is performed by boundary detection and separating source text into sentences. Tokenization is separating the input document into individual words. Next, in stop words removal, which are those words which rarely contribute to useful information in terms of document relevance and appear frequently in document but provide less meaning in identifying the important content of the document are removed. Those words including articles, prepositions, conjunctions and some other high-frequency words, such as a, an, the, in, and, I, etc. The last step for preprocessing is word stemming. Word stemming is the process of reducing inflected or derived words to their stem, base or root form. In this study, we performed words stemming using Porter’s stemming algorithm (Porter, 1980). For example, a stemming algorithm for English should stem the words: compute, computed, computer, computable and computation to its word stem, comput.
THE PROPOSED METHOD
In our proposed method as shown in Fig. 1, we extract the important sentences in source text based on both sentence semantic similarity and sentence features. We split the document into sentences and phrase each sentence into frame(s) using a semantic role parser. Then, we calculate sentence semantic similarities based on both semantic role labeling and word relation discovery using WordNet. We perform text summarization based on General Statistic Method (GSM) (Suanmali et al., 2009) and combine them with the proposed method.
Semantic Role Labeling (SRL) method
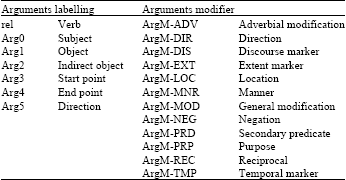
Identify semantic role: A semantic role is the underlying relationship that a participant has with the main verb in the clause (Payne, 1997) also known as semantic case, thematic role, theta role (generative grammar) and deep case (case grammar). The goal of SRL is to discover the predicate argument structure of each predicate in a given input sentence (Punyakanok et al., 2008). In SRL, given a sentence containing a target verb called a frame; we want to label the semantic arguments, or roles of that verb. We perform semantic role analysis on them and propose a method to calculate the semantic similarity between any pair of sentences. In semantic similarity method, we extracted semantic roles of each sentence based on PropBank semantic annotation (Palmer et al., 2005). Therefore, for each sentence, the number of frames generated by the parser equals to the number of verbs in the sentence. We have two groups of arguments: Argument labeling (Arg) and Argument Modifier (ArgM). Representation of arguments labeling and modifier are shown in Table 1.
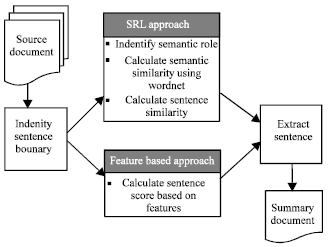 | |
| Fig. 1: | The proposed method architecture |
Calculate semantic similarity based on WordNet thesaurus: After performing the Semantic Role Labeling (SRL) semantic similarity of frame (verb or rel argument) is calculated based on the similarity of the pair of words using WordNet thesaurus to capture relationship between sentences. Semantic similarity is a confidence score that reflects the semantic relation between the meanings of two sentences. If pair words in rel labeling are identical or there exist semantic relations such as synonym, hypernym, hyponym, meronym and holonym, then the words are considered as related. WordNet (Fellbaum, 1998) was developed in Princeton University designed to establish the connections between four types of Parts of Speech (POS) such as noun, verb, adjective and adverb. In WordNet, each part of speech words are organized into taxonomies where each node is a set of synonyms or synset (synonyms set: groups of words that have the same meaning or would appear in the same place in the thesaurus) representing a specific meaning of a word in one sense. If a word has more than one sense, it will appear in multiple synsets at various locations in the taxonomy. WordNet defines relations between synsets and relations between word senses. Each synset has a single parent, forming a tree structure that allows the proximity of any two nodes to be found as a function of the subsumer. In Fig. 2 (Dao and Simpson, 2005), the subsumer of {car, auto…} and {truck} is {automotive, motor}, while the {automotive, motor}, is more specific than subsumer {wheeled vehicle}. On the other arguments, we calculated sentence similarity using cosine similarity of term frequency to capture word-matching as shown in Eq. 1. The frequency of term occurrences within a document has often been used for calculating the importance of the sentence.
Calculate sentence similarity: Sentence similarity measures play an increasingly important role in text-related research and text summarization.
| Table 1: | Representation of arguments labeling and modifier |
 | |
| Example sentence from DUC2002 data set. Sentence: Hurricane Gilbert swept toward the Dominican Republic Sunday. Label: |Arg0-Hurricane| Arg0-Gilbert| rel-swept| ArgM-DIR-toward| the| ArgM-DIR-Dominican| ArgM-DIR-Republic| ArgM-TMP- Sunday| | |
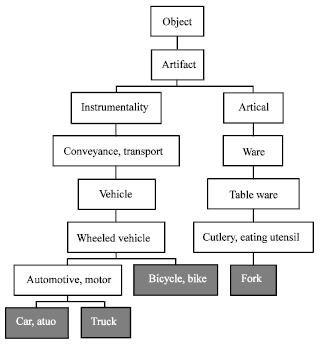 | |
| Fig. 2: | Example of hypernym taxonomy in WordNet |
A measure is simply a number within a range that represents how alike the objects being compared are to one another. An accurate sentence similarity measure would be a very powerful device that greatly enhances the computers interaction with humans. In this study, we calculate sentence similarity based on semantic roles labeling and their semantic similarity as shown in the following.
Sentence Si and Sj consist of frame (verbs) fa and fb, Ra = {r1, r2, …, rk} and Rb = {r1, r2, …, rk} regarded as the semantic role in fa and fb, {r1, r2, …, rk} is the set of K common semantic roles between fa and fb, Ta(rk) is the term set of fa in role rk and Tb(rk) be the term set of fb in role rk.
After removing stop words and word stemming, we compute the similarity between semantic roles fa(rk) and fb(rk) of each role, excluding rel role that will be calculated using cosine similarity.
| (1) |
where, wTat is term weight of term t of semantic role k of frame a of sentence i, wTbt is term weight of term t of semantic role k of frame b of sentence i.
For rel role similarity, we used Frame similarity (Fsim). The pair of verbs in rel roles were compared to find the semantic relations considered as related. We adapt WordNet library provided by Dao and Simpson (2005) with our method using the path length-based similarity measurement to obtain Fsim(fai,fbj) score between 0 and 1, which score near 1 means they are more related. In this study, we defined the threshold of related semantic similarity as 0.8. Then, the score of frame s of sentence t can be calculated as follows.
| (2) |
Finally, the semantic role similarity of sentence t can be calculated as follows:
| (3) |
where, N is the number of frame in the sentence.
General Statistic Method (GSM): The goal of text summarization based on extraction approach is sentence selection. One of the methods to extract the suitable sentences is to assign some numerical measure of a sentence for the summary which is called sentence weighting and then select the best ones. The first step in summarization by extraction is the identification of important features to be used to determine the weighting. General statistic method is used to produce the sentence weighting. After preprocessing, each sentence of the document is represented by an attribute vector of features. These features are attributes that attempt to represent the data used for their task. We focus on eight features for each sentence. Each feature is given a value between 0 and 1. There are seven features as follows: title feature, sentence length, term weight, sentence position, proper noun, thematic word and numerical data proposed by Suanmali et al. (2009).
S_F1: Title feature: The word in sentence that also occurs in title gives high score. This is determined by counting the number of matches between the content words in a sentence and the words in the title. We calculate the score for this feature which is the ratio of the number of words in the sentence that occur in the title over the number of words in title.
| (4) |
S_F2: Sentence length: This feature is useful to filter out short sentences such as datelines and author names commonly found in news articles. The short sentences are not expected to belong to the summary. We use the length of the sentence, which is the ratio of the number of words occurring in the sentence over the number of words occurring in the longest sentence of the document.
| (5) |
S_F3: Term weight: The frequency of term occurrences within a document has often been used for calculating the importance of sentence. The score of a sentence can be calculated as the sum of the score of words in the sentence. The score of important score wi of word i can be calculated by the traditional tf.idf method as follows (Wasson, 1998). We applied this method to tf.isf (Term frequency, Inverse sentence frequency).
| (6) |
where, tfi is the tern frequency of word i in the document, N is the total number of sentences and ni is number of sentences in which word i occurs. This feature can be calculated as follows:
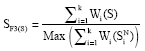 | (7) |
where, k is number of words in sentence.
S_F4: Sentence position: Whether it is the first 5 sentences in the paragraph, sentence position in text gives the importance of the sentences. This feature can involve several items such as the position of a sentence in the document, section and paragraph, etc., proposed the first sentence is highest ranking. The score for this feature: we consider the first 5 sentences in the paragraph. This feature score is calculated as the following Eq. 8.
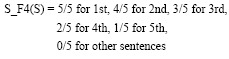 | (8) |
S_F5: Proper noun: The sentence that contains more proper nouns (name entity) is an important and it is most probably included in the document summary. The score for this feature is calculated as the ratio of the number of proper nouns that occur in sentence over the sentence length.
| (9) |
S_F6: Thematic word: The number of thematic word in sentence, this feature is important because terms that occur frequently in a document are probably related to topic. The number of thematic words indicates the words with maximum possible relativity. We used the top 10 most frequent content word for consideration as thematic. The score for this feature is calculated as the ratio of the number of thematic words that occur in the sentence over the maximum summary of thematic words in the sentence.
| (10) |
S_F7: Numerical data: The number of numerical data in sentence, sentence that contains numerical data is important and it is most probably included in the document summary. The score for this feature is calculated as the ratio of the number of numerical data that occur in sentence over the sentence length.
| (11) |
Finally, the score of each sentence can be calculated as shown in the following Eq. 12.
| (12) |
where, Score(S) is the score of the sentence S and S_Fk(S) is the score of the feature k
Combination of SRL and GSM method: In this method, we combine the sentence score generated by SRL method in the Eq. 3 with GSM method in the Eq. 12. It means, that we add the sentence score from SRL in the sentence score from GSM. The sentence score of this method is calculated as the Eq. 13.
| (13) |
where, Score(S) is the score of the sentence S, S_Fk(S) is the score of the feature k and SsimScore(S) is the score of semantic role similarity.
Extraction of sentences: In those three methods, each sentence of the document is represented by a sentence score. All document sentences are then ranked in descending order according to their scores. A set of highest score sentences are extracted as document summary based on the compression rate. Therefore, we extracted the appropriate number of sentences according to 20% compression rate. It has been proven that the extraction of 20% of sentences from the source document can be considered as informative as the full text of a document (Morris et al., 1992). Finally, the summary sentences are arranged in the original order.
RESULTS AND DISCUSSION
We use the ROUGE, a set of metrics called Recall-Oriented Understudy for Gisting Evaluation, evaluation toolkit (Lin, 2004) that has become standards of automatic evaluation of summaries. It compares the summaries generated by the program with the human-generated (gold standard) summaries (Yulia et al., 2008). For comparison, it uses n-gram statistics. Our evaluation was done using n-gram setting of ROUGE, which was found to have the highest correlation with human judgments at a confidence level of 95%. The results of this experiment are compared with two benchmarks: Microsoft Word 2007 Summarizer and baseline summarizer form DUC2002 data set using ROUGE-N (N = 1 and 2) and ROUGE-L, which those measures work well for single document summarization.
In the Table 2, we compare the average Precision (P), Recall (R) and F-MEASURE score (F) using ROUGE-1, ROUGE-2 and ROUGE-L among the five summarizers; semantic role labeling, general statistic method (GS-M), the proposed method, Microsoft Word 2007 Summarizer and baseline summarizer form DUC2002 data set with human judgments at a confidence level of 95%. The baseline is the first 100 words from the beginning of the document as determine by DUC 2002. The overall analysis for the results is concluded and depicted in Fig. 3-5 for ROUGE-1, ROUGE-2 and ROUGE-L evaluation measure.
The results of the experiment confirm that the sentence similarity based on semantic role labeling similarity has a significant improvement quality of text summarization.
| Table 2: | Performance evaluation compared between the proposed methods and other methods using ROUGE-(1, 2 and L) at the 95% confidence interval |
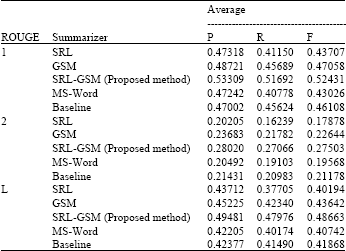 | |
It also shows that our proposed combined approach outperforms the text summarization approach by more than 50% of human judgment. It is claimed that the results of ROUGE-1 of all summarizers consistently correlates highly with human assessments and has high precision, recall and f-measure significance test with manual evaluation results.
In this study, we have presented the method based on general statistic method and a semantic role labeling aided sentence extraction summarizer that can be as informative as the full text of a document with good information coverage. A prototype has also been constructed to evaluate this automatic text summarization scheme by using some news articles collection provided by DUC2002 as input. We also use extracted important features for each sentence of the document represented by the vector of features consisting of the following elements: title feature, sentence length, term weight,sentence position, proper noun, thematic word, numerical data and sentence similarity based on semantic role labeling.
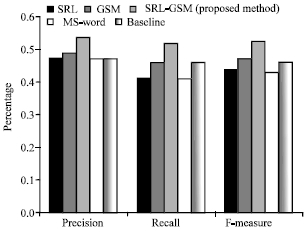 | |
| Fig. 3: | Performance evaluation compared between the proposed methods and other methods using ROUGE-1 |
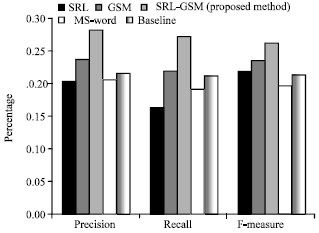 | |
| Fig. 4: | Performance evaluation compared between the proposed methods and other methods using ROUGE-2 |
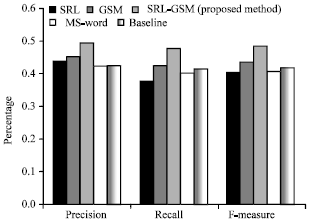 | |
| Fig. 5: | Performance evaluation compared between the proposed methods and other methods using ROUGE-L |
In this study, we address both the problem of finding the most important subset of sentences in text which in some way represents its source text and the problem of generating coherent summaries. General statistic method can extract sentences using various statistical features. This method can obtain the main content of the document and filter out the unimportant sentences such as datelines and author names commonly found in news articles but can fail to capture the relation between concepts in a text. If a sentence in summary is extracted without the previous context, the summary can become difficult to understand. Semantic role labeling can better capture the relationship between sentences but cannot depict the main content of the document. They require much memory and processor capacity because of additional linguistic knowledge and complex linguistic processing. Our proposed method combines the advantage of those methods to extract the important sentences in the source text.
We have done experiments with DUC2002 data set comparing our summarizer with Microsoft Word 2007 and baseline using precision, recall and f-measure built by ROUGE. The results show that the best average precision, recall and f-measure of summaries produced by our proposed method. In conclusion, we will extend the proposed method using combination of semantic role labeling and other learning methods.
ACKNOWLEDGMENTS
This project is sponsored partly by the Ministry of Science, Technology and Innovation under E-Science grant 01-01-06-SF0502, Malaysia. We would like to thank Suan Dusit Rajabhat University and Universiti Teknologi Malaysia for supporting us.
REFERENCES
- Barzilay, R. and M. Elhadad, 1997. Using lexical chains for text summarization. Proceedings of the Intelligent Scalable Text Summarization Workshop, August 1997, ACL, Madrid, Spain, pp: 10-17.
Direct Link - Edmundson, H.P., 1969. New methods in automatic extracting. J. Assoc. Comput. Machinery, 16: 264-285.
Direct Link - Fattah, M.A. and F. Ren, 2009. GA, MR, FFNN, PNN and GMM based models for automatic text summarization. Comput. Speech Language, 23: 126-144.
Direct Link - Gong, Y. and X. Liu, 2001. Generic text summarization using relevance measure and latent semantic analysis. Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, September 9-12, 2001, New Orleans, LA., USA., pp: 9-25.
CrossRef - Ko, Y. and J. Seo, 2008. An effective sentence-extraction technique using contextual information and statistical approaches for text summarization. Pattern Recognition Lett. Arch., 29: 1366-1371.
CrossRef - Kupiec, J., J. Pedersen and F. Chen, 1995. A trainable document summarizer. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, July 9-13, 1995, New York, USA., pp: 68-73.
Direct Link - Lin, C., 2004. Rouge: A package for automatic evaluation of summaries. Proceedings of the Workshop on Text Summarization Branches Out, July 25-26, 2004, Barcelona, Spain, pp: 74-81.
Direct Link - Luhn, H.P., 1958. The automatic creation of literature abstracts. IBM J. Res. Dev., 2: 159-165.
CrossRefDirect Link - Morris, G., G.M. Kasper and D.A. Adam, 1992. The effect and limitation of automated text condensing on reading comprehension performance. Inform. Syst. Res., 3: 17-35.
CrossRef - Palmer, M., P. Kingsbury and D. Gildea, 2005. The proposition bank: An annotated corpus of semantic roles. Computat. Linguistics, 31: 71-106.
CrossRef - Punyakanok, V., D. Roth and W. Yih, 2008. The importance of syntactic parsing and inference in semantic role labeling. Computat. Linguistics, 34: 257-287.
CrossRef - Aliruliyev, R.M., 2009. A new sentence similarity measure and sentence based extractive technique for automatic text summarization. Expert Syst. Appl. Int. J. Arch., 36: 7764-7772.
CrossRef - Rath, G.J., A. Resnick and T.R. Savage, 1961. The formation of abstracts by the selection of sentences. Am. Documentation, 12: 139-141.
CrossRef - Suanmali, L., N. Salim and M.S. Binwahlan, 2009. Fuzzy logic based method for improving text summarization. IJCSIS, 2: 65-70.
Direct Link - Wasson, M., 1998. Using leading text for news summaries: Evaluation results and implications for commercial summarization applications. Proceedings of the 17th International Conference on Computational Linguistics and 36th Annual Meeting of the ACL, (ICCLAM-ACL'98), Association for Computational Linguistics Morristown, NJ, USA., pp: 1364-1368.
- Yeh, J.Y., H.R. Ke, W.P. Yang and I.H. Meng, 2005. Text summarization using a trainable summarizer and latent semantic analysis. Inform. Process. Manage., 41: 75-95.
Direct Link