
A. Mueen
Faculty of Information Technology, Jalan Multimedia, 63100 Cyberjaya,
Selangor Darul Ehsan, Malaysia
M. Sapiyan Baba
Faculty of Information Technology, Jalan Multimedia, 63100 Cyberjaya,
Selangor Darul Ehsan, Malaysia
R. Zainuddin
Faculty of Information Technology, Jalan Multimedia, 63100 Cyberjaya,
Selangor Darul Ehsan, Malaysia
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 8 | Page No.: 1224-1229







ABSTRACT
The need of content-based image retrieval tools increases with the enormous growth of digital medical image database. Classification of images is an important step of content-based image retrieval (CBIR). In this study, we propose a new image classification method by using multi-level image features and state-of-the-art machine learning method, Support Vector Machine (SVM). Most of the previous work in medical image classification deals with combining different global features, or local level features are used independently. We extracted three levels of features global, local and pixel and combine them together in one big feature vector. Our combined feature vector achieved a recognition rate of 89%. Large dimensional feature vector is reduced by Principal Component Analysis (PCA). Performance of two classifiers K-Nearest Neighbor (K-NN) and Support Vector Machine (SVM) are also observed. Experiments are performed to verify that the proposed method improves the quality of image classification.
PDF Abstract XML References Citation
How to cite this article
A. Mueen, M. Sapiyan Baba and R. Zainuddin, 2007. Multilevel Feature Extraction and X-ray Image Classification. Journal of Applied Sciences, 7: 1224-1229.
DOI: 10.3923/jas.2007.1224.1229
URL: https://scialert.net/abstract/?doi=jas.2007.1224.1229
DOI: 10.3923/jas.2007.1224.1229
URL: https://scialert.net/abstract/?doi=jas.2007.1224.1229
INTRODUCTION
Digital image generation has increased tremendously from last few years. The Radiology Department of the University Hospital of Geneva alone produced more than 12,000 images a day in 2002 (Muller et al., 2004). This huge visual information increases the demand to be organized properly, in order to extract relevant information. One way to solve this problem is to automatically classify images according to predefined categories. Image classification is a long-standing problem of pattern recognition (or computer vision) (Colombo and Bimbo, 1999). Pattern recognition is an integral part of image processing (Duda et al., 2000) and machine learning. Two common methods are used for classification in pattern recognition, are supervised and unsupervised classification method (Acharya and Bimbo, 2005). In this study, we used supervised classification method Support Vector Machines (SVM) for the classification of unclassified images. Support Vector Machines is a relatively new machine learning technique. One of the main advantages of using SVM is that they are capable of learning in high-dimensional spaces. Support Vector Machine has been successfully used in content-based image retrieval.
Low-level image features are extracted from whole image and local regions. Secondly, pixel level information obtained after resizing the image. These three features set are combined to form one big vector. Feature set is then given to a classifier after dimensionality reduction. Our approach is different than other approaches in few aspects, three levels of feature, simple segmentation for local region extraction and classification done by state-of-the-art machine learning method SVM.
Previous work: A growing trend in the field of image retrieval is automatic classification of images by different machine learning classification methods. Image retrieval performance depends on good classification, as the goal of image retrieval is to return a particular image from class C according to the features x provided by the user (Lim et al., 2005). The most common approach in content-based image retrieval is to store images and there feature vector in a database. Similar images can be retrieved from database by measuring the similarity between the query image features and database features space as shown in Fig. 1, the general architecture of CBIR system proposed by Lehmann et al. (2000). Kherfi et al. (2004) pointed out in his survey review many of the system used this approach, such as QBIC (Flickner et al., 1995) was proposed by IBM, Photobook (Pentland et al., 1996) and BlobWorld (Carson et al., 1999) proposed from academic circles. These systems not being able to classify images in particular group they just retrieved similar images from the database.
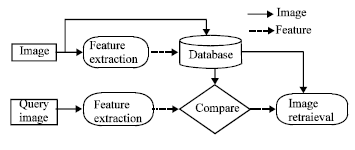 | |
| Fig. 1: | Architecture of CBIR system |
This limitation brings researchers into research of classifying images according to particular categories (Kherfi et al., 2004). In medical domain CBIR is facing same problem.
Medical images play a central part in surgical planning, medical training and patient diagnoses. In large hospitals thousands of images to be managed every year (Mulleret al., 2004) Manual classification of medical images is not only expensive but also time consuming and vary person to person.
The database used in this research is a set of 57 classes from the IRMA x-ray library (Lehmann, 2005). Medical experts classified images according to the body regions and biological system. Classification of x-ray images (radiographs) is challenging problem due to visual similarities between the classes. In image classification, set of image features play a very important role. Next section describes different features set used by different researchers in medical image classification.
Image features: The classification of images begins with the extraction of suitable features from the images. There are three level of feature extraction global, local and pixel. The simplest visual image features are directly based on the pixel values of the image. Images are scaled to a common size and compared using Euclidean distance and image distortion model (Keysers et al., 2004). Local features are extracted from small sub-images from the original image. The global feature can be extracted to describe the whole image in an average fashion. The low-level features extracted from images and local patches are color, texture and shape (Ma and Zhang, 1998).
Color features: Human vision system is more sensitive to color information than grey values of images (Lim et al., 2005). Commonly color feature is extracted using the histogram technique (Swain and Ballard, 1991). The color histogram describes the distribution of different colors in an image in a simple and computationally efficient manner. Other color feature extraction techniques are region histogram, color coherence vector, color moments, correlation histogram etc.
Texture features: The texture feature is extracted usually using filter base method. The Gabor filter (Turner, 1986) is a frequently used filter in texture extraction. A range of Gabor filters at different scales and orientations captures energy at that specific frequency and direction. Texture can be extracted from this group of energy distributions (Mulleret al., 2004). Other texture extraction methods are co-occurrence matrix, wavelet decomposition, Fourier filters, etc.
Shape features: Shape is an important and powerful feature for image classification. Shape information extracted using histogram of edge direction. The edge information in the image is obtained by using the Canny edge detection (Canny, 1986). Other techniques for shape feature extraction are elementary descriptor, Fourier descriptor, template matching, etc.
Proposed method: Automatic image classification is an active research area in field of pattern recognition and machine learning. Here, supervised learning approach is used to classify images. In supervised learning, training set is given with category label and image feature set. The learning task is to compute classifier from training set. This classifier used to label newly unlabeled images.
In this experiment, training set consists of images with 57 class labels and a big feature factor constructed by extracting texture and shape features at global and local level plus the pixel information. Principal Component Analysis (PCA) is used to reduce the dimensionality of feature vector.
This reduced feature vector is given as input in to a multi-class classification tool based on support vector machine classifier. The SVM produce a model. In testing stage unlabeled image go through the same process of feature extraction and dimensionality reduction but at the end SVM model is used to predict the class for unclassified image. The whole classification process is depicted in Fig. 2.
Feature selection: The accuracy of image classification depends mainly on image feature extraction. More discriminated features better will be the classification result. In this study we extracted three level of information, pixel level the pixel information as feature itself, shape and texture information at global and local level. Color information is not included as we are dealing with gray scale images.
Texture features: Texture contains important information regarding underlying structural arrangement of the surfaces in an image. Gray level co-occurrence matrix (GLCM) is well-know texture extraction tool originally introduced by Haralick et al. (1973).
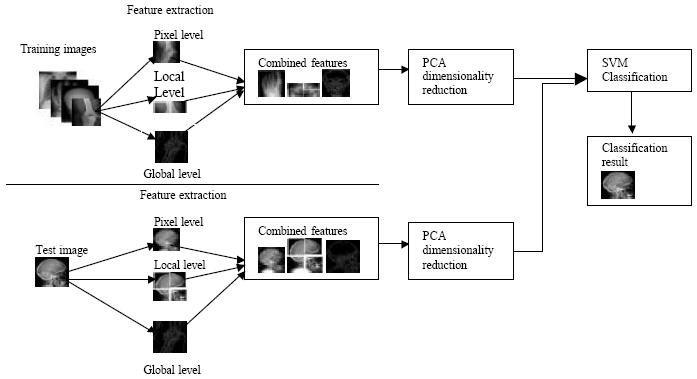 | |
| Fig. 2: | Classification using three level features |
The co-occurrence matrix is constructed by getting information about the orientation and distance between the pixels. Many texture features can be extracted from this gray level co-occurrence matrix (Acharya, 2005). For this task four co-occurrence matrixes for four different orientations (0°, 45 °, 90°, 135°) are obtained. Several texture measures may be directly computed from the gray level co-occurrence matrix (Haralick et al., 1973). We computed Contrast, Energy, Homogeneity and Entropy from each image.
Shape features: Shape provides geometrical information of an object in image, which do not change even when the location, scale and orientation of the object are changed. Canny edge operator (Canny, 1986) is used to generate edge histograms.
Combine visual features: The dataset consists of 10000 images, divided 9000 training images and 1000 test images. All the images are scaled down to 100x100 pixels. In global feature vector texture and shape features are combined to get 53 dimension (16 texture +37 edge) feature vector. Local features are obtained by dividing image in to four non-overlap patches and get same 53 dimensions feature set from each patch, which makes the size of local feature vector 212. Resizing image to 15x15 for pixel level information that produced a feature set of size 225. The total dimensionality of feature vector per image is 490 dimensional feature vectors (53 dimensions for global level, 212 dimensions for local and 225 dimensions for pixel level). As the dimensionality of our feature vector is very high we need to apply some dimensionality reduction techniques. Principal Component analysis (PCA) is a method for dimensionality reduction. PCA is very effective and competent way of dimensionality reduction.
Support vector machine: For several classification applications (Wang et al., 2002), SVM have been shown to provide better generalization performance than techniques such as neural networks (Scholkof et al., 1997). SVM constructs a binary classifier from a set of training samples (x1......xn), and each sample belongs to a class labeled.![]() SVM use hyperplanes in order to separate the two classes. SVM select the hyperplane that causes the largest separation among the decision function values for the borderline examples of the two classes. The hyperplane decision function can be written as:
SVM use hyperplanes in order to separate the two classes. SVM select the hyperplane that causes the largest separation among the decision function values for the borderline examples of the two classes. The hyperplane decision function can be written as:
Where the coefficients αi and b are calculated by quadratic programming problem.
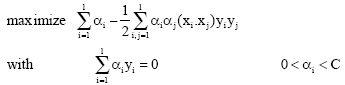 |
C is a regularization parameter, selected by the user.For multi-class classification problems where classes are more then two, there are two general approaches (Hsu and Lin, 2002) one-against-one and one-against-all.
One-against-one: Classifier is calculated from each pair of classes. Using majority voting scheme all classifiers is combined to conclude the final classification.
One-against-all: Classifier is calculated from each class versus all classes and then the first object that is classified as a single class is the class of the unseen data point.
K-nearest neighbors: The k-nearest neighbor pattern classifier is straightforward in concept, but yields good classification accuracy. Let A be a set of labeled feature vectors and B be a set of unlabeled feature vectors. Then the class label of each vector Bi can be said to be equal to the majority class label of the k vectors in A closest to Bi. In our experiments, K is chosen from (Muller et al., 2004).
EXPERIMENT AND RESULT ANALYSIS
Data set consists of 9000 training images under 57 labels and 1000 test images. We decided to take 80% images as training and 20% as test images from each class to ensure each class have representation in training and testing data. Evaluation is done by the formula correctness rate, which is equal to number of correct classified image divided by total number of images.
To show the significance of three level of information experiments are presented in three stages. Comparison of support vector machine and K-nearest neighbor classifiers has been done. Results are obtained using Radial Basis Function (RBF) kernel in support vector machine and k value 3 is used for K-nearest neighbor classifier.
Global level: In first stage, texture and edge features are extracted from each image as a global level image features and classification accuracy with SVM and K-NN classifiers are observed. Recognition rate of 53 and 54% is achieved by K-NN and SVM, respectively. Classes like 2,8,10, 16, etc have 0 classification. This is due to small number of training images available for each class. Global image features are failed to get good accuracy rate for classes 6, 7, 18, 47 etc although these classes have enough number of training images.
The similarity between images is pretty high among these classes, difficult for global features to classify. Figure 3 and 4 shows the result of global level classification of 57 classes.
Local level: Second stage, each image segmented into four non-overlap patches. Local texture and edge information from each patch is extracted using GLCM and canny edge detector, respectively.
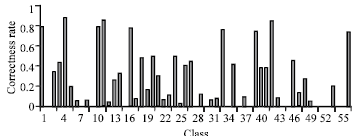 | |
| Fig. 3: | Classification result of global level feature+K-NN |
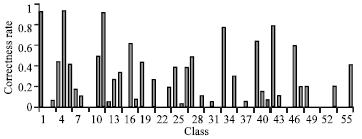 | |
| Fig. 4: | Classification result of global level feature+SVM |
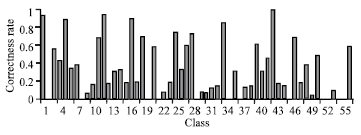 | |
| Fig. 5: | Classification result of local level feature+K-NN |
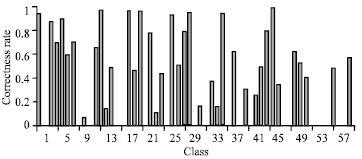 | |
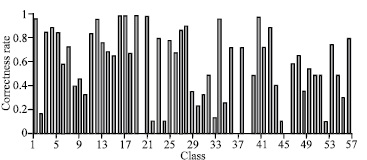
| Fig. 6: | Classification result of local level feature+SVM |
Correctness rate of 63% from K-NN and 73% from SVM attained. There is significant increase in classification accuracy of classes 6,7,18 etc. Local feature can distinguish better among these similar classes than global features. Figure 5 and 6 shows the best result with both classifiers.
Pixel level: In third stage, images are down scaled (15x15) to obtained pixel information as feature. Very good results of 78 and 82% achieved from both K-NN and SVM. Pixel level information provides result for classes, which have less number of training images like classes 2 and 35. Global and local features failed to give results for these classes. Figure 7 and 8 shows the result of two classifiers.
 | |
| Fig. 7: | Classifiction result of pixel level feature+K-NN |
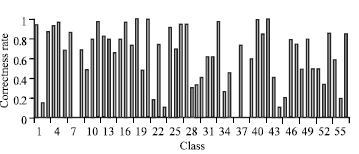 | |
| Fig. 8: | Classification result of pixel level feature+SVM |
 | |
| Fig. 9: | Classification result of combined level feature+K-NN |
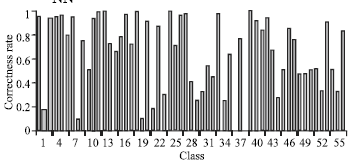 | |
| Fig. 10: | Classification result of combined level feature+SVM |
Combined feature: For final stage all of the three (global, local and pixel) levels combined into one big vector that makes vector size 490. To avoid memory and runtime problem feature set is reduced from 490 to 30 with help of Principal Component Analysis (PCA).
A combined feature vector increases the classification level for almost all the classes as compare to pixel level results.
| Table 1: | Correctness rate different level with two classifiers |
 | |
Figure 9 and 10 provide results of combined feature with two different classifiers. A recognition rate of 89% with SVM classifier and 82% with K-NN classifier is obtained as shown in Fig. 9 and 10. Table 1 shows the Correctness rate (CR) of different level plus combining all the level.
CONCLUSIONS
This research presents a new method directed towards the problem of automatic classification. The proposed approach combines three level of information i.e., global: different medical images like chest and hand x-ray images have substantial difference in their gray scale contrast and structure, local: need regional features to distinguish between different organs and body parts and pixel: pixel information provides good classification results in medical domain (Keyserset al., 2004). By combining three levels of information and an emerging machine learning technology Support Vector Machine (SVM) gave us an accuracy of 89%. In the future, we plan to investigate hierarchical classification by measuring high-level semantic similarity among the images. That helps in retrieval process by finding similar images to a query image.
ACKNOWLEDGMENT
The image data used in this study is courtesy of TM Lehmann, Department of Medical Informatics, RWTH Aachen, Germany.
REFERENCES
- Canny, J., 1986. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell., 8: 679-698.
CrossRefDirect Link - Carson, C., M. Thomas, S. Belongie, J. Hellerstein and J. Malik, 1999. Blobworld: A system for region-based image indexing and retrieval. Proceedings of the 3rd International Conference on Visual Information Systems, June 2-4, 1999, Amsterdam, Netherlands, pp: 509-516.
Direct Link - Colombo, C. and A.D. Bimbo, 1999. Color-induce image representation and retrieval. Pattern Recog., 32: 1685-1695.
Direct Link - Flickner, M., H. Sawhney, W. Niblack, J. Ashley and Q. Huang et al., 1995. Query by image and video content: The qbic system. Computer, 28: 23-32.
Direct Link - Haralick, R.M., K. Shanmugam and I.H. Dinstein, 1973. Textural features for image classification. IEEE Trans. Syst. Man Cybern., SMC-3: 610-621.
CrossRefDirect Link - Kherfi, M.L., D. Ziou and A. Bernardi, 2004. Image retrieval from the world wide web: Issues, techniques, systems. ACM Comput. Surveys, 36: 35-67.
Direct Link - Lim, J.H., S.J. Jesse and Luo-Suhuai, 2005. A structured learning approach to semantic photo indexing and query. Proceedings of the 2nd Asia Information Retrieval Symposium, October 13-15, 2005, Jeju Island, Korea, pp: 351-365.
Direct Link - Muller, H., N. Michoux, D. Bandon and A. Geissbuhler, 2004. A review of content based image retrieval systems in medical applications-clinical benefits and future directions. Int. J. Med. Inform., 73: 1-23.
Direct Link - Pentland, A., R. Picard and S. Sclaroff, 1996. Photobook: Content-based manipulation of image databases. Int. J. Comput. Vision, 18: 233-254.
CrossRefDirect Link - Scholkopf, B., K.K. Sung, C.J.C. Burges, F. Girosi, P. Niyogi, T. Poggio and V. Vapnik, 1997. Comparing support vector machines with Gaussian kernels to radial basis function classifiers. IEEE Trans. Signal Process., 45: 2758-2765.
CrossRefDirect Link - Swain, M.J. and D.H. Ballard, 1991. Color indexing. Int. J. Comput. Vision, 7: 11-32.
CrossRefDirect Link - Turner, M.R., 1986. Texture discrimination by Gabor functions. Biol. Cybern., 55: 71-82.
CrossRefDirect Link - Wang, Y., B.C. Long and G.H. Bao, 2002. Semantic extraction of the building images using support vector machines. Proceedings of 1st International Conference on Machine Learning and Cybernetics, 2002, IEEE Xplore, London, pp: 1608-1613.
CrossRef - Hsu, C.W. and C.J. Lin, 2002. A comparison of methods for multi-class support vector machines. IEEE Trans. Neural Networks, 13: 415-425.
CrossRef