
Yi-Hsin Wang
Department of Information Management, Chang Gung Institute of Technology, Kwei-Shan, Taoyuan County 333, Taiwan, Republic of China
Ding-An Chiang
Department of Computer Science and Information Engineering, Tamkang University, Tamsui, Taipei County 251, Taiwan, Republic of China
Sheng-Wei Lai
Communication Development Office, Ministry of National Defense, Shindian, Taipei County 231, Taiwan, Republic of China
Cheng-Jung Lin
Department of Computer Science and Information Engineering, Tamkang University, Tamsui, Taipei County 251, Taiwan, Republic of China
Information Technology Journal
Year: 2010 | Volume: 9 | Issue: 3 | Page No.: 488-493







ABSTRACT
In recent years, wireless service subscribers are easy and frequent to change from one service provider to another for better service, which is called churn. This study applied data mining techniques to predict customer churn in Customer Relationship Management (CRM) and build predicting model to prevent customer churn. The experimental evaluation results show that customer churn model is effective and efficient. It can help enterprise in predicting the customer churn, building customer loyalty and maximizing enterprise profitability.
PDF Abstract XML References Citation
How to cite this article
Yi-Hsin Wang, Ding-An Chiang, Sheng-Wei Lai and Cheng-Jung Lin, 2010. Applying Data Mining Techniques to WIFLY in Customer Relationship Management. Information Technology Journal, 9: 488-493.
DOI: 10.3923/itj.2010.488.493
URL: https://scialert.net/abstract/?doi=itj.2010.488.493
DOI: 10.3923/itj.2010.488.493
URL: https://scialert.net/abstract/?doi=itj.2010.488.493
INTRODUCTION
Currently, wireless equipments, such as Access Point (AP), wireless network cards, etc., are getting less expensive and mobile computing devices, such as notebooks and PDAs, are becoming more and more popular. WIFLY is a particular wireless network service project in Taipei city, which has begun since December 20 of 2005. Taipei has become the world’s first city to establish a wireless network that covers the entire city. In 2006, the Intelligent Community Forum (http://www.intelligentcommunity.org) named Taipei as recipient of its 2006 Intelligent Community of the Year award and presented awards to the Intelligent Building of the Year, Intelligent Community Technology and Intelligent Community Visionary of the Year as well. Taipei is on the way to develop a stable wireless city following the completions of many of its related infrastructure. Nowadays, Taipei Arena is offering wireless service which includes over 5,000 access points and around 90% of Taipei's resident has been covered by WIFLY. With a wireless connection, residents can log onto the Web through their laptops or personal digital assistants anytime and anywhere.
There is huge competition for wireless network companies in Taipei. Companies have to understand customers’ need and develop suitable strategies in order to keep customers’ loyalty and satisfaction. Therefore, the marketing strategy and CRM are becoming very important. Many researches are proposed in similar scenario, such as Hwang et al. (2004) came up with a method for wireless communication company that categorizes customers based on their different values. Yu et al. (2005) proposed a new model for strategic alignment of churn predictors to an adaptation of the Delta strategic model for firm competitiveness. Hung et al. (2006) applied data mining to telecommunication churn management. Chen et al. (2007) proposed a customer segmentation framework based on data mining and constructs a new customer segmentation method based on survival character. Luo et al. (2007) proposed a model for customer churn prediction in personal handy phone system service. Hsu et al. (2007) used systematic trace approach to analyze wireless users’ behavioral patterns by extensively mining wireless network logs from two major university campuses. Zhang et al. (2007) presented a hybrid approach for building a binary classifier in customer churn prediction. Dasgupta et al. (2008) proposed a spreading activation-based technique that predicts potential churners by examining the current set of churners and their underlying social network. Chen and Bose (2009) proposed two-stage hybrid models consisting of unsupervised clustering techniques and decision trees with boosting on two different data sets and evaluate the models in terms of top deciles lift. This study collects the data of WIFLY service subscribers from wireless network companies and data mining techniques used to analyze the data. It is not only segmentation of customers but also predictions of customer churn. The analysis results help wireless network companies understand customers’ behavior and do an excellent CRM job. Besides, service providers can develop adequate marketing strategies to prevent customers churn and enhance company profits.
BACKGROUND KNOWLEDGE
WIFLY: WIFLY is a wireless broadband network service using the IEEE 802.11 standards. It provides wireless internet services and mobile business service platform for citizens, schools, enterprises, communities, travelers from abroad and so on. Wireless networks transmit data via radio wave. Radio wave can penetrate walls so that computer can work anywhere within the range of access points. Therefore, there is no need to install new cables when computers are added or moved to other places. The most popular one among wireless network standards is IEEE 802.11, which operates in the 2.4 GHz at low powered frequency band. The range is up to 300 feet for IEEE 802.11b with few obstructions. It’s because all necessary software and hardware facilities are relatively well developed. Consequently, the cost of building an infrastructure of WLAN (Wireless Local Area Network) has reduced. The application of WLAN is more and more popular.
Customer relationship management: Customer Relationship Management (CRM) began in the early 1990s. Bligh and Turk (2004) defined CRM as a broad term for a group of ideas and technologies that were created to improve customer related business practices. Jutla (2001) describes CRM as acquiring, analyzing and sharing knowledge with customers. Bueren et al. (2004) consider CRM as aiming at building up customer close relations to strengthen the competitive position and maximize the returns. Therefore, CRM has evolved into a useful collection of business approaches and technologies that help companies develop more profitable relationships with customers. Nowadays, companies have to collect information from customers and analyze their behavior patterns and have the ability to integrate and utilize such information effectively.
Every customer’s value is not equal for a company. As the 80/20 rule goes, 80% of benefit comes from 20% of customers. Customers need to be segmented in order to strategically identify valuable customers and to ensure customers’ retention, loyalty and satisfaction. In addition, customers are free to change their original suppliers at little cost and suitable service at a mature market. However, bringing in a new customer tends to cost more than holding on to an existing one (Berry and Linoff, 2004). Therefore, it is essential that companies understand customers’ need and develop suitable CRM strategies.
Data mining technology: As computer technology improves, the amount of data stored in databases is exploding. However, these enormous sets of data provide poor information. In the competitive business environment, enterprises need to turn this large amount of data into their own meaningful information. Thus this information can guide their investment, management and marketing strategies. The data mining technology is concerned with the discovery and extraction of latent knowledge from a database (Chang et al., 2001). Many algorithms are developed, proposed and applied: the decision tree, clustering, sequence clustering, association rule, Naïve Bayes, regression, neural network, etc. These techniques have become more popular and been frequently used in real-world applications, clustering and decision tree are selected to further explain data mining.
Clustering: Clustering is one of the techniques in data mining. It separates a heterogeneous population into a number of more homogeneous subgroups or clusters so that data in each cluster share some common trait (Berry and Linoff, 2004). K-means is one kind of the major algorithms in common use for automatic cluster detection (Macqueen, 1967). In recent years, many researches have been used to improve the performance of clustering algorithms, such as CLARANS (Ng and Han, 1994), DBSCAN (Ester et al., 1996), BIRCH (Zhang et al., 1996), STING (Wang et al., 1997) and CLIQUE (Agrawal et al., 1998) etc.
Clustering is often done as a beginning to other form of data mining or modeling. In this study, clustering technique is used to divide customers into clusters with similar traits and then decision tree technique used to analyze the high churn rate cluster for customer churn prediction.
Decision tree: Decision tree is popular and powerful for both classification and prediction. The attractiveness of tree-based methods is due largely to the fact that decision tree represent rules (Berry and Linoff, 2004). A decision tree is based on the methodology of tree graphs and can be considered one of the more simple inductive study methods (Quinlan, 1986, 1993; Russell and Norving, 1995). Even if the user lacks any statistical knowledge, he or she can use a decision tree to analyze specific behavior and it can be converted into rules easily. However, if it becomes too complicated or too huge for decision-making, trimming some of its leaves or branches may become necessary in order to improve its effectiveness. Of all the calculative methods, ID3, C4.5 (Quinlan, 1993; Cheng et al., 1998), CART (Breiman et al., 1984) and CHAID (Magidson and Vermunt, 2004) are the most well known.
RESEARCH METHOD
Raw data set description: This study based on a real data set is obtained from a wireless network company in Taipei City. The users of the wireless network company with more than 4,000 members had joined the WIFLY project lasting ten month from January to October. We apply data mining techniques to analyze over 80,000 transactions. The data set make users connect to WIFLY related information of behavior pattern, such as account, frequency, duration, gap and so on. In this study, the chief analytical attributes are listed in Table 1. The objective is to understand the characteristics between different types of users in wireless network company. In order to improve customer retention and to predict customer churn.
| Table 1: | Analytical attributes used in decision tree |
 | |
Since to make sure the result is useful for wireless network companies, we separated ten- month original data set into three parts, which are history data, training and testing data. The first four months data is picked out to construct the historical information. The next three months is picked out as the modeling data set. At last, the last three months is picked out for the testing data set to evaluate the model constructed in the previous steps.
Clustering analysis result: In this study, the number of user accounts over 4000 includes more than ten types of subscribers in WIFLY project. We applied clustering technique to segment the diverse subscribers into a number of more similar subgroups or clusters. Nine clusters are produced from clustering analysis. In Fig. 1 it shows five specific characteristics clusters. First column is the cluster name. Second column shows the percentage of the cluster in population and then displays the related attributes of cluster and population. For example, cluster [1]0 accounts for 57.77% of all customers. The following columns are detailed description for corresponding attributes. The variable Drain_Result is the flag of churn. The pie chart shows the distribution of categorical variables for customers within the segment (inner circle), which can be compared with the distribution of all customers (outer circle). Inner pie chart is larger than outer pie chart, which indicates that cluster [1]0 has higher churn rate than that of other clusters. Therefore, we will apply decision tree techniques to predict its characteristics of churned customers. Furthermore, the inner pie chart in other four clusters is less than the outer pie chart in Fig. 1. They are with lower churn rate. These clusters are our target customers.
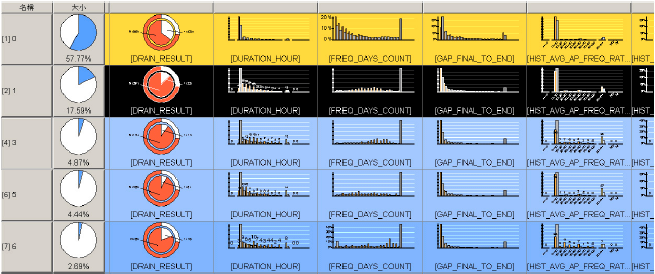 | |
| Fig. 1: | The results from clustering analysis |
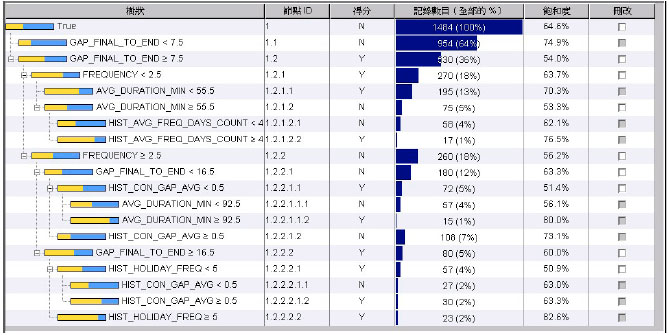 | |
| Fig. 2: | The results from decision tree analysis |
In Fig. 1, there are four loyal customer clusters and one churn customer cluster. The churn customer includes switching other service provider or terminating account. According to customer relationship management, the cost of retaining old customer is less than that of discovering new customers. Therefore, it’s important for the enterprise to keep loyal customers and to prevent customers churn.Those wireless network service providers can come up with various suitable pricing plans for their loyal customer clusters and build an effective customer churn model to prevent customers from churn.
Decision tree analysis result: Here, our goal is to analyze the characteristics of the customer with high churn rate by using decision tree technique. Figure 2 shows the results produced from decision tree analysis for the cluster with higher churn rate. First column displays the tree shape which shows the classifications of attributes. second column is node ID. It denotes the depth-level of a node in the tree visiting tree paths. Third column show the result of churn prediction. Fourth column represents the proportion recorded with specific attribute conditions to whole attributes. Fifth column shows the degree required to satisfy the conditions.
According to the decision tree in Fig. 2, the critical attribute is GAP_FINAL_TO_END. When the value of GAP_FINAL_TO_END is larger than or equal to 7.5, the result of predicting churn is Yes. We predict that the customer will churn. However, the condition of satisfaction is 54%, less than 60%. Thus, we will keep adding other attributes to increase the condition of satisfaction until it is more than 60%.
| Table 2: | Rules predicting absence of churn |
 | |
Following the decision tree path, the next attribute is FREQUENCY. When the FREQUENCY value is smaller than 2.5, the result of churn prediction is Yes and the condition of satisfaction condition is 63.7%. On the other hand, if the FREQUENCY value larger than or equal to 2.5, the threshold value of GAP_FINAL_TO_END has to be modified to 16.5. In addition, we will add other attributes to analysis. Consequently, there are five rules generated from decision tree analysis and displayed as Table 2. These rules could provide enterprise to construct adequate marketing strategies and to prevent customer churn.
EXPERIMENT RESULTS
In order to evaluate the efficacy of the predicting rules, three-month raw data was gathered as testing data set from August to October. We calculated the churn rate of these rules and compared it with each month’s total churn rate from August to October. The result is listed as Table 3 and it based on the sequence of each month’s total churn rate and rule 1-5 for corresponding month.
| Table 3: | To compare the total churn rate with five rules prediction churn rate during three months |
 | |
| The entire churn rate of five rules is greater than original one. The higher churn rate is more effective. Rule 1, 3 and 4 show particular effect for churn prediction | |
The churn rate of five rules of each month is greater than total churn rate of every month. It means that prediction rules are useful to prevent customer from churn possibilities. Particularly, the churn rate of rule 1, 3 and 4 are more than 50% during three months. Besides, their average churn rate of rule 1, 3 and 4 is more than 60%. Consequently, wireless network companies may use these rules to realize the behavior patterns of customers and lay out some related marketing blueprints or strategies to promote their services.
CONCLUSIONS AND FUTURE DIRECTIONS
This study applied data mining techniques to wireless network companies for customer relationship management. The clustering analysis results in differentiating customers from high churn rate and low churn rate clusters. The service provider can develop marketing strategy for corresponding cluster’s customer. Besides, we focus on high churn rate cluster and there are five rules produced from decision tree analysis to predict customer churn. The empirical evaluation result shows the rules are useful and efficient for predicting customers churn. Therefore, the service providers can build customer loyalty proactively and maximize profitability from customer segmentation and predicting customer churn.
Moreover, this study benefits not only customer segmentation and churn prediction but also other data mining applications with similar characteristics. In the future, we can apply this method to judge the performance of other enterprises. Therefore, more and more diverse applications will be provided.
REFERENCES
- Agrawal, R., J. Gehrke, D. Gunopulos and P. Raghavan, 1998. Automatic subspace clustering of high dimensional data for data mining applications. ACM SIGMOD Rec., 27: 94-105.
CrossRefDirect Link - Berry, M.J.A. and G.S. Linoff, 2004. Data Mining Techniques: For Marketing, Sales and Customer Relationship Management. 2nd Edn., Wiley Computer Publishing, New York, ISBN-10: 0471470643, pp: 672.
Direct Link - Bueren, A., R. Schierholz, L. Kolbe and W. Brenner, 2004. CKM-improving performance of customer relationship management with knowledge management. Proceedings of the 37th International Conference on System Sciences, January 5-8, 2004, Hawaii, USA., pp: 1-10.
CrossRefDirect Link - Chen, X. and I. Bose, 2009. Hybrid models using unsupervised clustering for prediction of customer churn. J. Org. Comput. Electronic Commerce, 19: 133-151.
Direct Link - Chen, Y., G. Zhang, D. Hu and C. Fu, 2007. Customer segmentation based on survival character. J. Int. Manuf., 18: 513-517.
CrossRef - Cheng, J., U.M. Fayyad, K.B. Irani and Z. Qian, 1998. Improved decision trees: A generalized version of ID3. Proceedings of the 5th International Conference on Machine Learning, (ICML'98), Morgan Kaufman, pp: 100-106.
Direct Link - Dasgupta, K., R. Singh, B. Viswanathan, D. Chakraborty, S. Mukherjea, A.A. Nanavati and A. Joshi, 2008. Social ties and their relevance to churn in mobile telecom networks. ACM Int. Conf. Proc. Series, 261: 668-677.
CrossRefDirect Link - Ester, M., H.P. Kriegel, J. Sander and X. Xu, 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, August 2-4, 1996, Portland, pp: 226-231.
CrossRefDirect Link - Hsu, W.J., D. Dutta and A. Helmy, 2007. Mining behavioral groups in large wireless LANs. Proceedings of the 13th Annual ACM International Conference on Mobile Computing and Networking, Sept. 9-14, Montreal, Quebec, Canada, pp: 338-341.
Direct Link - Hung, S.Y., D.C. Yen and H.Y. Wang, 2006. Applying data mining to telecom churn management. Expert Syst. Appl., 31: 515-524.
CrossRef - Hwang, H., T. Jung and E. Suh, 2004. An LTV model and customer segmentation based on customer value: A case study on the wireless telecommunication industry. Expert Syst. Appl., 26: 181-188.
CrossRef - Jutla, D., 2001. Enabling and measuring electronic customer relationship management readiness. Proceedings of 34th IEEE Hawaii International Conference on System Sciences, Jan. 3 -6, IEEE Computer Society Washington, DC, USA., pp: 7023-7032.
Direct Link - Luo, B., P. Shao and J. Liu, 2007. Customer churn prediction based on the decision tree in personal handyphone system service. Proceedings of IEEE International Conference on Service Systems and Service Management, June 9-11, Chengdu, pp: 1-5.
Direct Link - Magidson, J. and J.K. Vermunt, 2004. An extension of the CHAID tree-based segmentation algorithm to multiple dependent variables classification the ubiquitous challenge. Proceedings of the 28th Annual Conference of the Gesellschaft fur Klassifikation e.V., March 9-11, University of Dortmund, pp: 1-8.
Direct Link - MacQueen, J., 1967. Some methods for classification and analysis of multivariate observations. Proc. 5th Berkeley Symp. Math. Statist. Prob., 1: 281-297.
Direct Link - Ng, R. and J. Han, 1994. Efficient and effective clustering methods for spatial data mining. Proceedings of the 20th International Conference on Very Large Data Bases, September 12-15, 1994, San Francisco, CA., USA., pp: 144-155.
Direct Link - Quinlan, J.R., 1993. Programs for Machine Learning. 1st Edn., Morgan Kaufmann, San Francisco, ISBN: 1-55860-238-0.
Direct Link - Wang, W., J. Yang and R. Muntz, 1997. STING: A statistical information grid approach to spatial data mining. Proceedings of the 23rd International Conference on Very Large Data Bases, August 25-29, 1997, Athens, Greece, pp: 186-195.
CrossRef - Yu, W., D.N. Jutla and S.C. Sivakumar, 2005. A churn-strategy alignment model for managers in mobile telecom. Proceedings of the 3rd Annual Communication Networks and Services Research Conference, May 16-18, IEEE Computer Society Washington, DC, USA., pp: 48-53.
Direct Link - Zhang, T., R. Ramakrishnan and M. Livny, 1996. BIRCH: An efficient data clustering method for very large data bases. Proceedings of the ACM SIGMOD International Conference on Management of Data, June 4-6, 1996, Cananda, pp: 103-114.
CrossRef - Zhang, Y., J. Qi, H. Shu and J. Cao, 2007. A hybrid KNN-LR classifier and its application in customer churn prediction. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Oct. 7-10, Univ. of Posts and Telecommun., Beijing, pp: 3265-3269.
Direct Link