
Yuzhen Liu
School of Mathematics and Computational Science, Xiangtan University, Xiangtan, People�s Republic of China
Shoufu Li
School of Mathematics and Computational Science, Xiangtan University, Xiangtan, People�s Republic of China
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 3 | Page No.: 573-578







ABSTRACT
For Global Optimization Problems (GOPs), we propose a new variant of DE with linear neighborhood search, called LiNDE which employs a linear combination of triple vectors taken randomly from evolutionary population, in order to improve the ability of neighborhood search of Differential Evolutionary (DE) algorithm. The main characteristics of LiNDE are less parameters and powerful neighborhood search ability. Experimental studies are carried out on a benchmark set and the results show that LiNDE significantly improves the performance of DE.
PDF Abstract XML References Citation
Received: July 13, 2010;
Accepted: October 30, 2010;
Published: December 01, 2010
How to cite this article
Yuzhen Liu and Shoufu Li, 2011. A New Differential Evolutionary Algorithm with Neighborhood Search. Information Technology Journal, 10: 573-578.
DOI: 10.3923/itj.2011.573.578
URL: https://scialert.net/abstract/?doi=itj.2011.573.578
DOI: 10.3923/itj.2011.573.578
URL: https://scialert.net/abstract/?doi=itj.2011.573.578
INTRODUCTION
Recently, many complicate scientific and engineering problems are difficult to be solved using traditional optimization methods and researchers begin to get help to intelligent optimization algorithms, such as DE algorithm (Storn and Price, 1997), particle swarm optimization (Eberhart and Kennedy, 1995) Among these intelligent optimization algorithms, DE algorithm has showed superior power in dealing with benchmark problems and real-world applications (Ilonen et al., 2003; Storn, 1996; Rogalsky et al., 1999; Joshi and Sanderson, 1999).
The classical DE algorithm (Storn and Price, 1997) contains five candidate mutation operators and triple control parameters: population size NP, scale factor F and crossover rate CR. The characteristic of multiple mutation schemes and control parameters allows DE adapting to various environments. However, how to choose suitable mutation scheme (s) and set parameter value are not easy tasks (Zaharie, 2002).
Control parameters setting is frequently problem-independent task and required previous experience knowledge and environmental information. Despite of its crucial importance, there is no common methodology to determine the values of all parameters and in most time, they are set with an arbitrary manner within some given ranges (Maruo et al., 2005). In general, the setting approaches of parameter values are divided into two major forms (Brest et al., 2006): parameter tuning and parameter self adaptation. The former approach tries to find better parameter values before running the algorithm. However, such a trial-and-error searching process required high computational cost (Qin et al., 2009). Moreover, a set of fix parameter values is not all efficient during the whole evolutionary process. The self-adaptive method of parameter setting is employed in some variants of DE algorithm. Qin et al. (2009) proposed a self-adaptive DE (SaDE), where crossover rate CR and mutation strategies are self-adapted according to their associated-success rate. Another self-adaptive strategy was proposed by Yang et al. (2008b). In the strategy, CR is allocated to each individual according to its success rate and the Gaussian distribution with standard deviation 0.1. CR is set to 0.5 initially and not updated within 5 generations. After a specified number of generations, the memory base, saving the history information of CR, is updated. And then CR is calculated.
Another issue about DE algorithm is choosing suitable mutation strategies in different evolutionary phases. Qin et al. (2009) employed a selection probability p to determine which strategy is used in different evolutionary phases. The probability p is gradually self-adapted according to the previous performance of the strategy. Therefore, those mutation strategies who improve the solution quality have large probability to be used. But some variants of DE algorithm employ one mutation strategy. Brest et al. (2006) proposed a self-adaptive control parameter DE algorithm, where only rand/1 mutation strategy is used and the algorithm, noted as jDE, shows good performance when optimizing GOPs.
In the study, we present a novel variant of DE algorithm, shorted for LiNDE, to dealing with GOPs. Proposed LiNDE uses random strategy when setting scale factor F and crossover rate CR. Meanwhile, we adapt rand/1 mutation strategy and introduce a neighborhood searching operator.
PRELIMARY OF DE
A set of D-dimensional vectors is called evolutionary population P containing NP vectors, where NP is the number of vectors. The vectors with D dimension is call individual and it can be noted as xi, xi = (xi1, xi2 …, xiD). The classic DE algorithm can be summarized as follows:
Mutation operator:
| (1) |
where, vi = (vi1, vi1,…,viD) is a trial vector generated by mutation operator and xri , i = 1, 2, 3 are individuals taken from P randomly. F is a scale factor controlling the step size of the difference vector (xr2 - xr3).
If a component of the trial vector vi is beyond the given bound predefined by problem, then it is reinitialized randomly.
In classic DE algorithm, there are for different mutation strategies. For detailed description and analysis behind them (Storn and Price, 1997).
Crossover operator: The operator combines vi and xr1, then gets the target vector ui, ui = (ui1, ui2,…uiD).
where,
| (2) |
In Eq. 2, U (0, 1) stand for random distribution, j-rand is a random number chosen from {1, 2,…NP} to ensure target vector ui getting at least one component from xr1.
Selection operator: A greedy selection scheme is used in DE algorithm
| (3) |
where x’i enters the next generation.
According to Storn and Price (1997), DE is much more sensitive to the choice of F and CR. However, various conflicting conclusions have been drawn with regard to the rules for manually choosing the strategy and control parameters (Qin et al., 2009). Thus, in order to decrease the impact of control parameters, we set F and CR to a random number within (0, 1) and (0.5, 1), respectively. Another parameter is the size of evolutionary population NP. Although various setting method are given Storn and Price (1997) and Price (1999), there is no a universal method.
Consequently, we study the control parameter through a series of experiments to select a suitable value.
NEIGHBORHOOD SEARCH
Rand/1 mutation operator is used. Meanwhile, we propose a new mutation strategy searching the neighborhood of an individual. The proposed operator is given as follows:
| (4) |
where j is a scale factor generated through U (0,1) xri, I – 1, 2, 3 are individuals taken from P randomly and ri ≠ r2 ≠ r3.
Figure 1a and b show the distribution of offspring individuals generated by neighborhood searching operator and rand/1 operator, respectively.
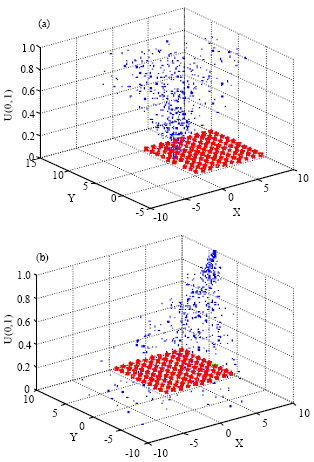 | |
| Fig. 1: | The distributing illustrations of offspring |
| Table 1: | Framework of linde |
 | |
Meanwhile, we calculate the deviation of offspring individuals generated by two operators, and their deviations are 2.04 and 3.26, respectively. Therefore we conclude the proposed neighborhood searching operator is suitable to exploit the neighborhood of any individuals.
FRAMEWORK OF LiNDE
It can be concluded that how to set control parameters and how to select strategies have been pay special attention in DE algorithm. However, the ability of neighborhood search has been neglected to some extent. Motivated by the above observation, we propose a novel DE algorithm with neighborhood searching operator. The framework of LiNDE is given as Table 1.
PERFORMANCE EVALUATION
The performance evaluation is important when comparing various population-based algorithms. However, how to evaluate the performance has no specific method, therefore we propose a novel performance evaluation criterion.
Suppose there are k test functions and their best optima are t1, t2, ...tk, so the vector of best optima can be noted as T = (t1, t2, ...tk). For a given algorithm A employed to optimize the above k test functions, after a certain independent runs, the algorithm outputs the best mean vector M and standard deviation vector S for k test functions and M = (m1, m2,...mk), S = (s1, s2,...sk). Therefore, the performance evaluation criterion is as the following form Eq. 5
| (5) |
where, ω is a weight factor.
The performance evaluation criterion gives the overall performance in term of solution quality and stability for evaluated algorithm, Fig. 2 show the procedure of evaluation.
 | |
| Fig. 2: | The convergence of mean vector and standard deviation vector in the process of optimization |
Theorem 1 If a algorithm named A obtains all best optima when optimizing k test functions in a certain independent runs, in addition, all standard deviations for all functions are zeros, then Pev (A) = 0.
Proof: Suppose the vector of best mean obtained by A for k test functions is M = (m1, m2,...mk) and the corresponding vector of standard deviation is S = (s1, s2,...sk); The vector of best optima for k test functions is T = (t1, t2,...tk). Consequently, the value of performance evaluation can be computed through the above form Eq. 6. The algorithm obtains all best optima in a certain independent runs, therefore M = T, namely, mi = ti, i = 1, 2, .., k. Then the item
| (6) |
Following the same idea, the next item
| (7) |
Consequently,
| (8) |
Deduction: Suppose two algorithms A and B are employed to optimize k test functions. The overall optimization process is independently done for a given times. If A performs better than B overall, then Pev (A)<PEv (B).
EXPERIMENTAL STUDIES
Experimental studies includes three parts: (1) A brief introduction to benchmarks; (2) A serial experiments on how to tuning parameters used in LiNDE; (3) A comparison studies with SaNSDE (Yang et al., 2008a), SaDE (Brest et al., 2006) and NSDE (Yang et al., 2008a).
Benchmarks: Experimental validation for the proposed LiNDE is conducted on 13 classical benchmarks (Yao et al., 1999), which can be divided into two classes: (1) F1-F7 are high dimensional unimodal problems employed to validate the convergence speed of algorithm; and (2) F8-F13 are high dimensional multimodal problems where the number of local optima increases exponentially with the problem dimension and they are utilized to demonstrate the searching ability of escaping local optima and tracing the global optima.
Parameter tuning: Two parameters population size NP and selection probability p are employed in LiNDE. In order to obtain the best performance of LiNDE, it is necessary to tune control parameters.
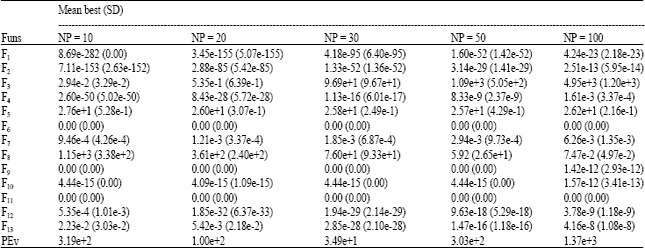
Firstly, we tune NP by optimizing 13 benchmarks when set p = 0.5 and Fes = 1e+5. The experimental results are listed in Table 2. For unimodal functions F1-F7 LiNDE achieved much better results when using small population size (10, 20 and 30) than that of large population size (50 and 100) except on the simple step function F6. The explanation behind the results is that: LiNDE using a small population could evaluate more iterations than that of large population. Therefore, the fitness values of unimodal functions could reach higher precision. However, the performance of LiNDE with large population size is better than that of LiNDE with small of population size when optimizing multi-modals functions F8-F13. The explanation behind the results is also the difference of iteration number.
According to the proposed evaluation criterion, LiNDE obtained the best performance when NP = 30 than that of other population size. Thus we set NP = 30 in later experiments.
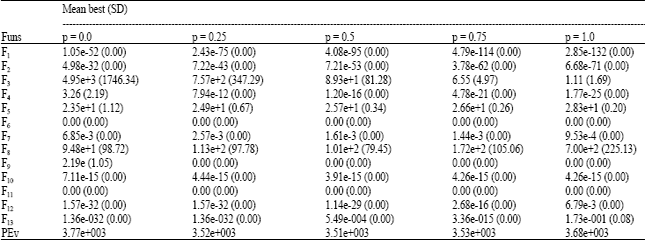
Secondly, we conducted a series of experiments under various selection probability p when NP = 30 and Fes = 1e+5. Optimization results are given in Table 3 where the last row lists scores obtained by evaluation criterion. We can observe that: scores are almost identical when p = 0.25, 0.5 and 0.75 which means LiNDE is not sensitive to the parameter. Therefore, we set p = 0.5 in the subsequent experiments.
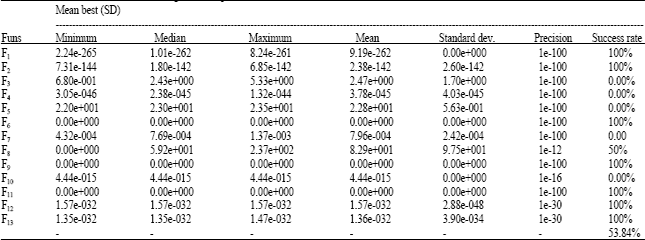
Performance of LiNDE: In order to obtain the performance of LiNDE optimizing benchmarks, we run the algorithm 25 times independently and experimental results are listed in Table 4. For unimodal functions F1-F7, LiNDE obtained the optima of F1, F2 and F6, meanwhile, the optimizing precision of F4 reached e-45. For multi-modal functions F8-F13, LiNDE algorithm performed better than that of unimodal functions and obtained higher precision for all benchmarks except for F8.
Comparison studies: In the experimental studies, we compare LiNDE with self-adaptive differential evolution (SaDE), differential evolution with neighborhood algorithm (NSDE) and self adaptive differential evolution with neighborhood search (SANSDE). In order to comparing the performance of different algorithms fairly, we adopted experimental data from reference. Then we also evaluate the performance of four algorithms using the proposed evaluation criterion.
| Table 2: | Optimizing results with different population size NP when p = 0.5 and Fes = 1e+5 |
 | |
| Table 3: | Optimizing results with different slection probability p when NP = 30 and Fes = 1e+5 |
 | |
| Table 4: | Performance of linde when setting NP = 30, p = 0.5, Fes = 3e+5 |
 | |
| Table 5: | Experimental results averaged over 25 independent |
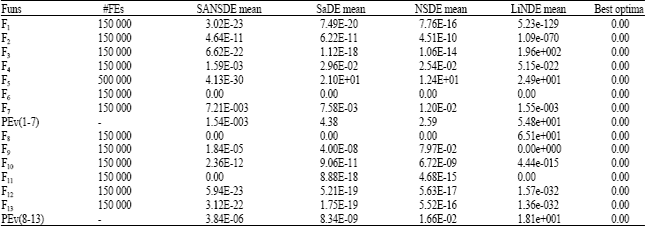 | |
The average results of 25 independent runs are listed in Table 5.
High-dimensional unimodal functions (F1-F7). LiNDE algorithm outperformed SANSDE, SaDE and NSDE except functions F3, F5 and F6. The significant difference can be seen from the result on function F3. On the other hand, SaDE, NSDE and LiNDE performed almost the same for function F5 and F6, however, SANSDE obtained the highest precision. Finally, we evaluate the performance of four algorithms by proposed evaluation criterion. LiNDE obtained a higher score than that of others; the reason behind of the scores is function F3 suffering LiNDE.
High-dimensional multimodal functions with many local minima (F8-F13). Functions F8-F13 are all multimodal functions with many local minima and the number of local minima increases exponentially as the dimension increases. According to the experimental results, LiNDE performed better than other algorithms in term of mean values except function F8. However, SANSDE, SaDE and NSDE all found the optima of the function. Consequently, the score of LiNDE is higher than that of other algorithm.
CONCLUSION
In this study we proposed a new variant of DE algorithm, LiNDE, aiming to improve searching ability of neighborhood. In LiNDE, (1) we generalized the control parameters F and CR, to whom DE algorithm is sensitive. In our study, F and CR are random numbers generated by uniform random distribution function; (2) we introduced a new operator for neighborhood search based on rand/1 operator and two operators had same the selection probability. The corresponding experimental results showed that LiNDE is non-sensitivity to the selection probability. Meanwhile, we proposed a novel evaluation criterion to evaluate the performance of different optimization algorithm. In order to select suitable control parameters and to evaluate the performance of proposed LiNDE algorithm, the algorithm was conducted on 13 classical benchmarks and LiNDE showed superiority over SANSDE, SaDE and NSDE for most benchmarks.
ACKNOWLEDGMENTS
This work was supported by National Natural Science Foundation of China under Grant 10871164 (Jan., 2009-Jan., 2011), 10676031 (Jan., 2007-Jan., 2010), 60673193 (Jan., 2007-Jan., 2010).
REFERENCES
- Qin, A.K., V.L. Huang and P.N. Suganthan, 2009. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans. Evolut. Comput., 13: 398-417.
Direct Link - Ilonen, J., J.K. Kamarainen and J. Lampinen, 2003. Differential evolution training algorithm for feed-forward neural networks. Neural Process. Lett., 7: 93-105.
Direct Link - Brest, J., S. Greiner, B. Boskovic, M. Mernik and V. Zumer, 2006. Self-adapting control parameters in differential evolution: A comparative study on numerical benchmark problems. IEEE Trans. Evolut. Comput., 10: 646-657.
Direct Link - Maruo, M.H., H.S. Lopes and M.R. Delgado, 2005. Self-adapting evolutionary parameters: Encoding aspects for combinatorial optimization problems. Lecture Notes Comput. Sci., 3448: 154-165.
Direct Link - Storn, R. and K. Price, 1997. Differential evolution-A simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim., 11: 341-359.
CrossRefDirect Link - Eberhart, R.C. and J. Kennedy, 1995. A new optimizer using particle swarm theory. Proceedings of the 6th International Symposium on Micro Machine and Human Science, October 4-6, 1995, Nagoya, Japan, pp: 39-43.
CrossRefDirect Link - Storn, R., 1996. On the usage of differential evolution for function optimization. Proceedings of Biennial Conference of the North American Fuzzy Information Processing Society, June 19-22, 1996, Berkeley, CA, pp: 519-523.
Direct Link - Rogalsky, T., R.W. Derksen and S. Kocabiyik, 1999. Differential evolution in aerodynamic optimization. Proceedings of the 46th Annual Conference of the Canadian Aeronautics and Space Institute, (CASI`99), Canada, pp: 29-36.
Direct Link - Joshi, R. and A.C. Sanderson, 1999. Minimal representation multisensor fusion using differential evolution. IEEE Trans. System. Man Cybernet. A Syst. Humans, 29: 63-76.
Direct Link