
A.R. Ebrahimipoor
Academic Center for Education, Culture and Research, Tarbiat Moallem Branch, No. 49, Mofatteh Avenue, Tehran, Iran
A. Alimohamadi
Department of GIS, Faculty of Geodesy and Geomatics Engineering, K.N. Toosi University of Technology, Tehran, Iran
A.A. Alesheikh
Department of GIS, Faculty of Geodesy and Geomatics Engineering, K.N. Toosi University of Technology, Tehran, Iran
H. Aghighi
Department of GIS, Faculty of Geodesy and Geomatics Engineering, K.N. Toosi University of Technology, Tehran, Iran
LiveDNA: Iranian Space Agencies, Tehran, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 23 | Page No.: 4137-4145







ABSTRACT
Linear and nonlinear optimization problems can be solved using classical methods. However, the solutions become inefficient as the number of variables and limitations increase. Routing pipelines requires optimum solutions in which technical, economical and environmental parameters are taken into consideration. In this study capabilities of GIS and Genetic Algorithm have been exercised to specify the best route for constructing a pipeline from the Panzdahe Khordad dam to city of Qom, Qom located in central part of Iran. Hence, all the required information have been gathered and transformed to a GIS database. The layers have then been weighted and integrated to represent the cost layers. In order to evaluate the algorithm, three routes have been compared, namely the existing route, the routes defined by using Genetic Algorithm and the least cost path approaches. Results of the research have shown that the Genetic Algorithm and least-cost routes were the same in most parts. The Genetic Algorithm route proved to be 20% cost efficient than the existing routes. The cost reduction is mainly attributed to the decrease in the pipeline length as well as the number of bridges. This study showed that the Genetic Algorithm can be used as a reliable solution in problems related to route optimization.
PDF Abstract XML References Citation
How to cite this article
A.R. Ebrahimipoor, A. Alimohamadi, A.A. Alesheikh and H. Aghighi, 2009. Routing of Water Pipeline Using GIS and Genetic Algorithm. Journal of Applied Sciences, 9: 4137-4145.
DOI: 10.3923/jas.2009.4137.4145
URL: https://scialert.net/abstract/?doi=jas.2009.4137.4145
DOI: 10.3923/jas.2009.4137.4145
URL: https://scialert.net/abstract/?doi=jas.2009.4137.4145
INTRODUCTION
In the modern age growth of cities will likewise increase the demand for water pipelines. Pipelines are by far the most economical, practical and safe option of fluid transport. Pipelines are the most efficient, cost effective and environmentally friendly means of fluid transport. An important problem in pipeline is the routing assignment (Ghose et al., 2006).
Careful planning of their route can save on cost, time and operating expenses, ensure longer operational life and help prevent environmental fallouts.
So, it is clear that more efficient methods for route design are required (Hasan et al., 2007; Iqbal et al., 2006; Jun et al., 2002).
Traditional methods of optimum routing in pipelines are mainly based on expensive and protracted methods. These methods are not precise and the role of all effective parameters in pipeline routings cannot be easily considered. Most technical, economical and environmental concerns are not observed in designed paths. Mean while remote sensing, GIS and intelligent methods are efficient tools for decision making and consultation for experts in pipeline design (Rudolph, 1994; Feldman et al., 1995).
The GIS and genetic algorithm are important techniques play an important role taking route (path) best of pipeline (Ghose et al., 2006; Yashoda et al., 2006).
The genetic algorithm (GA) that is a method of dynamic programming is a parallel, stochastic search algorithm which can be applied to a variety of problems (Vijayanand et al., 2000). it is one of the natural optimization methods, which produces many feasible optimal solutions they are better than the other linear programming tool (Mohamad and Khawlie, 2003; Harik et al., 1999).
Genetic algorithms are adaptive heuristic search methods that mimic evolution through Natural selection (Berger and Barkaoui, 2004).
Various investigations have been performed for using genetic algorithm in routing problems optimization (Sheu and Chuang, 2006).
Ahn and Ramakrishna (2002) proposed a genetic algorithmic approach to the shortest path (SP) routing problem.
Extensive researches have been performed in using GIS for designing best routs, railways, oil and gas and water pipelines, communication cables (Ghose et al., 2006; Iqbal et al., 2006; Yashoda et al., 2006).
A GIS optimal routing model is proposed to determine the minimum cost/distance efficient collection paths (Ghose et al., 2006).
The GIS, as a new technique for collection and analysis of spatial data, together with genetic algorithm as one of the most important evolutionary algorithms with features like flexibility, robustness and consistency in solving the complicated problems have important functions. So, combination of information from satellite images, object-oriented programming, available GIS techniques and genetic algorithm can lead to more accurate results in shorter time (Rudolph, 1994; Collischonn and Pilar, 2000).
Thus, selecting a suitable route to avoid existing obstacles not only reduces the risk of damaging existing utilities, but also minimizes the cost and duration required for construction. The GIS helps planners identify the spatial relationships between different data layers. In addition, GIS not only stores the spatial features and attributes, but can also be used as an analysis tool (Min-Yuan and Chang, 2001).
A GIS usually provides a number of tools for the analysis of spatial networks. It generally offers tools to find the shortest or minimum route (Derekenaris et al., 2001). The routing technique used for calculating shortest paths, cost reductions reported by the companies was typically between 10 and 20% (Tarantilis et al., 2004).
Feldman et al. (1995) proposed a prototype the least cost analysis for pipeline routing using remotely sensed data and GIS analysis. A small section of the proposed Caspian oil pipeline was chosen for developing of the prototype. The length and cost of the least cost pathway with the length and cost of straight line path were compared. Although the least cost pathway is longer, but it is 14% less expensive to construct than the straight line path.
In this study, we investigated the possibility of using Genetic Algorithms (GAs) and shortest path algorithm in Geographic Information System (GIS) to solve pipeline routing problem.
MATERIALS AND METHODS
Study area: The general route of the proposed pipeline is located between the Qom City and the Panzdahe Khordad dam, in Iran.
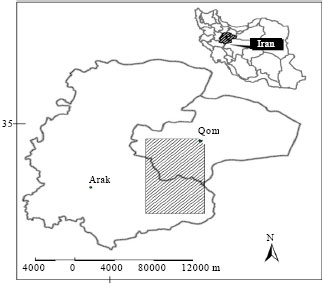 | |
| Fig. 1: | The study area |
The area is bounded by latitudinal 34°N to 34°44’ N and longitudinal 50° 25’ E to 51° E, as shown in Fig. 1. The physiographic of the area is mostly undulating with gently sloping pediments and valleys occurring at an altitude ranging from 920 to 1050 m above mean sea level (mol) (Fig. 1).
Data collection: The input data in the present case consisted:
| • | Topographic database: With a scale of 1: 25,000 for the entire study area and 1:2,000 for the corridor of the pipeline |
| • | Land cover map: Digital topographic map, ETM+ and IRS-PAN satellite images and aerial photos were interpreted in order to determine the land-use |
| • | Geology map database: With a scale of 1:100,000 |
| • | Digital Elevation Model (DEM): Derived from the contours on the 1/25000 map; this raster map had 10x10 m grids |
| • | Soil type map: This was a set of vector data in 1:100,000 scale. The data have been collected by field observations and digitization |
| • | National digital roads database: This database covered all vehicle accessible roads in Qom province |
| • | Additional data: Were collected by Global Positioning System (GPS) with the road and street geometry defined according to geometric accuracy of 5 m |
Methodology: Efficient routing of water pipeline using the least cost path or genetic algorithms depended on the Cost matrix (Fig. 2). The Cost matrix was produced by application of different analytical procedures on data layers including topography, geology, land use and environmental data (Collischonn and Pilar, 2000; Feldman et al., 1995) (Fig. 2).
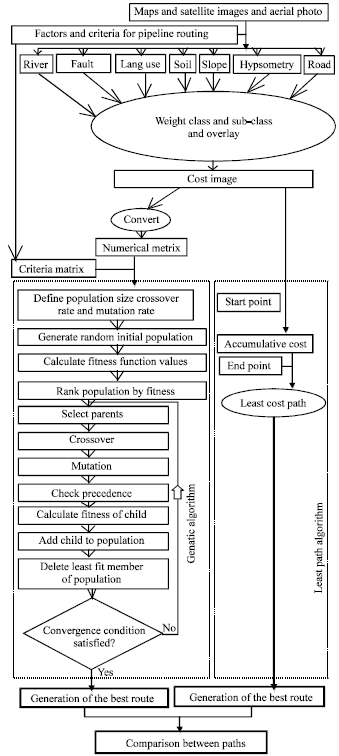 | |
| Fig. 2: | Flowchart of research methodology |
The analyses involved conversion of vector to raster model, weighting each of the information layers and classes and finally overlaying of information layers. Results of these analyses were the production of a raster or grid map in which the values of each cell represented the cost for the pipeline to cross that specific cell.
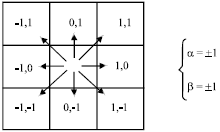 | |
| Fig. 3: | Eight directions of α and β movements |
The size of the cells depends on the required accuracy (Scott, 2005; Collischonn and Pilar, 2000; Feldman et al., 1995).
In this study, the grid cell size of 10*10 m was chosen and the total portrait dimension included a matrix with 6000*4000 dimensions regarding the scale of the data used, mainly including topography maps with 1:25000 scale, data fusion of ETM+ and IRS-PAN images and updated geological maps with field verified data.
Procedure for routing in GIS environment: For tracking, first the cost image of the study area and the start and end points of the path should be defined. Then the accumulated cost surface can be calculated. To calculate the accumulative cost surface, the cost surface is weighted. Accumulated cost is the cost for movement from one cell to another one and depends on distance, time and cost.
The General formula to calculate the collective costs is as Eq. 1:
(1) |
Where:
| accum_costij | : | Accumulative cost from the original cell towards cell ij |
| α and β | : | Values show the direction (Fig. 3) |
After preparing accumulated cost, the optimum path is determined from the point of destination towards the point of origin (Fig. 4). In each step of movement, the accumulative cost of the first neighbors (eight adjacent pixels) is considered and the pixel with the minimum collective cost is chosen as the movement direction Eq. 2:
(2) |
Where:
| MD | : | Direction |
| (Nnaccum_cost)ij | : | Accumulative cost of neighbor cells |
Routing by using the genetic algorithm: After preparing the cost image in the GIS environment, the genetic algorithm was designed, so that the variables were appropriately encoded and represented as chromosomes and an initial population was randomly generated. Then the fitness function was estimated for each chromosome of the initial population. Afterwards, an appropriate number of chromosome pairs were chosen according to their fitness levels (the chromosome with higher fitness takes part in the progeny generation more frequently) using the Roulette Wheel model. After this step, the new chromosomes were produced by the crossover operator. With the use of mutation on crossover function, new data were produced. Then, a new population for entry to the next stage of the algorithm among the new members and some members of the takes part in the progeny generation more frequently) using the Roulette Wheel model. After this step, the new chromosomes were produced by the crossover operator. With the use of mutation on crossover function, new data were produced. Then, a new population for entry to the next stage of the algorithm among the new members and some members of the previous population with the highest fitness were chosen. The genetic algorithm finds the optimum path from origin to the destination, based on evaluation of the chromosome fitness (Goldberg, 1989; Sheu and Chuang, 2006; Ha, 2000; Mohamad and Khawlie, 2003; Randaccio and Atzori, 2007).
In this study each available path within the initial population had a fitness value. Therefore, it was separated from other destinations by its fitness value. This meant that in each new generation, paths were produced with a better fitness values as compared with the former progeny population and by doing so, all the population members were evaluated. If the conditions for ending the algorithm were reached, then the algorithm was stopped.
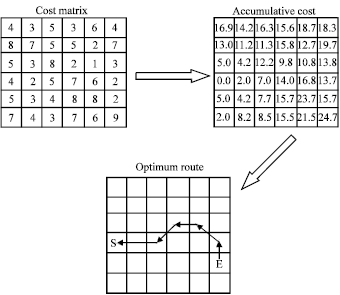 | |
| Fig. 4: | Steps in optimum path determination |
Otherwise, the existing population was used as initial population for the next stage. After determining the optimum paths, the results were fed into GIS environment.
RESULTS
Cost image is a basic layer in routing of water pipeline by using either the least-cost path or the genetic algorithms.
So different analytical procedures such as class weighting and combination of the layers were used in order to produce the cost image (Collischonn and Pilar, 2000; Ahn and Ramakrishna, 2002) (Fig. 5).
The procedure of this research is divided into two main parts (Fig. 4): Routing with the least cost path and genetic algorithms.
The least cost path algorithm: As shown in Fig. 6 the optimum path resulting from least cost path algorithm does not overlap with the constructed path. Comparison of the two paths indicates that the optimum path is less expensive than the constructed path (about 20%). This cost reduction is due to the reduced pipeline length and fewer intersections with rivers and roads.
Genetic algorithm
nitial population development process: The number of chromosomes as the initial population was defined in the first stage. The magnitude of the initial population was selected proportionate to the cost matrix dimensions.
 | |
| Fig. 5: | Cost image of the study area |
 | |
| Fig. 6: | Comparison of the existing (constructed) and optimum path determined by the least cost method |
The larger the cost matrix, the larger the initial population chosen for attaining the optimum answer or earlier conversion of objective function.
To determine the density of the initial population, the designed algorithm was examined on a limited matrix besides using the already performed investigations. As shown in Table 1, increasing the population density intensified the cost reduction process and increased the likelihood of the attainment of an optimum path.
Fitness function: The Fitness or absurdity of the answer was determined by considering the objective function. The more appropriate the answer, the greater the fitness values. To maximize the chance of continued existence for this answer, its survival probability was considered.
To overcome the problem of entrapment in local optimum and avoidance of distance from the absolute optimum, the quantity of crossover and mutation probability for chromosomes of the population with high fitness is considered to be low and for chromosomes with lower fitness is considered to be high. This way the algorithm will not move away from the absolute optimum while evading local optimum points. To solve this problem, the algorithm was designed so that the mutation and crossover values were functions of the fitness values of each chromosome (Eq. 3, 4).
(3) |
(4) |
| Table 1: | The trend in cost changes as function of initial population size |
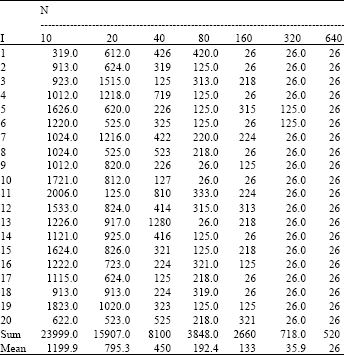 | |
| PM | : | 0.1, PC: 0.99 |
| Pc | : | Mutation probability |
| Pm | : | Mutation probability |
| Pc | : | Average population fitness degree |
| Pm | : | Maximum population fitness degree |
| Fa | : | The chromosome fitness degree upon which Pm and Pc values are affected |
| K1, K2 | : | Constants |
Crossover function: This is the main framework of the genetic algorithm and more important than all other stages of this algorithm (Goldberg, 1989; Vijayanand et al., 2000). In this research, the crossover function was implemented by using a function that its arguments are initial population, cost matrix and crossover probability. To determine the most appropriate range of crossover probability the written program was tested on a limited matrix along with the research results. As presented in Table 2, the results of the experiment show that the best crossover probability is in the range of 0.8-1.
Mutation operator: Mutation and its probability are very important in achieving the general optimal point in the genetic algorithm. (Goldberg, 1989; Vijayanand et al., 2000).
Mutation in the simplest form is the inadvertent change of one or a few genes from one chromosome with a mutation probability in (0<pm<1) range (Goldberg, 1989; Mitcheal, 1999; Berger and Barkaoui, 2004).
The algorithm in minimum local areas is not stopped by using the mutation operator.
| Table 2: | Trends of cost changes as a functions of crosser probability |
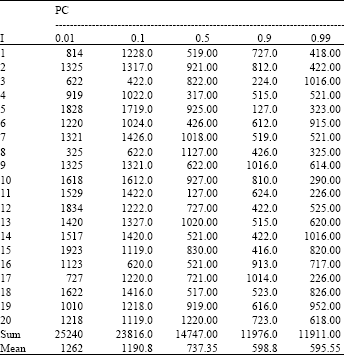 | |
| No.: 30, PM: 1 | |
| Table 3: | Trends of cost changes as a function of mutation probability |
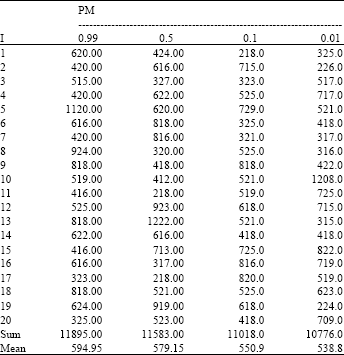 | |
| No.: 30, PC: 0.99 | |
It must be noted that the mutation probability must be low, otherwise good chromosomes produced by the crossover operator would be lost and the algorithm would fall into a stochastic search stage (Goldberg, 1989; Berger and Barkaoui, 2004).
To determine the most appropriate range of mutation probability, the written program was tested on a limited matrix besides using the research results. As presented in Table 3, the results of the experiment showed that the best crossover probability was in the range of 0.01-0.1.
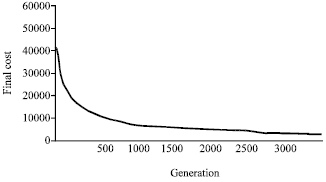 | |
| Fig. 7: | Change of cost as a function of generation |
Generation process: After full implementation of the algorithm, the cost of paths determined in each generation was sequenced in each generation from the first to the last generation, respectively. Then the cost of paths resulting from production of new generations took the form of a diagram with x axis relating to progeny generation and y axis showing the cost of paths determined in various generations. The resulting diagram clearly showed that the cost of the determined path in the initial stages of algorithm implementation for production of a number of new generations rapidly decreased, so that the cost of the determined path in generation 100 was half the cost in the first generation. The cost of the generation 3500 is half when compared to the generation 1700, producing nearly 1800 generations. This demonstrated that the conversion rate of the algorithm, as shown in Fig. 7, was much higher in the initial generations, so that the cost decrease process in initial generations was nearly 18 times more than the final generations.
The process of cost change clearly proved the effect of crossover and mutation functions and the choice of chromosomes with higher fitness in producing the next generation. Mutation, however, led to increase in costs of the designated path when compared with the previous generation. Considering the proper choice of objective function and better chromosomes, the general trend of cost change was decreased. It must be noted that increased cost of mutation in the X axis of the cost change trend diagram was not noticeable but could be obvious by assessing the cost change table.
Algorithm termination criterion: Two conditions were imposed as the algorithm ending criterion in this study:
| • | Difference between the costs of all assigned paths in a generation equals zero, in other words all the paths are overlaid |
| • | Result constancy for a specific number of progeny generations. In other resources the production of a specific number of new progenies is usually regarded as the algorithm termination criterion; however it seems that the criterion used to terminate the algorithm in this study is more appropriate than the other criteria |
Appropriateness of the algorithm termination condition is due to the fact that doubling the cost of all paths in a generation indicates fitness of all chromosomes of a progeny. As equality of chromosomes demands a generation with a large number of new progenies and introduction of better chromosomes from the parents’ generation to the progeny generation, this can be regarded as the condition for routing different paths for algorithm ending. Moreover, constancy of the answer for a large number of new progeny generations can indicate attaining of the algorithm to the optimum path regarding the mutation function on chromosomes.
DISCUSSION
Comparison of the existing path with optimum path: As shown in the final cost diagram (Fig. 8), total costs of the optimum path cost are nearly 20% lower than the constructed path. Most of the extra costs in the constructed path are due to the crossing roads and rivers, crossing regions with more slopes, crossing regions with various land uses which all result in higher costs and increased final pipe length.
Besides comparison of the constructed path and the path designated by using GIS; comparison of the two paths determined by using the genetic algorithm and GIS showed that the two paths completely overlap. In other words, the designed algorithm in this research could easily provide access to the designated goal.
Attaining such a goal demanded proper design of the genetic algorithm in accordance with the problem. The problem must be precisely identified at the algorithm design stage and care must be taken in determination of the algorithm parameters which mainly include the encoding method, assigning values or proper range of mutation and crossover probability and algorithm termination conditions. In this stage, the main problem was the algorithm run time, which could be solved with the help of further researches.
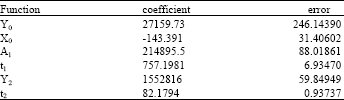
Fitness function: After algorithm execution and cost estimation in various generations, a function was fit to evaluate the trend in cost change on the data resulting from execution of the algorithm (Eq. 5). As shown in Fig. 9, the function has just about completely befitted the diagram emanating from the data.
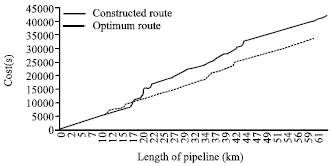 | |
| Fig. 8: | Final accumulative cost(s) |
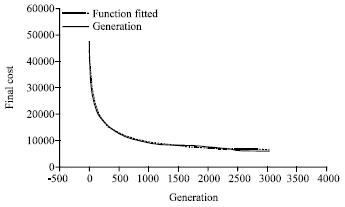 | |
| Fig. 9: | The fitted function |
So, it can be concluded that the cost decline obeys a specific trend and there is a logical and specific relationship between data in the two axes; so that the fitted function can be used to extrapolate the data and predict the path cost in future generations. Review of the function diagram reveals that the relationship between the generation of new progenies and the cost change has remained constant. In other words, after producing nearly 3500 new generations the cost variation trend has remained constant and production of new generations does not reduce the costs. Review of this matter will show that the algorithm termination condition is appropriate because the path cost has remained constant and has not changed in 100 terminal generations. In addition it can be concluded that the genetic algorithm has achieved the absolute optimum. Assessment of the befitted function and extrapolation of the function also confirmed this fact.
Model: ExpDecay2:
(5) |
Weighting:
Y : No weighting
 |
Advantages and disadvantages: Since GIS acts upon virtual data and geo-reference maps, there is a higher probability of achieving more genuine results.
Using GIS capabilities’ enables modeling and flight upon the studied region. This can give the designer a comprehensive view of the region before routing the path and project implementation.
The Capabilities of GIS in combining information layers enables the involvement of all parameters effective in routing. On the other hand the genetic algorithm determines the optimum path among the possible paths through inspiration from nature and the integration of the two can create powerful tools in helping designers and authorities.
As the results of the genetic algorithm implementation revealed, appropriate design of the genetic algorithm parameters indicated that the general optimum could be attained through proper design of parameters of the genetic algorithm including mutation probability, fitness function and mutation operators.
The method used in this research also has a number of disadvantages as follows: despite the easy problem- modeling and solutions of this method there are many matrix operations. Therefore, a high percentage of the memory is occupied by matrices and vectors required in this algorithm which can be an issue when there are software/hardware limitations. Using computers with higher capabilities can resolve this limitation to a great extent. Also using software tricks like saving some of the data in files and reusing these files during the program execution along with using subprograms for performing each part of the algorithm can help diminish this limitation. The program run time is longer than methods utilizing approximation formulas to calculate the objective function due to the execution of various chain programs. On the other hand, the program run time is directly proportional to the grid dimensions and increasing the grid dimensions nonlinearly increases the program run time. Since the program is run offline and increase in its run time will not be noticeable. Conversion is guaranteed in this method but a number of factors affect the conversion rate of the method. Experiments showed that the quality of mutation and crossover and their probabilities are effective factors in conversion rate. As shown in Fig. 1-4, initial population density is the most important parameter for attaining the optimum results.
REFERENCES
- Ahn, C.W. and R.S. Ramakrishna, 2002. A genetic algorithm for shortest path routing problem and the sizing of populations. IEEE Trans. Evolut. Comput., 6: 566-579.
CrossRefDirect Link - Collischonn, W. and J.V. Pilar, 2000. A direction dependent least cost path algorithm for roads and canals. Int. J. Geographical Inform. Sci., 14: 397-406.
Direct Link - Derekenaris, G., J. Garofalakis, C. Makris, J. Prentzas, S. Sioutas and A. Tsakalidis, 2001. Integrating GIS, GPS and GSM technologies for the effective management of ambulances. Comput. Environ. Urban Syst., 25: 267-278.
CrossRefDirect Link - Feldman, S.C., R.E. Pelletier, E. Walser, J.C. Smoot and D. Ahl, 1995. A prototype for pipeline routing using remotely sensed data and geographic information system analysis. Remote Sens. Environ., 53: 123-131.
Direct Link - Ghose, M.K., A.K. Dikshit and S.K. Sharma, 2006. A GIS based transportation model for solid waste disposal: A case study on Asansol municipality. Waste Manage., 26: 1287-1293.
CrossRefDirect Link - Harik, G., E. Cantu-Paz, D.E. Goldberg and B.L. Miller, 1999. The Gambler`s ruin problem, genetic algorithms and the sizing of populations. Evol. Comput., 7: 231-253.
CrossRefPubMedDirect Link - Hasan, B.S., M.A. Khamees and A.S.H. Mahmoud, 2007. A heuristic genetic algorithmfor the single source shortest path problem. Proceedings of the IEEE/ACS International Conference on Computer Systems and Applications, May 13-16, 2007, Amman, pp: 187-194.
CrossRef - Iqbal, M., F. Sattar and M. Nawaz, 2006. Planning a least cost gas pipeline route a GIS and SDSS integration approach. Proceedings of the International Conference on Advances in Space Technologies, September 2-3, 2006, Islamabad, Pakistan, pp: 126-130.
CrossRef - Berger, J. and M. Barkaoui, 2004. A parallel hybrid genetic algorithm for the vehicle routing problem with time windows. Comput. Operat. Res., 31: 2037-2053.
CrossRefDirect Link - Rudolph, G., 1994. Convergence analysis of canonical genetic algorithms. IEEE Trans. Neural Networks, 5: 96-101.
CrossRefDirect Link - Randaccio, L.S. and L. Atzori, 2007. Group multicast routing problem: A genetic algorithms based approach. Comput. Networks, 51: 3989-4004.
CrossRefDirect Link - Sheu, S.T. and Y.R. Chuang, 2006. A pipeline-based genetic algorithm accelerator for time-critical processes in real-time systems computers. IEEE Trans. Comput., 55: 1435-1448.
CrossRefDirect Link - Tarantilis, C.D., D. Diakoulaki and C.T. Kiranoudis, 2004. Combination of geographical information system and efficient routing algorithms for real life distribution operations. Eur. J. Operat. Res., 152: 437-453.
CrossRef - Vijayanand. C., M. Shiva-Kumar, K.R. Venugopal and P. Sreenivasa-Kumar, 2000. Converter placement in all-optical networks using genetic algorithms. Comput. Commun., 23: 1223-1234.
CrossRef