
Jun Deng
School of Electronics and Information Technology, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Guanghui Ren
School of Electronics and Information Technology, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Yansheng Jin
School of Electronics and Information Technology, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Wenjing Ning
School of Electronics and Information Technology, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 7 | Page No.: 1409-1414







ABSTRACT
Finding sparse solution to undetermined linear systems is one of the fundamental challenging issues in compressive sensing problems and other signal processing applications. This study has presented a novel iterative weighted gradient projection algorithm, referred to as the IWGP, to recover sparse signal in large-scale settings. IWGP is based on a widely used weighted filter technique in signal processing which reduces undesirable influence so that gradient projection can be applied to achieve computational efficiency. Numerical experiments are carried out and the results demonstrate the proposed algorithm is significantly faster than the fastest known methods for the l1 minimization programs and further show that the computational time isn’t sensitive to the sparsity level of original signal.
PDF Abstract XML References Citation
Received: January 11, 2011;
Accepted: April 13, 2011;
Published: June 10, 2011
How to cite this article
Jun Deng, Guanghui Ren, Yansheng Jin and Wenjing Ning, 2011. Iterative Weighted Gradient Projection for Sparse Reconstruction. Information Technology Journal, 10: 1409-1414.
DOI: 10.3923/itj.2011.1409.1414
URL: https://scialert.net/abstract/?doi=itj.2011.1409.1414
DOI: 10.3923/itj.2011.1409.1414
URL: https://scialert.net/abstract/?doi=itj.2011.1409.1414
INTRODUCTION
Sparse signal reconstruction from a set of underdetermined or ill-conditioned linear measurements is a fundamental problem in signal processing and statistics. This problem has over the last few years found application areas from compressive sensing (Donoho, 2006; Guochang et al., 2010) to source coding (Goyal et al., 1998), image restoration (Figueiredo and Nowak, 2003; Yu et al., 2010) and source localization (Picard and Weiss, 2010).
Suppose A is a measurement matrix in RMxN (M<N) and n is a noise vector in RM, then we are given measurements y ∈RM of the form:
| (1) |
If there are no restrictions on the measurement matrix A and the original signal x, then the problem of finding an estimate ![]() is NP-hard in general. While there are at least five major classes of computation techniques for solving sparse reconstruction problem (Tropp and Wright, 2010), namely greedy pursuit (Mallat and Zhifeng, 1993), Bayesian framework (Wipf and Rao, 2004), nonconvex optimization (Chartrand, 2007), brute force (Miller, 2002) and convex relaxation (Chen et al., 1998).
is NP-hard in general. While there are at least five major classes of computation techniques for solving sparse reconstruction problem (Tropp and Wright, 2010), namely greedy pursuit (Mallat and Zhifeng, 1993), Bayesian framework (Wipf and Rao, 2004), nonconvex optimization (Chartrand, 2007), brute force (Miller, 2002) and convex relaxation (Chen et al., 1998).
Greedy pursuit, one of the most popular ways at present (Chen et al., 2008), is used in approaches such as Matching Pursuit (MP) (Mallat and Zhifeng, 1993), Orthogonal Matching Pursuit (OMP) (Pati et al., 1993), Stagewise Orthogonal Matching Pursuit (StOMP) (Donoho et al., 2006) and Stagewise Weak Gradient Pursuit (SWGP) (Blumensath and Davies, 2009). Greedy pursuit iteratively refines a sparse signal representation by successively choosing one or more elements on a dictionary that have the highest correlation with current residual. Bayesian framework employs relevance vector machine for estimating the underlying signal while nonconvex optimization procedures develop a related nonconvex problem and attempt to find a stationary point. Brute force strategies search through all possible support sets to minimize the number of possibilities. Another very popular approach is to solve the convex unconstrained optimization problems of the form:
| (2) |
Here, τ is a regularization positive parameter which balances the sparsity of the data against the data fidelity (Tropp and Wright, 2010). Many optimization algorithms have been proposed to solve the unconstrained (but nonsmooth) formulation (2), such as Interior-Point (IP) methods (Kim et al., 2007), Iterative Shrinkage/Thresholding (IST) (Daubechies et al., 2004) algorithms, GPSR (Figueiredo et al., 2007) and SpaRSA (Wright et al., 2009).
This study has concentrated on GPSR methods. There are two main problems associated with the application of GPSR to large scale data sets. On the one hand, the computational time is easily affected by original signal sparsity and number of measurements. On the other hand, there is a great deal of interference of other uselessly searching directions in GPSR so that the computational time per reconstruction is long if without continuation schemes. Inspired by greedy pursuit methods, we introduce a variant of GPSR together with iterative weighted vector estimate and we only update the searching directions of ![]() based on the weighted vector. We refer to the resulting approach as IWGP (Iterative Weighted Gradient Projection). We show that IWGP retains all the merits of the GPSR methods and greatly decreases the computational time. We use numerical experiments to show IWGP can handle lager scale compressive sensing problems more efficiently than GPSR and IST. We also compare the sensitivity of IWGP with those of GPSR and IST in terms of change of number of nonzero components and number of measurements.
based on the weighted vector. We refer to the resulting approach as IWGP (Iterative Weighted Gradient Projection). We show that IWGP retains all the merits of the GPSR methods and greatly decreases the computational time. We use numerical experiments to show IWGP can handle lager scale compressive sensing problems more efficiently than GPSR and IST. We also compare the sensitivity of IWGP with those of GPSR and IST in terms of change of number of nonzero components and number of measurements.
GRADIENT PROJECTION FOR SPARSE RECONSTRUCTION
The algorithms discussed and developed in this study are all part of GPSR algorithms. Given a vector x and a measurement matrix A, the approach of GPSR is to express Eq. 2 as a Bound-Constrained Quadratic Program (BCQP) (Wu et al., 2010) via splitting the variable x into positive and negative parts (Figueiredo et al., 2007) and can be rewritten Eq. 2 as:
| (3) |
where, ![]() ,
, ![]() and
and ![]() .
.
Equation 3 can be more properly rewritten in a standard BCQP form as:
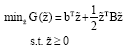 | (4) |
Where:
And:
The gradient of the objective function G (![]() ) is defined as:
) is defined as:
| (5) |
GPSR chooses the negative gradient -Δ G (![]() ) to search for each iterate
) to search for each iterate ![]() :
:
| (6) |
where, α(k) is the step size. This can be solved by two strategies in GPSR, called GRSR-Basic algorithm and GPSR-BB algorithm respectively. In GPSR-Basic, the step size α(k) is defined initially as:
| (7) |
Where:
| (8) |
Then it is achieved the proper step size until a sufficient decrease is attained in G by running a backtracking line search. Alternatively, in order to avoid the fussily inner searching loop, the Barizilai and Borwein equation (Figueiredo et al., 2007) is applied to approximate to the Hessian of G at ![]() in GPSR-BB. So the stp size is calculated simply as:
in GPSR-BB. So the stp size is calculated simply as:
| (9) |
Where:
Note that GPSR-Basic ensures objective function decrease per iteration and GPSR-BB makes the iteration easier. They are easy to implement and do not appear to require application-specific tuning. In reality, GPSR algorithms tend not to work very well for large-scale settings because they spend much computational time. Instead, it is necessary to apply specialized techniques, such as warm-start and continuation. A more detailed discussion of GPSR algorithms can be found by Figueiredo et al. (2007).
ITERATIVE WEIGHTED GRADIENT PROJECTION
In this study, we propose a novel approach, called IWGP which combines a weighted vector with GPSR to achieve a spare approximation solution to Eq. 1. More precisely, we mean that it is more efficient to compute the gradient ΔG (![]() ) and to solve Eq. 2 by GPSR. In this section, we discuss how the algorithm works efficiently as well as the different ways to choose threshold, describing the IWGP framework formally.
) and to solve Eq. 2 by GPSR. In this section, we discuss how the algorithm works efficiently as well as the different ways to choose threshold, describing the IWGP framework formally.
In fact the gradient ΔG (![]() ) contain more information than its form suggests, by further analyzing its particular Eq. 5. For a given
) contain more information than its form suggests, by further analyzing its particular Eq. 5. For a given ![]() , we have:
, we have:
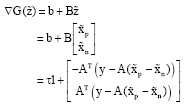 | (9) |
We define a residual vector (Liejun, 2011):
| (10) |
So Eq. 9 can be rewritten as:
| (11) |
Where:
| (12) |
It may be worth noting that the gradient of the objective function in Eq. 11 can be constitution of a constant vector τ1 and a vector ATr which means that the gradient ΔG (![]() ) includes the information of residual correlation between the current residual r and measurement matrix A.
) includes the information of residual correlation between the current residual r and measurement matrix A.
Now we may concentrate on showing that the proposed algorithm makes full use of the residual correlation to build up a weighted vector to filter out unwanted gradient value. We define a vector J in RN by:
| (13) |
where, c = Atr, Th is a threshold parameter, hard (x, th) = 2xsign (|x|-th1) +1 is the well-known hard-threshold function. We merge the newly identified vector with the previous weighted vector estimate, thereby updating the estimate:
| (14) |
Since the original sparse signal x is a signal populated primarily with zeros, we can be only interested in the gradient directions of the locations of the nonzeros in ![]() .
.
Specifically, we define a new gradient vector:
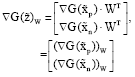 | (15) |
Where:
| (16) |
With the direction to move given by Eq. 15, we can simply compute the step size as Eq. 9 and update the next estimate ![]() by Eq. 6.
by Eq. 6.
Threshold selection: To recover the original signal x, we hope to know which columns of A participate in the measurement vector y. The idea behind the algorithm is to identify columns in a thresholding fashion. At each iteration, we firstly wish to determine a weighted vector which represents the column of A that is most strongly correlated with the remaining part of y. Then we start to search from a new approximation along the negative gradient filtered by the weighted vector. After proper iterations, we wish that the algorithm will have identified the correct vector of columns.
These considerations motivate a few number of possible threshold selection. One simple selection is:
| (17) |
where, t typically takes values in the range 2≤t≤3. The selection strategy is inspired by Gaussian behavior of residual Multiple-Access Interference (MAI) (Donoho et al., 2006).
A similar strategy is called stagewise weak element selection (Blumensath and Davies, 2009). This selection takes advantage of a threshold based on the maximum of |ri|. Based on this approach, the threshold is calculated as:
| (18) |
where, β∈ (0, 1) is a weakness parameter.
Both these strategies are well suited to the class of problems addressed in this study. In the experiments, unless otherwise noted, we choose (18), with β = 0.75 as the threshold.
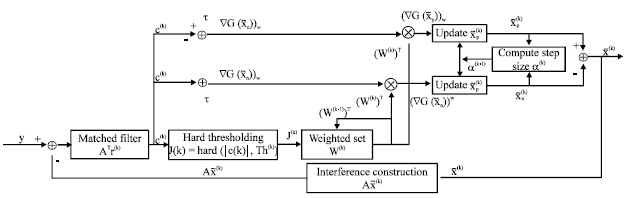 | |
| Fig. 1: | Schematic Representation of the IWGP algorithm |
The IWGP framework: IWGP operates in k iterations, building up a sequence of estimations ![]() by searching along a sequence of negative weighted gradient vectors
by searching along a sequence of negative weighted gradient vectors ![]() Moreover, the algorithm also maintains a sequence of estimates W(0), W(1)…, of weighted coefficients. Figure 1 gives a diagrammatic representation.
Moreover, the algorithm also maintains a sequence of estimates W(0), W(1)…, of weighted coefficients. Figure 1 gives a diagrammatic representation.
Meantime a precise framework of the algorithm is defined as follows.
Algorithm IWGP:
| Step 1: | Start with initial ‘solution’ |
| Step 2: | Apply matched filtering to the current residual, achieving the vector of residual correlations: |
| (19) |
| Step 3: | Compute the threshold Th(k) from Eq. 18, the identified vector J(k) as in Eq. 13 and then yield the weighted vector W(k)as in Eq. 14. |
| Step 4: | Compute the weighted gradient |
| Step 5: | Calculate the new estimate and the new residual: |
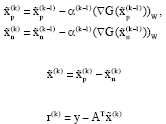 |
| Step 6: | Compute the step size α(k-1) from Eq. 9 |
| Step 7: | Check the stopping criterion which is chosen as suggested by Figueiredo et al. (2007) ||min (z, ΔG (z))||≤tolP and if it is satisfied, set |
EXPERIMENTS
This section illustrates experimentally that IWGP is a powerful algorithm for several types of sparse reconstruction problems of the form Eq. 2. All the experiments were carried out on a personal computer with an Intel Pentium (R) Dual E2200 processor and 1.99GB of memory.
Let us describe the experimental setup. In each trial, we start with a d-sparse signal x and its measurements y according to the model in Eq. 1. In all of the experiments below, we have used an MxN Gaussian matrix as our measurement matrix A, with all entries independently distributed Normal (0, 1) and then orthonormalizing the rows. We used parameter of stopping criterion tolP = 10-5.
In our first experiment, we consider a length N = 4096 signal x that contains d = 100 randomly placed±1 spikes. To simulate measurement noise, zero-mean Gaussian white noise with variance 10-4 is added to each of the M measurements that define the observation y. In the example M = 1024, τ = 0.005 ||ATy||∞ and the reconstructions are implemented by GPSR and IWGP.
Figure 2 shows that the original signal and the reconstruction results with GPSR-BB and IWGP, respectively. Because of noisy reconstruction, GPSR-BB cannot recover the underlying sparse signal exactly, nor can IWGP. However, the IWGP reconstruction exhibits a bit lower Mean Squared Error (MSE) with respect to the original signal.
In the second experiment, we compare the speed of IWGP with that of other recently proposed algorithms, namely, variants of GPSR and IST (Daubechies et al., 2004). All the parameters are similar in the first experiment except that we perform 100 independent trials. Table 1 reports the average CPU times needed by the several algorithms.
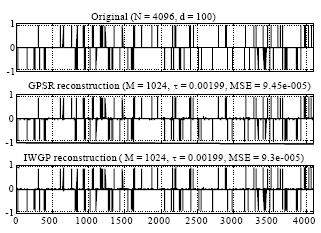 | |
| Fig. 2: | From top to bottom: original signal, reconstruction via GPSR-BB and IWGP |
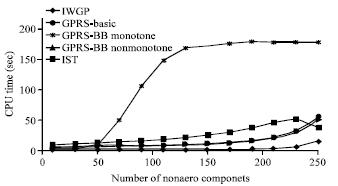 | |
| Fig. 3: | CPU time and number of nonzero components |
| Table 1: | Average CPU times |
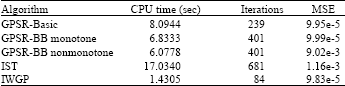 | |
The finding in this table presents IWGP is significantly faster than the others. More in detail, IWGP is approximate 12 times faster than IST and about 5 times faster than GPSR.
The plot in Fig. 3 presents how the CPU time of IWGP changes when the number of nonzero components increases. For comparison, also shown are the results obtained with GPSR and IST. And the noise’s variances in this example are fixed the same and the results are averaged over 100 runs. In general the CPU time of the algorithms is in line with the increase of the number of nonzero components. However, IWGP keeps this growth very mild. In other words, IWGP is insensitive to the change in the sparsity level.
Then let us see how much CPU time of the algorithms is required to recover a fixed sparsity level of signal with change in the number of measurements.
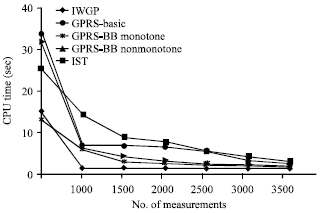 | |
| Fig. 4: | CPU time and number of measurements |
Results in Fig. 4 display that CPU time of IWGP (as well as GPSR and IST) is affected by increase in the number of measurements. Not surprisingly, IWGP costs the least CPU time solving spare reconstruction problem although the others also decrease gradually as the number of measurements grows.
CONCLUSION
We have presented a novel gradient projection algorithm to more effectively solve the solution to sparse signal reconstruction problems arising in compressive sensing and other inverse problems. We have employed a weighted technique to filter out unwanted gradient components and the resulting algorithm is well suited to handling large-scale settings. In the numerical experiments, we have tested IWGP by utilizing a large-scale example. The novel algorithm is significantly faster compared to state-of-the-art algorithms. Moreover, the decrease of sparsity level can hardly interfere the computational time of the algorithm derived in this paper. The numerical results further show that IWGP is superior to GPSR algorithms and IST.
REFERENCES
- Wu, G., Y. Zhang and X. Yang, 2010. Sampling theory: From shannon sampling theorem to compressing sampling. Inform. Technol. J., 9: 1231-1235.
CrossRefDirect Link - Goyal, V.K., M. Vetterli and N. Thao, 1998. Quantized overcomplete expansions in RN: Analysis, synthesis and algorithms. IEEE Trans. Inform. Theory, 44: 16-31.
CrossRef - Picard, J.S. and A.J. Weiss, 2010. Bounds on the Number of Identifiable Outliers in Source Localization by Linear Programming. IEEE Trans. Image Process., 58: 2884-2895.
CrossRef - Mallat, S.G. and Z. Zhang, 1993. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process., 41: 3397-3415.
CrossRef - Chen, S.S., D.L. Donoho and M.A. Saunders, 1998. Atomic decomposition by basis pursuit. SIAM J. Sci. Comput., 20: 33-61.
CrossRefDirect Link - Wipf, D. and B. Rao, 2004. Sparse Bayesian learning for basis selection. IEEE Trans. Signal Process., 52: 2153-2164.
CrossRef - Chartrand, R., 2007. Exact reconstruction of sparse signals via nonconvex minimization. IEEE Signal Process. Lett., 14: 707-710.
CrossRef - Tropp, J.A. and S.J. Wright, 2010. Computational Methods for Sparse Solutions of Linear Inverse Problems. Proc. IEEE, 98: 948-958.
CrossRef - Pati, Y.C., R Rezaiifar and P.S. Krishnaprasad, 1993. Orthogonal matching pursuit: Ication to wavelet decomposition. Conf. Rec. Asilomar Conf. Signals Syst. Comput., 1: 40-44.
CrossRef - Blumensath, T. and M.E. Davies,, 2009. Stagewise weak gradient pursuit. IEEE Trans. Signal Process., 57: 4333-4346.
CrossRef - Figueiredo, M.A.T., R.D. Nowak and S.J. Wright, 2007. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Sign. Proces., 1: 586-597.
CrossRef - Wright, S., R. Nowak and M. Figueiredo, 2009. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process., 57: 2479-2493.
CrossRef - Kim, S., K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, 2007. An interior-point method for large-scale ℓ1-regularized least squares. IEEE J. Sel. Top. Sign. Proces., 1: 606-617.
CrossRef - Wu, H., L. He, L. Qin, T. Feng and R. Shi, 2010. Solving interval quadratic program with box set constraints in engineering by a projection neural network. Inform. Technol. J., 9: 1615-1621.
CrossRefDirect Link - Yu, X., Y. Gao, X. Yang, C. Shi and X. Yang, 2010. Image restoration method based on least-squares and regularization and fourth-order partial differential equations. Inform. Technol. J., 9: 962-967.
CrossRefDirect Link - Liejun, W., 2011. An improved water-filling power allocation method in MIMO OFDM systems. Inform. Technol. J., 10: 639-647.
CrossRefDirect Link - Chen, J., J. Fan, X. Cao and Y. Sun, 2008. GRFR: Greedy rumor forwarding routing for wireless sensor/actor networks. Inform. Technol. J., 7: 661-666.
CrossRefDirect Link - Figueiredo, M.A.T. and R.D. Nowak, 2003. An EM algorithm for wavelet based image restoration. IEEE Trans. Image Process., 12: 906-916.
CrossRef