
Fengyu Zhu
Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Qi Wang
Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Zhengguang Shen
Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 10 | Page No.: 1496-1501







ABSTRACT
Selection of Relevance Vector Machine (RVM) kernel function parameter is one among ineffectively resolved issues which is first resolved in the literature by Adaptive Particle Swarm Optimization (APSO). A novel APSO-RVM method is proposed to optimize and select the RVM kernel parameter, thus forming, taking the advantage of APSO dramatically convergence. Furthermore, the method is applied to the fault detection of liquid rocket engines test-bed. In order to verify the validity of dramatically effectiveness in fault detection, this paper demonstrates the proposed APSO-RVM approach by performing both simulations and experiments using Oxygen Valve Outlet Pressure (Pejy) data. Results show that APSO-RVM can rapidly detect faults effectively and has a high practical value.
PDF Abstract XML References Citation
Received: December 13, 2011;
Accepted: May 18, 2012;
Published: July 03, 2012
How to cite this article
Fengyu Zhu, Qi Wang and Zhengguang Shen, 2012. APSO-RVM for Fault Detection of Liquid Rocket Engines Test-bed. Information Technology Journal, 11: 1496-1501.
DOI: 10.3923/itj.2012.1496.1501
URL: https://scialert.net/abstract/?doi=itj.2012.1496.1501
DOI: 10.3923/itj.2012.1496.1501
URL: https://scialert.net/abstract/?doi=itj.2012.1496.1501
INTRODUCTION
Liquid rocket engines experiment is a extremely sophisticated integrated technology and huge systematic project. Compared with other large scientific experiments, it has particularly high comprehensiveness encompassing large numbers of subjects such as rocket engine expertise, monitoring and control technology, propellant chemistry technology, cryogenic technology, vacuum technology, high-altitude environment simulation technology, environmental monitoring technology, environmental technology and organization and management science (Figueroa and Schmalzel, 2006). Because of complex structure, high precision and hefty expense, experiment failure can lead to huge losses and even equipment damage. According to the fault records form Aerospace Testing Technology Institute, the failure rate due to experiment system fault was 20%. The early detection of faults can help avoid failure from spreading, reduce system shutdown and prevent accident involving human fatality and material damage (Wu, 2005). Therefore, it has great economic and security significance for early fault detection and timely preventive maintenance of the liquid rocket engine test-bed.
Our liquid rocket engines test-bed still adopts off line monitoring method in the present in China which merely forces on several main parameters, while may result in fallacious prediction even erroneous failure detection relating to the sensors fault (Wu, 2005). Many widely employed methods based on statistics are simple and reliable, however, whose accuracy rely heavily on statistical results of test-bed. And it is difficult to establish accurate mathematical model by mathematical analysis on account of nonlinear and instability of the liquid rocket engine test-bed. In recent years, as computer technology and artificial intelligence constantly developed, many new theories and methods in the field of fault detection and diagnosis are applied to propulsion system. Fuzzy hyper-sphere neural network based real-time monitoring failure system is presented (Huang et al., 1999) which is verified that it outperforms the BP neural network in the article. Neural network based real-time fault detection algorithm in ground test process is implemented with MATLAB (Huang et al., 2007) which performs effectiveness in engine failure detection through many offline evaluation and real-time online test. A Support Vector Machines (SVM) based multi-fault classifier is established for data mining of liquid rocket engine steady state test (Han and Hu, 2007) which is verified by experiment that the algorithm has excellent classification and anti-jamming ability and requires few training data.
To deal with the defects of difficultly determined neural network structure and easily immerging in partial minimum frequently, a novel adaptive particle swarm optimization relevance vector machine (APSO-RVM) is proposed which is based on liquid rocket engines test-bed fault detection method. Through, mapping the raw data to high dimension space with kernel function, it solves nonlinear in the high dimension space to avoid the lower linear inseparable problem. It not only resolves over learning problems in virtue of small samples and nonlinear but also generates better generalization ability by solving sparse model.
The main contributions in this study are the development of the following:
| • | A novel RVM kernel parameter selection method is proposed, reflecting faster computing speeds and locating the global optimum |
| • | A novel liquid rocket engines test-bed fault detection method was suggested, reducing the alarm time and promoting the system reliability |
THE RELEVANCE VECTOR MACHINE
RVM, like SVM, has a sparse probabilistic model (Tipping, 2001). However, RVM appeases to be advantageous against SVM due to Bayesian treatment which does not suffer from the basic limitations of SVM. The RVM trains in the Bayesian framework, obtains the priori probability of weight by a set of hyper-parameters and find the optimal value via iterative algorithm. RVM applied Bayesian inference based on Gaussian process methods to SVM, derives probability distribution and makes kernel function free from Mercer. It has good performance (Tipping and Lawrence, 2005) on function regression and classification.
For regression, given a set of input vector ![]() and relevant output vector
and relevant output vector ![]() , supervised learning aims at designing a model with those training data and prior knowledge (Tipping and Faul, 2003). Based on new input vector xn, the model can forecasted relevant output vector y(xn). tn are observed output which can be taken as a unknown function y(x, w) contained the Gaussian noise with σ2 variance:
, supervised learning aims at designing a model with those training data and prior knowledge (Tipping and Faul, 2003). Based on new input vector xn, the model can forecasted relevant output vector y(xn). tn are observed output which can be taken as a unknown function y(x, w) contained the Gaussian noise with σ2 variance:
| (1) |
where, ε is independently distributed noise; w is adjustable parameters weight. So, obtain:
| (2) |
where, Φi(x) = K(x, xi). The selection of kernel function will be free from Mercer. Thus, we can choose the most popular kernels such as Gaussian kernel, polynomial kernel, Radial Basis Function (RBF) kernel, etc. The likelihood function corresponding training set is :
| (3) |
Where:
and:
that:
The way got the optimal weight w of Empirical Risk Minimization (ERM) can result in over learned. To avoid this situation, given a priori conditional probability distribution using sparse Bayesian method for the weight w:
| (4) |
Meanwhile, for hyper-parameters α and noise variance β ≡ σ2 definite hyper-prior distribution as Γ distribution:
| (5) |
Where:
In normal circumstances, parameter a, b, c, d is very tiny, it can provide a = b = c = d = 0. So, it will get consistent hyper-prior.
Then, according to the Bayes rule, it can find posteriori formula for all of unknown parameters as following:
| (6) |
Given to new observed point x*, the distribution of corresponding target forecasted value t* is:
| (7) |
Considering:
| (8) |
Thus:
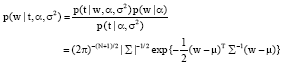 | (9) |
where, covariance matrix is Σ = (σ-2 ΦTΦ+A)-1, A = diag(α0, α1,..., αN), mean vector is μ = σ-2ΣΦTt.
This study use the peak of delta function to approximate the hyper-prior p(α, σ2|t) in t he above formula. Aim at forecasting, we do not care p(α, σ2)≈δ(αMP, σ2MP), where α, σ2 possible values are αMP, σ2MP. Focus on:
| (10) |
Thus, RVM problem is converted into posterior mode for hyper-parameters problem, that is, seeking the maximum of posteriori hyper-parameters which is equal to seeking the maximum of α and β. In the condition of consistent hyper-prior, it only needs to take the maximum of p(t|α, σ2). So, obtain:
| (11) |
To obtain p(t|α, σ2), it need to integrate out α and β with following iterative formula:
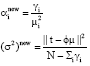 | (12) |
where, γi = 1-αiNii, Nii are the ith diagonal elements of posteriori weight covariance matrix.
Ideally, if given an new input x*, it can predict target through following steps:
| (13) |
| (14) |
| (15) |
| (16) |
Corresponding to the new observations, the predicted output of RVM is y(x*, μ).
SELECTION OF RVM KERNEL PARAMETER
Yet it has never been proposed any analytic instructional method for RVM kernel parameter selection (Li et al., 2010; Tao et al., 2008). At present, empirical method and ergodic searching have been mostly used to study kernel parameter setting. Ergodic searching has certain blindness for parameters setting and demands enormous sacrifices of time.
Characteristics analysis of RVM kernel parameter: In this study, based on standard function sinc, effects of kernel parameters on training results is discussed.
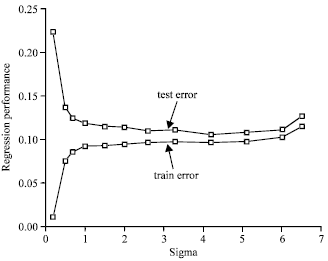 | |
| Fig. 1: | Regression performance diagram |
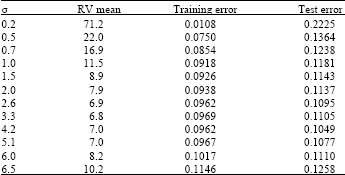
| Table 1: | Regression performance of different σ |
 | |
The function of sinc is:
where, noise is random noise in the range [-1, 1]. Even taken 100 sample points as samples, this paper adopted 5-fold cross-validation to calculate training error and test error. The Gaussian kernel used for the construction of the basis matrices is K(x, y) = exp[-||x-y||/σ2].
From the Table 1, it can conclude that training error approximates zero as σ approaches zero which means all samples can be compact fitted. Whereas, we must notice that corresponding test error approaches infinity, the number of corresponding relevance vector is 100, that is to say, all the training samples are relevance vector, for test samples are 100. At this stage there is over learned and RVM lost learning ability. All above arguments show ERM based on traditional learning approach such as neural network cannot ensure excellent generalization ability. The sizes of relevance vector get smaller with the increase of σ (in a small range) and training error increasing but test error decreasing. That means the generalization ability of RVM is improving. When σ approximates 4.2, it can get minimum test error. Figure 1 illustrates minimum test error is not coincide with minimum training error which verifies traditional ERM cannot guarantee excellent generalization ability. When σ reach a certain value (nearly 6 in the Table 1), the sizes of relevance vector and corresponding training error and test error are increasing again. That indicates the performance of discrimination and generalizations gets worse. Actually, the generalizations ability of RVM based on Gaussian kernel goes from low to high and to low.
Adaptive particle swarm optimization: After RVM kernel parameter characteristics analysis, a novel method about optimizing RVM kernel parameter with adaptive particle swarm optimization is proposed. Particle Swarm Optimization (PSO) based on swarm intelligence theory is an optimization technique for locating the global optimum (Tu et al., 2011) which produces swarm intelligence to guide optimization with cooperation and competition among particles. This algorithm simulates birds foraging behavior, considers each individual always maintain the optimal distance with adjacent ones during activity. It promotes the co-evolution in the virtue of information sharing. Comparing with other intelligent optimization algorithms, PSO has an excellent performance on parallel searching and meanwhile it has few parameters and shape convergence speed. In PSO, each optimization problem is regarded as searching a flight particle in the space. Flight direction and distance of particle depend on velocity and optimal objective function determines fitness. Particles dynamically adjust their speed based on flying experience and find the optimal solution by iteration.
According to the above problem, defined PSO fitness function as:
| (17) |
where, wi is relevance vector weight, yi is truth value, ![]() is predicted value.
is predicted value.
The implementing steps of this optimization process are:
| • | Step 1: Vmax = 1, Vmin = -1, c1 = c2 = 1.5, iteration step is 100, population size is 20. Definite mutation operator as 0.9 on the basic PSO to prevent from immerging in partial minimum on account of iterative efficiency reduced in the post course of the optimization procedure |
| • | Step 2: Random generate velocity and position of each particle |
| • | Step 3: Calculate Fitness according to fitness function |
| • | Step 4: Compare the current fitness value and the best fitness value in history for each particle. If the current fitness value is smaller, then take it as the best experienced individual fitness value |
| • | Step 5: Calculate the minimum of the best fitness value of all particle experience and record it as the global best fitness value |
| • | Step 6: Update particle velocity and position and limit each new velocity and position |
| • | Step 7: Random generate mutation factor. If reach the variation conditions, re-initialize the particles |
| • | Step 8: If reach the maximum of iteration step, stop searching and return the best fitness value and the position. Else turn to step 3 |
| Table 2: | Optimization results of APSO |
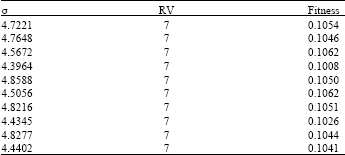 | |
Following the above steps, 10 optimization results are give in Table 2.
From Table 2, the experimental results show that σ makes a nearly perfect fit with the optimal value at a high probability, meanwhile which prove consistent relevance vector number and close sparse level (7/100). From what has been discussed above, it may safely draw the conclusion that the proposed APSO is efficiently applicable to the problem of RVM kernel parameter optimization.
PROJECT EXAMPLE
Establishing mathematical model is the emphasis and difficulty of complex and nonlinear dynamic systems fault detection (Yu et al., 2009). For a project of liquid rocket engines test-bed, hydrogen supply system is the key part of rocket engine test-bed, whose work status will have a directly impact on the engine test. For security, it have to real-time monitor many significant parameters, such as oxygen valve outlet pressure (Pejy), oxygen tank pressure (Pxy), pre-pump pressure of oxygen (Pohy), etc. which ensure reliability of entire system. Because system conditions rapidly changed before ignition start, the value of parameters mentioned above changed abruptly. It is necessary to use sensors real-time monitoring signal change, in order to prevent unnecessary damage.
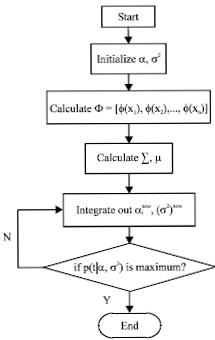 | |
| Fig. 2: | Modeling process |
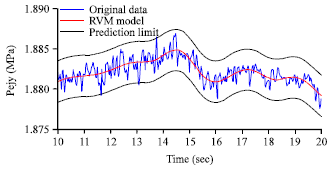 | |
| Fig. 3: | The results of training Pejy via APSO-RVM |
| Table 3: | Pejy training parameters and results |
Here, it demonstrates how the proposed APSO-RVM framework is efficiently applicable to the project of liquid rocket engines test-bed fault detection. This paper focus our analysis on the parameter of Pejy and model it using 37 times normal test data which are truncated 10 seconds data in pre-cooling phase before ignition with 50 Hz sampling frequency. The total sample points are 500. The modeling process is as follows:
| • | Data preparation. First of all, make data preprocessing and normalize to [0, 1]. Besides, select Gaussian kernel and optimize kernel parameter using APSO-RVM. Return optimal kernel parameter σ |
| • | Modeling using the theory of section 2. Simplified process is as Fig. 2 |
| • | Calculating prediction error and evaluating upper and lower limit of model |
| • | According to Chebyshev inequality P(|x-μ|≥nσ)≤1/n2, via APSO-RVM model, obtain: |
| (18) |
In practice, making estimated standard deviation S instead of the standard deviation σ. The threshold range of sensor signal characteristics can be formulate as:
| (19) |
where, wT is relevance vector, φ(xi) relevance vector kernel matrix, n = 3. The probability of falling into this interval is 99.74%. The results of training Pejy model via APSO-RVM are shown in Fig. 3. Training parameters and results are presented in Table 3.
The experimental results indicated that APSO-RVM has excellent modeling ability (fitness is 8/500), while reduces detection time.
Furthermore, for verifying the performance of model presented via APSO-RVM, it employed on the actual data of an oxygen valve leakage. Using the method proposed in this literature, alarm occurred at 17.53 sec which is 0.95 sec ahead of alarm time via red threshold detection method.
CONCLUSION
In this study, a novel APSO-RVM kernel parameter method is proposed for augmenting RVM kernel parameter selection by adaptive PSO. What this paper done make up for amending the defects in the analytic instructional method for RVM kernel parameter selection. Results show that kernel parameter will converge in a tiny region using analytic instructional method proposed instead of experience and ergodic searching. It is efficiently applicable to the project of liquid rocket engines test-bed fault detection and can rapidly detect failure which meet the engineering requirements of real-time and reliability with high practical significance. According to the different observer points, it can flexibly analysis data features and select the appropriate parameters. It will have extensively effect.
As further study, the proposed model remains to integrate consider the pressure and flow direction among different observer points.
REFERENCES
- Yu, C., H.X. Han and W. Min, 2009. Missile fault detection based on linear parameter varying fault detection filter. Inform. Technol. J., 8: 340-346.
CrossRefDirect Link - Wu, J., 2005. Liquid-propellant rocket engines health-monitoring-a survey. ACTA Astronaut., 56: 347-356.
CrossRef - Tu, J., Y. Zhan and F. Han, 2011. An improved PSO algorithm coupling with prior information for function approximation. Inform. Technol. J., 10: 2226-2231.
CrossRefDirect Link - Tipping, M.E., 2001. Sparse Bayesian learning and the relevance vector machine. J. Machine Learn. Res., 1: 211-244.
Direct Link - Tipping, M.E. and N. Lawrence, 2005. Variational inference for Student-t models: Robust Bayesian interpolation and generalised component analysis. NeuroComputing, 69: 123-141.
CrossRef