
E. Eyduran
Department of Animal Science, Biometry Genetics Unit, Faculty of Agriculture,
University of Y�z�nc� Yil, 65080 Van, Turkey
T. Ozdemir
Department of Animal Science, Biometry Genetics Unit, Faculty of Agriculture,
University of Y�z�nc� Yil, 65080 Van, Turkey
E. Alarslan
Department of Animal Science, Biometry Genetics Unit, Faculty of Agriculture,
University of Y�z�nc� Yil, 65080 Van, Turkey
Journal of Applied Sciences
Year: 2005 | Volume: 5 | Issue: 10 | Page No.: 1792-1796







ABSTRACT
The aim of this study was to obtain some valuable information from different diagnostics in Multiple Regression Analysis (MRA). Sample data set was composed of live weights at different periods (birth weight (X1), live weights in 30th (X2), 45th(X3), 60th (X4) and 75th (Y) days) of 18 Hamdani breed single-male lambs born in early March of 2001. According to results of MRA, although all independent variables including in model explained approximately 92% of variation in dependent variable, Y, the effect of only independent variable X4 on dependent variable Y was significant (p<0.01). With respect to residual analysis, it could be said that the assumptions of normal distribution and homogeneity of error terms in MRA were provided. As the value of Durbin-Watson statistics equaled to 2.31, there was not a sequent correlation among error terms, that is, the assumption that error terms independent from each other was ensured. Considered the leverage and influence diagnostics calculating for observations of sample data set, only two observations (2nd and 16th observations) of all observations-both outliers and potential effective (influence) observations- should be carefully examined. It could be concluded that diagnostics would be an important statistics for researchers because they could give an idea about whether the basic assumptions would be provided for reliability of MRA, data set and goodness of fit.
PDF Abstract XML References Citation
How to cite this article
E. Eyduran, T. Ozdemir and E. Alarslan, 2005. Importance of Diagnostics in Multiple Regression Analysis. Journal of Applied Sciences, 5: 1792-1796.
DOI: 10.3923/jas.2005.1792.1796
URL: https://scialert.net/abstract/?doi=jas.2005.1792.1796
DOI: 10.3923/jas.2005.1792.1796
URL: https://scialert.net/abstract/?doi=jas.2005.1792.1796
INTRODUCTION
Multiple Regression Analysis (MRA) is commonly used in all science fields. As being in other analysis techniques, MRA should be provided with some assumptions for reliable estimation of parameters: expected value of residual terms should be zero; residual terms should have a normal distribution; residual terms should be independent from each other; observation number should be more than parameter number; there should not be multicollinearity between or among independent variables[1,2].
The aim of MRA is to find the best set of the independent variables which can explain dependent variable on condition that the assumptions are provided[1,3]. Diagnostics are analysis techniques that given an idea about determining levels of unfavorable cases such as lack of model and heterogeneity of variances which can be encountered in data set[1,3,4].
This paper dealt with some problems by using diagnostics mentioned below. Therefore, the aim of this study was to obtain some valuable information from different diagnostics in Multiple Regression Analysis (MRA).
MATERIALS AND METHODS
Materials of this study were composed of 18 male-single lambs randomly selected from Hamdani lambs raised in Van province of Turkey. Data of body weights at different periods (birth weight, body weights at 45th, 60th and 75th days) of the lambs were recorded. The data set was analyzed by using SAS program[5].
MRA is used to explain effects of independent variables on dependent variables. Model of MRA can be written as follows:
| (1) |
Where, Y, dependent variable; X1,X2...Xk are independent variables, β0, β1, β2...βk (regression coefficients (slopes) and εi random error.
Equation 1 can be rewritten as Y=Xβ + ε in matrix notation where X, design matrix; β, coefficients vector of regression coefficients and ∈, vector of random error. Regression coefficients can be estimated by Ordinary Least Square (OLS) Method. The method is based on minimizing ![]() difference between observed Y values with predicted
difference between observed Y values with predicted ![]() values
values ![]() is solved by using OLS then β0, β1, β2,....βk were calculated[2].
is solved by using OLS then β0, β1, β2,....βk were calculated[2].
Diagnostics: Regression diagnostics are statistics used for detecting problems which are encountered in model or data set[1,3]. Let’s examine Diagnostics by turns.
Leverage points diagnostics: The diagnostics composed of residual Analysis, standardized residuals, studentized residuals and Hat matrix.
Residual analysis: Residual, difference between observed Y values with predicted ![]() values, denotes by ei. The term can be obtained by Eq. 2. The assumptions that variance and expected values of error terms in MRA should be fixed, which is denoted by var (e) = σ2I and E (e) = 0 [2,4,6].
values, denotes by ei. The term can be obtained by Eq. 2. The assumptions that variance and expected values of error terms in MRA should be fixed, which is denoted by var (e) = σ2I and E (e) = 0 [2,4,6].
| (2) |
Standardized residuals: The diagnostic, which is denoted by ri, the ratio of each residual to standard deviation of all residuals[1-4, 6], can be written as follows:
| (3) |
Where, ei is residual, s term is the root of means squares of error and diagonal elements of hat matrix, hii.
Studentized residuals: Each residual is standardized with standard deviation which is calculated after it is released out of calculation[1-4,6]. After the ith observation is removed from data set, variance for ith residual is denoted by s2(i), estimating from the rest of data set. s2(i) can be calculated below:
| (4) |
Thus residual value converted to Student’s t, denotes by ri* and can be written follow as:
| (5) |
In application[1], Eq. 5 can be expressed as Eq. 6:
| (6) |
The ith observation is an outlier if |ri*| > 1.96 or |ri*| > 2 The ei, ri and ri* values are based on studies related to effectiveness of model estimation[3,4]. In most observations, these three values can have similar results. It was reported that studentized residuals can be used as appropriate criterion in point of size of residuals[1,2].
Hat matrix: Consider a matrix H;
| (7) |
Where, X is data matrix containing independent variables. First column of matrix X is only 1’s corresponding to intercept and matrix XT is transpose of matrix X. The Eq. 7 is called as Hat Matrix whose diagonal elements are denoted by hii.
The hii value is an indicator of the leverage of data point concerning ith observation from space centre of X variables (X1, X2…Xn). In other words, the value, which ranges from 0 to 1[2,4] as well as lies between 1/n and 1/r according to other author where n, is the number of observations and r is the number of ith observation and/or is shown whether ith observation will be an outlier in a space of X variables[6].
The critic value or cut-off value for the statistics is 2 p’/n where the number of parameters or independent variables and regression constant (intercept =1), respectively, is denoted by p’ and p. For instance, let’s we have 3 independent variables in a model. The number of parameters estimated equals to p’ = 3+1 = 4. Observations whose hii values are larger than 2 p’/n values can be expressed as outliers in place of X variables[1-4].
Durbin-Watson: The statistics whose optimum value ranges from 2 to 4 is used in determining sequent correlation among residuals[1-4,6,7] and is calculated as:
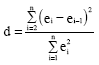 | (8) |
Calculated value of Durbin-Watson statistics is compared with the table value(s) containing the cut-off values for the statistics[4].
Influence statistics: The influence diagnostics comprised of Cook Distance, Differences between the fits (DFFITS), Differences between the betas (DFBETAS) and Covariance ratio (COVRATIO).
Cook’s distance: Cook’s distance is shown the combined effects of ith observation on all regression coefficients. Observations whose values are larger than the cut off value for Cook’s distance, 4/n, can be expressed as influential observations and said to be ![]() effective on. The statistics can be calculated by Eq. 9:
effective on. The statistics can be calculated by Eq. 9:
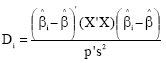 | (9) |
Where ![]() , is calculated in the event of deletion of ith observation and the other is normally calculated[1-4].
, is calculated in the event of deletion of ith observation and the other is normally calculated[1-4].
Differences between the fits (DFFITS): The statistics is given the changes of predicted ![]() is given when ith observation is ignored and its expression can be written as follows:
is given when ith observation is ignored and its expression can be written as follows:
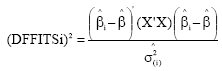 | (10) |
The cut value for the statistics is ![]() and if DFFITS value of ith observation is larger than the cut value, it can be said to be effective of the observation on
and if DFFITS value of ith observation is larger than the cut value, it can be said to be effective of the observation on ![]()
As there is a close association between the statistics and Cook’s distance, results of both statistics are similar[1-4,6].
Differences between the betas (DFBETAS): The statistics is based on measured influence of ith observation on each regression coefficient and obtained from standardized differences between ![]() and
and ![]() .
.
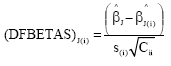 | (11) |
Where, ![]() is obtained from ignored to ith observation.
is obtained from ignored to ith observation.
The cut off value for DFBETAS is ![]() and if DFBETAS value of ith observation is larger than it, it can be said to be effective of ith observation on j. regression coefficient[1-4,6].
and if DFBETAS value of ith observation is larger than it, it can be said to be effective of ith observation on j. regression coefficient[1-4,6].
Covariance ratio (COVRATIO): The statistics is the ratio of determinant of variance-covariance matrix calculated when ith observation is omitted to determinant of variance-covariance matrix calculated when all observations are considered.
The ratio, if closes to 1, influences of ith observation on regression coefficients is small. If the ratio is larger than 1, its influence is larger compared to approximate ratio of 1.
The cut off values for COVRATIO are expressed as COVRATIOi ≥ 1+3 p’/n or COVRATIOi ≤ 1-3 p’/n[1-3,6].
RESULTS AND DISCUSSION
Descriptive statistics of live weights at different periods of Hamdani breed 18 male-single randomly selected lambs born in early March of 2001 are presented in Table 1.
As examining in Table 2, correlations between different pairs of independent variables were more significant and much higher which showed an evidence for multicolinearity[1-4].
As shown in Table 3, the ratio of model explanation was 0.9186% in case of all being independent variables in model. In case of reliability of model, with coefficient of determination is much higher, assumptions (homogeneity of variance, expected value of error is zero) should be provided[1-4]. Because of context of assumptions and reasons mentioned, it is inevitable that the diagnostics should be taken into account for MRA. The effect of only 60th live weight as independent variable on 75th live weight was significant. Besides, with respect to result of stepwise elimination method that the most ideal set of independent variables was determined; the effect of only 60th live weight on 75th live weight was significant.
The statistics related to residuals analysis such as ei, ri and r*i, are used for determining problems which are encountered in data set and model[1,3,4,8].
As examining Table 4, Observation 2 and 16 are outliers with respect to the statistics. It is obviously seen that only two observations of all observations are exceeding the cut off values with ±2.
Although these two observations had unfavorable effects on the assumption mentioned above, it was not correct to remove them from data set[1,3,4].
With respect to hii statistics, only the 2nd observation can potentially affect the regression analysis in point of X value. As examined Cook’s D and DFFITS, it is said that only observations 2nd and 16th on the results related to all regression coefficients can be effective. The Cook’s and DFFITS had similar results which were in consistent with those reported by other authors[3,4].
| Table 1: | Descriptive statistics of live weights at different periods |
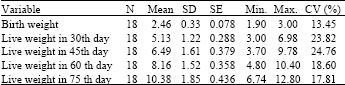 | |
| Table 2: | Correlation between all pair of variables |
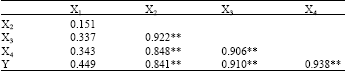 | |
| * : p < 0.05, **: p < 0.01 | |
| Table 3: | Results of regression analysis related to estimation of parameters |
 | |
| Model R2 value : 0.9186 Model (%CV) : 5.81 | |
| Table 4: | Results of residuals analysis concerning each observation |
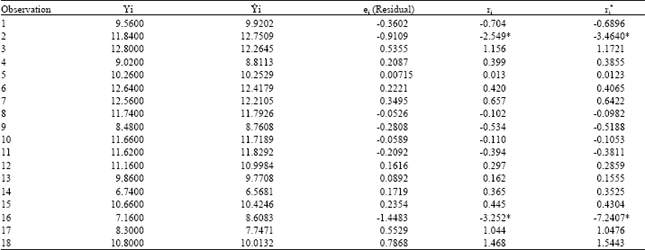 | |
| Table 5: | The cut off formulas and their values of influence statistic |
 | |
| Table 6: | Values of potential effective observation in point of influence statistics |
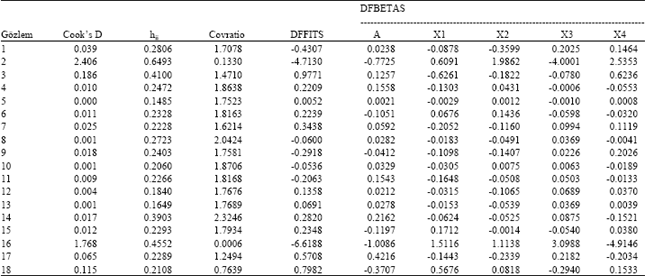 | |
The cut off formulas and their values concerning the statistics are presented in Table 5. Based on the cut off values of Table 5, the values of potential effective observations in point of influence statistics are given in Table 6.
As to COVRATIO statistics, six observations (2, 4, 8, 10, 14 and 16) on fitted or predicted values were ![]() potential effective.
potential effective.
According to DFBETAS statistics, 2nd and 6th observations which were potentially effective influenced on intercept and all regression coefficients.
Durbin-Watson value for the data set was 2.31 which means that auto-correlation among residuals was not exist.
As a result, if points of observations with large leverage (outlier) are influential or potential, the observations (observation 2 and 16) should be carefully examined by researcher[4].
CONCLUSIONS
The aim of MRA is to determine the best set of independent variables most efficiently explaining variation of dependent variable, which is based on realizing the assumptions of MRA mentioned in introduction section. Diagnostics are given an idea about whether the basic assumptions will be provided or whether results of MRA will be reliable.
The most important results from this study can be summarized as;
Plot of residuals ei versus fitted values gives an idea about whether assumptions of normal distribution and homogeneity of error terms will be supplied. In other words, the value of each residual should be in the interval of ±2 for ensuring the assumptions. Otherwise, ideal transformation as to scatter form of residuals ei versus fitted values should be performed to dependent variable Y.
Being serial correlation among residuals means that residuals is not independent from each other. To provide this, the optimum cut off value of Durbin Watson statistics should be 2 to 4.
Consequently, it could be suggested that it would be useful to employ diagnostics in addition to MRA to make it more reliable due to discussed reasons above.