
Omar Mohd. Rijal
Institute of Mathematical Science, University Malaya, Lembah Pantai, 59000 Kuala Lumpur, Malaysia
Norliza Mohd. Noor
Department of Electrical Engineering, Science and Technology College, UTM City Campus, Universiti Teknologi Malaysia, Jalan Semarak, 54100 Kuala Lumpur, Malaysia
Shee Lee Teng
Institute of Mathematical Science, University Malaya, Lembah Pantai, 59000 Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 7 | Page No.: 1293-1298







ABSTRACT
A statistical method of comparing two digital chest radiographs for Pulmonary Tuberculosis (PTB) patients has been proposed. After applying appropriate image registration procedures, a selected subset of each image is converted to an image histogram (or box plot). Comparing two chest X-ray images is equivalent to the direct comparison of the two corresponding histograms. From each histogram, eleven percentiles (of image intensity) are calculated. The number of percentiles that shift to the left (NLSP) when second image is compared to the first has been shown to be an indicator of patients` progress. In this study, the values of NLSP is to be compared with the actual diagnosis (Y) of several medical practitioners. A logistic regression model is used to study the relationship between NLSP and Y. This study showed that NLSP may be used as an alternative or second opinion for Y. The proposed regression model also show that important explanatory variables such as outcomes of sputum test (Z) and degree of image registration (W) may be omitted when estimating Y-values.
PDF Abstract XML References Citation
How to cite this article
Omar Mohd. Rijal, Norliza Mohd. Noor and Shee Lee Teng, 2008. Selecting a Variable for Predicting the Diagnosis of PTB Patients From Comparison of Chest X-ray Images. Journal of Applied Sciences, 8: 1293-1298.
DOI: 10.3923/jas.2008.1293.1298
URL: https://scialert.net/abstract/?doi=jas.2008.1293.1298
DOI: 10.3923/jas.2008.1293.1298
URL: https://scialert.net/abstract/?doi=jas.2008.1293.1298
INTRODUCTION
With the number of Pulmonary Tuberculosis (PTB) cases on the rise (Cruez, 2005; WHO, 2006), greater awareness of the disease and the need for better monitoring approach is essential. Reports by WHO (2004), the global targets for tuberculosis control are to cure 85% of the sputum smear-positive cases detected and to detect 70% of the estimated new sputum smear-positive cases.
Unnikrishnan and Jagannatha (2002) uses the definition, monitoring is a program of supervision designed to monitor the health and activities of an afflicted person. It includes ensuring compliance with an appropriate prescribed course of medication or medical therapy and with the recommendations and orders of the expert doctors. However, in this study, monitoring is defined as the investigation of a patients response to treatment by comparing a series of his chest radiographs.
The study by Rijal et al. (2006) applies the seven control point registration (SCPR) method and a resizing technique before the comparison of images is carried out. The correlation RF2 defined from the ULFR model (Rijal et al., 2006; Dolby, 1976; Fuller, 1987) was used as a measure of quality of image registration. In this study the variables W is defined as follows;
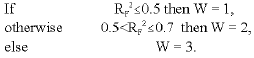
Figure 1 shows three box-plots corresponding to three histograms of the appropriate chest radiograph image of the PTB infected area of the same patient taken at three consultation time points.
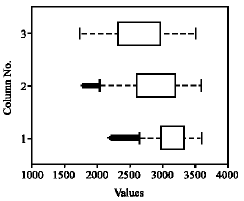 | |
| Fig. 1: | Lowest box-plot corresponds to the histogram of chest radiograph of the PTB infected area from the first consultation. Similarly top-most box-plot is for the last consultation visit |
The left-ward shift of the histogram (from bottom to top) motivates the definition of NLSP which is the number of percentiles that shifted to the left (for example, second image compared to the first).
After registration and resizing (Hill et al., 2001; Gonzalez et al., 2004; Zitova and Flusser, 2003), a subset of two images, say
and
were obtained such that I(·,·)and K(·,·) represent identical regions at two different time point, say t and t+1.
Henceforth eleven percentile of the image intensity values for each of I(·,·)and K(·,·) were calculated and compared. For example if the median of intensity values for K(·,·) is less than the corresponding median for I(·,·), this suggests that the image histogram has shifted to the left. This leftward shift suggests a decrease in intensity of snowflakes and hence in turn indicate a positive response to treatment. The total number of percentile shifting to the left is defined as NLSP. Estimate for NLSP was obtained from a computer aided diagnostic for monitoring PTB (CAD-M-PTB) system (Rijal et al., 2006).
Selection of hospital: The data or images were collected randomly from three types of hospitals recommended by Mahyuddin (2006). They are the District Hospital Tanjung Karang (HTK), Kuala Selangor, Hospital Tengku Ampuan Rahimah (HTAR), Klang and The Institute of Respiratory Medicine (IPR), Hospital Kuala Lumpur. The HTK and HTAR were selected because
| • | They have a dedicated chest clinic. The hospitals were located in areas of high occurrence of PTB cases and therefore a high number of PTB cases can be obtained easily. |
| • | The medical officers are experienced in the PTB cases. |
| • | The hospitals have their own particular PTB treatment days. We may obtain and get latest information about the progress of the PTB patients accordingly. |
A total of 5 volunteer medical officers were involved in this study. The hospital visits were limited as follows due to time consideration:
| Week 1: HTK | |
| Week 2: HTAR | |
| Week 3 and 4: IPR |
MATERIALS AND METHODS
The experiment: In this experiment, medical records (patient wallet) at each hospital are randomly selected. Then for each selected patient wallet/file, the medical officer uses the standard procedure of direct visual interpretation of x-ray and analyses the information (e.g., sputum test) from patient’s file, (Shaban, 2005). The same patient will then be subjected to the diagnostic procedure of the CAM-PTB system where the statistic NLSP was calculated.
Only the confirmed PTB cases (37 from IPR, 29 from HTK and 16 from HTAR) are used for data analysis. The data is analyzed separately because IPR is a referral centre to which other hospital like HTAR, must report to. HTK is a smaller district hospital where respiratory specialist from HTAR will do their routine weekly visit.
Each doctor was required to make one of four responses in a survey form which are as follow:
| • | Patient’s chest x-ray Worse, y = 1 |
| • | Patient’s chest x-ray No change, y = 2 |
| • | Patient’s chest x-ray Improvement, y = 3 |
| • | Patient’s chest x-ray Stable, y = 4 |
Increasing y-values indicated good progress of treatment. We relabeled y = 1, y = 2 into category 0 and y = 3, y = 4 into category 1. The combination of dependent variable y into two categories helps reduce the complication of interpreting the four responses.
As stated in the introduction section, the NLSP values (X) ranged from 0 to 11.
To model the relationship between y and x, a simple logistic regression function is then proposed. According to Menard (2002) and Hosmer and Lemeshow (1989), it has become, in many fields, especially in the health sciences, the standard method of analysis when studying the relationship between a (binary) discrete response/ dependent variable and one or more explanatory variables.
Since the medical doctor incorporates information from the patients file before confirming his diagnosis, this study also consider the relationship of sputum test results, Z with that of Y. Finally the effect of image registration, W, is also investigated.
Brief review of logistic regression: The logistic regression model has been used in statistical analysis for many years. It does not assume linearity of relationship between the independent variables and the dependent, does not require normally distributed variables, does not assume homoscedasticity and in general has less stringent requirements (Menard, 2002). A simple logistic regression function, Model (A), is given as follows (Hosmer and Lemeshow, 1989; Neter et al., 1989):
| (1) |
where, E{Yi} is viewed as a conditional mean of the doctor’s response, given the value of NLSP (Xi). Both parameters β0 and β1 will be estimated by using maximum likelihood estimation.
The logarithm of the likelihood functions is given as:
To maximize the likelihood function, we take partial derivatives with respect to β0 and β1, set these equal to zero, replace β0 and β1 with b0 and b1, respectively, yields the likelihood equations:
| (2) |
| (3) |
Since the Eq. 2 and 3 are nonlinear in the parameter estimates b0 and b1, a numerical solution specifically designed for logistic regression in MATLAB software program is used to estimate the parameters. Once the maximum likelihood estimates b0 and b1 are found, the fitted response function can be obtained as follows:
| (4) |
To obtain the multiple logistic regression model, we simply replace β0+β1X in Eq. 1 by β0+β1X1+β2Zi, where for example Zi is the value of sputum test results. The multiple logistic response function, Model (B), is then given as:
| (5) |
where | 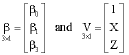 |
The procedure for estimating the regression parameters in multiple regression is the same as explained in simple logistic regression.
Goodness-of-fit test for model (A): As the case for all regression models, the aptness of the logistic regression model needs to be checked before it is accepted for use. Since our data is in the ungroup binary category, two common methods: Hosmer-Lemeshow statistic and analogues of the R2-statistic are suggested by Hosmer and Lemeshow (1989) and Collet (1952) to summarize model adequacy. However, Imon (2007) commended that our sample size is small in three hospitals, respectively, thus the Hosmer-Lemeshow statistic may not be appropriate for testing the accuracy of the fitted model. Only the analogues of the R2-statistic is then applied to evaluate the fit of the model.
Several analogues to the linear regression R2 have been proposed for logistic regression. For general use, Nagelkerke (1991) recommended the statistic ![]() and Menard (2002) suggested the statistic
and Menard (2002) suggested the statistic ![]() .
.
For statistic ![]() , it is defined as:
, it is defined as:
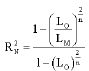 | (6) |
where, LO is the likelihood function for the model that contains only the intercept, LM is the likelihood function that contains all the predictors (NLSP or sputum results) and n is the total number of binary observations (tested PTB patients) that make up the data base.
For statistic ![]() , it is defined as:
, it is defined as:
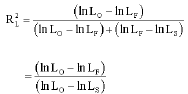 | (7) |
where, LO is the log-likelihood function for the model that contains only the intercept, LF is the log-likelihood function that contains all the predictors (NLSP or sputum results) and LS is the log-likelihood function from the saturated model. In Eq. 8, the value of the log-likelihood LS could be easily obtained from the definition of deviance as below:
| (8) |
| (9) |
Both ![]() and
and ![]() is then multiplied by 100 to show the percentage of accuracy the model predict the dependent variable.
is then multiplied by 100 to show the percentage of accuracy the model predict the dependent variable.
Comparing linear logistic models: In examining the effect of including terms Z in Model (B), it is important to recognize the change in deviance (Neter et al., 1989; Collet, 1952);
Let
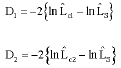 |
and
| (10) |
where, ![]() is the maximum likelihood under Model (A),
is the maximum likelihood under Model (A), ![]() is the maximum likelihood under Model (B), given in Eq. 5 and
is the maximum likelihood under Model (B), given in Eq. 5 and ![]() is the maximum likelihood under the saturated model.
is the maximum likelihood under the saturated model.
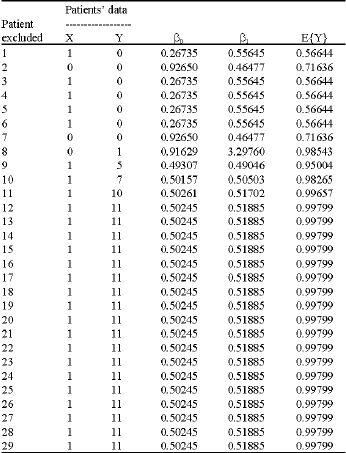
| Table 1: | Analysis of Leave-One-Out method (LOU) for HTK data |
 | |
It is known that De~ χ2 (dD1–dD2) where dD1 and dD2is the degree of freedom, respectively for model (A) and model (B). If De < χ2 (dD1–dD2) for a given level of significance (α = 0.05), the Model (A) and Model (B) are considered similar, in other words choose the simpler model.
If the reduction in deviance is highly significant, the term Z should be added in model (A). Otherwise, we may ignore the variable.
The leave-one-out method (LOU): Since the sample size is important in deciding the choice of model, the robustness of the model is investigated by using the LOU method. Suppose there are n observations (x1, y1), (x2, y2),..., (xn, yn). The LOU method is as follows;
| • | Omit point (x1, y1), estimate β0, β1 and E{Y}. |
| • | Omit point (x2, y2), replace with (x1, y1) and again estimate β0, β1 and E{Y}. |
| • | Repeat the process until (xn, yn) is omitted. |
Some of the results are shown in Table 1 for HTK. For large values of X, E{Y} is close to 1 (as expected). However for X values less than seven, E{Y} takes values around 0.5. This suggests that Model (A) should be recommend for use for values of X greater or equal to seven.
RESULTS AND DISCUSSION
Imon (2007) noted that in practice the coefficient of determination, ![]() and
and ![]() with values approximately 0.5 is considered reasonably high. Thus, the goodness-of-fit test showed the simple logistic model fits the data in HTK and HTAR. But, the model is not fitted well in IPR data. The reason might be the biased data since IPR is a referral centre and the chances that a patient referred to this hospital is very likely a positive PTB case.
with values approximately 0.5 is considered reasonably high. Thus, the goodness-of-fit test showed the simple logistic model fits the data in HTK and HTAR. But, the model is not fitted well in IPR data. The reason might be the biased data since IPR is a referral centre and the chances that a patient referred to this hospital is very likely a positive PTB case.
In Table 2, ![]() is compared to
is compared to ![]() . The former is suitable as a measure of goodness-of-fit because Eq. 7 does not critically depend on n, whilst the latter is suitable as a measure of goodness-of-fit because Menard (2002) noted that it is a common measure used in the current versions of SPSS and SAS statistical package.
. The former is suitable as a measure of goodness-of-fit because Eq. 7 does not critically depend on n, whilst the latter is suitable as a measure of goodness-of-fit because Menard (2002) noted that it is a common measure used in the current versions of SPSS and SAS statistical package.
| Table 2: | Results of |
 | |
| Table 3: | Analysis of deviance table and test statistic for IPR, HTK and HTAR |
 | |
| D: Deviance | |
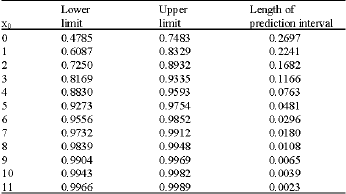
| Table 4: | Prediction interval for E(Y) from several selected x0 values for HTK |
 | |
Nevertheless, the general conclusion is the same, namely the simple logistic model fits the data ‘better’ for HTK and HTAR.
Table 3 shows that the change of deviance in the three hospitals, respectively is not significant when the variable Z is added to Model (A). This result suggests that the visual interpretation of the chest X-ray film may be carried out independently of the outcome of the sputum test. In view of the possible errors when conducting sputum test, for example, a patient not being able to give a good sputum sample, omission of variable Z would mean simplifying the diagnosis process. The results of Table 3 also suggest that it is possible to omit the variable W. The omission of W implies that two X-ray films need not be perfectly aligned before any comparison can be carried out.
Based on a sample of 29 patients for HTK and a sample of 16 patients for HTAR, the following models were obtained:
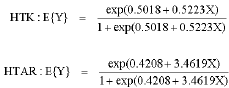 |
The LOU method for HTK (Table 1) shows that the β1 parameter is not very different from the value 0.5223, except when patient number eight is omitted (this is a patient where his chest radiograph shows lung scarring). Hence Model (A) gives robust estimates of β1. However for β0, estimates are reliable for X values larger than seven. Similar remarks may be made for the HTAR model.
The estimate for β0 and β1 for HTK and HTAR suggest that this parameter values are geographically dependent. Comparison of these models is not trivial. Instead of performing any hypothesis test on the existing data, prediction interval for E{Y} was derived. For values of X≥7 narrow prediction intervals were obtained as shown in Table 4.
CONCLUSION
The results from the experiment suggested that the simple logistic regression Model (A) is appropriate to model the relationship between the doctors diagnosis (or response) (Y) and NLSP (X) for hospital HTK and HTAR. Further the LOU method suggests that the logistic regression model may predict Y-values (doctors’ response) accurately for X-values greater than seven, but should be treated with caution otherwise.
Since films scanners are affordable by most hospitals, the CAD-M-PTB system used may be easily applied to estimate the statistics NLSP which in turn can give an objective assessment of the patient’s progress to treatment. This facility would be most suitable when doctors involved are not in the category of specialist or consultant.
ACKNOWLEDGMENTS
We would like to acknowledge the contribution from Datin Dr. Hjh Aziah Ahmad Mahyuddin (Director) and Dr. Azwayati Abas, The Respiratory Unit, Kuala Lumpur General Hospital and Dr. Hamidah Shaban, Selangor Medical Centre.
This research was funded under an IRPA grant from the Ministry of Science, Technology and the Environment and Universiti Teknologi Malaysia.
REFERENCES
- Dolby, G.R., 1976. The ultrastructural relation: A synthesis of the functional and structural relations. Biometrika, 63: 39-50.
CrossRefDirect Link - Hill, D.L.G., G.P. Batchelor, M. Holden and D.J. Hawkes, 2001. Medical image registration. Phys. Med. Biol., 46: R1-R45.
Direct Link - Nagelkerke, N.J.D., 1991. A note on a general definition of the coefficient of determination. Biometrika, 78: 691-692.
Direct Link - Rijal, O.M., N.M. Noor and L.T. Shee, 2006. A statistical method for comparing chest radiograph images of MTB patients. WSEAS. Trans. Sig. Process, 2: 1017-1023.
Direct Link - Zitova, B. and J. Flusser, 2003. Image registration methods: A survey. Image Vision Comput., 21: 977-1000.
CrossRefDirect Link