
W. Yanqing
School of Computer Science and Technology, Harbin University of Science and Technology, Harbin, Heilongjiang Province, 150080, China
C. Deyun
School of Computer Science and Technology, Harbin University of Science and Technology, Harbin, Heilongjiang Province, 150080, China
S. Chaoxia
School of Computer Science and Technology, Nanjing University of Science and Technology, Nanjing, Jiangsu Province, 210094, China
W. Peidong
School of Computer Science and Technology, Harbin University of Science and Technology, Harbin, Heilongjiang Province, 150080, China
Information Technology Journal
Year: 2010 | Volume: 9 | Issue: 3 | Page No.: 481-487







ABSTRACT
A novel vision-based road detection method is proposed in this study to realize visual guiding navigation for Autonomous Land Vehicles (ALV). The captured image was first segmented into road region and non-road region by using Otsu thresholding algorithm. Subsequently, the extracted Canny edges located in deep position of road region and non-road region would be removed by filtering so that the recognition of road boundary could not be affected by mussy edges existed in the image. In order to improve the performance of road detection, the dynamics of ALV and the Monte Carlo Method was taken into account to associate the possible road boundary in different image frames. The method proposed in this study is robust against strong shadows, surface dilapidation and illumination variations. The real world experiment on road detection has demonstrated that the proposed method is feasible and valid.
PDF Abstract XML References Citation
How to cite this article
W. Yanqing, C. Deyun, S. Chaoxia and W. Peidong, 2010. Vision-Based Road Detection by Monte Carlo Method. Information Technology Journal, 9: 481-487.
DOI: 10.3923/itj.2010.481.487
URL: https://scialert.net/abstract/?doi=itj.2010.481.487
DOI: 10.3923/itj.2010.481.487
URL: https://scialert.net/abstract/?doi=itj.2010.481.487
INTRODUCTION
Road detection techniques have been extensively developed due to their widely applications in driver assistance systems, visual navigation of Autonomous Land Vehicles (ALV), the Intelligent Transport Systems (ITS) and other corresponding researching fields (He et al., 2004).
Due to the fact that camera can acquire more abundant information from its surroundings and at the same time supply a cheaper way for autonomous navigation, several vision based road-following application systems have been developed. Some researchers focus their works on structured roads, in which clear marks can be recognized. The Generic Obstacle and Lane-Detection (GOLD) system (Bertozzi and Broggi, 1998) at Parma University, Italy, reprojects the image ahead of the vehicle onto the ground plane and extracts left-middle-right groups of road markings. The Yet Another Road Follower (YARF) system (Kluge and Thorpe, 1992) pays even more attention to the modeling of road geometry and thereby estimates road-model parameters based on the road-marking extraction result.
Obviously, these methods are not appropriate in many real-life situations in which the roads have no clear road markings, such as roads in urban, campus and country environment. Therefore, some researchers propose the road detection methods those are applicable to unstructured roads. The Supervised Classification Applied to Road Following (SCARF) (Crisman and Thorpe, 1993) and unsupervised clustering applied to road following (UNSCARF) systems (Crisman and Thorpe, 1991) at Carnegie Mellon University, have been built to deal with road in parks, with no lane markings and considerable difference in color between the road area and surroundings.
Four typical methods were proposed to realize robust road detection for the unstructured road which have no lane markings, may have degraded surfaces and edges and may be partially obscured by strong shadows:
Methods based on road features: Such methods, i.e., feature clustering, threshold segmentation or region growing, usually catch the key point on color, intensity or texture information between the road region and the non-road region, are usually insensitive to road shapes, but sensitive to illumination, shadows and water marks.
Methods based on road models: Such methods often assume a road model first, then, find the fittest model according to original images. Although, these methods can detect the road more integrally, it may be invalid when facing diverse road shapes.
Methods based on Artificial Neural Networks (ANN) (Conrad and Foedisch, 2003): Such methods are independent of road markings and lanes. During a short initialization step, feature data is automatically collected based on the conforming road structure in images captured from the driver’s point of view. Then, the new Neural Network is trained and applied to the new environment. This procedure allows the system to detect road adaptively and supplies a promising way for road recognition and environmental learning. However, these methods often fail when current road is dissimilar to that of the training set.
Methods based on vanishing points (Se and Brady, 2000; Simond and Rives, 2003): Generally, the key to the approach is to use a voting procedure like a Hough transform on edge-detected line segments to find the intersection point of different road edges (Nguyen et al., 2009). Similar grouping strategies have also been investigated outside the context of roads, such as in urban and indoor environment rich in straight lines, in conjunction with a more general analysis of repeated elements and patterns viewed under perspective (Turina et al., 2001; Schaffalitzky and Zisserman, 2000).
When performing vision-based road detection, the input is a camera image. It can be a grey image or a color image. To locate the road in the image some assumptions regarding the image information are made:
Firstly, the road region differs from the non-road region in color or intensity features.
Secondly, most part of the road has similar features and certain different feature caused by watermark, strong shadow and surface dilapidation is also permitted.
Based on the assumptions mentioned above, the road region was first recognized against its surrounds by using Otsu thresholding algorithm in part II. In part III, the Canny edges extracted in grey images would be filtered in the road region and non-road region. The Monte Carlo method and the dynamics of ALV would be discussed in part IV. After the road detection experiments in different scenes and different illuminations, some conclusions would be given in part V.
ROAD REGION RECOGNITION BASED ON OTSU THRESHOLDING METHOD
Region recognition can be handled by popular thresholding algorithm such as Maximum Entropy, Invariant Moment and Otsu thresholding method. Because Otsu thresholding method supplies a more satisfactory performance in image segmentation, it was used to overcome the negative impacts caused by environmental variation (Otsu, 1979).
In order to utilize the most important color information of the color image, the candidate color channel that was dominant in certain color space was selected to realize image segmentation.
| (1) |
Equation 1 indicates the principle of the color channel selection, in which CC means the color channel; NR means the number of the dominant color channel in certain referenced regions. Because the camera is installed in a fixed place, it is a reasonable hypothesis that certain region can be regarded as road region. The dominant color channel of the region will be selected adaptively to calculate the histogram of the image. Otsu thresholding method was then used to segment the whole image into road region and non-road region adaptively.
ROAD BOUNDARY DETECTION BASED ON CANNY EDGE
Though Otsu thresholding method can relieve such negative impacts as illumination variations, strong shadows or surface dilapidation to some extent, it often mistakes certain part of non-road region for road region due to the similar feature of nearby buildings. Therefore, the Canny edge will be extracted and regarded as the constraint of the road region so that both the accurate road region and the road boundary can be acquired simultaneously.
During the course of Canny edge detection, we have to handle the dilemma as follows: The less the parameter of edge strength selected, the more possible road boundary will be extracted, but it is difficult to extract the due road boundary from so many Canny edges; Increasing the parameter of edge strength will reduce the quantity of the Canny edges naturally, but some weak edges that located on road boundaries may be neglected inevitably.
In order to resolve the dilemma mentioned above, we combine the road region and non-road region with the Canny edges. Firstly, appropriate edge strength will be selected to produce enough strong and weak Canny edges. Secondly, redundant edges lie in deep non-road region or in deep road region will be removed.
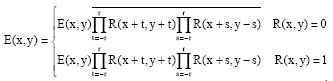 | (2) |
The principle of Canny edge filtering is described in Eq. 2, where, E(x, y) means whether the pixel (x, y) is the edge or not (1: edge; 0: non-edge); R(x, y) means whether the pixel (x, y) is the road region or not (1: road region; 0: non-road region); r is the depth threshold and the upper line in the right part of the Eq. 2 means the negative operator.
After the redundant Canny edges have been filtered by road and non-road region, the remaining edges will be used to produce several lines by Hough Transform. One or two of those lines will be selected to fit nearby left or right road boundary by considering the distance from the vehicle to the line, the mean strength of the Hough line, as well as each line’s orientations.
MONTE CARLO METHOD
For most small curvature roads, nearby road boundary can be fitted by straight line. Therefore, the Hough transform was used to detect the road boundary in this work for the reason that it is invariant to pixel position in an image. In Hough space, each edge segment is responding to a certain line and each line can be represent with L(ρ, θ), where, ρ is the distance from the line to ALV and θ is the angle that the line makes to the Ox-coordinate axis. Taking into account the dynamics model of the vehicle, ALV can predict the variation of L(ρ, θ) with its moving.
Dynamics of ALV: The dynamics of ALV is expressed in Eq. 3, where, (Δxk, Δyk, Δθk) is the variation of the vehicle’s pose (position and orientation) at time k, ![]() is the velocity space composed of linear velocity and angular velocity
is the velocity space composed of linear velocity and angular velocity ![]() .
.
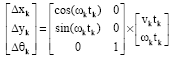 | (3) |
Considering most vehicles have the capability of acquiring its velocity information rather than its position and orientation in certain global reference frame, only the distance ρ and the angle θ of a possible road boundary in the vehicle’s reference frame are calculated in the dynamics of ALV.
| (4) |
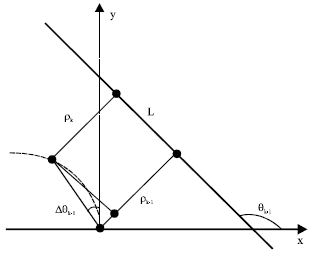 | |
| Fig. 1: | Prediction of L(ρ, θ) |
When ALV moves forward with velocity ![]() at time step k, based on Fig. 1 and Eq. 3, the prediction of L(ρ, θ) at time step k can be calculated by Eq. 4.
at time step k, based on Fig. 1 and Eq. 3, the prediction of L(ρ, θ) at time step k can be calculated by Eq. 4.
Monte Carlo method: Provided the belief of the system state at time t, Lt, is represented by Bel(Lt), apparently, Bel(Lt) also means the possibility that the ith line li in Hough space belongs to left or right road boundary. According to the Bayes law and Markov assumption (past and future data are independent if the current state of the system is known ), Bel(Lt)can be updated by both the perception model and the motion model:
| (5) |
where, η is a normalizing constant. Perceptual model p(ot|Lt) means the valuation of Lt purely depending on the perception information captured by vision system on board. In motion model p(Lt|Lt-1,ut-1), the estimation of current state Lt depends not only on the belief of previous state Lt-1, but also on the past neighboring executed action ut-1, that could be calculated in Eq. 3.
To acquire L(ρ, θ) in real-world coordinates, the corresponding relation between the Hough line in image and the road boundary in actual surroundings should be considered. However, limited to the content of the study, this part will not be discussed.
Representing the continuous probability density function (pdf) by a set of n weighted samples is computationally more efficient and proves satisfactory also for representation of multi-modal and non-Gaussian belief states if the number n is sufficiently large:
| (6) |
where, Lt(i) is a sample state of the random variable Lt and the non-negative numerical factor ![]() is an importancy weight factor representing probability measure of each particle. The Lt(i) is defined as
is an importancy weight factor representing probability measure of each particle. The Lt(i) is defined as ![]() with the probability
with the probability ![]() associated to this hypothesis.
associated to this hypothesis.
Traditional Monte Carlo method at each time step comprises of three steps:
| • | Resampling: Resample N samples randomly from Lt-1 according to the distribution defined by |
| • | Importance sampling: Sample state Lt(i) from p(Lt|Lt-1,ut-1), for each of the N possible state Lt(i) and evaluate the importance factor |
| • | Summary: Normalize the important factors |
Since, samples are actually drawn from a proposal density, if the observation density moves into one of the tails of the proposal density, most of the samples’ non-normalized importance factors will be small. In this case, a large sample size is needed to represent the true posterior density to ensure stable and precise tracking of the road boundary. Another problem is that samples often too quickly converge to a single, high likelihood pose. This might be undesirable in the environments have many line segment similar to the road boundary. To make the samples represent the posterior density better, proposed mixture Monte Carlo method, but it needs much additional computation in the sampling process (Thrun et al., 2001). To improve the efficiency of Monte Carlo method, methods adjusting sample size adaptively over time are proposed, but they increase the probability of premature convergence (Fox, 2003).
In this study, a new version of Monte Carlo method is proposed to overcome those limitations above. Different operation on particle sample and evaluation has been executed. At the step of importance sampling, the sample state Lt(i) will be produced from the perception model p(ot|Lt(i)) and the selected N possible state Lt-1(i) will be evaluated by the importance factor ![]() in motion model.
in motion model.
For lack of the priori knowledge of the road boundary such as the quantity of the lanes, the distance and the orientation etc., we approximate the perceptual model as Eq. 7, where, ![]() is described in Eq. 2:
is described in Eq. 2:
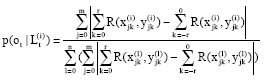 | (7) |
The above likelihood function has the advantage of being quick to evaluate. This is important for real-time operation since, it needs to be computed for every particle at each time step. However, its discrete form means that care must be taken in setting the threshold. Setting it too high results in reduced discrimination ; Reducing it increases discrimination, but requires greater coverage of the sampling space so that enough samples are drawn around significant modes. Unfortunately, increasing the number of samples to achieve this quickly becomes prohibitive. To address this, we use particle annealing, in which samples are iteratively focused onto potential modes, whilst gradually reducing the threshold (Deutscher et al., 2000).
At each time step, we use a large value for the threshold to obtain an initial set of weighted particles. Annealing then proceeds by resampling from this set using a uniform distribution with a smaller width than that used to propagate the samples from the previous time step. An updated set of weighted particles is then obtained using a smaller value of the threshold in the likelihood and this initializes the next annealing step. The process continues using smaller and smaller values of annealing velocity and the threshold, resulting in greater concentration of the samples around modes in the state space.
Due to the fact that the particle sampling takes place in perception model rather than in motion model, we can adjust the size of the particles adaptively to the quantity of the Hough line detected in perception model. Therefore, the proposed method is robust to the variation of the environment: when the surroundings have too much disturbance, the increasing of the particles precise the tracking of the due road boundary; On the contrary, if the background is becoming simple, the decreasing of the particle means the quick reaction to the environment.
RESULTS
To validate the proposed algorithm in this study, several experiments on road detection have been executed in campus roads. The images were acquired in different scenes and different illuminations so that the proposed method can be assessed appropriately.
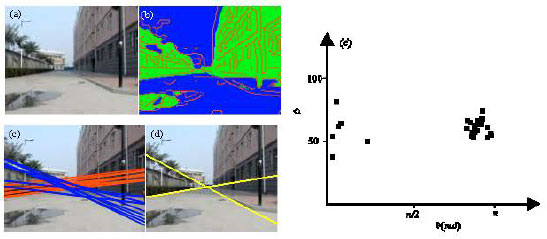 | |
| Fig. 2: | Negative effects caused by water mark. (a) Original image, (b) Otsu-edge image, (c) candidate Hough line, (d) result of road boundary and (e) particle distribution |
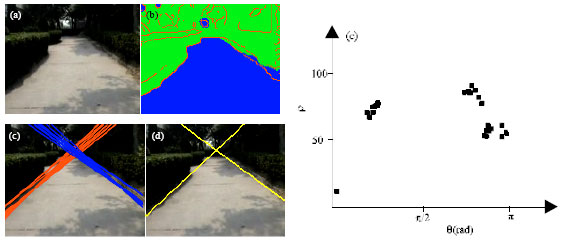 | |
| Fig. 3: | Road detection under the condition of shadows, surface dilapidation. (a) Original image, (b) OTSU-edge image, (c) candidate Hough line, (d) result of road boundary and (e) particle distribution |
Experiments on road detection: The Negative impacts such as the illumination variation, the strong shadows, the surface dilapidation as well as the nearby buildings that have similar intensity features have tested by the single camera installed on the ALV.
Figure 2a-e showed us the negative effects result from watermark. The adaptive selection of the particle size is visually shown in Fig. 2, in which the particle distribution shown in Fig. 2e is corresponding to the Hough lines shown in Fig. 2c. In Fig. 2e, θ means the orientation between the Hough line and the positive x-coordinates and ñ means the image distance from the Hough line to the middle bottom point of the image.
Though the watermark in Fig. 2b was mistaken for non-road region by Otsu thresholding method (green region), the road boundary in Fig. 2d could be recognized among the candidate Hough lines shown in Fig. 2c by virtue of Monte Carlo method. The distribution of the particle was shown in Fig. 2e, where all the particles huddle in different regions.
Figure 3a-e showed us the experimental results when shadows, surface dilapidation happen simultaneously. Fig. 3b indicated that when most Canny edges on both background and the road surface were removed by Otsu thresholding image, the detail of the weak road boundary was well preserved.
In Fig. 4a-e both the road surface and the nearby buildings had the similar color and intensity features. By combining the road region segmentation, the Monte Carlo method with the road boundary extraction, the road’s boundary could be recognized correctly.
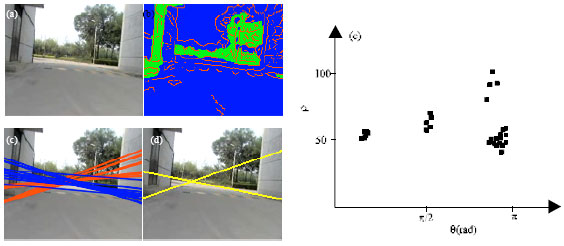 | |
| Fig. 4: | Negative impacts result from similar scene. (a) Original image, (b) Otsu-edge image, (c) candidate Hough line, (d) result of road boundary and (e) particle distribution |
CONCLUSION
A novel road detection algorithm that combined the road region segmentation, the Monte Carlo method with the road boundary extraction was proposed in this study. Road detection experiments illustrate that the proposed method is not only robust to such negative impacts as illumination variation, strong shadows, surface dilapidation and water marks, but also it can meet the requirement of real-world navigation for autonomous land vehicle.
ACKNOWLEDGMENTS
This study has been supported by Major Program of National Natural Science Foundation of China (grant No. 90820306) and supported by the Special funds for the Research on Scientific Creation and Talent People (grant No. 2008RFQXG067) and Supported by Educational Commission Science and Technology of Heilongjiang Province of China (grant No. 11541040; 11541050).
REFERENCES
- Deutscher, J., A. Blake and I. Reid, 2000. Articulated body motion capture by annealed particle filtering. Proc. Int. Conf. Comput.Vision Pattern Recognition, 2: 126-133.
CrossRef - Otsu, N., 1979. A threshold selection method from gray-level histogram. IEEE Trans. Syst. Man Cybern., 9: 62-66.
CrossRefDirect Link - Turina, A., T. Tuytelaars and L. van Gool, 2001. Efficient grouping under perspective skew. Proc. Comput. Vision Pattern Recognition, 1: I-247-I-254.
CrossRef - Schaffalitzky, F. and A. Zisserman, 2000. Planar grouping for automatic detection of vanishing lines and points. Image Vision Comput., 9: 647-658.
CrossRef - Fox, D., 2003. Adapting the sample size in particle filters through KLD-sampling. Int. J. Robot. Res., 22: 985-1004.
CrossRef - Crisman, J.D. and C.E. Thorpe, 1993. SCARF: A color vision system that tracks roads and intersections. IEEE Trans. Robotics Automation, 9: 49-58.
CrossRef - Crisman, J.D. and C.E. Thorpe, 1991. UNSCARF: a color vision system for the detection of unstructured Roads. Proc. IEEE Int. Conf. Robotics Automation IEEE Comput. Soc., 3: 2496-2501.
CrossRef - Kluge, K. and C. Thorpe, 1992. Representation and recovery of road geometry in YARF. Proceedings of the IEEE Symposium Intelligent Vehicles, June 29-July 1, Carnegie Mellon Univ., Pittsburgh, PA., pp: 114-119.
Direct Link - Bertozzi, M. and A. Broggi, 1998. GOLD: A parallel real-time stereo vision system for generic obstacle and lane detection. IEEE Trans. Image Process., 7: 62-81.
CrossRefDirect Link - Simond, N. and P. Rives, 2003. Homography from a vanishing point in urban scenes. Proc. Int. Conf. Intel. Robots Syst., 1: 1005-1010.
CrossRef - Conrad, P. and M. Foedisch, 2003. Performance evaluation of color based road detection using neural nets and support vector machines. Proceedings of the Applied Imagery Pattern Recognition Workshop, Oct. 15-17, Washington, DC., pp: 157-160.
Direct Link - Se, S. and M. Brady, 2000. Vision-based detection of staircases. Proc. 4th Asian Conf. Comp. Vision ACCV, 1: 535-540.
Direct Link - Thrun, S., D. Fox and W. Burgard, 2001. Robust monte carlo localization for mobile robots. Artificial Intel., 128: 99-141.
CrossRef - Nguyen, T.T., X.D. Pham and J.W. Jeon, 2009. Rectangular object tracking based on standard hough transform. Proceedings of the IEEE International Conference on Robotics and Biomimetics, Feb. 22-25, IEEE., pp: 2098-2013.
Direct Link - He, Y., H. Wang and B. Zhang, 2004. Color-based road detection in urban traffic scenes. IEEE Trans. Intel. Transport. Syst., 1: 309-318.
Direct Link