
Muhammad Mutahir Iqbal
Bahauddin Zakariya University, Multan, Pakistan University of Kent at Canterbury, Kent, U.K.
G.M. Clarke
Bahauddin Zakariya University, Multan, Pakistan University of Kent at Canterbury, Kent, U.K.
Journal of Applied Sciences
Year: 2003 | Volume: 3 | Issue: 5 | Page No.: 280-290







ABSTRACT
A large number of response variables were recorded for a long-term rotation experiment at Central Cotton Research Institute, Multan, Pakistan. Short-listing of the response variables and of treatment combination is usually among the objectives of the analysts for such experiments. A visual extension of the Least Significant Difference Test has been proposed in this paper for screening experimental treatments as well as for screening large number of response variables. A graphical layout of unadjusted coefficient of variation has also been introduced in this paper which provides basis for first short listing of response variable. The methods have successfully been applied to the above-mentioned experiment.
PDF Abstract XML References Citation
How to cite this article
Muhammad Mutahir Iqbal and G.M. Clarke, 2003. Visual Least-Significant-Difference and Visual Coefficient of Variation Methods for Screening of Experimental Treatments for Large Number of Response Variables. Journal of Applied Sciences, 3: 280-290.
DOI: 10.3923/jas.2003.280.290
URL: https://scialert.net/abstract/?doi=jas.2003.280.290
DOI: 10.3923/jas.2003.280.290
URL: https://scialert.net/abstract/?doi=jas.2003.280.290
INTRODUCTION
Least Significance Difference method is widely used for comparing experimental conditions and treatments in various fields of scientific research where statistical designs are used for the conduct of experiments. The method has certain limitations but extreme simplicity of the method makes it very attractive. However the method can not be recommended for the comparisons of treatments when large number of response variables are studied.
For adequate interpretation of the data within specified time frame it is the objective of the researchers to study such response variables that are more informative. Identification of these response variables we call the response variable screening.
Two techniques for response variable screening namely Visual Least Significance Difference (VLSD) and Visual Coefficient of Variation (VCV) have been proposed. The application of these methods has been successfully demonstrated in this paper for an experiment on cotton repeated under the same experimental treatments for 14 seasons in a row where 51 responses were recorded for each of the season.
Visual least significance difference method (VLSD)
The VLSD method can easily be used as a better alternative to LSD test for the reason of compactness and added versatility. To study the inherent variability of the huge sets of data simultaneously the method of VCV can prove to be the best alternative to any technique being used. Moreover, VLSD test along with VCV test can prove to be more useful than any technique available for screening out the less informative response variables.
It is a valid test criterion to compare the pairs of treatment means when these comparisons are planned in advance independently without taking data into account. If such comparisons are made after examining the data then the level of significance will exceed from the preset level. For three independent treatments, the difference between the largest and the smallest means when compared at 5% level of significance will exceed the LSD value about 13% of the times when actually there is no significant difference between the two values. The situation will be more alarming if six treatments are under investigation. In such a case at about 40% of the occasions a non-significant difference between the extreme means will exceed the LSD value; for 10 treatments it will exceed 60% of the times and for 20 treatments it will exceed 90% of the times. It is therefore recommended that the likelihood of the misuse of this simple technique must be kept in the mind by the researcher.
With all the above-mentioned constraints, the LSD technique still enjoys a big popularity. The technique proceeds further by arranging the set of treatment means in ascending (or descending) order and putting lines under every group of treatment means that are not significantly different among each other. Hence it is a technique which divides the whole set of treatments into various internally homogenous subsets of treatments. However this procedure does not either take into account the actual distances between consecutive (in order) treatment means, hence, is not able to depict the internal consistency of the identified homogenous groups of treatment means nor is able to detect how apart the identified groups are. An extension of LSD technique called Visual Least Significant Difference (VLSD) is introduced which operates as follows:
| (i) | the treatment means are arranged in ascending order, |
| (ii) | the value of LSD is calculated in the usual way, |
| (iii) | the VLSD plot is then constructed by drawing a line representing the treatment means, duly annotated to retain the identification, parallel to the horizontal axis at a suitable height, |
| (iv) | another line representing the distance of the LSD value is plotted above the line representing the treatment means. |
| N.B. The scale for both of the lines remains the same. | |
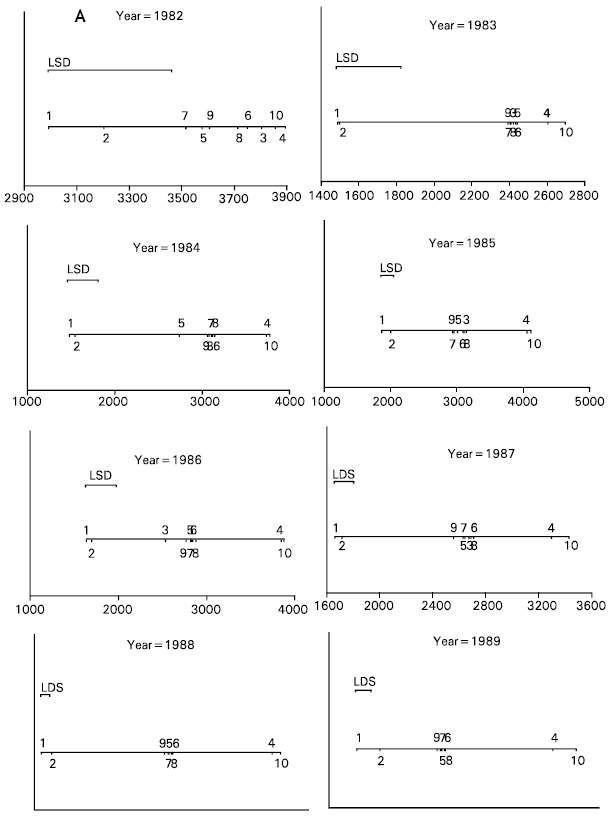
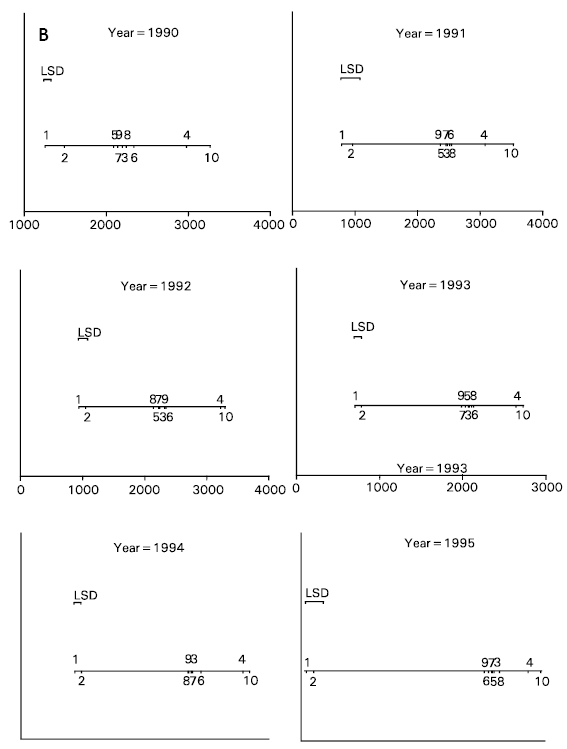
If the LSD line’s distance exceeds the distance between any two treatments means then the effect of the two treatments are judged to be significantly different. The difference between the two distances, i.e. LSD distance and distance between two treatments, will reflect the strength of the conclusion. It will be very straightforward to locate the subsets of treatments, if any, which are internally homogenous. To explain this method LSD technique and VLSD are performed on a dataset for cotton crop with 10 treatments shown in Table 1. Application of this technique has been demonstrated to the experimental data on cotton that was repeated on the same Randomized Complete Block Design with 10 treatments and three replicates experimental treatment for 14 seasons in a row.
A large number of responses were measured, the one we used here is Seed Cotton Yield (SCY). A separate VLSD plot for each of the 14 years is presented in Fig. 1. It is quite easy to observe how VLSD technique can be helpful in studying a large quantity of data more quickly and provides a basis for proposing hypothesis for later studies e.g. throughout the years treatment Nos. 1 and 10 are on the extreme ends whereas treatment Nos. 3, 5, 6, 7, 8 and 9 are grouped in a single cluster which can be considered internally homogenous.
| Table 1: | Treatment Combinations |
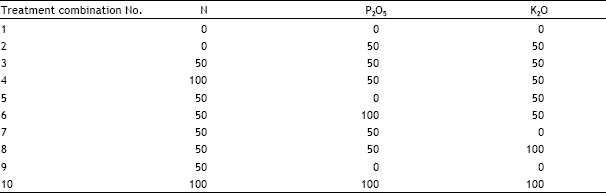 | |
| Table 2: | Responses recorded on cotton plants |
 | |
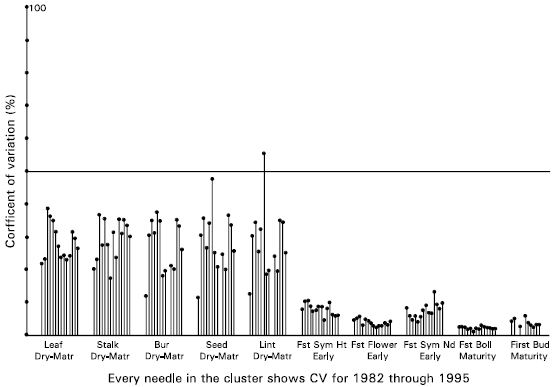 | |
| Fig. 1a: | Coefficients of variation for 10 responses for 14 years relating to Dry Matter Weight, Earliness and Maturity of the crop |
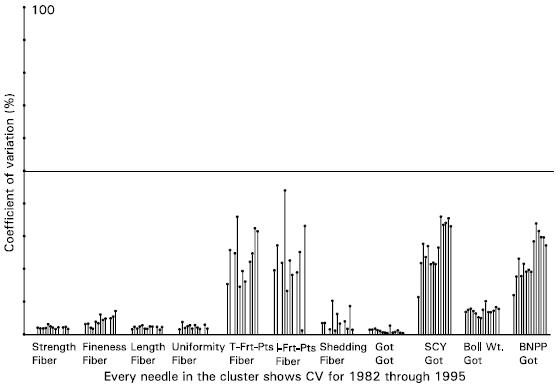 | |
| Fig. 1b: | Coefficients of variation for 11 responses for 14 years relating to Fibre, Fruit and Ginning Out Turn (GOT) |
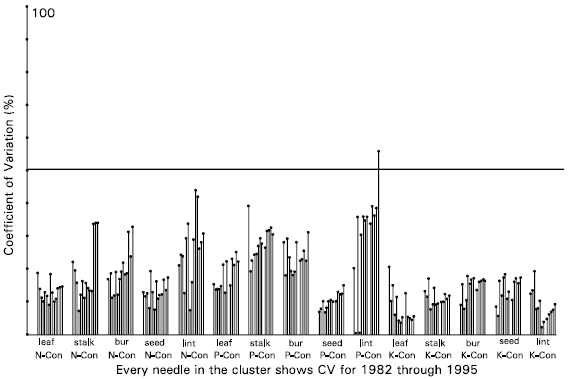 | |
| Fig. 1c: | Coefficients of variation for 15 responses for 14 years Nitrogen (N), Phosphorus (P), Potassium (K) concentration |
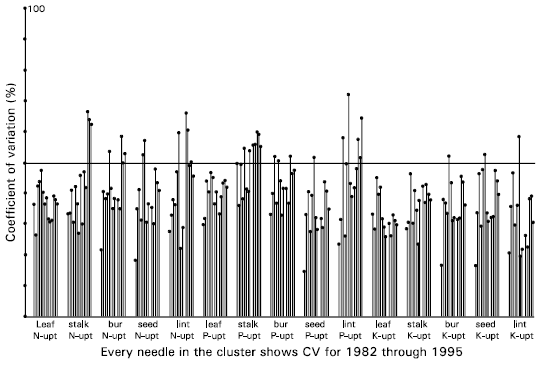 | |
| Fig. 1d: | Coefficients of variation for 15 responses for 14 years Nitrogen (N), Phosphorus (P), Potassium (K) uptake |
It is further to note that the strength of the difference for the years 1984-95 is higher as compared to the years 1982 and 1983. This is visible straight away, as the length of the LSD line for the years 1982-83 is much larger than the rest.
This particular example is of the 14 years’ data from an experiment on cotton, carried out with the same treatment combinations every year. A large number of response variables were recorded and the study trends to search for consistency among groups of treatments was one of the objectives. The experiment under study is a long term rotation experiment on cotton and wheat crop which has been running by the Central Cotton Research Institute (CCRI), Multan, Pakistan since the cotton season of 1981. The main interest lies on the effect of three applied levels of each of Nitrogen (N), Phosphorus (P) and Potassium (K). The season of 1981 was considered as an establishment stage of the experiment and then between 1982-95 several responses were measured. A list of those is shown in Table 2. The response variables include the concentration and uptake of nutrients in various parts of the plant and fruit. For each response, we have the results from the three replications of each treatment combination as the experiment was conducted using RCBD with three blocks for each of the 10 treatment combinations. Since we are interested to look for the trends of an individual treatment combination and also an overall trend of all of them, the VLSD technique has proved to be a useful tool Iqbal (1999), Iqbal and Clarke (in progress).
If the proportion of the LSD value to the range of treatment means of a particular response variable is over 1:3 for most of the years then that variable is set aside. The larger MSE is the main reason for the larger LSD value which is because of the fact that the factors taken under consideration are not enough to explain whole of the systematic component of the variation in the data. If the factors under study are the main source of explaining the systematic variation in the data, the LSD value will be smaller and the chance for detecting the significantly different mean, if any, will be higher as a result, it will also be possible to identify the grouping of treatments based on an explainable criterion.
Among all the total 51 response variables, 28 were set aside on the basis of the application of LSD values and VCV (explained in the next section), the remaining 23 have been studied thoroughly for their behaviour with reference to the time and treatments applied Table 3 give the results related to time while the results for grouping the treatments were established by having a close look at a large number of diagrams similar to one shown in Fig. 1. In the Table 3, a ‘*’ (an asterisk) indicates a higher value of LSD i.e. the ratio of LSD to the range of treatment means is over 1:3. It is easy to identify that the above mentioned ratio for the response variables Nitrogen Concentration in Lint, Phosphorus Concentration in Lint, Potassium Concentration in Lint and Ginning Out Turn (GOT) have a larger value of LSD for most of the years as a result, for the reason stated above, should have been set aside but they were retained in the analysis as they were important due to the commercial values of the variables. The remaining variables do have large values of LSD in the early years of the experiment. This is the period which can be considered as the settling phase. Graphical representation of all these variables was closely examined and observed that treatment Nos. 4, 6, 8 and 10 always appear on the right tail of the VLSD graph i.e. showing higher mean values of the relevant response variable. Thus these treatments are the most influential ones and should be taken into consideration while deciding the conditions for future experimentation.
It is further observed that treatment No. 1 which is a control treatment (i.e. N=0, P=0, K=0) has shown the poorest performance which explores that using a control treatment in such experimentation is just wastage of resources. Another appropriate combination of the applied factors may be used instead.
Visual coefficient of variation (Vcv) for screening response variables
Coefficient of Variation (CV) is a quantity used to measure the spread in relative terms by dividing the sample Standard Deviation (SD) by sample Mean (![]() ). This quantity is used by the experimenter to evaluate results from different experiments conducted under the similar conditions. The main advantage of this quantity is, being a ratio of two averages, its independence from unit of measurement of the data.
). This quantity is used by the experimenter to evaluate results from different experiments conducted under the similar conditions. The main advantage of this quantity is, being a ratio of two averages, its independence from unit of measurement of the data.
The CV is considered to be a measure for reliability in the experiment. It should be noted that the CV varies with the type of data collected and the response variables measured. For field experiments the CV can reach up to 20% but the experiments performed under the controlled conditions can have this value between 5-10% Hoshmand (1993) and Gomez and Gomez (1984). Initial investigation of data, especially for deciding which of the large measured response variables should be included for valid conclusion of the phenomenon under study.
| Table 3: | Response/Years where treatment combinations give similar results |
 | |
  | |
| Fig. 2A-B: | Visual coefficient of variation for all 714 response variable |
The CV calculated without taking into account the adjustment of the factors applied can be very useful to discriminate between the sets of variables which are influenced by the systematic factors and those on which the effect of the applied factor is insignificant. Those with insignificant effects of the factors applied will have smaller CV and those for which the factors applied have significant effect will have larger CV. The method of Visual Coefficient of Variation (VCV) is established for this purpose i.e. screening of the variables to be included in the analyses. The variables with smaller CV will be ignored as are considered to explain the inherent variability without the effect of the factors applied and those with higher CV are retained as the error factor fail to explain the variability of the data which indicates that the systematic error needed to be given due consideration. The method of VCV proceeds as follows:
| (i) | Calcuate the CV by using the formula for each of the 51 response variables for all the 14 years i.e. 714 coefficient of variations. |
| |
| (ii) | The coefficients of variations are graphically presented in the clusters of needles for one response for all the 14 years from 1982 through 1995. The horizontal scale of the graph presents clusters for a number of response variables and the vertical scale presents CV from 0 to 100%. Height of the needle shows the corresponding CV. Since the cut-off point for CV for field experiments is considered to be 20% at the most so a vertical-reference line is drawn at 20%. The variables for which most of the years show the height of the needle below this line will be set-aside or ignored and those which most of the needles cross this reference line will be retained and considered more influenced by the factors applied. Hence will be discussed in detail for the analysis of data. |
Visual Coefficients of Variation for all 714 response variables are presented in Fig. 2. Using the proposed cut-off point of 20%, these graphs suggest to retain Nitrogen Concentration in Lint, Phosphorus Concentration in Stalk, Bur and Lint among those responses which are represented in part a; All 15 responses presented in part b; Total Fruiting Points, Intact Fruiting Points, Seed Cotton Yield and Boll Number Per Plant from part c; and Dry Matter Weight of each of Leaf, Stalk, Bur, Seed and Lint from part d. The proposal from VCV was then blended with the theoretical background and the variables listed in Table 3 were selected for further analysis.
The task of choosing variables for analysis becomes much easier and quicker by having the screening methods presented in this paper. And if these methods are blended with the theoretical background and importance of the response variables, as discussed in the previous section, best results can be expected. By means of adapting SAS facilities, VLSD and VCV has found to be a useful addition to annual analyses of data because they allow similarities or changes among the annual results to be seen very quickly. For a long-term experiment it is much more useful to look at these effects over time and gives a basis for recommending experimental conditions for future experimentation. Handling large amounts of data for several years can be difficult, because similarities between years are not easily noticed without incorporating such methods as proposed in this paper, when there is so much data to be processed. The SAS codes for both of the routines which fully automate construction of these graphs can be had from the first author.
ACKNOWLEDGMENTS
We are grateful to Prof. Asghar Ali, Department of Statistics, Bahauddin Zakariya University, Multan, Pakistan for the suggestions he made on the first draft.
REFERENCES
- Gomez, K.A. and A.A. Gomez, 1984. Statistical Procedures for Agricultural Research. 2nd Edn., John Wiley and Sons Inc., Hoboken, New Jersey, ISBN: 978-0-471-87092-0, Pages: 704.
Direct Link