
Mitat Uysal
Dogus University, Acibadem-Kadikoy 34722, Istanbul, Turkey
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 6 | Page No.: 922-925







ABSTRACT
Missing data are a part of almost all research and it must be decided how to deal with it from time to time. Missing data creates several problems in many applications which depend on good access to accurated data. Conventional methods for missing data, like listwise deletion or regression imputation, are prone to three serious problems: Inefficient use of the available information, leading to low power and Type II errors. Biased estimates of standard errors, leading to incorrect p-values. Biased parameter estimates, due to failure to adjust for selectivity in missing data. In this study, we propose a new algorithm to predict missing values of a given time series using Radial Basis Functions.
PDF Abstract XML References Citation
How to cite this article
Mitat Uysal, 2007. Reconstruction of Time Series Data with Missing Values. Journal of Applied Sciences, 7: 922-925.
DOI: 10.3923/jas.2007.922.925
URL: https://scialert.net/abstract/?doi=jas.2007.922.925
DOI: 10.3923/jas.2007.922.925
URL: https://scialert.net/abstract/?doi=jas.2007.922.925
INTRODUCTION
Time series data are used to represent many real world phenomenon. For various reasons, a time series database may have some missing data. Traditional interpolation or estimation methods usually become invalid when the observation interval of the missing data is not small (Hong and Chen, 2003).
The methods of handling missing data are directly related to the mechanisms that caused the incompleteness. These mechanisms fall into three classes (Sentas and Angelis, 2005; Little and Rubin, 2002).
| • | Missing Completely at Random (MCAR): The missing values in a variable are unrelated to the values of any other variables, whether missing or valid. |
| • | Non-Ignorable Missingness (NIM): The probability of having missing values in a variable depends on the variable itself. |
| • | Missing at Random (MAR): This can be considered as an intermediate situation between MCAR and NIM. The probability of having missing values, does not depend on the variable itself but on the values of some other variable. |
Missing data techniques are given in Little and Rubin (2002). They can be listed as: Listwise deletion, mean imputation, regression imputation and expectation maximization. Details can be obtained from Little and Rubin (2002).
Many recent publications appeared in literature related to dealing missing data.
Choi and Kim (2002) presented a physics-based approach for automatically reconstructing three dimensional shapes in a robust and proper manner from partially missing data.
Tang and Hung (2006) have proposed an algorithm to estimate projective shape, projective depths and missing data iteratively.
Yemez and Wetherilt (2007) presented a hybrid surface reconstruction method that fuses geometrical information acquired from silhouette images and optical triangulation.
Golyandina and Osipov (2007) have proposed a method of filling in the missing data and applied to time series of finite rank.
Heintzmann (2007) introduced a novel way of measuring the regain of out-of-band information during maximum likelihood deconvolution and applied to various situations.
Formal representation of missing data: Original data matrix D = (dij) I = 1,2,3…n, j = 1,2,…k contains time series data where dij is the value of variable dj for case I.
When there are missing data, the missing data indicator matrix M = (mij) can be defined as below:
if mij = 1 then dij is missing
if mij = 0 then dij is present
(Sentas and Angelis, 2005).
Radial basis functions for time series forecasting: An RBF network consists of 3 layers: an input layer, a hidden layer and an output layer. A typical RBF network is shown in Fig. 1.
Mathematically, the network output for linear output nodes can be expressed as below:
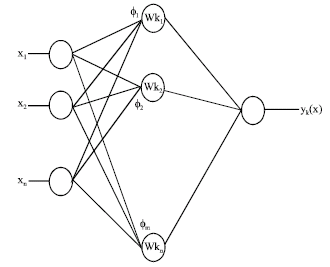 | |
| Fig. 1: | Typical RBF network |
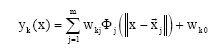 |
Where x is the input vector with elements xi (where I is the dimension of the input vector),
![]() is the vector to determine the center of the basis function Φj with elements
is the vector to determine the center of the basis function Φj with elements ![]() ’s are the weights and wk0 is the bias (Harpham and Dawson, 2006). The basis function Φj (-) provides the nonlinearity. The most used basis functions are Gaussian and multiquadratic functions (Harpham and Dawson, 2006).
’s are the weights and wk0 is the bias (Harpham and Dawson, 2006). The basis function Φj (-) provides the nonlinearity. The most used basis functions are Gaussian and multiquadratic functions (Harpham and Dawson, 2006).
Calculating the optimal values of weights: A very important property of the RBF Network is that it is a linearly weigthed network in the sense that the output is a linear combination of m radial basis functions, written as below:
(Duy and Chong, 2003)
The main problem is to find the unknown weights {w(I) } I = 1,m For this purpose, the general least squares principle can be used to minimize the sum squared error:
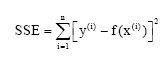 |
With respect to the weights of f, resulting in a set of m simultaneous linear algebraic equations in the m unknown weights
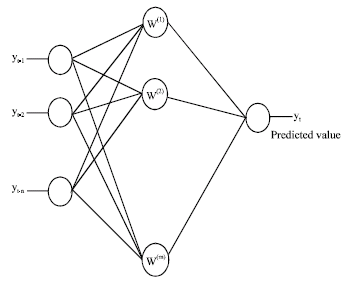 | |
| Fig. 2: | Finding the predicted value yt |
where
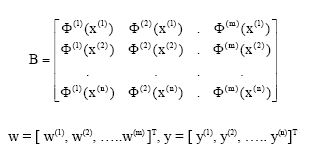 |
In the special case where n = m the resultant system is just
| Bw | = | y | (Duy and Chong, 2003) |
The output y(x) represents the next value of y in time t taking input values x1, x2, …..xn that represent the previous function values set of the time series with values yt-1, yt-2,……yt-n. So, xn corresponds to yt-1, xn-1 corresponds to yt-2 etc. as in Fig. 2.
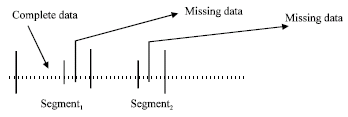
Reconstruction of data series by radial basis functions: a new algorithm: The following algorithm is proposed in this work to find the values of missing data.
| • | Remove the 20% of the original data from the data set. Divide the data set into segments so that each segment contains some missing data: |
| • | Use the complete data of segmenti to find an artificial time series equation with an RBF network that means finding the weights in the RBF approximation. |
| • | Calculate the error in each segment according to the following formula: |
 |
Where eij is the error value in the xi point on the jth segment.
| • | Calculate the sum squared errors in each segment in each pass of the algorithm. |
where k is the number of the pass.
| • | Replace the missing data with the predicted values in each segment in the pass m where SEEm is the minimum value of SSEk. Stop the algorithm. |
SIMULATION RESULTS
Several simulation runs were carried out in a computer environment to find the optimal values of parameters in radial basis functions like width δ and centers ![]() to obtain good predictions for the missing data in the time series.
to obtain good predictions for the missing data in the time series.
Figure 3 shows the results of the first simulation run.
In this run, the first 40 data items were used to predict the next 8 data items that was considered missing data and the results were compared with the real data.
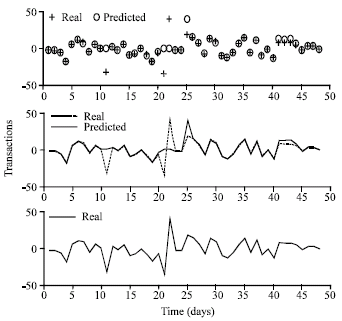 | |
| Fig. 3: | Gaussian Function sigma = 0.93 and 18 neurons in the hidden layer |
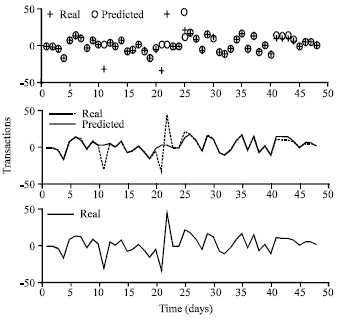 | |
| Fig. 4: | Gaussian Function sigma = 1 and 18 neurons in the hidden layer |
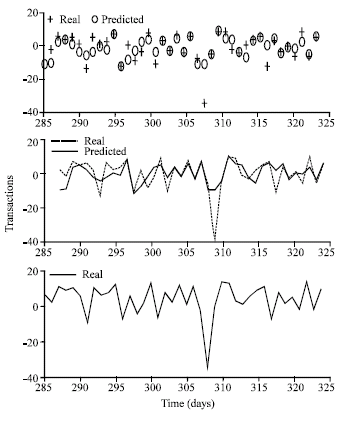 | |
| Fig. 5: | Gaussian Function sigma =1 and 18 neurons in the hidden layer for the last 40 data |
Real data values are represented with symbol + and predicted values are represented with symbol o.
In Fig. 4, similar experiment was carried out with δ = 1 for a Gaussian function and better results were obtained.
Figure 5 shows, the results of the similar experiment for the last 40 data items for a Gaussian function.
CONCLUSIONS
In this study, I proposed a new algorithm to predict missing values of a given time series using Radial Basis Functions. Radial Basis Functions provide a good way to predict the values of missing data in a time series. In this study, a monthly data log of a bank was used to carry out the simulation experiments. The data log file consisted of 324 data items. This file was divided to small parts with 48 data items for the first 6 parts and 36 data items for the last part. The last 20% of the data for each part was removed and these removed data items were predicted using RBF’s and the 80% of the data items for each part. For some optimal parameters of the RBF’s, very good predictions are obtained for the missing data.
REFERENCES
- Choi, S.M. and M.H. Kim, 2002. Shape reconstruction from partially missing data in modal space. Comput. Graph., 26: 701-708.
Direct Link - Duy, N.M. and T.T. Cong, 2003. Approximation of function and its derivations using radial basis function networks. Applied Math. Modell., 27: 197-220.
Direct Link - Golyandina, N. and E. Osipov, 2007. The Caterpillar-SSA method for analysis of time series with missing values. J. Stat. Plan. Inference, 137: 2642-2653.
Direct Link - Harpham, C. and C.W. Dawson, 2006. The effect of different basis functions on a radial basis function network for time series prediction a comparative study. Neurocomputing, 69: 2161-2170.
Direct Link - Heintzmann, R., 2007. Estimating missing information by maximum likelihood deconvolution. Micron, 38: 136-144.
Direct Link - Sentas, P. and L. Angelis, 2006. Categorical Missing data imputation for software cost estimation by multinomial logistic regression. J. Syst. Software, 79: 404-414.
Direct Link - Tang, W.K. and Y.S. Hung, 2006. A subspace method for projective reconstruction from multiple images with missing data. Image Vision Comput., 24: 515-524.
Direct Link - Yemez, Y. and C.J. Wetherilt, 2007. A volumetric fusion technique for surface reconstruction from silhouettes and range data. Comput. Vision Image Understand., 105: 30-41.
Direct Link