
Xiangqian Feng
Department of Management Science and Engineering, School of Computer Science and Technology, Nanjing Normal University 210046, China
Xiaohua Qian
Department of Management Science and Engineering, School of Computer Science and Technology, Nanjing Normal University 210046, China
Qiang Wu
Department of Management Science and Engineering, School of Computer Science and Technology, Nanjing Normal University 210046, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 12 | Page No.: 1764-1769







ABSTRACT
A new method to solve multi-attribute decision making problem with Intuitionistic Fuzzy (IF) information is given here. This method is based on the Dempster Shafer-Analytical Hierarchy Process (DS-AHP) theory. The DS-AHP theory can solve a problem directly based on the decision matrix which is different from most of current methods. But in reality, the decision maker may provide several types of uncertain information such as fuzzy or interval values. So, the original DS-AHP method is combined with the IF information here. The expected utility is used to transform decision matrix with intuitionistic fuzzy information which is obtained from assessment. And then a non-linear optimization model is used to combine all the attributes. Using the combined results, the rank of the alternatives can be finally got. At the end of the paper a numerical example is studied to illustrate the details.
PDF Abstract XML References Citation
Received: February 02, 2012;
Accepted: July 09, 2012;
Published: August 29, 2012
How to cite this article
Xiangqian Feng, Xiaohua Qian and Qiang Wu, 2012. A DS-AHP Approach for Multi-attribute Decision Making Problem with Intuitionistic Fuzzy Information. Information Technology Journal, 11: 1764-1769.
DOI: 10.3923/itj.2012.1764.1769
URL: https://scialert.net/abstract/?doi=itj.2012.1764.1769
DOI: 10.3923/itj.2012.1764.1769
URL: https://scialert.net/abstract/?doi=itj.2012.1764.1769
INTRODUCTION
Multi-attribute Decision Making (MADM) is concerned with the elucidation of the levels of preference of decision alternatives, through judgments made over a number of criteria. Many complex MADM problems are characterized with both quantitative and qualitative-of preference of decision alternatives, through judgments made over a number of criteria. Many complex MADM problems are characterized with both quantitative and qualitative-attributes. For instance, the design evaluation of an engineering product may require the simultaneous consideration of several attributes such as cost, quality, safety, reliability, maintainability and environmental impact; in selection of its suppliers, an organization needs to take into account such attributes as quality, technical capability, supply chain management, financial soundness, environmental and so on. Most of such attributes are qualitative and could only be properly assessed using human judgments which are subjective in nature and are inevitably associated with uncertainties due to the human being's inability to provide complete judgment, or the lack of information, or the vagueness of the meanings about attributes and their assessments. For decades, many MADM methods have been developed, such as Analytical Hierarchy Process (AHP) (Saaty, 1980), TOPSIS (Lan, 2009), ELECTRE, PROMETHEE, LINMAP (Jiang and Fan, 2005) etc. for certain MADA and fuzzy multi-attribute decision making under uncertainty (Wang et al., 2011). AHP has been widely used in many areas such as accounting (Webber et al., 1997), assessment (Wu et al., 2010), programming (Yang and Kuo, 2003), research and development management (Liu and Tsai, 2007) and information management (Liu and Shih, 2005). AHP can be applied under the precondition that the decision maker can make pairwise comparison between decision alternatives. This prerequisite, however, may not be satisfied in practice. For a practical MADM problem, information about decision alternatives may be incomplete because of time pressure, lack of data, intangible of some attributes (Kim and Ahn, 1997, 1999), limitation of attention, or limitations on information processing capabilities (Kahneman et al., 1982), etc. The Dempster-Shafer (DS) theory of evidence (Dempster, 1967; Shafer, 1976) models have both quantitative and qualitative attributes with an appropriate framework. The power of the DS theory in handling uncertainties has found wide applications in many areas such as expert systems (Beynon et al., 2001), diagnosis and reasoning (Jones et al., 2002), pattern classification (Denoeux and Zouhal, 2001), information fusion (Telmoudi and Chakhar, 2004), sort (Xu, 2012). In recent years, there have been several attempts to use the DS theory of evidence for MADA (Yang et al., 2006; Liu et al., 2011; Zhang et al., 2012a). In many cases, the DS theory has been used as an alternative approach to Bayes decision theory (Beynon et al., 2000; Yager et al., 1994) incorporated the DS theory with the AHP process. The method can not only model both quantitative and qualitative attributes but also take advantage of the AHP to lower the number of alternatives that fit the limited number of opinions given so far, with only a few opinions stated.
In some uncertain decision problems with qualitative attributes, however, it may be difficult to define assessment grades as independent crisp sets. It would be more natural to define assessment grades using subjective and vague linguistic terms which may overlap in their meanings. While intuitionistic fuzzy set has been proven to be highly useful in dealing with uncertainty and vagueness, accordingly, intuitionistic fuzzy set is a very suitable tool to be used to describe the imprecise uncertain decision information (Zhang et al., 2012b; Amer et al., 2010). Nevertheless, the current DS-AHP approach does not take into account vagueness or fuzzy uncertainty. As such, there is a clear need to combine the DS-AHP theory for handling both types of uncertainties. The purpose of this paper is to investigate how to incorporate the intuitionistic fuzzy information with the DS-AHP method.
PRELIMINARY
The existing DS-AHP approach: On the base of Dempster-Shafer theory of evidence, the method first identifies all possible focal elements from the decision matrix and then it calculates the basic probability assignment of each focal element and the belief interval of each decision alternative. The AHP approach is used to describe the MADM problem. Using AHP approach, the MADM is decomposed into three levels. The first level is the MADM problem with incomplete information, the second level is the decision attributes of the MADM problem and the third level is focal elements identified from the decision matrix. Next, we will describe the main steps of the DS-AHP approach (Gong, 2007; Hua et al., 2008).
First, we identify focal elements from an incomplete decision matrix. Let Θ = {a1,…, aN} be a collectively exhaustive and mutually exclusive set of decision alternatives, called the frame of discernment.
Given a decision matrix V = |f (ai, Ci)| where, f (ai, Ci) is the evaluation of the decision alternative ai (i = 1, 2,…, N) under the jth attribute Cj (j = 1, 2,…, M). The decision matrix V implies the body of evidence of the MADM and a focal element can be defined from the decision matrix as follows:
then ai and ak belong to the same focal element.
According to above definition, we can obtain the focal elements of each attribute. Then, the hierarchical structure of DS-AHP can be constructed. And similar to AHP, the weights of importance of decision attributes ωj, j = 1, 2,…, M in DS-AHP can be determined through pairwise comparison.
Second, construct belief interval of each decision alternative. Denote by Ajk (j = 1, 2,…, M; k = 1, 2,…, t; t<2N) the set that consists of all focal elements under decision attribute Cj and if ai∈Ajk, we can view ωjf (ai, Cj) as the decision maker’s preference on the focal element Ajk, where, ωj is the importance weight of decision attribute Cj. Denote by P(Aik) the decision maker’s preference on the focal element Ajk, then p(Ajk) = ωjf(ai, Cj). Because Θ is the frame of discernment which consists of all decision alternatives, we let the p(Θ). Then we can define the basic probability assignment (BPA) of each focal element as follows:
Applying the operator of combination in the DS theory, the BPA of each focal element considering all decision attributes can be obtained. Suppose Aj1k and Aj2k are two focal elements under decision attribute Cj1 and Cj2, respectively, j1, j2∈{1, 2,…, M}, j1 ≠ j2. Denote the intersection of Aj1k and Aj2k as E, then according to DS rule of combination, the BPA of E is defines as follows:
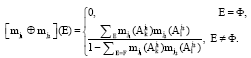 |
After obtaining BPA of each focal element considering all decision attributes, we can define its belief measure (Bel) and plausibility measure (Pls).
Denote by Bel({ai}) and Pls ({ai}) the exact support to a decision alternative ai (i = 1, 2,…, N) and the possible support to ai, respectively. The two values can be got as follows:
Using Bel({ai}) and Pls ({ai}), we obtain the belief interval [Bel({ai}), Pls ({ai})] for all decision alternatives of the MADA problem with incomplete information. Then in order to obtain the preference relations among all decision alternatives, we need a mechanism to generate the rank of decision alternatives based in their belief intervals. There’re many available methods to rank the alternatives. Here we cite the method described as follows.
We define the degree of preference of ai over ak, denoted by P(ai>ak) as follows:
with P(ai>ak)∈[0, 1].
By applying the above definition, we define the preference relation between decision alternative as follows.
| • | Decision alternative ai is said to be superior to ak (denoted by ai |
| • | Decision alternative ai is said to be inferior to ak (denoted by ai |
| • | Decision alternative ai is said to be indifferent to ak (denoted by ai~ak ) if P(ai>ak) = 0.5 |
The above formulas consist of the main process of the DS-AHP approach. After these steps, we can obtain the rank of all the decision alternatives.
The intuitionistic fuzzy set (IFS): An intuitionistic fuzzy set A on a universe U is defined as an object of the following form (Hua et al., 2008):
where, the functions μA: U→ [0, 1] and vA: U→[0, 1] define the degree of membership and the degree of non-membership of the element u∈U in A, respectively and for ∀u∈U, 0≤μA (u)+vA (u)≤1.
For convenience, we call u = (u, v) an intuitionistic fuzzy number.
THE COMBINATION OF THE DS-AHP METHOD WITH INTUITIONISTIC FUZZY INFORMATION
Just as the existing DS-AHP approach, we first need to obtain a decision matrix.. Here we assume there are n evaluation grades to which all alternatives can be assessed, denoted by H = {h1, h2,…, hn} are mutually exclusive and collectively exhaustive. And we also need to define the utility of each grade as u (hr) with u (hr+1)>u(hr) if it is assumed that the grade hr+1 is preferred to hr. And the assessment value is provided with intuitionistic fuzzy information. Then we have that: if an alternative ai is assessed on an attribute Cj to a grade hr with an intuitionistic fuzzy data, we denote this by:
where, μr,j (ai) is the degree of membership of an alternative ai on the attribute Cj associated with the grade hr and vr,j(ai) is the degree of non-membership. For convenience, we use (μr,j, vr,j) to represent the assessment (μr,j (ai), vr,j(ai)) in the following paragraphs. After N alternatives are all assessed on M attributes, we obtain the following decision matrix: D = (S(Cj(ai))).
First, to every alternative assessed on each attribute, combine the assessment given to the different grades. With the utility of each grade, a comprehensive assessment value of alternative ai on the attribute Cj can be got as follows:
The operational rules of intuitionistic fuzzy set were defined by Atanassov (1986). Obviously, u(ai, Cj) is still an intuitionistic fuzzy data. As the process of assessment is often accompanied with incomplete information, so we need to revise the results obtained using the expected utilities.
We denote ![]() as the weight assigned to alternative ai on the attribute Cj, where:
as the weight assigned to alternative ai on the attribute Cj, where:
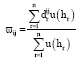 |
And δijr represents the counts of grades an alternative is assigned to δijr is about the following formula:
Using the weight above, we can revise u(ai, Cj). We denote (μij, vij) = ![]() u(ai, Cj). From now onwards, we can finally obtain the transformed decision matrix V = (μi,j, vi,j) NxM.
u(ai, Cj). From now onwards, we can finally obtain the transformed decision matrix V = (μi,j, vi,j) NxM.
Second, identify the focal element of each attribute. On the base of the transformed decision matrix V = (μi,j, vi,j) NxM, we can define the following method. The decision alternatives which have the same assessment value or the same degree of influence on an attribute belong to the same focal element of the attribute. A focal element can be defined as follows:
Definition 1: For ∀ ai, ak∈Θ and ai ≠ ak, if μij = μkj then ai and ak belong to the same focal element.
The next step, we will define the interval probability masses of each focal element. Denote by Ajk (j = 1, 2,…, M; k = 1, 2,…, t; t<2N)the set that consists of all focal elements under decision attribute Cj. We can obtain the interval probability masses of Ajk.
Definition 2: Considering the weight of Cj, for ∀ai∈Θ, ∀Ajk∈2Θ if ai∈Ajk, then we define the interval probability masses as:
We denote it as:
As to the whole set Θ = {a1,…, aN}, the followings are used to obtain its interval probability masses:
where, t<2N.
Third, to obtain the interval probability masses of each focal element considering all decision attributes, we need to define the combination rule.
Definition 3: Let mj1 (Aj2k), mj2 (Aj1k) be two interval belief structure with interval probability masses mj1 (Aj1k)¯≤mj1 (Aj1k)≤mj1 (Aj1k)+ k = 1, 2,…, and mj2 (Aj2k)¯≤mj2 (Aj2k)≤mj2 (Aj2k)+, l = 1, 2,…, t.
We define E as the intersection of two focal elements Aj1k and Aj2k. Their combination, denoted by mj1⊕mj2 is also an interval belief structure defined by:
where, (mji⊕mj2)¯ (E) and (mji⊕mj2)+ (E) are, respectively the minimum and the maximum of the following optimization model:
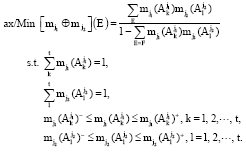 |
When there are three or more attributes to be combined, we can use the combination rule recursively to obtain the final combined results. It should be pointed out that when using the combination rule recursively, we should do follow the next processes. We can first do the combination between two attributes and then combine the intersections of the two with the third attribute. This process will be stopped when all decision attributes are considered. These non-linear programming models can be solved by some mathematical software such as LINGO. Similar models can also be constructed for mj(Θ).
The last step is to construct belief interval of each decision alternative.
Definition 4: The belief measure (Bel) and the plausibility measure (Pls) of alternatives aj are defined, respectively by:
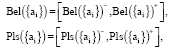 |
Where:
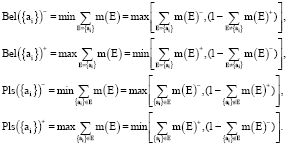 |
Finally, we obtain the belief interval of all the decision alternatives which can be used to rank the alternatives. As for the ranking problem, there are a lot of methods provided by many scholars. Here we use the following formula:
| (1) |
If P(ai>ak)>0.5 then ai ![]() ak; else if P(ai>ak)<0.5; else ai
ak; else if P(ai>ak)<0.5; else ai ![]() ak.
ak.
NUMERICAL EXAMPLE
Here, we give an example on how to select a good project when the investment is carried on. The problem is described as follows: there are four available projects which consist of the decision alternative set Θ = {a1, a2, a3, a4} and there are four attributes related to the investment problem: marketing opportunity (C1), support degree of policy (C2), economy (C3), technical capability (C4) and the weight of importance of decision attributes are ω = {ω1, ω2, ω3, ω4}.
| Table 1: | Decision matrix of the project selection problem |
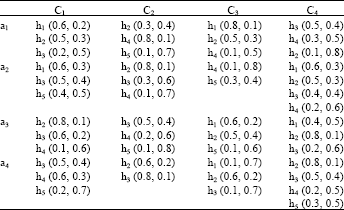 | |
| Table 2: | Transformed decision matrix |
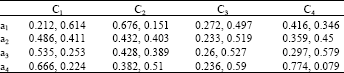 | |
All alternatives can be assessed to five grades H = {h1, h2, h3, h4, h5}, here we assume the expected utility of each grades are:
u(h1) = 0.2, u(h2) = 0.4, u(h3) = 0.6, u(h4) = 0.8, u(h5) = 1 |
First of all, we should calculate the weight of importance. By comparing with each other and using AHP algorithm, we can obtain ω = (0.517, 0.168, 0.077 and 0.238). After we assessed every alternative on each attribute, we obtain the decision matrix as shown in Table 1.
With the original information, we can obtain the transformed matrix V = ((μi,j, vi,j)) as shown in Table 2.
According to definition 2, we calculate the interval probability masses of each focal element as follows:
Under the decision attribute C1:
Under the decision attribute C2:
Under the decision attribute C3:
Under the decision attribute C4:
According to definition 3 and 4, we can obtain the belief measure and the plausible measure of alternative a1 as follows:
 |
Then according to Eq. 1, we have the final rank of the four alternatives: a1 ![]() a1
a1 ![]() a3
a3 ![]() a4, that is to say a4 is the best project to invest.
a4, that is to say a4 is the best project to invest.
CONCLUSION
The DS-AHP approach is a novel, flexible and systematic method. It can solve the problems directly based on its decision matrix. In this paper, we introduced something about intuitionistic fuzzy data and gave the basic steps of the DS-AHP method. We used the expected utilities to transform the original decision matrix. And then we defined interval probability masses which is different from the original basic probability assignment. In fact, it is an interval BPA. With the interval probability masses, we used a non-linear model to combine the focal element. In the end, we obtain the belief interval, where belief measure and plausible measure are both intervals. As we know the intuitionistic fuzzy information is used commonly in real assessment, so this combination is meaningful.
Further extension about DS-AHP approach includes developing methods with information expressed in interval intuitionistic fuzzy values or other uncertain values.
ACKNOWLEDGMENTS
The authors acknowledge support of Chinese Humanities and Social Sciences Project of Ministry of Education (10YJC630269) and University Science Research Project of Jiangsu Province (11KJD630001).
REFERENCES
- Amer, A.A., R. Rakesh and B. Ranjit, 2010. Applying a new method of soft-computing for system reliability. J. Applied Sci., 10: 1951-1956.
CrossRefDirect Link - Beynon, M., B. Curry and P. Morgan, 2000. The Dempster-Shafer theory of evidence: An alternative approach to multicriteria decision modeling. Omega, 28: 37-50.
CrossRef - Dempster, A.P., 1967. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat., 38: 325-339.
Direct Link - Denoeux, T. and L.M. Zouhal, 2001. Handling possibilistic labels in pattern classification using evidential reasoning. Fuzzy Sets Sys., 122: 409-424.
CrossRef - Jones, R.W., A. Lowe and M.J. Harrison, 2002. A framework for intelligent medical diagnosis using the theory of evidence. Knowledge-Based Syst., 15: 77-84.
CrossRefDirect Link - Kim, S.H. and B.S. Ahn, 1997. Group decision making procedure considering preference strength under incomplete information. Comput. Oper. Res., 24: 1101-1112.
CrossRef - Kim, S.H. and B.S. Ahn, 1999. Interactive group decision making procedure under incomplete information. Eur. J. Oper. Res., 116: 498-507.
CrossRefDirect Link - Lan, T.S., 2009. Taguchi optimization of multi-objective CNC machining using TOPSIS. Inform. Technol. J., 8: 917-922.
CrossRefDirect Link - Liu, P.L. and C.H. Tsai, 2007. A study on the application of fuzzy analytic hierarchy process to construct an R and D management effectiveness evaluation index for taiwan`s high-tech industry. J. Applied Sci., 7: 1908-1915.
CrossRefDirect Link - Liu, D.R. and Y.Y. Shih, 2005. Integrating AHP and data mining for product recommendation based on customer lifetime value. Inform. Manage., 42: 387-400.
Direct Link - Liu, H.C., L. Liu, , Q.H. Bian, Q.L. Lin, N. Dong and P.C. Xu, 2011. Failure mode and effects analysis using fuzzy evidential reasoning approach and grey theory. Expert Syst. Appl., 38: 4403-4415.
CrossRef - Telmoudi, A. and S. Chakhar, 2004. Data fusion application from evidential databases as a support for decision making. nform. Software Technol., 46: 547-555.
Direct Link - Webber, S.A., B. Apostolou and J.M. Hassell, 1997. The sensitivity of the analytic hierarchy process to alternative scale and cue presentations. Eur. J. Oper. Res., 96: 351-362.
CrossRef - Wu, H.H., J.I. Shieh, Y. Li and H.K. Chen, 2010. A combination of AHP and DEMATEL in evaluating the criteria of employment service outreach program personnel. Inform. Technol. J., 9: 569-575.
CrossRef - Xu, D., 2012. The research on sort method of consumer's brand preference under uncertain environment. Inform. Technol. J., 11: 637-641.
CrossRefDirect Link - Yang, J.B., Y.M. Wang, D.L. Xu and K.S. Chin, 2006. The evidential reasoning approach for MADA under both probabilistic and fuzzy uncertainties. Eur. J. Oper. Res., 171: 309-343.
Direct Link - Yang, T. and C. Kuo, 2003. A hierarchical DEA-AHP methodology for the facilities layout design problem. Eur. J. Opert. Res., 147: 128-136.
CrossRefDirect Link - Zhanga, Y., X. Denga, D. Weia and Y. Denga, 2012. Assessment of E-Commerce security using AHP and evidential reasoning. Expert Syst. Appl., 39: 3611-3623.
CrossRef - Zhang, Z., J. Yang, Y. Ye, Y. Hu and Q. Zhang, 2012. Intuitionistic fuzzy sets with double parameters and its application to pattern recognition. Inform. Technol. J., 11: 313-318.
CrossRefDirect Link - Wang, H., G. Qian and X. Feng, 2011. An intuitionistic fuzzy AHP based on synthesis of eigenvectors and its application. Inform. Technol. J., 10: 1850-1866.
CrossRefDirect Link - Beynon, M., D. Cosker and D. Marshall, 2001. An expert system for multi-criteria decision making using dempster shafer theory. Expert Syst. Appl., 20: 357-367.
CrossRefDirect Link