
S.N. Qasem
Soft Computing Research Group, Faculty of Computer Science and Information System, Universiti Teknologi Malaysia, 81310, Johor, Malaysia
S.M. Shamsuddin
Soft Computing Research Group, Faculty of Computer Science and Information System, Universiti Teknologi Malaysia, 81310, Johor, Malaysia
Journal of Artificial Intelligence
Year: 2010 | Volume: 3 | Issue: 1 | Page No.: 1-16







ABSTRACT
The problem of unsupervised and supervised learning of RBF networks is discussed with Multi-Objective Particle Swarm Optimization (MOPSO). This study presents an evolutionary multi-objective selection method of RBF networks structure. The candidates of RBF networks structures are encoded into particles in PSO. These particles evolve toward Pareto-optimal front defined by several objective functions with model accuracy and complexity. This study suggests an approach of RBF network training through simultaneous optimization of architectures and connections with PSO-based multi-objective algorithm. Present goal is to determine whether MOPSO can train RBF networks and the performance is validated on accuracy and complexity. The experiments are conducted on two benchmark datasets obtained from the machine learning repository. The results show that; the best results are obtained for our proposed method that has obtained 100 and 80.21% classification accuracy from the experiments made on the data taken from breast cancer and diabetes diseases database, respectively. The results also show that our approach provides an effective means to solve multi-objective RBF networks and outperforms multi-objective genetic algorithm.
PDF Abstract XML References Citation
How to cite this article
S.N. Qasem and S.M. Shamsuddin, 2010. Generalization Improvement of Radial Basis Function Network Based on Multi-Objective Particle Swarm Optimization. Journal of Artificial Intelligence, 3: 1-16.
DOI: 10.3923/jai.2010.1.16
URL: https://scialert.net/abstract/?doi=jai.2010.1.16
DOI: 10.3923/jai.2010.1.16
URL: https://scialert.net/abstract/?doi=jai.2010.1.16
INTRODUCTION
Radial Basis Function (RBF) networks form a class of Artificial Neural Networks (ANNs) which has certain advantages over other types of ANNs. Due to their better approximation capabilities, simpler network structures and faster learning algorithms, RBF networks have certain advantages over other types of ANNs and have been widely applied in many science and engineering fields. It has three layers feed forward fully connected network which uses Radial Basis Functions (RBFs) as the only nonlinearity in the hidden layer neurons. The output layer has no nonlinearity, the connections of the output layer are only weighted and the connections from the input to the hidden layer are not weighted (Leonard and Kramer, 1991).
Since, the number of input and output layer neurons is determined from the dimension of data, the model designer can only set the number of hidden layer neuron. Hence the model structure determination is to determine the number of hidden layer neuron. Although, parameter estimation methods such as the backpropagation method are well known, the method of model structure determination has not been established. This is caused by the model complexity (Nelles, 2001). If a model is complex, the generalization ability is low because of its high variance error (Yu et al., 2006). Conversely, if a model is simple, then it can’t represent better correlation between input and output because of high bias error. The learning method with regularization and the model structure selection method using information criteria have been studied by Hatanaka et al. (2001) to take a trade-off about the model complexity into account.
In this study, the construction of the Pareto RBF network set obtained from the perspective of the multi-objective optimization is considered. The set of Pareto optimal RBF networks based on evaluation of approximation ability and structure complexity using evolutionary computations had show good results on multi-objective optimization. The optimal RBF network is constructed from the Pareto set since the obtained Pareto-optimal RBF networks are diverse on its structure and the diversity. The Pareto optimal RBF network is applied to the pattern classification problems.
The objective of this study to design a novel framework based on multi-objective PSO and RBF network for improving generalization and classification accuracy while avoiding over-fitting in data and it compared to multi-objective GA.
RBF NETWORK
Artificial Neural Network (ANN) using Radial Basis Function (RBF) as activation function instead of sigmoid functions is RBF network. The RBF network is constructed of three layers which are the input layer, the hidden layer and the output layer, as shown in Fig. 1. The input layer neuron has a role to transmit data to the hidden layer. The hidden layer neuron calculates value of the basis function by the received data from the input layer and then transmits the value to the output layer. The output layer neuron calculates the linear sum of values of the hidden neuron. In this study, the Gaussian function is used as radial basis functions. Let Φj (x) be the j-th basis function, Φj (x) is represented as follows:
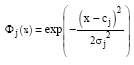 | (1) |
where, x = (x1, x2. . . xd)T is the input vector, cj = (c1j , c2j,…,cdj)T and σ2j are the j-th center vector and the width parameter, respectively. The output of RBF network y which is the linear sum of basis function, is follows:
| (2) |
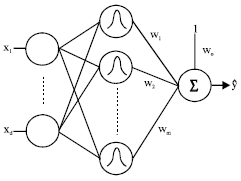 | |
| Fig. 1: | Structure of RBF Network |
where, y is the output of the RBF Network, m is the number of the hidden layer neuron and wj is the weight from jth neuron to the output layer.
In the typical learning of RBF network, the network structure will be determined based on prior knowledge or the experiences of experts and then the parameters are estimated by methods such as the clustering and the least square method. On the other hand, there are approaches in which the network structure and its parameters are estimated by the evolutionary computation (Bai and Zhang, 2002; Wenbo et al., 2002). Such a RBF network is called an evolutionary RBF network.
MULTI-OBJECTIVE OPTIMIZATION OF RBF NETWORK
Generally, a mathematical model has dilemma about model complexity (Nelles, 2001). If a model is complex, then it can fit to data well because it has low bias error, but the variance error become high, so the model generalization ability becomes worse. Moreover, a complex model is not desirable since it is not easy to treat. Conversely, if a model is simple then variance error is small. Such a model can prevent over-learning and the treatment of it will be easy. The learning method with regularization and the model structure selection method using information criteria have been studied by Hatanaka et al. (2001). The trade off about model complexity is expressed by adding a penalty term about model complexity to the error term and using it as evaluation criterion of the model construction and selection. However, there is an alternative approach that solve the above problem by considering the model construction as the multi-objective optimization problem about the model representation ability and the model complexity (Abbass, 2001; Yen and Lu, 2003; Jin et al., 2004). The evolutionary RBF network needs to evolve its structure with consideration of model complexity. By utilizing characteristics of evolutionary algorithms that they are methods of multi-point search, the method obtaining trade-off models has been studied by Yen and Lu (2003) and Kondo et al. (2004).
Neural Networks (NNs) are bio-inspired tools that have been widely used in tasks such as control processes, optimization, pattern recognition, classification, etc. The use of a neural network to solve problem involves selecting the appropriate network model and network structure and then training. These stages often require high computational time and human interaction until the required network is obtained. In case of Radial Basis Function (RBF) networks, the classic training algorithms are limited and so, these tasks may become even more difficult.
Although, there are few studies regarding the implementation of multi-objective RBF network training, but research on training of RBF network with evolutionary multi-objective is still new. Here, some existing work of training RBF network based on multi-objective evolutionary algorithms (MOEAs) is presented.
Kokshenev and Braga (2008) applied multi-objective (MOBJ) optimization algorithm to the problem of inductive supervised learning depended on smoothness based apparent complexity measure for RBF networks. However, the computational complexity of the proposed algorithm is high in comparison with other state-of-the-art machine learning methods. A multi-objective genetic algorithm based design procedure for the RBF network has been proposed by Yen (2006). A hierarchical rank density genetic algorithm (HRDGA) has been developed to evolve both the neural network’s topology and its parameters simultaneously.
Kondo et al. (2006) proposed method in which RBF network ensemble has been constructed from Pareto-optimal set obtained by multi-objective evolutionary computation. Pareto-optimal set of RBF networks has been obtained by multi-objective GA based on three criteria, i.e., model complexity, representation ability and model smoothness and RBF network ensemble has been constructed. Lefort et al. (2006) applied new evolutionary algorithm, the RBF-Gene algorithm to optimize RBF networks. Unlike other works, their algorithm can evolve both from the structure and the numerical parameters of the network: it is able to evolve the number of neurons and their weights.
Gonzalez et al. (2001) presented optimizing RBF network from training examples as a multi-objective problem and an evolutionary algorithm has been proposed to solve it. Their algorithm incorporates mutation operators to guide the search to good solutions. A method of obtaining Pareto optimal RBF network set based on multi-objective evolutionary algorithms has been proposed by Kondo et al. (2007) to solve nonlinear dynamic system identification problem. RBF networks are widely used as model structure for nonlinear systems. The determination of its structure that is the number of radial basic functions and the tradeoff between model complexity and accuracy exists. On the other hand, Ferreira et al. (2005) proposed a multi-objective genetic algorithm to the identification of RBF network couple models of humidity and temperature in a greenhouse. Two combinations of performance and complexity criteria were used to guide the selection of model structures, resulting in distinct sets of solutions.
Unlike previous studies mentioned earlier, this study shares the problem of unsupervised learning and supervised learning of RBF network with multi-objective PSO which evolve toward Pareto-optimal front defined by several objective functions with model accuracy and complexity to improve generalization while avoiding over-fitting on data.
MULTI-OBJECTIVE OPTIMIZATION PROBLEM
Many real-world problems involve simultaneous optimization of several objective functions. Generally, these functions are often conflicting objectives. Multi-objective optimization with such conflicting objective functions gives rise to a set of optimal solutions, instead of one optimal solution. The reason for the optimality of many solutions is that no one can be considered to be better than any other with respect to all objective functions. These optimal solutions are known as Pareto-optimal solutions.
A general multi-objective optimization problem consists of a number of objectives to be optimized simultaneously and is associated with a number of equality and inequality constraints. It can be formulated as follows:
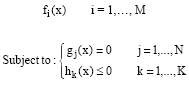 | (3) |
where, fi is the ith objective function, x is a decision vector that represents a solution and M is the number of objectives.
For a multi-objective optimization problem, any two solutions x1 and x2 can have one of two possibilities- one dominates the other or none dominates the other. In a minimization problem, without loss of generality, a solution x1 dominates x2 iff the following two conditions are satisfied:
| (4) |
The solutions which are not dominated by any other solutions are called the Pareto-optimal solution or non-dominated solution. Generally many Pareto-optimal solutions exist. The set of Pareto-optimal solutions is called Pareto optimal front. A non-dominated set is required to be near to the true Pareto front and distributed uniformly.
PARTICLE SWARM OPTIMIZATION
Particle Swarm Optimization (PSO) is a population based stochastic optimization technique developed by Kennedy and Eberhart (1995), inspired by social behavior of bird flocking or fish schooling, in which each individual is treated as an infinitesimal particle in the n-dimensional space, with the position vector and velocity vector of particle i being represented as Xi(t) = (Xi1(t), Xi2(t),…., Xin(t)) and Vi(t) = (Vi1(t), Vi2(t),…., Vin(t)). The particles move according to the following equations:
| (5) |
| (6) |
I = 1,2,…, M ; d = 1,2,…,n
where, c1 and c2 are the acceleration coefficients, Vector Pi = (Pi1, Pi2,…, Pin) is the best previous position (the position giving the best fitness value) of particle i known as the personal best position (pbest); Vector Pg = (Pg1, Pg2,…, Pgn) is the best position among the personal best positions of the particles in the population and is known as the global best position (gbest). The parameters r1 and r2 are two random numbers distributed uniformly in (0, 1). Generally, the value of Vid is restricted in the interval [-Vmax, Vmax]. Inertia weight w was first introduced by Shi and Eberhart in order to accelerate the convergence speed of the algorithm (Shi and Eberhart, 1998).
MULTI-OBJECTIVE PARTICLE SWARM OPTIMIZATION ALGORITHM
A particle swarm algorithm for the solution of multi-objective problems was presented by (Coello and Lechuga, 2002). In MOPSO, in contrast PSO, there are many fitness functions. Differently from PSO, in MOPSO there is no global best, but a repository with the non-dominated solutions found.
The MOPSO (Raquel and Naval, 2005) extends the algorithm of the single-objective PSO to handle multi-objective optimization problems. It incorporates the mechanism of crowding distance computation into the algorithm of PSO specifically on global best selection and in the deletion method of an external archive of non-dominated solutions (Fig. 2). The crowding distance mechanism together with a mutation operator maintains the diversity of non-dominated solutions in the external archive. This algorithm also has a constraint handling mechanism for solving constrained optimization problems.
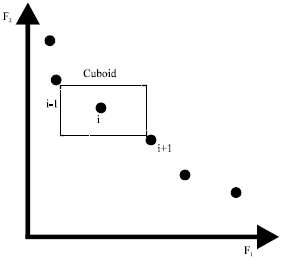 | |
| Fig. 2: | Crowding distance computation |
The MOPSO algorithm is presented below:
MOPSO Algorithm
BEGIN
Input: Optimization problem
Output: Non-dominated solutions in archive (A)
 |
 |
END
ELITIST NON-DOMINATED SORTING GENETIC ALGORITHM (NSGA-II)
The capabilities of multi-objective genetic algorithms (MOGAs) to explore and discover Pareto optimal fronts on multi-objective optimization problems have been well recognized. It has been shown that MOGAs outperform traditional deterministic methods due to their capacity to explore and combine various solutions to find the Pareto front in a single run. We will implement a multi-objective optimization technique called the non-dominated sorting genetic algorithm II (NSGA-II) (Deb et al., 2002) to RBF network training. The NSGA-II algorithm may be stated as follows:
| 1. | Create a random parent population of size N |
| 2. | Sort the population based on the non-domination |
| 3. | Assign each solution a fitness (or rank) equal to its non-domination level (minimization of fitness is assumed) |
| 4. | Use the usual binary tournament selection, recombination and mutation operators to create a new offspring population of size N |
| 5. | Combine the offspring and parent population to form extended population of size 2N |
| 6. | Sort the extended population based on non-domination |
| 7. | Fill new population of size N with the individuals from the sorting fronts starting from the best |
| 8. | Invoke the crowding comparison operator to ensure diversity if a front can only partially fill the next generation |
| 9. | Repeat the steps (2)-(8) until the stopping criterion is met. The stopping criterion may be a specified number of generations |
It is clear from the above description that NSGA-II uses (i) a fast non-dominated sorting approach, (ii) an elitist strategy and (iii) no niching parameter (Deb et al., 2002).
HYBRID LEARNING OF RBF NETWORK BASED ON MOPSO
The proposed algorithm called RBFN-MOPSO is a multi-objective optimization approach to RBF network training with MOPSO as the multi-objective optimizer. The algorithm will simultaneously determine the set of connections and its corresponding architecture by treating this problem as a multi-objective minimization problem. In this study, a particle represents a one-hidden layer RBF network and the swarm consists of a population of one-hidden layer networks. We set the number of hidden neurons depended on the problem to be solved.
Parameters and Structure Representation
The RBF network is represented as a vector with dimension D contains the connections. The dimension of a particle is:
| (7) |
where I, H and O are refer to the number of input, hidden and output neurons respectively. The centers of RBF are initialized from k-means clustering algorithm and the connection weights of RBF network are initialized with random values. The number of input and output neurons is problem-specific and there is no exact way of knowing the best number of hidden neurons. We set the number of hidden neurons (RBFs) depended on the number of clusters (classes) of the problem to be solved.
RBFN-MOPSO
RBFN-MOPSO starts by collecting, normalize and reading the dataset. This is followed by setting the desired number of hidden neurons and the maximum number of generation for MOPSO. The next step is determining the dimension of the particles and initializing the population with fully-connected feed-forward RBF network. In each generation, every particle is evaluated based on the two objective functions and after the maximum generation is reached, the algorithm outputs a set of non-dominated Pareto RBF networks. Figure 3 shows the description of proposed study.
Objective Functions
Two objective functions are used to evaluate the RBF network particle’s performance. The two objective functions are:
| (8) |
| • | Accuracy based on Mean-Squared Error (MSE) on the training set where okj and tkj are the model output and the desired output, respectively and N is the number of data pairs in the training data |
| • | Complexity based on the sum of the squared weights which is based on the concept of regularization and represents the smoothness of the model |
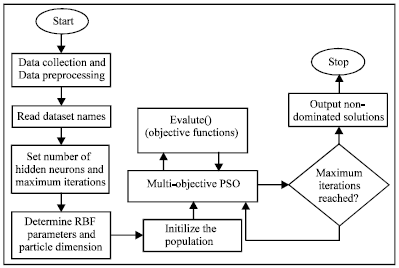 | |
| Fig. 3: | The description of the proposed study RBFN-MOPSO |
| (9) |
where wj, j=1... M is a weight in the network mode and M is the number of weights in total.
EXPERIMENTAL STUDIES
To evaluate the performance of RBFN-MOPSO, several experiments were conducted on two data sets are listed in Table 1. All data sets have been loaded from the machine learning benchmark repository (Asuncion and Newman, 2007). These problems have been the subjects of many studies in ANNs and machine learning.
| Table 1: | Description of data sets |
 | |
Experimental Setup
In this study, all data sets are partitioned into three sets: a training set, a validation set and a testing set. The validation set is used to select the best one from the Pareto optimal solutions, while the testing set is used to test the generalization performance of Pareto RBF network. It is known that the experimental results may vary significantly for different partitions of the same data set.
| Table 2: | Parameters settings for RBFN-MOPSO |
 | |
In the experiment, we analyze the evolutionary process of RBFN-MOPSO and evaluate the performance of it on breast cancer and diabetes data sets and compare with RBFN-NSGA-II. To do so, we partitioned the data sets sequentially as follows:
| • | For the breast cancer data set, 50% of data (i.e., 349 examples) were used for the training set, 25% of data (i.e., 175 examples) for the validation set and the rest (i.e., 175 examples) for the testing set |
| • | For the diabetes data set, 50% of data (i.e., 384 examples) were used for the training set, 25% of data (i.e., 192 examples) for the validation set and the rest (i.e., 192 examples) for the testing set |
For each data set, the experiments were implemented to minimize the influence of random effects. Each experiment uses a different randomly generated initial population. In addition, the number of input and output nodes is problem-dependent but the number of hidden nodes is the number of classes (clusters) of data. The number of iterations is the same for all algorithms. There are some parameters in MOPSO which need to be specified by the user. Therefore, these parameters were set to the same for all data sets: the number of generations (1,000), the inertia weights wmax and wmin (0.7 and 0.4), the initial acceleration coefficients c1 and c2 (1.5). The other various parameters settings of RBFN-MOPSO are presented in Table 2.
RESULTS AND DISCUSSION
Here, the results of study on RBF network based on MOPSO are presented. The experiments are conducted using two data sets. The results for each dataset are analyzed based on the convergence to Pareto optimal set and classification results. One advantage of evolutionary multi-objective optimization approach to RBF network generation is that accuracy of RBF networks with complexity can be obtained in one single run.
Table 3 and 4 showed that the best results of RBF network based on MOPSO algorithm on training, validation and testing in terms of convergence to error and classification accuracy for the breast cancer and diabetes data sets respectively. The result of this algorithm is Pareto optimal solutions to improve the generalization on unseen data. We report the results in terms of error and correct classification for the two data sets. Figure 4a and b demonstrated that MOPSO has the capability to evolve compact RBF networks which generalize well on unseen data while avoiding over-fitting on data.
In order to evaluate the performance of RBFN-MOPSO under generalization and classification, the comparison was carried out by using RBFN-NSGA-II in terms of convergence to error and classification accuracy for all data sets. Table 3 also showed that the results of RBFN-NSGA-II on training, validation and testing in terms of convergence to error for all data sets respectively.
| Table 3: | Results of RBFN-MOPSO and RBFN-NSGA-II for all data sets |
 | |
| Table 4: | Classification results of RBFN-MOPSO and RBFN-NSGA-II for all data sets |
 | |
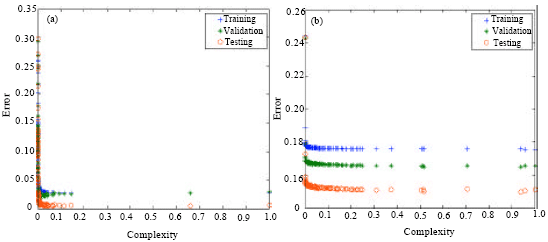 | |
| Fig. 4: | Pareto front obtained using RBFN-MOPSO for data, (a) Breast cancer and (b) Diabetes |
Figure 5a and b illustrated that Pareto front obtained using RBFN-NSGA-II for breast cancer and diabetes data sets respectively. From Table 3 and Fig. 5, the RBFN-NSGA-II results are weak for all data sets because the test error has the trend to oscillate even when the complexity increases. This event can be considered as that the resulting networks are over-fitted. From the comparison, Fig. 4-6 showed that RBFN-MOPSO is better than RBFN-NSGA-II in convergence to Pareto front solutions and improved generalization while avoiding over-fitting for all data sets.
When, we minimize both error and complexity of the network in multi-objective approach, we are able to achieve a number of Pareto optimal solutions with complexity ranging from simple networks to highly complex ones. From all data sets, we can conclude that by trading off accuracy against complexity, the Pareto based multi-objective optimization algorithm is able to find the simplest structures that solve the problem best. Besides, the simple Pareto optimal networks are able to generalize well on unseen data.
Moreover, from Fig. 4-6, we can see that when the network complexity increases, the testing error decreases. This phenomenon can be observed from the results by all of the selected testing approaches.
However, this phenomenon is only partially maintained for the relationship between the test performance and the network complexity. Test error still decreases as the network complexity increases. After that, the test error has the tendency to fluctuate even when value of weights increases. This occurrence can be considered as that the resulting networks are over-fitted in RBFN-NSGA-II.
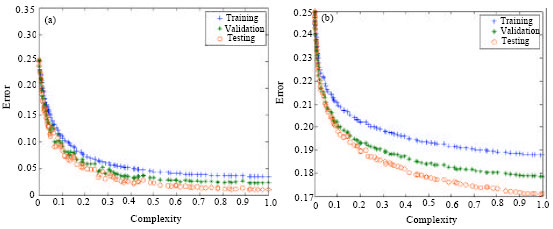 | |
| Fig. 5: | Pareto front obtained using RBFN-NSGA-II for data, (a) Breast cancer and (b) Diabetes |
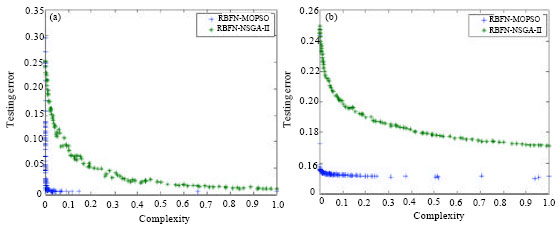 | |
| Fig. 6: | Accuracy versus complexity of Pareto front of testing data for (a) Breast cancer and (b) Diabetes |
Note that RBF network based on NSGA-II solutions are far from the Pareto optimal solutions and therefore it could still be minimized considering both objectives.
From Fig. 6a and b, it is very difficult to find a single optimal network that can offer the best performance for all datasets. Therefore, instead of searching for a single optimal RBF network, an algorithm that can result in a near complete set of optimal networks can be more reasonable and applicable option. This is the essential reason that MOPSO algorithms can be justified for this type of neural network design problems.
The classification accuracy results of RBF network based on MOPSO and NSGA-II for breast cancer and diabetes data sets are shown in Table 4. The accuracy in the table refers to the percentage of correct classification on training, validation and testing data sets, respectively.
Figure 7a and b showed that the correct classification of Pareto front solutions for testing data which are produced with RBFN-MOPSO and RBFN- NSGA-II for all data sets. Table 4 showed that RBF networks based on MOPSO have higher classification accuracy than RBFN- NSGA-II for diabetes data set. RBFN-MOPSO has best classification accuracy and maintains diversity of Pareto fronts solutions. However, RBFN-NSGA-II provides competitive classification accuracy compared to RBFN-NSGA-II for breast cancer data set (Fig. 7).
| Table 5: | Results of computational time (in seconds) of RBFN-MOPSO and RBFN-NSGA-II for all data sets |
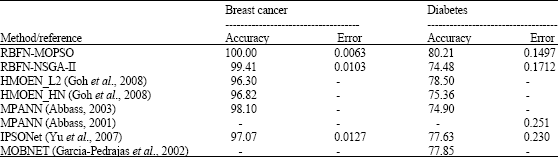
| Table 6: | Comparison between our proposed approach with the various work in terms of testing classification accuracy and testing error and the best results are highlighted in bold |
 | |
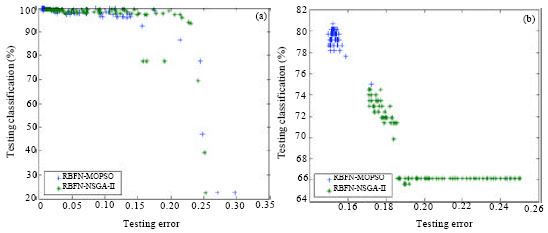 | |
| Fig. 7: | Correct classification of Pareto front of testing data for (a) Breast cancer and (b) Diabetes |
From Table 5, the results show that RBFN-MOPSO is significantly faster convergence time than RBFN-NSGA-II for all datasets. This is attributed to the crowding distance used by MOPSO which can be computed faster than elitism used by NSGA-II.
Having validated the effectiveness of multi-objective optimization, the performances of RBFN-MOPSO and RBFN-NSGA-II are compared against other works in the literature using these data sets. The summary of the results is shown in Table 6. We note that comparisons between the results obtained from different approaches have to be made cautiously, as there are numerous ways in which the experimental and simulation setups are done, for example, the training/testing ratio, the pre/postprocessing, etc. The results that are presented here are not fine-tuned in any manner, i.e., the same parameter and experimental settings are used for all the data sets. Nonetheless, it can be observed that proposed approach is better or at least competitive for breast cancer and diabetes data sets. Breast cancer results are proposed by RBFN-NSGA-II showed that better than HMOEN_L2 (Goh et al., 2008), HMOEN_HN (Goh et al., 2008), MPANN (Abbass, 2003) and IPSONet (Yu et al., 2007) except RBFN-MOPSO in terms of classification accuracy and generalization error while diabetes results is outperformed by HMOEN_L2 (Goh et al., 2008) except RBFN-MOPSO. On the other hand, RBFN-NSGA-II and MPANN (Abbass, 2003) perform poorly for diabetes in term of classification accuracy. In term of generalization error, RBFN-NSGA-II provided smaller error than MPANN (Abbass, 2001) and IPSONet (Yu et al., 2007) except RBFN-MOPSO for diabetes data set. We notice here that RBFN-MOPSO optimized network performance while improving its generalization ability. The results can be observed from Table 6 that the proposed approach RBFN-MOPSO is the best results for all data sets.
CONCLUSION AND FUTURE WORK
In this study, a novel approach for multi-objective optimization based on swarm intelligence principles, called MOPSO, is proposed and applied to develop generalization and classification accuracy for multi-objective RBF network. This study introduces multi-objective PSO approach to RBF network design called Multi-objective PSO-RBF network Optimizer to concurrently optimize the architectures and connections of network. The optimal RBF network is constructed from Pareto front set obtained by MOPSO. RBF network structure and its parameters are encoded to particle and Pareto-optimal set of RBF networks is obtained by MOPSO based on two criteria, i.e. model accuracy and complexity. The benchmark of pattern classification indicates that our proposed method provides better results than multi-objective GA in terms of yielding diverse of solutions along the true Pareto optimal fronts. The main advantages of the proposed MOPSO approach are that it is simple algorithm, faster convergence and yet robust in yielding efficient Pareto frontiers. Hence it can be concluded that, for RBF networks, the proposed technique is a viable tool for multi-objective analysis. Further improvement of the proposed algorithm will be the automatic parameters tuning and structure tuning of RBF network. The proposed method will optimize the network performance and its structure at the same time, in terms of hidden nodes (RBF) and active connections and we will do the cross validation and ROC analysis for data sets in future work.
ACKNOWLEDGMENTS
This work is supported by Ministry of Higher Education (MOHE) under Fundamental Research Grant Scheme (Vote No. 78183). The authors would like to thank Research Management Centre (RMC) Universiti Teknologi Malaysia, for the research activities and Soft Computing Research Group (SCRG) for the support and incisive comments in making this study a success.
REFERENCES
- Abbass, H.A., 2003. Speed up backpropagation using multiobjective evolutionary algorithms. Neural Comput., 15: 2705-2726.
CrossRefDirect Link - Deb, K., A. Pratap, S. Agarwal and T. Meyarivan, 2002. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput., 6: 182-197.
CrossRefDirect Link - Garcia-Perdrajas, N., C. Hervas and J. Munoz-Perez, 2002. Multi-objective cooperative coevolution of artificial neural networks. Neural Netw., 15: 1259-1278.
Direct Link - Goh, C., E. Teoh and K.C. Tan, 2008. Hybrid multiobjective evolutionary design for artificial neural networks. IEEE Trans. Neural Netw., 19: 1531-1548.
CrossRefDirect Link - Kokshenev, I. and A.P. Braga, 2008. A multi-objective approach to RBF network learning. Neurocomputing, 71: 1203-1209.
CrossRefDirect Link - Leonard, J.A. and M.A. Kramer, 1991. Radial basis function networks for classifying process faults. Cont. Syst. Mag., 11: 31-38.
CrossRefDirect Link - Raquel, C.R. and P.C. Naval, 2005. An effective use of crowding distance in multiobjective particle swarm optimization. Proceedings of the Conference on Genetic and Evolutionary Computation, Jun. 25-29, ACM, New York, USA., pp: 257-264.
CrossRefDirect Link - Shi, Y. and R. Eberhart, 1998. A modified particle swarm optimizer. Proceedings of the World Congress on Computational Intelligence and IEEE International Conference on Evolutionary Computation, May 4-9, 1998, Anchorage, AK., pp: 69-73.
CrossRefDirect Link - Yen, G.G. and H. Lu, 2003. Hierarchical rank density genetic algorithm for radial-basis function neural network design. Int. J. Comput. Intell. Appl., 3: 213-232.
CrossRefDirect Link - Yu, J., L. Xi and S. Wang, 2007. An improved particle swarm optimization for evolving feedforward artificial neural networks. Neural Proc. Lett., 16: 217-231.
CrossRefDirect Link