
Z. Chalabi
Research Laboratory in Intelligent Systems, Department of Electronics, Algeria
N. Berrached
Research Laboratory in Intelligent Systems, Department of Electronics, Algeria
N. Kharchouche
Research Laboratory in Intelligent Systems, Department of Electronics, Algeria
Y. Ghellemallah
Research Laboratory in Intelligent Systems, Department of Electronics, Algeria
M. Mansour
Laboratory of LSI-REC, University of Sciences and Technology, Mohamed Boudiaf,USTOran 31000, BP 1505, Algeria
H. Mouhadjer
Laboratory of LSI-REC, University of Sciences and Technology, Mohamed Boudiaf,USTOran 31000, BP 1505, Algeria
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 7 | Page No.: 1149-1158







ABSTRACT
This study fits within the framework of the diagnosis assistance and deals with the MR brain image types. To highlight the possibility of cerebral pathology such as tumours, one of the newest techniques of pattern recognition which exploits SOM (Self Organization Map) and LVQ (Learning Vector Quantization) algorithms of Kohonen is proposed. A short outline on these algorithms is brought back. Pre-processing adopted method is presented describing the training basis construction. Three classification approaches are carried out, comparative studies are conducted. The algorithm`s proprieties are verified according to the iteration number and the maps size. The classification quality is expressed via two parameters: the quantization error (QE%) and the good classification rate (CR%). Five pathological images and a healthy one are tested. The obtained results are in accordance with those of the results presented in the referred bibliographic.
PDF Abstract XML References Citation
How to cite this article
Z. Chalabi, N. Berrached, N. Kharchouche, Y. Ghellemallah, M. Mansour and H. Mouhadjer, 2008. Classification of the Medical Images by the Kohonen Network SOM and LVQ. Journal of Applied Sciences, 8: 1149-1158.
DOI: 10.3923/jas.2008.1149.1158
URL: https://scialert.net/abstract/?doi=jas.2008.1149.1158
DOI: 10.3923/jas.2008.1149.1158
URL: https://scialert.net/abstract/?doi=jas.2008.1149.1158
INTRODUCTION
The cerebral IMR (Image by Magnetic Resonance) is an imagery technique used to follow-up the evolution of various brain’s pathologies. The IMR is characterized by the effect of partial volume actually corresponds to a mixture of two or several tissues existing specially at the borders between tissues. The detection and the characterization of the cerebral structures and lesions are significant diagnosis’s elements (Yazid et al., 2004).
The aim of this processing studies the tumour evolution or change in the tissue state in the framework of automated detection and pathology classification. So as, it is necessary to know exactly the occurred changes. However, the visual interpretation of images is not always reliable. It is sometimes necessary to analyze several images before reaching a final decision. Consequently, it is useful to have diagnosis aid tools in order to collect the exact information about the element’s characteristics contained in the image. In addition, the number of images to be treated, for example, in the case of systematic tracking, makes the resorting to automated techniques. For less automated techniques, processing tools can simplify such a task (Tarroux et al., 1992).
Detection passes inevitably by a segmentation stage, not yet resolved problem in cerebral MRI. The approaches by classification are largely used, they are different by two significant characteristics: the existence and character of a modelling and by the nature of knowledge a prior. Based on Bayesian theory, they exploit the principle information of brain image’s segments. This allows obtaining appropriate results of segmentation. Hence, this is the approach proposed, in this work as in Moussaoui and Chen (2004) but by using Vector Quantization Technical (VQT), for segmenting the brain’s MRI to grey and white substances, by proceeding a manual selection of the interest’s area.
In recent years, many advanced classification approaches, such as artificial neural networks, fuzzy-set and expert system, have been widely applied for image classification. The study (Lu and Weng, 2007) is focused on current practices, problems and prospects of image classification. The techniques used for improving classification accuracy and some important issues affecting classification performance are discussed. It is of great help in this domain. Classifiers such as neural networks have increasingly become important approaches because of their robustness and their easy availability in almost any image processing.
In reality, different classification methods have their own merits: the question of which classification approach is suitable for a specific study is not easy to answer. The purpose in Lukas et al. (2004) and Jan et al. (2007) was to compare several classification techniques applied to discriminate four types of brain tumours, Linear Discriminant Analysis (LDA), Support Vector Machines(SVM) and Least Squares SVM (LS-SVM) with a linear kernel as linear techniques and LS-SVM with a Radial Basis Function (RBF) kernel as a nonlinear technique are compared. The combined use of Magnetic Resonance Imaging (MRI) and Magnetic Resonance Spectroscopic Imaging (MRSI) has demonstrated to improve the accuracy of classifiers. MRI and MRSI data used in these papers are selected from the INTERPRET project database of the European Union. The area under (AUC) the Receiver Operating Characteristic (ROC) curve analysis measures the performance of binary classifiers, the percentage of correct classifications was used to evaluate the multiclass classifiers. For (Lukas and Devos), the automated binary classifiers reached a mean test AUC of more than 0.95% and did not find any statistically significant difference between the performances of LDA and the kernel based methods. However, Jan et al. (2007) demonstrates that the combination between LS-SVM, Bayesian class probabilities, future selection based on automatic relevance determination are able to classify not only the main type of tissue but also the grade and the subtype of a tumor. The work in Nizar et al. (2007) is focused on the reduction of the false positive using in the pretreatment the morphological operators, the wavelets transform for the microcalcifications detection and classification in two categories, suspect and normal, by neural networks. Good system sensitivity 85.2% is obtained assessed on the ROC curves.
To extract and to characterize the STROK (AVC) Accident Vascular Cerebral, mathematical morphology especially the geodesic dilatation approach is used in Yazid et al. (2006), the results are good but the improvement of the pre-processing, the refinement of the tolerance adjustment will allow obtaining better results.
Generally, depending on the classifiers chosen, different results may be obtained. Therefore, it is necessary to still seek the most powerful and optimal method inbrain image classification. But selecting suitable dataset is a critical step for successfully implementing an image classification (Lu and Weng, 2007). This is why, we exploit the parallel processing and the nonlinear characteristics of the Neural Networks, mainly SOM (Self Map Organization) and LVQ (Learning Vector Quantization) Kohonen Networks, to classify healthy and pathological brain images. A lot of works (CeZhu et al., 1995; Tarroux et al., 1992; Richard, 2004; Kohonen, 1997; Lory and Gietl, 2000) proved that these networks are really adapted to classify a great number of data. The learning by Vector Quantification (VQ) takes into account the specificities of the given application and permits to exploit a priori information.
The aim of this study is, in a first task, to propose a simple realization, easy to implement in order to improve the automatic control. A systematic functional brain MRI study is done in Axel et al. (2004), showing comparative quantitative evaluations between neural gas network, Kohonen’s self-organizing map and fuzzy clustering technique. One of the most important findings is: Kohonen’s map outperforms the two other methods in terms of computational expense. The second task is to evaluate the obtained results by comparison first between the two algorythms then with other published results. For example, in Karen et al. (1995) the same technique of classification is used, based on pulmonary tomography images with only a classification rate of 74%. The authors as Aleksandra et al. (1997) used the wavelet transform and the t-test statistical to analysis and classify the infarction of the myocardium tissue. They obtained promising results with a rate of 96%.
The study is concentrated on the study of the used algorithms properties and the basis construction of the training and testing using five pathological images and one healthy image.
MATERIALS AND METHODS
This study was realised in June 2006 by the aid to diagnosis team, in the Research Laboratory in Intelligent Systems (LRESI) of Electronics Department at the University of Sciences and the Technology, Oran in Algeria. We used an environment Matlab/Toolbox neural Nets to implement SOM and LVQ algorithms. Tested images are acquired free from internet.
SOM and LVQ networks of Kohonen are significant networks for competitive training, largely widespread for classification. Data analysis and pattern recognition have given best results than those obtained by other classifiers (Lory and Gietl, 2000). Several works (Cédric et al., 2004; CeZhu et al., 1995; Tarroux et al., 1992; Kohonen, 1997) present many informations on these networks. Tarroux et al. (1992) treat the classification theory in particular on labelling, rule of training and criterion of classification. In CeZhu et al. (1995), a rigorous theoretical study, not often made, on the performances of optimization of classification performed by LVQ is deferred. Details on their implementation are given in Kohonen (1997). Their basic tool is a vector quantification realized by the nearest neighbour technique.
SOM networks: SOM maps learn how to classify, in a non-supervised manner, the input vectors respecting to their topology in the input space. The training is performed iteratively presenting each vector X of the whole of training at the neuron network whose weight vectors Wi are randomly initialized. The nearest neuron, according to the Euclidean distance (Eq. 1) between its vector Wi and X, is selected; its weight as those of its neighbours undergoes a modification according to the Eq. 2:
| (1) |
| (2) |
| (3) |
where, t is the iteration count carried out (time), α is a training parameter which evolves in the interval [0, 1] and decreases in time to refine. Vc is an area defined around the wining neuron Wc, with the last iterations it contains only the winner Wc and possibly its neighbours. In Eq. 3, the degree of the modification decreases with the distance on the map between the neuron positions Wc and the updated neuron. D (i,c) is the euclidean distance between i and c. The ray of vicinity σ is inversely proportional to the number’s iteration.
SOM maps constitute already a useful tool for pre-processing for the separation and the redistribution of the input vectors in various classes and give an idea about the statistical distribution of the input vectors on the output layer, without any considerations for the classes. Nevertheless, at this level, a problem remains posed in the decision-making process and of neurons labelling.
LVQ network: A supervised training can cure this limit. The LVQ algorithm learns how to classify the inputs vectors with respect to a desired class selected by the user (Tarroux et al., 1992). There are several versions of this algorithm noted: LVQ1, LVQ2, LVQ2.2 and LVQ3. This method will allow a re-adjustment of the probability distributions on the output map and will thereafter make decision on the label allotted to each neuron (Andras, 1999; Tarroux et al., 1992). The main objective of LVQ is to obtain good recognition rate without any topology preserving mapping. In our work, the LVQ1 method is employed, with general principle:
| • | The weights Wi of each neuron of the network are initialized with random values. |
| • | Calculate euclidean distance between the classified vector and the weights of each neuron of the map. |
| • | The nearest neuron to the input vector is selected Wc (winer neuron), only its weights are modified by the following training rule with 0<α(t)<1: |
If the selected neuron (the nearest) represents the good class, therefore:
| (4) |
If the selected neuron does not represent the good class, hence:
| (5) |
For the other neurons:
| (6) |
The robustness of the Kohonen networks is due to the training by the VQ method whose principal interest depends mainly on the construction of a dictionary (codebook) which takes into account the specificities of the given application allowing consequently the a prior information exploitation. Although, the choice of certain parameters as the number of neurons and iterations, the training step, remains empirical.
Realization: According to Lu and Weng (2007), for a particular study it is often difficult to identify the best classifier due to the lack of a guideline for the selection and the availability of suitable classification algorithms to hand. Comparative studies of different classifiers are thus frequently conducted. Moreover, the combination of different approaches has shown to be helpful for improvement of classification algorithms. For this, we propose to explore three classification approaches:
| • | Classification by SOM algorithm |
| • | Classification by LVQ1 algorithm |
| • | Classification by combination between SOM and LVQ1 algorithms. |
Accuracy assessment is an integral part in an image classification procedure, based on error quantification is the most commonly employed approach. Here, the classification quality of each approach is expressed by the calculation of the parameters referred to performance: the Quantification Error (QE) and the good Classification Rate (CR). The QE measures the distortion between the input vectors and their representatives in the codebook. The rate (CR) permits to know the rate of assignment of a class to a data (vector) with a degree of probability (Richard, 2004; Andre and Emanuel, 1998).
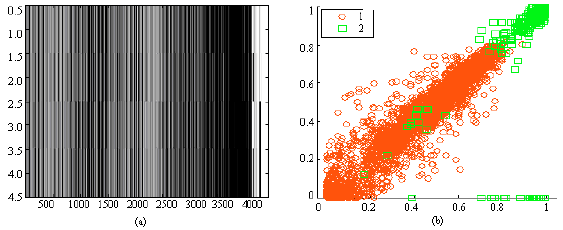 | |
| Fig. 1: | Input Database: (a) Total corpus and (b) Distribution of the inputs vectors. The red circles are the healthy areas class 1; the green squares are the pathological ones class 2 |
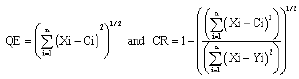 | (7) |
where, C is the winner neuron, Y the neuron more far from vector X.
Pre-processing: The tumour detection is based especially on the pre-processing with which the goal is to build the training base and checks the compactness and the separability of the input vectors. The principal tasks are the standardization for limiting the grey level intensity of the pixels between 0 and 1 and the identification of the interest healthy and pathological areas. Tumours places are determined by qualified radiologists. The information which characterizes these areas is the intensity of grey levels. To segment the cerebral IMR in grey and white substances, a technique by manual selection is used, taking samples which represent sufficiently the class which corresponds to the tumour and the healthy area. Construction includes the realization of a corpus1 (codebook) starting from a healthy image, a corpus2 starting from four pathological images and a total corpus by the combination of the two first corpus (Fig. 1a).
The selected area is partitioned into 2x2 size block to have vectors of 4 elements. The mean intensities of the first two lines of the block is presented in X-coordinate, that of the third and fourth is carried in ordinate of the input vector distribution curve in Fig. 1b. It shows the compactness and separability which guarantee the distribution of the input vectors of classification algorithms. Practically, these properties are rarely respected, in Fig. 1b, some vectors (very little) of class2 (square) are superposed on vectors of classe1(circle).The red circles are the healthy areas and the green squares are the pathological ones.
The corpus generation takes 30 min, for this reason, only total corpus (Fig. 1a) which will be exploited by the three approaches.
RESULTS
Classification by SOM
Study according to the iteration count: To demonstrate the map evolution, we fixed the number of hidden layers 8x8, then we changed the iterations in an incremental way by taking the good Classification Rate (CR) and the Quantification Error (QE) to each iteration number (Ni). Figure 2a displays a 8x8 size SOM map after 3400 iterations. Table 1 summarizes the realized tests: values of QE and CR with Ni.
The curves in Fig. 3a described by the variations of QE and CR versus iteration number, show obviously the SOM network properties. Error is minimal when the iteration number increases involving a high recognition rate of 96.42% for an error 0.036, see the last column of Table 1.
The curves shapes of Fig. 3a confirm the direction of variation of the two parameters (CR and QE). At the end of the course they become slow what means the learning end.
Study according to the map size: The iteration number is fixed at 200 and the map size (Ta) varies like in Table 2 (values of EQ and CR according to Ta). Figure 2b shows a 16x16 size map, the distribution of neuron grey level is better than in Fig. 2a.
 | |
| Fig. 2: | SOM map: (a) 8x8 size map on 3400 iterations and (b) 16x16 size map on 200 iterations |
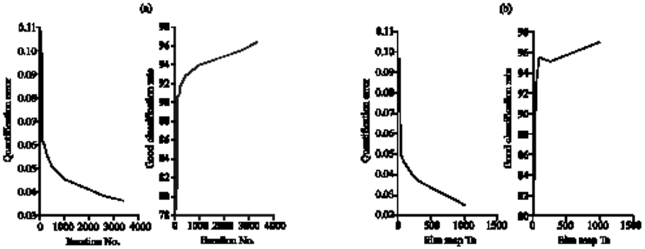 | |
| Fig. 3a: | Variations of QE and RC according to Ni in SOM map 8x8 size, (b)Variations of QE and RC according to Ta and 200 iterations SOM map |
| Table 1: | Values of QE and RC according to Ni in SOM map |
| Table 2: | Values of EQ and TC according to Ta in SOM map |
| Table 3: | Variations of QE and RC for a size 8x8 LVQ map |
The best results, QE = 0.025 and CR = 96.96%, are reached with 32x32 size map. According to Table 2 and Fig. 3b, the good Classification Rate (CR) improves and the quantification error decreases with the increase in the size map. We can make the same remark concerning the shape of the curves in Fig. 3b as in Fig. 2a with a very fast rise at the beginning and a more visible linearity towards the end of the learning.
Classification by LVQ: The learning by LVQ being supervised, hence the realized map cells (Fig. 4a, b) will carry the labels P for pathological and S for healthy. The obtained quantitative results of performance for the 8x8 size for different iterations are shown in Table 3 (variations of QE and CR for LVQ map. The best CR (96.36%) is carried out with 10000 iterations (Ni) which giving the weakest error.
It is important to note that the better results are obtained with 10000 iterations and a 32x32 size map. Increasing the size of the map, on Fig. 4a, revealed more pixels P compared to those of lower sizes. The results are: For size 16x16, QE = 0.0179 with CR = 98.024% and for 32x32 size map, QE = 0.0096 with CR = 98.98%.
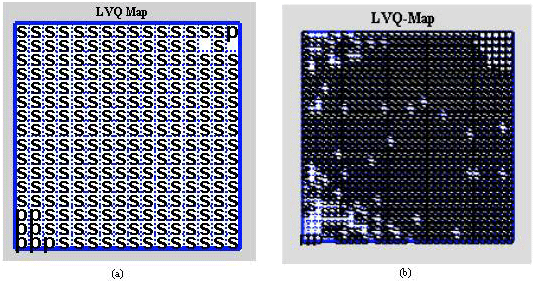 | |
| Fig. 4: | LVQ map: (a) 16x16 size and (b) 32x32 size |
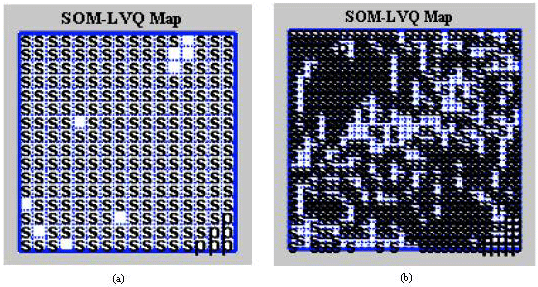 | |
| Fig. 5: | SOM+LVQ map: (a) 16x16 size and (b) 32x32 size |
In 32x32 size map, Fig. 4b, there are also more rejected pixels which are represented by empty boxes (cells). The good classification rate increased from 96.36 (8x8 size Table 3) to 98.98% (32x32 size) and the quantification error decreased from 0.0381 to 0.0096 with the increase in the map size with 10000 iterations.
Classification by combination SOM and LVQ: Taking into consideration of the previous results, the codebook obtained by SOM (Ta = 32x3 and Ni = 3400) is exploited as an input database of LVQ algorithm. The combination takes its interest from the two network advantages. SOM map can positively approximate the statistical distribution of the data to be treated. The associated cells are labelled in LVQ for optimization. This means that this procedure improves both recognition rate and topology preserving mapping characteristics (Andras, 1999).
The iteration number being fixed at 10000, we carry out the two SOM and LVQ maps shown on Fig. 5a 16x16 size map and (b) 32x32 size map. The white cells (rejected pixels) are more numerous on the Fig. 5b than on the Fig. 5a and as more as in the preceding maps, they are badly classified pixels having joined their places. The mains advantage of this hybrid algorithm (combination) is for example if a bad classified neuron happens, a simple analysis of the neighbour of the winning neurons (cells) helps in correcting the class.
Variations of QE and CR according to the SOM and LVQ map size are: For 16x16 size map, QE = 0.0145 with CR = 98.0464% and for 32x32 size, QE = 0.0073 with CR = 99.0911%.
The combination of the two algorithms gives a more reduced quantification error QE = 0.0073 and a higher rate of recognition CR = 99.09%. The execution time is shorter, compared to that of LVQ which uses the total corpus as a database.
DISCUSSION
Our results are in axe with the previous objective to make an improvement in the automatic control using an easy technique to implement According before to the obtained results, the refinement (refining) of the two classes in SOM and LVQ maps varies with the increase of the iteration number and that of the size map. In the various graphs, the quantification error decreases versus the iteration number, however, the good classification rate improves. Comparison, between classification by the SOM and LVQ, emphasizes the properties of each algorithm. In the first unsupervised learning, we can distinguish the classes by grey level, but nothing concerning the class of each neuron (Fig. 2a). Indeed, the weights of the neurons are organized so as to minimize the QE. Only the borders between the classes are more important. Nevertheless, the second labelled map displays exactly the class of each neuron (S, P or rejection in Fig. 4a, b). Labelling allows an adjustment of the vectors weights in such a manner that they determine the separation surfaces between the classes close to optimal Bayes surfaces. This is why the LVQ performances are better than those of the SOM. The first finding is as wished by the theoretical studies (CeZhu et al., 1995; Lory and Gietl, 2000), LVQ is optimal for a great number of data and depend on the number of codebook vectors assigned with each class and the proper training rate, which was checked by the our results. By way of comparison, we can cite a few works in the same field and goals, using LVQ algorithm. In (Andre and Emanuel, 1998), obtained results by the classification of the underwater ferromagnetic objects, using LVQ classifier, are CR = 96% with geometrical attributes to carry out the database. The study (Meritxell et al., 2005) is focused on the non-supervised statistical methods in which the various assumptions, about the intensity distribution, the number of classes and the a priori space use, are compared. Best obtained CR is 85% for one of the 5 classes of brain tissue. In (Allexandra et al., 2003), the identification of a mammary micro-calcification is made with a CR = 90% using LVQ algorithm and the Fischer Discrimination. The study of Tarroux et al. (1992) relating to histological images cuts of mammary tissue by the use of various adaptive algorithms to discriminate in two classes (malignant and benign), LVQ algorithm reaches the highest CR = 90%. We note according to these results that LVQ is a method adapted to classification. It is the reason which directed our choice of this type of network to classify medical images. Under almost the same conditions, our results with LVQ1 are rather better, giving CR = 98.97%.
In several articles, the VQ algorithm of Kohonen is often considered as a tool for compression and has been realised successfully. The combination procedure between the compression and classification was made in Karen et al. (1995), to classify Pulmonary Tomography Images. The authors wished to compress the images and to identify the pulmonary nodules of tumour. The codebook was built by the SOM map and 32x32 size LVQ map. Hence, the obtained CR is 74.9%. Our proposed method by combination (SOM and LVQ) provides high accuracy a CR = 99.09%. Combining by SOM and LVQ has proven successful because the compression, here by SOM, can present data selectively to LVQ, keeping only the most representative data, which is important in the separation of the classes, what is recommended by Jan et al. (2007) and Lu and Weng (2007). Hence, a good representation, of the database for each class is the key to implement a supervised classification. Generally our results relate to previous finding, even support them. Also as important results: the technique to select the interest areas is reliable, the combination of nonlinear methods increases performance.
Based classification SOM and LVQ carried out high performances indicating that it is possible to hope for the method integration in a clinical system of aid to diagnosis. But it is wiser than this technique is tested on a greater number of cerebral images and on other medical images types so that it to be generalized. It is also desirable to combine the advantages of many methods, to propose a technique where the arbitrary parameters are fewer, because method LVQ even if it gives good classification rates, it remains dependant on the arbitrary parameters of initialization.For further work, we use the algorithm SART, relating to Supervised Adaptive Theory Resonance, which combines the advantages of the non-parametric methods and those of the vectorial quantification. It is completely automatic method which does not require any arbitrary choice of parameter structuring the neural networks.
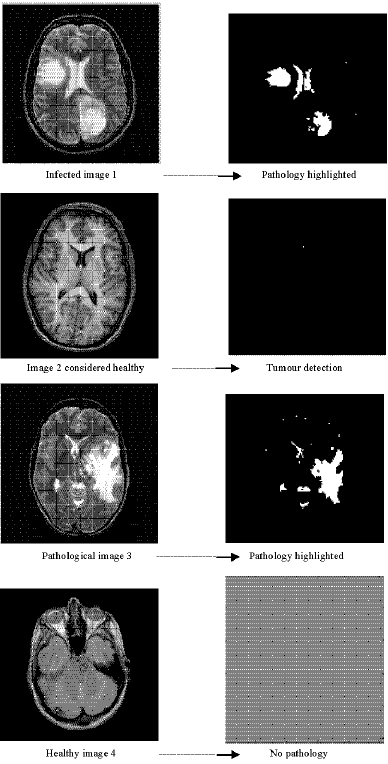 | |
| Fig. 6: | Tested images |
Of course, the procedure by combination SOM and LVQ is tested according to better rates obtained to validate the classification supervised by Kohonen Networks for the medical diagnosis. Starting from a brain IMR, this phase permits to know if the brain is healthy or infected, in order to highlight pathology. We partition the image into 2x2 size blocks to obtain vectors with 4 elements. Subsequently, by the decision, we assign to each vector a class, i.e., the vector takes the class of the nearest neuron to him. We binaries each pixel so that it takes a value 0 if it belongs to a vector of healthy class (class 1) and a value 1 if it belongs to a vector of pathological class (class 2). Then, we rebuild the image and see whether it is infected or not. Tests are carried out on four images demonstrated as in Fig. 6 in tested images.
Pathologies are well located in images 1 and 3. Image 4 being healthy did not reveal any pathology. Image 2 represents visually the case of a healthy image, but after the test, we observe the opposite: a tumour is evolving. In fact, a small white area is visible on the image after test. It should be noticed that the network can cover human deficiency in the medical diagnosis with precision. These tests prove the parallel capacity of the neural networks processing, in particular those of Kohonen planned for classification and the need to have a system of aid with an automatic diagnosis largely justified by the introduction.
CONCLUSION
The main goal to implement an intelligent system of pattern recognition for the automation of diagnosis on Cerebral IMR is reached according to the higher results images tests. An efficient classifier depends on the attributes choice during the pre-processing of which the goal is to build the learning basis. Classification by neural network offers several advantages such as parallelism, capacity of adaptation, distributed memory, capacity of generalization and the facility of implementation. The properties of the adopted algorithms are checked, where the results prove it well.
The combination, SOM and LVQ1, is more efficient because the non-supervised map of Kohonen constitutes already an effective stage of pre-processing for discrimination and redistribution of the input vectors in various classes by LVQ1. It acts on the combination between compression and classification. The objective to present better results is achieved considering the quality of detection on the tested images and the performance values displayed by the proposed procedure. With 10000 iterations and a 32x32 size map and CR = 99.09%, the collected results are better than those published in the used references.
REFERENCES
- Mojsilovic, A., M.V. Popovic, A.N. Neskovic and A.D. Popovic, 1997. Wavelet image extension for analysis and classification of infarcted myocardial tissue. IEEE Trans. Biomed. Eng., 44: 856-866.
CrossRefDirect Link - Wismüller, A., A. Meyer-Bäse, O. Lange, D. Auer, M.F. Reiser and D. Sumners, 2004. Model-free functional MRI analysis based on unsupervised clustering. J. Biomed. Inform., 37: 10-18.
PubMed - Archambeau, C., T. Butz, V. Popovici, M. Verleysen and J.P. Thiran, 2004. Supervised nonparametric theoretic classification. Proceedings of the 17th International Conference on Pattern Recognition, Volume 3, August 23-26, 2004, IEEE Xplore London, pp: 414-417.
CrossRef - CeZhu, W. Jun and W. Taijun, 1995. Analysis of learning vector quantization algorithms for pattern classification. Proceedings of the International Conference on Acoustics, Speech and Signal Processing, May 9-12, 1995, Detroit, MI., USA., pp: 3471-3474.
CrossRefDirect Link - Luts, J., A. Heerschap, J.A.K. Suykens and S. van Huffel, 2007. A combined MRI and MRSI based multiclass system for brain tumour recognition using LS-SVMs with class probabilities and feature selection. Artificial Intel. Med., 40: 87-102.
Direct Link - Oehler, K.L. and R.M. Gray, 1995. Combining image compression and classification using vector quantization. IEEE Trans. Pattern Anal. Mach. Intel., 17: 461-473.
CrossRefDirect Link - Lu, D. and Q. Weng, 2007. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens., 28: 823-870.
Direct Link - Lukas, L., A. Devos, J. Suykens, L. Vanhamme and F. Howe et al., 2004. Brain tumour classification based on long echo time proton MRS signals. Artificial Intel. Med., 31: 73-89.
Direct Link - Cuadra, M.B., L. Cammoun, T. Butz, O. Cuisenaire and J.P. Thiran, 2005. Comparison and statistical methods classification in T1-weighted MR brain image. IEEE Trans. Med. Imag., 24: 1548-1565.
Direct Link
ankit patel Reply
sir i want python code of image classification using kohonen self organizing maps and report