
H. Akhoondali
Control and Intelligent Processing Center of Excellence, Faculty of Engineering, School of Electrical and Computer Engineering, University of Tehran, Tehran, Iran
R.A. Zoroofi
Control and Intelligent Processing Center of Excellence, Faculty of Engineering, School of Electrical and Computer Engineering, University of Tehran, Tehran, Iran
G. Shirani
Departmentof Oral and Maxillofacial Surgery, Faculty of Dentistry Medical Science, University of Tehran, Tehran, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 11 | Page No.: 2031-2044







ABSTRACT
In this study, a fast automatic method is proposed for the segmentation and visualization of teeth in multi-slice CT-scan data of the head. The algorithm consists of five main procedures. In the first part, the mandible and maxilla are separated using maximum intensity projection in the y direction and a step like region separation algorithm. In the second part, the dental region is separated using maximum intensity projection in the z direction, thresholding and cropping. In the third part, the teeth are rapidly segmented using a region growing algorithm based on four thresholds which are used to distinguish between seed points, teeth and none teeth tissue. In the fourth part, the results are visualized using iso-surface extraction and surface and volume rendering. A semi-automatic method is also proposed for rapid metal artifact removal. Results on multiple datasets have shown the success of the algorithm with the dental region separation and segmentation procedure taking an average of only 2.4 sec to complete for each jaw making it at least tens of times faster than any previously proposed method.
PDF Abstract XML References Citation
How to cite this article
H. Akhoondali, R.A. Zoroofi and G. Shirani, 2009. Rapid Automatic Segmentation and Visualization of Teeth in CT-Scan Data. Journal of Applied Sciences, 9: 2031-2044.
DOI: 10.3923/jas.2009.2031.2044
URL: https://scialert.net/abstract/?doi=jas.2009.2031.2044
DOI: 10.3923/jas.2009.2031.2044
URL: https://scialert.net/abstract/?doi=jas.2009.2031.2044
INTRODUCTION
Many medical procedures need specific parts of the body to be visualized for better diagnosis and treatment. Most times, these parts and organs must first be segmented. If performed by hand, this will become a tedious and time consuming procedure. Many algorithms have been developed for the automatic segmentation of various tissues. In this regard automatic segmentation of teeth from the mandible and maxilla is a fairly new subject.
Accurate knowledge of the 3D shape of teeth and the position of the roots is very important in many maxillofacial surgical applications, endodontic procedures and treatment simulations (Cucchiara et al., 2004; Pongracz and Bardosi, 2006). The arrangement of teeth with respect to neighboring tissue can only be recognized by the 3D visualization of teeth and their surrounding tissue. For correct visualization of teeth, correct segmentation must be performed.
The enamel of the teeth being the hardest substance in the body can easily be separated using normal thresholding but this technique cannot be applied to other parts of the teeth like the roots because they have pixel values similar to neighboring none teeth tissues (Fig. 1).
 | |
| Fig. 1: | The result of using normal thresholding on teeth tissue. It is evident that using thresholding the teeth can not be correctly segmented. Threshold values used for the three images are (a) 2800, (b) 2000 and (c) 1200 |
To segment teeth for correct visualization volumetric data like CT-scan must be used. Currently most teeth segmentation techniques have been proposed for 2d radiology images of the teeth. For example Jain et al. (2003) used a semi-automatic method to find the contour of the teeth. Chen and Jain (2004) proposed a technique based on active contours. Li et al. (2006) used a variational level set technique in normal dental X-ray images. Fevens et al. (2006) used pathological modeling, PCA and SVM for tooth segmentation. Shah et al. (2006) have used active contours without edges. Said et al. 2006 have used mathematical morphology. In methods which use CT-scan data, algorithms have been proposed to segment the jaw or all jaw tissues as a whole and not the teeth only (Rueda et al., 2006). Other methods have been proposed which segment the teeth interactively and not automatically (Zhao et al., 2005; Liao et al., 2005). Procedures have also been proposed which segment models of the teeth obtained using 3D laser scanners (Kondo et al., 2004). Current procedures which completely segment the teeth from other tissues are based on the level set method. Liao et al. (2005) have used a semi-automatic hybrid technique which first uses the level set to extract a coarse whole tooth surface model. Hosntalab et al. (2008) have used a panoramic projection and variational level set technique for complete teeth segmentation, their technique is based on a method initially proposed by Keyhaninejad et al. (2006). Methods based on the level set method usually use the Hamilton-Jacobi formulas seen below:
(1) |
(2) |
Because of the need to perform numerous mathematical procedures the level set method is not considered a fast method. The current study has two main goals. (1) presenting a very fast segmentation method which is absent in earlier studies and (2) performing the segmentation in a fully automatic manner. In all, the algorithm has 5 main parts from beginning to end. In the first part, the mandible and maxilla are separated. In the second part, the dental region is found in all slices. In the third part, the segmentation is performed. In the fourth part, the results are visualized using surface and volume rendering. The last part is an optional semi-automatic metal artifact removal procedure.
MATERIALS AND METHODS
Here, the datasets, the compiler and libraries used for implementation, the computational environment and the proposed algorithm will be described.
Data sets: Each dataset had between 39-112 slices with a dimension of 512x512. All images had 16 bit signed grayscale pixels with 12 bits of usable data which included a range of between -1024 to 3071. Most datasets were obtained using a SIEMENS sensation 64 CT-scan device with FOV of 18x18 cm. Slice thicknesses were variable in different images but were usually between 0.6 and 0.8. To evaluate the effect of metal artifacts and image quality on the segmentation procedure different datasets were used which had different characteristics in terms of noise and quality. The number of teeth varied between the datasets.
Implementation: The algorithm was implemented using Microsoft Visual Studio 2008 sp1. The code was written in C++ language. Most functions needed for dicom image reading and processing were implemented using the Insight Segmentation and Registration Toolkit (Ibanez et al., 2005). The Visualization Toolkit (Schroeder et al., 2002) was used for iso-surface extraction, implementation of color and opacity transfer functions and also 3D visualizations.
Proposed algorithm: We now explain the proposed algorithm. There are 4 main steps: (1) separation of mandible and maxilla, (2) dental region separation, (3) teeth segmentation (4) metal artifact reduction and (5) visualization. The block diagram in Fig. 2 shows the proposed algorithm.
In CT-scan images there exists a certain amount of salt and pepper noise. To remove this noise originally a 3D median filter was used (Gonzales and Woods, 2001). This filter was very time consuming in terms of image processing. We decided to replace this filter with a faster filter that could de-noise present images efficiently. Present first candidate was a 3D mean filter with a size of 1 in all directions. Results showed that this filter was efficient enough while being faster than the median filter. We then changed this filter to a 2D mean filter. This filter was even faster than the previously mentioned filter without significantly affecting the final results. This was chosen as the final filter. Other than a good increase in processing speed another advantage that a mean filter has over a median filter is that it smoothes the edges and the resulting visualized images of the teeth will also become smoother.
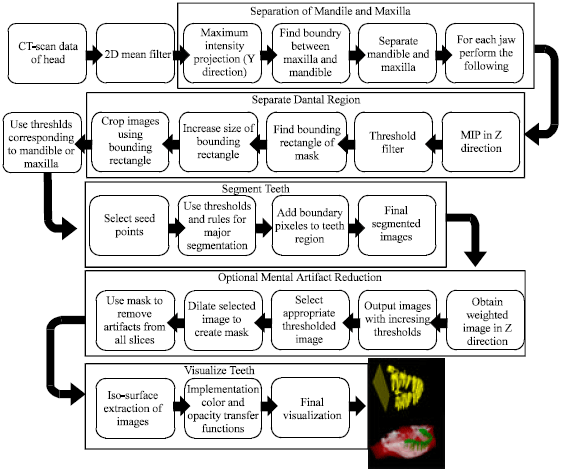 | |
| Fig. 2: | Block diagram of proposed algorithm |
Separation of mandible and maxilla: Since, in present algorithm the mandible and maxilla are each segmented separately but using a similar procedure we must first separate the mandible and maxilla from each other then segment the teeth in each of them separately. Usually, there is no single slice that can be used to completely separate the two jaws from each other because some of the slices will contain parts of the teeth in them which belong to both jaws. To perform the separation procedure a novel technique has been proposed. The technique is based on Maximum Intensity Projection (MIP) and a step like region separating algorithm. The first step in this procedure is to obtain a MIP of the dataset in the Y direction (Fig. 3a). As we can see by performing the MIP the region separating both jaws can be clearly seen. We must now find a way to separate these two from each other. To do this we first pass this image through a threshold filter to remove none bone tissue (Fig. 3b). Next in each row, we calculate the distance of the left edge of the image to the nearest bone pixel in that row. The row in which the mentioned distance is a maximum compared to the other rows a line is drawn from the left side of the image to the first bone pixel. From this pixel, a vertical line is drawn up till we reach the first bony pixel. On this vertical line, the same procedure is performed which was performed on the left side of the image. This procedure is continued until we can no longer move right or upwards (Fig. 3c). By seeing the result we can clearly see that the teeth in the mandible and maxilla have been separated from each other (Fig. 3d). Using this step like line the regions are then separated from each other. The distance between the first and last horizontal line is calculated and all pixels beneath the step like line are shifted downwards the amount of this distance in the volumetric data. The resulting gap is then filled with black pixels. The result is a volume with two jaws which have been separated with a single slice (Fig. 3e). This volume is then separated into two volumes with one containing the mandible and another containing the maxilla.
Dental region separation: To achieve higher processing speeds a dental region separation procedure has been used. Four sample slices from a dataset can be shown in Fig. 4a. To separate the dental region we get the Maximum Intensity Projection (MIP) of a jaw in the z direction (direction of the growth of teeth) (Fig. 4b).
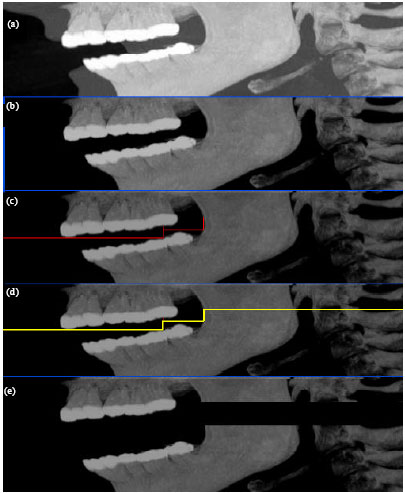 | |
| Fig. 3: | Procedure for separating mandible and maxilla. (a) MIP in y direction, (b) result of threshold filter to remove none bone tissues, (c) initial region separation lines, (d) final step like region separation line and (e) final separated jaws |
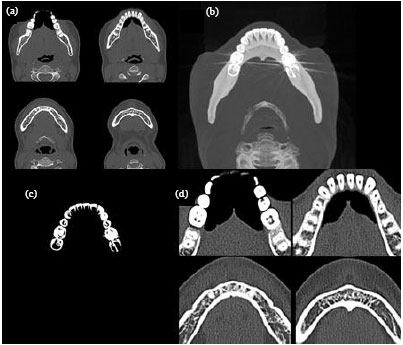 | |
| Fig. 4: | Procedure for separating the dental region. (a) sample images from a dataset, (b) MIP in z direction, (c) result of threshold filter and (d) sample cropped images using bounding rectangle of mask |
A threshold filter is then used to remove all pixels with values lower than the enamel, being the hardest substance in the body (Fig. 4c). What remains of the image is the mask of the teeth. The bounding rectangle of the mask of the teeth is then used to crop all the images in the dataset (Fig. 4d).
Experiments on this algorithm showed that it had 2 weak points (which occurred in some datasets). To show these weak points we will use Fig. 5 which is the MIP of one of this datasets. This data set has been used because it suffers from both problems.
The first problem occurs when there are teeth in a dataset which have their crowns missing (partially or completely). If these teeth are the farthest teeth from the mid-line of the jaw they will not be included in the dental region. The reason for this is that in these datasets the result of the threshold filter (Fig. 5b) will not contain any part of these teeth in it unless a small part of the enamel can still be seen in the thresholded image. The red lines in Fig. 5 show the right side edge of the dental region that will incorrectly be selected. The second problem occurs because all present datasets are obtained open-bite i.e., the patient’s mouth is kept open while the CT-scan device is scanning the head. With the mouth open the teeth will have a slight angle with respect to the tube the head is in during imaging. Depending on this angle the roots of the teeth may show up in a place lower than the crown in the MIP image for some datasets. This problem usually occurs in the mandible because the maxilla usually makes a 90° angle with the CT-scan tube and to open the mouth the mandible must be moved thus it creates an angle which creates these errors. It must be noted that this error does not always occur and we have shown a severe case in Fig. 5. The red arrow in Fig. 5a points to the projection of one of the roots. Since, the roots of the teeth are softer than the enamel passing such an image through a threshold filter that removes all pixels not associated with enamel will result in a mask which will not include the roots of the teeth in the slices which have the roots in them. The yellow line shows the bottom side of the dental region that must be selected and the blue line shows the bottom side that was selected which has excluded the root of one the teeth.
To solve the above mentioned problems we have done 2 things: (a) we slightly decreased the threshold of the threshold filter and (b) a margin of error has been added to all sides of the bounding rectangle. The margin of error from the top is small because we usually have no problem at the top of the region. The one on the left and right sides is a little longer than the diameter of a typical tooth and the one on the bottom is a little longer than the length of the roots as viewed in a MIP image. The result of the new technique can be shown in Fig. 6.
In datasets that the teeth are complete the dental region separation procedure reduces the size of processing region to about one sixth or fifth. In datasets in which the patient has teeth missing the processed region is reduced much more than this for instance in one of this datasets the processing region was reduced by 36 times!
Segmentation: Once the dental region has been separated the segmentation procedure will be started. The segmentation process is basically a region growing procedure performed in 3 steps involving 4 thresholds (TH1-TH4) which are constant for all datasets. All thresholds have been obtained by a thorough examination of many different teeth images and their values are based on the anatomical features of the teeth.
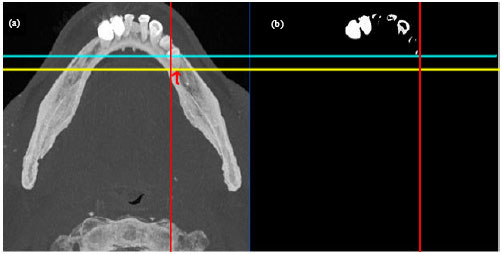 | |
| Fig. 5: | (a) result of MIP of one of the datasets and (b) result of threshold filter on mip image. The yellow line shows the bottom edge of the region that should have been selected and the blue line shows the region that has been wrongly selected. The red line shows the incorrectly selected right side of the image |
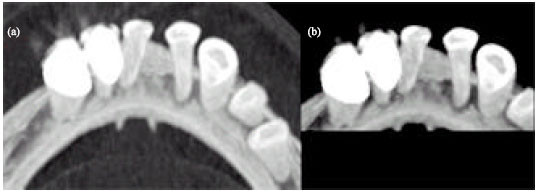 | |
| Fig. 6: | (a) region selected using modified algorithm and (b) region selected using initial algorithm, one of the teeth and half of another have been missed |
They have been fine tuned using results obtained from multiple datasets. We will now explain why we used these thresholds. The fine tuning procedure will be explained after the segmentation procedure.
Th1: This threshold is used to locate the seed points needed for the region growing procedure. As we know the enamel of the teeth is the hardest material in the body and it is only located in teeth. With this point in mind a threshold can be easily found in which all pixels having a value above it will be part of the enamel and consequently part of the teeth. We call this threshold TH1. In cases which we have metal artifacts these artifacts will also be chosen as seed points but since these metal artifacts are themselves either in the teeth or connected to them they will not pose a problem for us.
Th2: The initial value of this threshold is selected slightly above the pixel value of bones which the roots of the teeth reside in. This is a stopping threshold which stops the teeth region from spreading into the bones. This is the most important threshold.
Th3: In the beginning of the algorithm a mean filter was used for smoothing and noise reduction in all images. The result of this filter caused a reduction in the value of pixels which are located in boundary locations in which their neighbors have lower values than themselves. If these pixels are part of the teeth they would not be included as teeth because of their decreased value. In the final part of segmentation pixels above this threshold that have a teeth neighbor but themselves have not been segmented as teeth will be added to the tooth region. The initial value of this threshold was found by studying the pixel values of the teeth in boundary locations after the mean filter.
Th4: This threshold is chosen so that all pixels above it are bony tissue and all pixels below it are non-bony tissue. Only pixels which have a value higher than Th4 will be processed in the segmentation procedure. This threshold is used to achieve higher processing speed and to remove all none bone tissue.
It must be noted that because of the difference in the anatomical features of the mandible and maxilla we will have different TH2’s for them.
The following condition exists between the thresholds: Th1>Th2>Th3>Th4.
There are two reasons for separately segmenting the mandible and maxilla. The first one as stated is that we have different TH2’s for them. But the second and most important one is that in the segmentation procedure we start from the seed points (which are located in the crown) and move towards the roots to grow the tooth region. So, in the mandible we are moving upwards and in the maxilla we are moving downwards. Because we are segmenting the teeth in each jaw in opposite directions we must first take them apart and then perform the segmentation procedure on each of them separately.
Segmentation steps: There are three main steps. They aim of the first step is to select the seed points also an initial region growing is performed. In the second step most of the region growing (segmentation) procedure is performed. In the third step boundary regions degraded due to the mean filter are also added to the teeth region.
Step 1: Here, we choose the initial seed points. All pixels higher than Th1 are marked as the seed points. As already mentioned all these pixels will only be located in the enamel of the teeth. Once the seed points have been a minor region growing procedure is also performed. All pixels which fulfill the following conditions are added to the region: (a) their value is higher than Th4 (i.e., they are bony tissue) and (b) they are in a neighborhood of 1 (in 3D space) from the seed points. In this step most of the enamel will be segmented.
Step 2: In this part most of the teeth will be added to our region. The only remaining parts will be some pixels in the outer and inner boundaries of the teeth whose values have been lowered by the mean filter. For pixels to be included in the tooth region in this step they must fulfill the following conditions: (a) their value is higher than Th4 (i.e., they are bony tissue) and (b) they have an already segmented neighbor in the neighborhood of 1 in all directions whose value is above Th2. If we are processing the maxilla the z neighborhood is only regarded from the bottom and in the mandible only the z neighborhood from the top is processed. In other words the z neighborhood is one sided and depends on the structure (mandible or maxilla) we are processing. The reason, as we stated before is that since the seed points are in the crown we grow our region from the crown towards the roots and to do this it suffices to use the data of the last slice processed and there is no need to use the information in the next slice. It must be noted that this step is repeated on the dataset until one of the 2 following conditions is met: (a) the number of pixels added to the region in the last iteration were less than 50 and (b) the dataset has been iterated 10 times. Although in most datasets the process stopped after 3-4 iterations the maximum number of iterations has been selected as 10 as a precaution even though this condition will never occur for nearly all datasets. The reason of our precaution is situations in which the teeth region might spread in the mandibular or maxilla bone. Simulated results showed that in cases which this event occurs the iteration will continue for tens of times adding false positive pixels (pixels wrongly segmented as teeth) to the region. To prevent these pixels to be added to the region we limit the number of iterations thus limiting the mean error rate in cases which such situations might occur.
Step 3: Because of the mean filter we used at the beginning of the dental region separation procedure some of the pixels which were on the boundary of the teeth experienced a reduction in value. This value reduction prevented these pixels from being included in the tooth region. Also there are always some pixels which are part of the tooth but naturally have a lower value than expected. Pixels which met the following conditions have been segmented in this step: (a) their value is higher than Th4 (i.e., they are bony tissue) and (b) they are in a neighborhood of 1 (in 3D space) from pixels already segmented as teeth and they themselves have a intensity value higher than Th3.
The 2D results for 4 datasets can be shown in Fig. 7. The visualized 3D results will be shown after the visualization procedure.
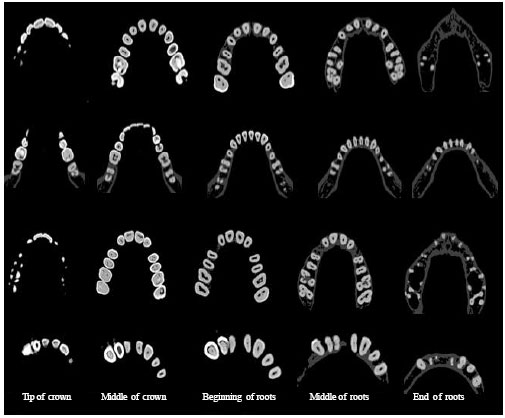 | |
| Fig. 7: | 2D results of the segmentation procedure. Each row has 5 slices of a dataset from different locations. None teeth tissue has been shown using gray color |
Threshold fine tuning procedure: At the beginning of the segmentation section we explained why we chose Th1-Th4. The initial values of these thresholds are based on the anatomical knowledge of the teeth. Except for Th2 the final value of the other thresholds is easily found. As we said Th1 is selected just below the value of the enamel. The value of Th3 is found by observing the boundary pixels of teeth after the mean filter and Th4 is chosen so that none bone tissue will be removed. A slight error in these thresholds is tolerable and is not critical in the segmentation procedure since in the worst possible case they will only create a minor number of false positive pixels. But Th2 is different and very critical in the segmentation procedure because if it has a value too low we will get many false positive pixels and if we choose a value too high we will have many false negative pixels (tooth pixels which are not selected as teeth). The fine tuning procedure is performed separately for the mandible and maxilla datasets.
It must be clarified that for an acceptable segmentation in each dataset Th2 has a range with the following relationship: BLi<Th2i <BUi. In which Th2i is the acceptable threshold for dataset i, BLi is the lowest acceptable value for Th2i to have a successful segmentation in dataset i and BUi is the highest acceptable value for Th2i to have a successful segmentation in dataset i. If Th2i is selected lower than BL unacceptable amounts of false positive pixels will be added to the teeth region and if Th2i is higher than BUi many teeth pixels will be left out of the segmentation procedure. If the region between BLi and BUi is called Ri we can find a Global Region (GR) which has the following property:
GR = R1 ∩ R2 ∩ R3 ∩ … ∩ Rn |
The bottom boundary for this region is chosen as the final global value for Th2.
The fine tuning procedure is as following: We implemented the complete algorithm using the C programming language. Then for a number of our datasets which were selected for the fine tuning procedure we performed the following: we chose a very high value for Th2 so no segmentation would take place in step 2. We then lowered its value until the teeth were segmented. We kept on lowering Th2 until we reached an acceptable number of false positive pixels. The value of Th2 was then recorded (BLi). We then moved to the next data set. Since, we will use the bottom boundary of the final global region as Th2 there is no need to find BUi.
The final threshold used for Th2 was the maximum value of BUi’s recorded for the datasets. This threshold was then used as the global threshold for the datasets. Most of the datasets used in the fine tuning procedure were the ones which had higher quality images and lower amounts of metal artifact noise. It must be noted that since the final value of Th2 was different from Th2 obtained for each dataset, all present datasets were used in the final assessing procedure. The global value of Th2 is considered appropriate because correct results were obtained from datasets which were not used in the fine tuning procedure.
Visualization: Once present images are segmented they need to be visualized. Here, 2 kinds of images will be produced. The first image only shows the teeth. This is visualized using surface rendering. The second image is a volume rendered image showing the teeth and other bones with different opacities. Except for the optional metal artifact reduction section which is semi-automatic all other parts of the segmentation and visualization are automatic.
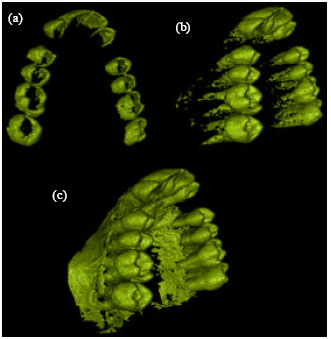
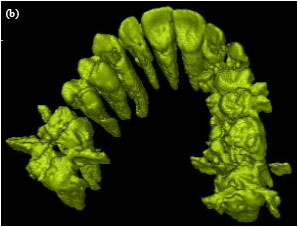
For visualization an initial iso-surface extraction procedure is performed. The surfaces of the segmented teeth are extracted from the volume. These have been labeled as teeth in the segmentation procedure. To show the teeth isolated from other tissue we simply render the extracted surface of the teeth. For visualizing the teeth with the bones volume rendering is used. In this part the teeth are shown with complete opacity and bones are shown with a low opacity and different color. By doing this we can visualize the position of the roots with respect to the bones they reside in. The final result for some of this datasets can be shown in Fig. 8.
Metal artifact reduction: Here, we will introduce a novel post processing segmentation procedure. This process can only be used in places where the metal artifacts have introduced false positive pixels. In pixels where the metal artifact has degraded the image in a way that the algorithm has produced true negative results this process cannot be applied.
We will first explain the knowledge which this method is based on then we will explain each block. As we know the teeth are mostly elongated parallel with the Z axis with a small cross section in the X-Y plane. In contrary, teeth metal artifacts are spread as lines in the X-Y plane which intersect in nearly one point which is the source of the metal which has caused the artifact and they only have a short length in Z. The length in Z is equal to the length of the artifact in Z which is small compared to the length of the teeth. This can be shown in Fig. 9.
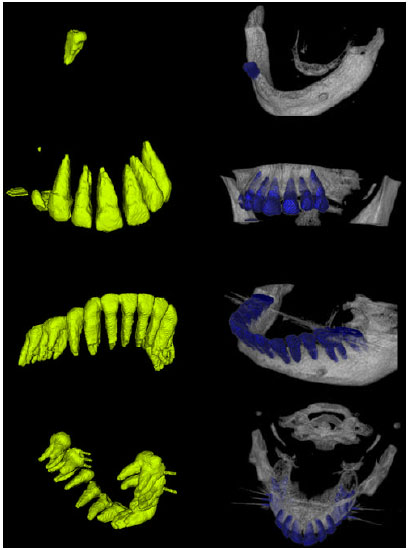 | |
| Fig. 8: | Visualized results of 4 jaws. Images in left column are surface rendered teeth and the images in the right column are the teeth shown with the bones using volume rendering |
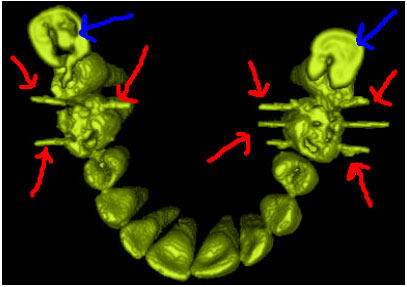 | |
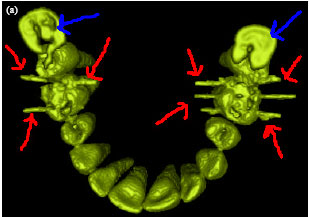
| Fig. 9: | Red arrows show metal artifacts in segmented image of maxilla. The two small parts shown with blue arrows are parts of teeth from opposite jaw. They have been added to show the effect of the metal artifact reduction algorithm on artifacts which lie directly above or beneath the teeth |
Using these near opposite characteristics of teeth and artifacts we can implement a method to clear out the metal artifacts. We first find a weighted image of the segmented teeth in the Z direction. What we mean by a weighted image is an image in which the value of each pixel is equal to the total number of slices in which the corresponding pixel is segmented as being part of the teeth. The reason the z direction is used is that the teeth are elongated in the z direction and the artifacts are not elongated in this direction. The weighted image is a mask of the teeth where the pixels corresponding to the artifacts are shown darker. Passing this mask through a threshold filter we will get a secondary mask which does not have pixels corresponding to artifacts in it. This mask can be used to remove artifacts in all slices. Figure 10 shows the weighted image.
As it can be seen the place where the artifacts were are darker than the teeth. Now that we have the weighted image we have to pass this image through a threshold filter with multiple threshold values. The results are then viewed and the image which has the lowest threshold value which does not have metal artifacts in it is selected. This image will be used by the system as the metal artifact reduction mask. The output images of this filter, for threshold values between 3 and 8 can be shown in Fig. 11. The image in Fig. 11e has been selected as the mask because the metal artifacts have been removed in it. The value of the threshold used was 8. Values higher than 8 can also be used but they will cause more of the teeth pixels to be removed.
Because the threshold filter has also removed some of the pixels which might correspond to the teeth we slightly dilate the selected mask to compensate for the useful pixels that have been removed. The dilated result of the selected mask can be shown in Fig. 12.
Now, we use the dilated image as a final mask to reduce metal artifacts from all slices. To perform this task all pixels in all slices of the segmented teeth which lie outside the mask area are removed.
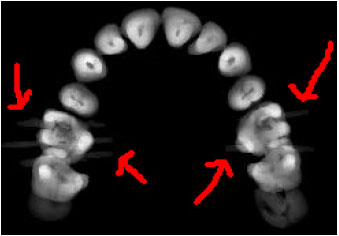 | |
| Fig. 10: | Weighted image of segmented dataset with artifacts. Red arrows point to pixels corresponding to metal artifacts |
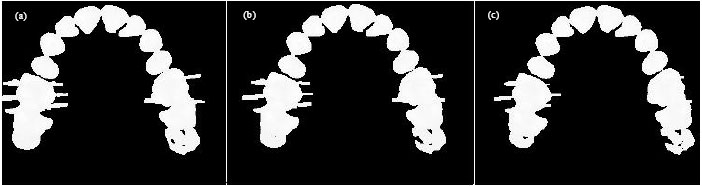 | |
| Fig. 11: | (a- f) The result of passing the initial mask through a threshold filter with thresholds 3-8 |

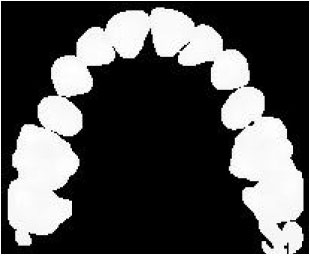 | |
| Fig. 12: | Final mask |
 | |
| Fig. 13: | (a) Before and (b) after metal artifact reduction |
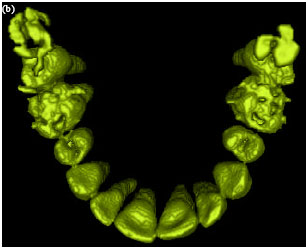
The result of the metal artifact reduction procedure can be shown in Fig. 13.
RESULTS AND DISCUSSION
Results were evaluated in terms of sensitivity, specificity, precision, accuracy and relative overlapping with the following definitions:
| Sensitivity | : | True | positive/(True | positive+False negative) | |
| Specificity | : | True | negative/(True | negative+False positive) | |
| Precision | : | True | positive/(True | positive+False positive) | |
| Accuracy | : | True | positive+True | negative)/Total samples | |
| Relative overlapping | : | True | positive/(True | positive+ False negative+False positive) |
In which:
| True positive | : | No. of pixels correctly segmented as teeth tissues |
| False positive | : | No. of pixels incorrectly recognized as teeth tissues due to the failure of the technique |
| False negative | : | No. of pixels of missed teeth tissues |
| True negative | : | No. of pixels correctly separated as non-teeth tissues |
To calculate the accuracy the total samples were calculated after image cropping (dental region separation). Teeth were segmented by hand to be used as gold standard. These were then compared with the results obtained by the algorithm for evaluation.
Table 1 shows the results obtained for the datasets. The average relative overlapping is 86% and the average segmentation time is 2.46 sec which is extremely fast.
The relative overlapping index was used to assess a segmentation failure or success. A value above 0.85 was regarded as success and a value below it a failure. In the 18 jaws processed we had 4 failures. All failures occurred because of high metal artifacts. Of the 4 failures 3 of them also had low quality images. As we will show in the discussion section using the metal artifact algorithm we can easily convert some of the failed segmentation into successful ones.
In datasets with lower amounts of metal artifacts or higher quality images the relative overlapping index was above 90% with datasets which had high quality images and little or no artifacts this was above 95%.
An overall analysis of the results showed that most false negative and false positive pixels were the result of metal artifacts and/or low quality images. What we mean by low quality images is images which have been digitally zoomed for better viewing. In these images the overall pixel intensity values are slightly lower than normal images thus some of these pixels will have final values lower than Th2 and will be missed in the segmentation process. Metal artifacts can have three kinds of effects which result in failures.
| Table 1: | Segmentation results |
 | |
 | |
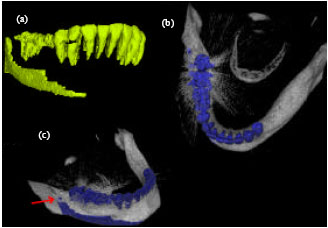
| Fig. 14: | (a) Failed segmentation due to an increase in false positive pixels and (b) result of metal artifact reduction algorithm which turned the failure into a success |
The first effect causes false positive pixels because of a great increase in pixel intensity values adjacent to the metal source. For instance one of the failed segmentation can be shown in Fig. 14. In this dataset although the teeth pixels were separated correctly but the metal artifacts caused an overall error that created a failure.
 | |
| Fig. 15: | The effect of metal artifacts in preventing pixels from being added to the tooth region. Blue arrows point to the source of artifacts which are two metal implants. Red arrow points to roots which should have been added to the tooth region |
Although this cannot really be called a failure, because even if a Level Set technique were used these pixels would still have been incorrectly segmented, unless the artifacts were removed. By using the metal artifact reduction algorithm these failed segmentation are easily converted to a success. The complete metal artifact reduction procedure only took 859 msec for this dataset.
The second effect metal artifacts have is in places where the intensity value of pixels near the metal source are highly reduced. In these cases since the algorithm starts from the tip of the crown and moves towards the roots if a tooth has decreased pixel value in a single slice the parts of the tooth after that slice will no longer be added to the region. This can be shown in Fig. 15.
 | |
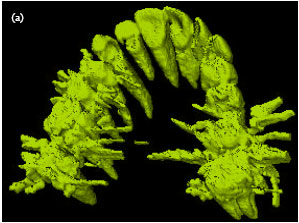
| Fig. 16: | (a) Isolated teeth in a failed dataset and (b,c) teeth shown with bones from two different views. Red arrow points to a seed point created because of the high amounts of metal artifacts |
The two metal implants (shown with blue arrows) caused one and a half of the roots to be missed in the segmentation procedure (red arrow).
The third and most devastating effect that metal artifacts can have sometimes occurs in extremely noisy images (metal artifact noise). In these cases the metal artifacts can increase the value of none-tooth bones so much that they surpass the seed point threshold (Th1). These pixels will then be selected as thresholds and the bone will wrongly be segmented as teeth. In Fig. 16 we can see such a case. The incorrect seed point caused the mandible to be segmented instead of teeth. Also the metal artifacts had degraded a few slices of two of the teeth preventing the roots of those teeth from being further segmented. Because the mandible was being segmented we had the highest processing time for this dataset (about 5 sec).
The average segmenting time was 2.46 sec (on a 2 GHz processor). This is very fast in terms of image processing. In personal communications Keyhaninejad et al. (2006) have stated that their algorithm executed in 15-20 min on a processor running at 3 GHz (which is an average of 1150 sec). Hosntalab et al. (2008) have also stated a similar time. Since, both of their algorithms were implemented using matlab and were executed on computers with a higher processor speed than ours we cannot know the real amount of increase of speed in this algorithm. Using the current mentioned values we can see that present algorithm performs more than 450 times faster than these algorithms. The main reason for this tremendous increase in speed is the fact that they have used level set techniques which are much slower than intensity based segmentation.
Hosntalab et al. (2008) have also proposed a metal artifact reduction procedure which is based on a butterworth filter. This will also perform very slowly because of the need to take the images into the frequency domain and back again. As stated before this metal artifact reduction algorithm only took 859 msec to execute for the datset in Fig. 14 which is very fast.
We were not able to compare the segmentation results of this algorithm qualitatively with these studies because they used different indexes to evaluate their algorithm.
CONCLUSION
In this study, a rapid and automatic method for the segmentation and visualization of teeth has been proposed. New techniques were proposed for separation of mandible and maxilla, segmentation of teeth and metal artifact reduction. The separation of the mandible and maxilla was based on MIP and a step like region separating procedure. Teeth segmentation was performed using an intensity based region growing procedure. The metal artifact procedure was based on a mask created from the weighted image of the segmented teeth. The algorithm was evaluated using multiple datasets. Results showed the algorithm had a high success rate and the average time needed for segmentation was only 2.46 sec which is extremely faster than previously proposed methods which needed an average of 1150 sec to execute. The future plans include finding a method to reconstruct images degraded by metal artifacts.
REFERENCES
- Chen, H. and A.K. Jain, 2004. Tooth contour extraction for matching dental radiographs. Proceedings of the 17th International Conference on Pattern Recognition, August 23-26, 2004, Cambridge, UK., pp: 522-525.
CrossRef - Cucchiara, R., E. Lamma and T. Sansoni, 2004. An image analysis approach for automatically re-orienteering CT images for dental implants. Comput. Med. Imaging Graph, 28: 185-201.
CrossRef - Fevens, T., A. Krzyzak and S. Li, 2006. Automatic clinical image segmentation using pathological modeling, PCA and SVM. Eng. Applied Artif. Intell., 19: 403-410.
CrossRef - Hosntalab, M., R.A. Zoroofi, A.A. Tehrani-Fard and G. Shirani, 2008. Segmentation of teeth in CT volumetric dataset by panoramic projection and variational level set. Int. J. Cars, 3: 257-265.
CrossRefDirect Link - Jain, A.K., H. Chen and S. Minut, 2003. Dental biometrics: Human identification using dental radiographs. Proceedings of the International Conference on Audio and Video Based Biometric Person Authentication (AVBPA), June 9-11, 2003, Guildford, UK., pp: 429-437.
CrossRef - Keyhaninejad, S., R.A. Zoroofi, S.K. Setarehdan and G. Shirani, 2006. Automated segmentation of teeth in multi-slice CT images. Proceedings of the IET International Conference on Visual Information Engineering (VIE 2006), September 26-28, 2006, Bangalore India, pp: 334-339.
CrossRefDirect Link - Kondo, T., S.H. Ong and K.W. Foong, 2004. Tooth segmentation of dental study models using range images. IEEE Trans. Med. Imag., 23: 350-362.
CrossRefDirect Link - Liao, S.H., W. Han, R.F. Tong and J.X. Dong, 2005. A Hybrid Approach to Extracting Tooth Models from CT Volumes. In: Mathematics of Surfaces, Martin, R., H. Bez and M. Sabin (Eds.). LNCS 3604, Springer-Verlag, Berlin Heidelberg, ISBN: 978-3-540-28225-9, pp: 308-317.
CrossRefDirect Link - Li, S., T. Fevens and A. Krzyzak, 2006. An automatic variational level set segmentation framework for computer aided dental X-ray analysis in clinical environments. Comput. Med. Imaging Graph, 30: 65-74.
CrossRef - Pongracz, F. and Z. Bardosi, 2006. Dentition planning with image based occlusion analysis. Int. J. CARS, 1: 149-156.
CrossRef - Rueda, S., J.A. Gil, R. Pichery and M. Alca�iz, 2006. Automatic Segmentation of Jaw Tissues in CT Using Active Appearance Models and Semi-Automatic Landmarking. In: Medical Image Computing and Computer-Assisted Intervention, Larsen, R., M. Nielsen and J. Sporring (Eds.). LNCS 4190, Springer-Verlag, Berlin, Heidelberg, ISBN: 978-3-540-44707-8, pp: 167-174.
CrossRefDirect Link - Said, E.H., D.E.M. Nassar, G. Fahmy and H.H. Ammar, 2006. Teeth segmentation in digitized dental X-ray films using mathematical morphology. IEEE Trans. Inform. Forensics Security, 1: 178-189.
CrossRefDirect Link - Shah, S., A. Abaza, A. Ross and H. Ammar, 2006. Automatic tooth segmentation using active contour without edges. Proceedings of the Biometric Consortium Conference, September 19, 2006, Baltimore, pp: 1-6.
CrossRef - Zhao, M., L. Ma, W. Tan and D. Nie, 2005. Interactive tooth segmentation of dental models. Proceedings of the Conference of Engineering in Medicine and Biology Society, January 17-18, 2005, Shanghai, pp: 654-657.
CrossRef
Sharma Mayank Reply
Hello Sir,
I am doing my masters from IIT Madras and on same project.
I had gone through your paper on same topic and liked it, liked the approach.
But to actually implement it on matlab, can't figure it out how to approach.
Can you send me the codes for this segmentation and reconstruction, this will be great help.
H. Akhoondali
Hello,
The algorithm has been implemented using C++ not Matlab. Unfortunately, it is not possible to give the codes.
Kind regards