
Zhongjie Wang
Research Center of Intelligent Computing for Enterprises and Services,
School of Computer Science and Technology, Harbin Institute of Technology,
P.O. Box 315, No. 92 West Da Zhi Street, Harbin, Heilongjiang, China
Dechen Zhan
Research Center of Intelligent Computing for Enterprises and Services,
School of Computer Science and Technology, Harbin Institute of Technology,
P.O. Box 315, No. 92 West Da Zhi Street, Harbin, Heilongjiang, China
Xiaofei Xu
Research Center of Intelligent Computing for Enterprises and Services,
School of Computer Science and Technology, Harbin Institute of Technology,
P.O. Box 315, No. 92 West Da Zhi Street, Harbin, Heilongjiang, China
Information Technology Journal
Year: 2008 | Volume: 7 | Issue: 3 | Page No.: 474-481







ABSTRACT
In this research, we put forward a general approach for designing components from multiple domain applications by optimizing degree of variability of components, to reach a global optimization between usefulness and usability and maximize global reusability performance of components. A simplified software component model and its usability metrics are firstly introduced. Then process of variability optimization oriented component design is put forward. Three important issues in this approach, i.e., choosing variability policies (negative or positive), determining degree of variability based on semantics abstraction tree (SAT) partitioning and component structure design by composing multiple dimensions, with some primary solutions, are briefly discussed.
PDF Abstract XML References Citation
How to cite this article
Zhongjie Wang, Dechen Zhan and Xiaofei Xu, 2008. A General Approach for Optimizing Degree of Variability of Software Components. Information Technology Journal, 7: 474-481.
DOI: 10.3923/itj.2008.474.481
URL: https://scialert.net/abstract/?doi=itj.2008.474.481
DOI: 10.3923/itj.2008.474.481
URL: https://scialert.net/abstract/?doi=itj.2008.474.481
INTRODUCTION
One of the most important goals of software engineering is to achieve large-scale reuse. From 1970s there has appeared the concept Software Component (Szyperski, 1998) and researchers imported Reuse-Based Software Engineering (RBSE) (Mili et al., 2002) to design software components with higher reusability. There is a core step named Domain Analysis (Kang et al., 1990), whose goal is to find commonalities between various applications in a specific domain and encapsulate them in a reusable component by abstraction and variability techniques.
For example, a programmer tries to write a SORT function with an int-type array as its parameter. To improve its reusability, he extends the function so that it could deal with any data types, e.g., float, double, char, etc. Another typical example may be found from Addy et al. (1999), where aiming at the domain of waiting queue simulations, a reusable system is required to have the ability of dealing with ten similar applications, e.g., CPU dispatching, self-serve car wash, check-out counters, immigration posts, etc.
Surely domain analysis has a quite good objective and it has been widely put in practice in the past decades. However in real world, there exists an issue that has been little noticed. For instance, we`ve ever met the following typical scenarios:
| • | Domain analyzers have designed a good component model but programmers cannot (or are difficult to) transform it to executable codes, just because the component model is so abstract and containing too much variation points that make it quite difficult for programmers to understand and implement. |
| • | Even such components are finally implemented by paying innumerable trials and hardships, some of them are kept on the shelf for long time, even if their reusability is high. This is because a lot of work (e.g., instantiations, configurations or extensions) must be done before reusing such components. |
Take philosophy as a metaphor. In philosophy, things in real world are abstracted as two general concepts (substance and spirit) that have the largest reusability, but how many people will directly use them to describe concrete things? -Seldom. Similarly in domain analysis, it is not always true that the higher degree of abstraction, the higher reusability, then the better. Besides reusability, analyzers should carefully consider some other questions, too, e.g., can the abstraction be easily implemented, how much cost must be paid in order to reuse it, etc. If implementation cost or reuse cost of a component is too heavy or even severely counteracts the benefits brought from high reusability, then it is not necessary to do so deep abstraction.
Mili et al. (2002) decomposed reusability into two sub-metrics, i.e., usefulness and usability. The former one concerns with the extent to which a reusable component will often be needed, while the latter one refers to the extent to which a software component is easy to use. Most of practitioners pay most of their attentions to usefulness while ignore the optimization on usability. In fact, that is a tradeoff between the two metrics and such tradeoff is closely related to the degree of abstraction (or degree of variability) of a component. There has reached a consensus that, the higher degree of variability a component has, the more reuse opportunities it has, then the higher reusability; however at the same time, it will lead to more complex design, lower developing efficiency and higher reuse cost; and vice visa.
Concerning domain analysis and software reuse, there have been a lot of mature theories and methodologies that have been widely applied. For example, there are tens of domain analysis methods, e.g., FOAD (Kang et al., 1990), FORM (Kang et al., 1998), ODM (Simos, 1995), etc. Various reuse techniques are emphatically imported into Object-Oriented Programming, Component-Based Development (CBD) and Service-Oriented Architecture (SOA). However, all such methods focus on the optimization of usefulness. Although Mili et al. (2002) presented the concept usability, they just considered it from extrinsic and intrinsic packaging styles, e.g., rationality of components static structure, completeness and undestandability of components description information, while ignored the tradeoff mentioned earlier.
This research will do some primary attempts on this issue. Reuse-oriented and variability-based component model is firstly analyzed in retrospect, with several usability metrics presented. Then, a general process for component variability optimization is put forward, with some brief discussions on three key technical steps to find an optimal solution for the tradeoff.
SOFTWARE COMPONENT MODEL AND ITS USABILITY METRICS
Three separate parts of a reusable component: The reason a component is reusable is that it contains some functions which are common to various applications. Generally speaking, a reusable may be decomposed into three parts (Mili et al., 2002), i.e.,
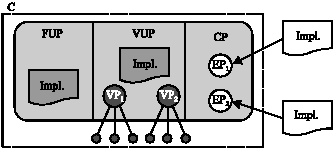 | |
| Fig. 1: | Three separate parts of a reusable component |
| • | Fixed Universal Part (FUP): No matter they are reused in which specific application, such parts are completely the same and could be directly reused without any modifications, extensions or abridgements; |
| • | Variable Universal Part (VUP): Functions provided in such parts, abstracted from different but similar applications, have to be instantiated or configured to a concrete form when they are reused in a specific application. To support such purpose, variation point (VP) based mechanism is applied, where each variation point has a set of configuration parameters. Aiming at a specific reuse situation, each parameter is assigned with a specific value so as to make the component exhibit expected behaviors; |
| • | Customized Part (CP): Functions in this part are quite different for various applications in a domain and they cannot be abstracted to a unified form. Implementations of this part are in most circumstances not contained in the component but should be further reinforced by application developers when it is reused in a specific application. A component might provide some extension point (EP) based mechanism for such purpose. |
Figure 1 shows an example of a reusable component composed of FUP, VUP and CP and there are two variation points VP1 and VP2 in VUP and two extension points EP1 and EP2 in CP. The dashed rectangle represents scope of the component.
Coarse-grained component reuse: Along with the flourish of reuse-related technologies, one of the most distinct trends in this field is coarse-grained reuse (Helton, 1998), not only for improving reuse efficiency, but also for maintaining a direct mapping from real-life business. Especially in the development of enterprise software and applications (e.g., ERP and SCM), there have gradually appeared business form (e.g., procurement orders, bill of lading, sales order, etc.) based coarse-grained component reuse (Wang et al., 2007).
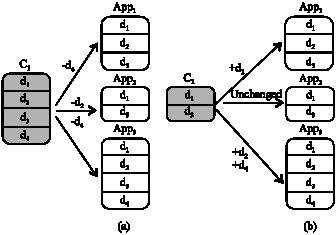 | |
| Fig. 2: | Negative and positive variability policies (a) Negative variability (NV) and (b) Positive variability (PV) |
Design and implementation of such coarse-grained components are more complex and difficult than traditional fine-grained components, not only because it should support multiple complicated application scenarios, but also because unitary dimension cannot fully cover all aspects of its functions but have to make use of multiple dimensions for complete descriptions.
For example, in manufacturing enterprises there are various types of procurement orders (PO), e.g., PO for production materials, PO for fuels, PO for equipments, etc and in order for reuse, we wish to develop one abstract PO component instead of developing three independent PO components. Such abstract component is composed of tens of functional dimensions, e.g., data set, business operations, user interfaces, etc. For the waiting queue simulation system (Mili et al., 2002), designers should consider multiple dimensions, too, e.g., topology of service stations, length of service time, customer arrival distribution, dispatching policy, etc.
Negative and positive abstraction: There are two opposite abstraction policies, i.e., positive and negative variability (Mili et al., 2002). Positive variability (P/V) starts with a minimal core and selectively adds additional parts based on the presence or absence of features in the configuration models during reuse. While negative variability (N/V) selectively takes away parts of a creative construction model based on the presence or absence of features in the configuration models during reuse (Groher and Voelter, 2007).
For example in Fig. 2, component C1 is designed following N/V and C2 is designed following P/V. When they are reused for developing three applications App1, App2 and App3, different modifications should be considered.
In practice, the two policies are both widely applied. But aiming at a specific domain, it should take some time for domain analyzers to elaborately determine which one is more proper to be adopted. Generally speaking, implementing a positive variability is relatively easy, but requires a lot of works when it is reused. Implementing a negative variability is relatively complex, but does not require too much works when it is reused (except pruning those unnecessary functions).
Metrics for usability: In literatures there have numerous metrics for measuring quality and performance of a component (Mili et al., 2001). Here we just present several new metrics closely related to usability and variability optimization.
| • | Usefulness, measured by the total number of applications where a component may be reused, or the percent of applications where a component could be reused in a specific domain. For example, there are n possible applications in a domain and a component may be reused in m ones, then its usefulness is m/n. |
| • | Development Cost (DC): Total cost for designing and implementing a reusable component from multiple applications. DC is often closely related to the degree of variability. From our empirical study, developing a high abstract component would pay more cost than, respectively developing n different but similar concrete components, although the latter situation requires developing more LOC than the former. For simplification, we use the average time t for implementing a component c by a programmer who is in average programming level, to measure DC of c. |
| • | Reuse Cost (RC): Total cost for reusing a component in a specific application. RC is further considered as the sum of three sub-costs, i.e., cost for deleting those unnecessary functions, cost for instantiating abstract dimensions to required concretions by specifying value of each parameter and cost for implementing unfulfilled functions (i.e., extension). |
PROCESS FOR COMPONENT VARIABILITY OPTIMIZATION
Suppose in domain D there are n different applications {a1, a2, …, an}. Our purpose is to design one or several components to cover all the n applications as far as possible and reach a tradeoff optimization between usability and usefulness of components.
Firstly we denote applications as the form of multi-dimensional vectors. Suppose that in order to completely describe domain D, m inter-independent dimensions are required, i.e., {d1, d2, …, dm}, with the following features:
| • | Some dimensions are common to all applications, while for other dimensions, only one or some of the applications have and the others have not |
| • | Some dimensions are mandatory while others are optional |
| • | It is possible that all applications have the same value on a specific dimension, or have multiple different values |
| • | There are value dependencies between dimensions, e.g., if a dimension di is instantiated to a specific value, another dimension dj must be instantiated to some specific values |
| • | Each dimension depicts one specific semantics aspect of the domain and different dimensions cannot be abstracted as one dimension. Therefore during domain analysis, these dimensions should be separately considered First we put forward two questions, i.e., |
Q1: Which dimensions should be reserved in final components and which should be ignored? That is to say, choose N/V or P/V policies for each dimension
Q2: If a dimension is to be kept in final components, how about its representation styles? That is to say, does the dimension belong to FUP, VUP or CP? If it belongs to VUP, what degree of variability it should have?
To answer Q1, a method is necessary to help judge the worth of each dimension.
To answer Q2, supposing a dimension di has totally t different values {vi1, vi2, …, vit} in m applications (of course t&≤n and m&≤n) and other n-m applications do not contain di at all, we then identify di as one of the following five types, i.e.,
| S1: | t = 1, m = n |
| S2: | t = 1, m<n |
| S3: | 1<t≤n, m = n |
| S4: | 1<t≤n, m<n |
| S5: | t = 1, m = 1 |
Here another two questions are raised:
Q21: For each value of a dimension, should it be reserved in final components or not? That is to say, choose N/V or P/V policies for each value of a dimension;
Q22: For S3 and S4, since there are multiple values for a dimension, what degree of variability of the dimension should be kept in final components? For example, should these values be abstracted to one value with highest
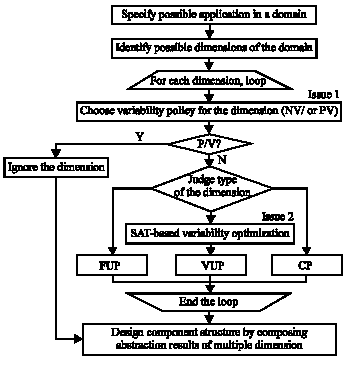 | |
| Fig. 3: | Process of variability optimization oriented component design |
degree of variability, to q (1<q<t) values, or just kept the t values un-abstracted?
| • | For Q21, we will adopt to the same method to be discussed |
| • | For Q22, there are three possible solutions |
| • | For S1 and S2, directly form FUP of the final component |
| • | For S3 and S4, use specific strategy to determine the degree of variability, then form one abstract, several semi-abstract or several concrete values to form VUP of the final component |
| • | For S5, directly form CP of the final component |
After obtaining FUP, VUP and CP, the last step of component design is to consider how to compose these dimensions together to get the final component.
In conclusion, variability optimization oriented component design process is shown in Fig. 3.
THREE KEY ISSUES ABOUT VARIABILITY OPTIMIZATION
Choosing negative or positive variability policy: As mentioned earlier, there are two separate places where elaborate selection between N/V and P/V is required, i.e.,
| • | For a specific dimension di |
| • | For a specific value vij of a specific dimension di |
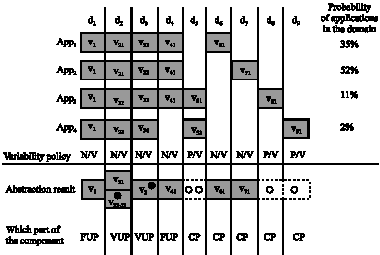 | |
| Fig. 4: | Strategies for designing FUP, VUP and CP of a component by dimension analysis |
Here we apply a very simple strategy to solve this issue, i.e., if a dimension has more chances to appear in most of applications of the domain, then it shows it is valuable to be reused, therefore N/V policy should be adopted; on the contrary, if only a small number of applications contain this dimension, then it has no enough value to be kept in the component and this dimension will be cast away and P/V is adopted.
Formally speaking, suppose the percent of n applications in domain D are, respectively g1, g2, …, gn where
and for a dimension di, there are p applications {ai1, ai2,…, aip} containing di, whose percent are respectively gi1, gi2,…, gip. So, if
(T is a threshold), di will be kept using N/V policy, i.e., if such component is to be reused for developing ai1, ai2,…, aip, it is not necessary to re-develop di; while when it is to be reused for those applications out of {ai1, ai2,…, aip}, the implementation of di has to be manually pruned.
Similarly,
if, then di will be thrown away by using P/V policy, i.e., if such component is to be reused for developing ai1, ai2,…, aip, any extra work are unnecessary for this dimension and for those applications out of {ai1, ai2,…, aip}, developers have to manually write some code for implementing di.
For example in Fig. 4 where there are four applications app1~app4 that are described by nine independent dimensions d1~d9, we could easily find the best variability policy of each dimension according to the method mentioned earlier.
In real world, it is sometimes difficult to specify probability of each application in the domain before experiencing large-scale or long-period reuse. In this situation, experiences and knowledge of domain specialists, or investigation on requirements of future potential customers, will be imported to help determine whether N/V or P/V is adopted.
When choosing N/V or P/V for each value vij of a dimension di, the same strategy is adopted, i.e., if the total reuse probability of vij in the domain is above the threshold, it should be implemented and kept in final component by variation point mechanism; otherwise, it will be ignored in final component by extension point mechanism.
As an empirical result, value of the threshold (T) is usually set between 0.25 and 0.3. Practitioners may adjust this threshold according to specific reuse strategies of their own product lines.
Determining degree of variability based on Semantics Abstraction Tree (SAT) partitioning: This sub-section tries to solve the issue that, how to determine degree of variability for optimization.
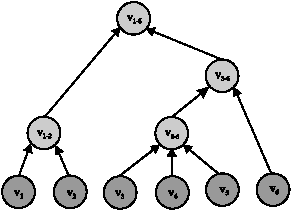
Because of ideation limitations of human beings, when people think about a complex problem, they usually firstly deal with simpler issues, then gradually with more complex issues and finally the most difficult ones. Therefore when trying to do abstraction on m different values {vi1, vi2,…, vim} of a specific dimension di, steps of the abstraction process usually form a hierarchical tree, which is called Semantics Abstraction Tree (SAT). Figure 5 shows a simple example of SAT.
There are two types of nodes in SAT, i.e., concrete node (CN) and abstract node (AN), where CN are leaf nodes and locate in the bottom layer of SAT and reflect concrete requirements from various specific domain applications; contrarily, AN are non-leaf nodes and locate in the middle or top layer of SAT and reflect the final or interim abstraction results.
 | |
| Fig. 5: | An example of Semantics Abstraction Tree (SAT) |
There may possibly multiple layers in a SAT and the higher layer a node locates in, the higher degree of variability it has.
In SAT, an edge with the direction from lower to higher layer represents an instantiation-generalization relationship between nodes directly connected by the edge. In OO, CBD and SOA there have been a series of abstraction techniques and Mili et al. (2002) did a summarization about these techniques from high level. Due to limited space, we will not list them here in detail.
Take Fig. 5 as examples, where v1 and v2 are firstly abstracted to v1-2, v3, v4 and v5 are abstracted to v3-5, then v3-5 and v6 are merged to form v3-6 and finally v1-2 and v3-6 are abstracted to v1-6.
Every node has three attributes related to its reusability, i.e., usefulness, development cost (DC) and reuse cost (RC), all of which has been briefly discussed earlier. For arbitrary node N,
| • | UF(N), denoting the usefulness of N, is measured by the total number of leaf-nodes contained in the descendant of N |
| • | DC(N), denoting the total cost of abstracting N`s all children nodes to N and implementing N as program codes, is measured by the number of Man-Month required to fulfill such abstraction and development |
| • | RC(N), denoting the total cost of reusing N if N is included in the final component, e.g., instantiating N to one of its descendant leaf-nodes, is measured by the number of Man-Month required to fulfill such instantiation and configuration |
As mentioned earlier, there is a tradeoff between these attributes. For instance, if we just consider optimization on usefulness, the best solution is to do abstraction as far as possible, i.e., the nearer to the root of SAT, the better.
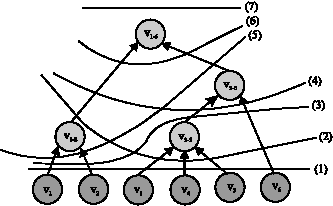 | |
| Fig. 6: | Partitioning SAT for variability optimization |
However for optimization on RC and DC, it is completely opposite, i.e., the farther to the root of SAT, the better. Hence it is quite necessary to find a proper boundary to partition SAT as two parts, where we just realize the abstraction under the boundary and for the part above the boundary, we just ignore it, to ensure a global optimization between usefulness, DC and RC.
Aiming at the SAT in Fig. 5, there are seven possible partition solutions, which are marked in Fig. 6 by thick real lines. Take (4) as an example, where it means v1 and v2 are abstracted to v1-2, v3, v4 and v5 are abstracted to v3-5, while for the abstractions from v3-5 and v6 to v3-6 and from v1-2 and v3-6 to v1-6, it is not necessary any longer. Therefore the dimension with six concrete values {v1, v2, v3, v4, v5, v6} is finally abstracted to three semi-abstract values {v1-2, v3-5, v6}.
Since there are multiple partitioning approaches, which one is the best? This is an optimization problem whose objective is represented as the following:
Where:
| Ni | = | (1&≤i&≤n) is a node in the SAT |
| xi | = | if Ni is above the partition boundary |
| xi | = | 1 if Ni is below the boundary |
If size of an SAT is small and there are only finite partitioning solutions, then list all possible solutions and calculate the objective to find the optimal one. If size of an SAT is too large and there are too many partitioning solutions, a linear programming or evolutionary algorithm is employed for reasonable time complexity. Detailed algorithms will not be shown here.
Designing component structure by composing multiple dimensions: From the analysis we have seen that, after partitioning SAT of a dimension, the number of values of this dimension is reduced to some extent.
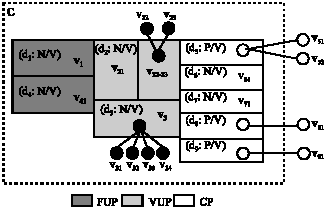 | |
| Fig. 7: | Composing multiple dimensions into a reusable component |
Besides an extreme situation where the dimension is fully abstracted to a single value, i.e., root node of its SAT (e.g., in Fig. 4, d3`s four values v31, v32, v33 and v34 are abstracted to one value v3), in other situations there are still more than one values that should be kept in final components (e.g., in Fig. 4, d2`s three values v21, v22 and v23 are abstracted to two values v21 and v22-23).
In addition, since multiple dimensions are inter-related with each other, we have to find a way to compose the abstraction results of all dimensions together to form an integrated component and fairly identify what structure the component has.
For a dimension di, think about five situations (S1 to S5):
| • | If di is satisfied with S1 or S2, di will be mapped to a part of FUP |
| • | If di is satisfied with S3 or S4, di will be mapped to a part of VUP and for di`s values formed from the partitioning of its SAT, they are mapped to a variation point of the component |
| • | If di is satisfied with S5, di will be directly mapped to a part of CP |
| • | If di is completely ignored or some of di`s values are ignored by following P/V policy, then add an extension point for each of them in CP |
For better understanding, Fig. 7 shows the structure of the final component C according to the abstract results in Fig. 4. FUP of C is composed of two dimensions d1 and d4. VUP of C is composed of two dimensions d2 and d3, where d2 is abstracted to two different values v21 and v22-23 and d3 is abstracted to a single value v3. CP of C contains five dimensions d5, d6, d7, d8 and d9, where d6 and d7 are fully implemented because they follow N/V policy, while d5, d8 and d9 are designed as extension points because they follow P/V policy.
CONCLUSIONS
In this research, we discuss a neglected issue in domain analysis, i.e., tradeoff between usability and usefulness. We elaborately analyze the reason why the tradeoff comes into existence, then briefly put forward our process for designing a reusable component from multiple domain applications. This process seeks a global optimal solution by optimizing degree of variability, containing three key technical problems, i.e., choosing abstraction policy (negative or positive), finding optimal degree of variability and designing structure of the final component. Our work are partially applied in analysis of procurement domain in manufacturing enterprises and statistical shows that DC, RC and usefulness of identified/developed components are synthetically improved.
Future works include: (1) summarize various abstraction techniques and quantitatively measure their development cost and reuse cost; (2) design a more practical method for determining variability policies (P/V or N/V); (3) design and implement a linear programming based algorithm for partitioning SAT.
ACKNOWLEDGMENTS
Research works in this paper are partial supported by the National Natural Science Foundation (NSF) of China (60773064, 60673025), the National High-Tech Research and Development Plan of China (2006AA01Z167) and the Development Program for Outstanding Young Teachers in Harbin Institute of Technology (HITQNJS.2007.033).
REFERENCES
- Addy, E., A. Mili and S. Yacoub, 1999. A case study in software reuse. Software Qual. J., 8: 169-195.
CrossRefDirect Link - Helton, D., 1998. The impact of large-scale component and framework application development on business. Proceedings of the Workshop ION on Object-Oriented Technology, July 20-24, 1998, Springer-Verlag, London, UK., pp: 163-164.
Direct Link - Kang, K.C., S. Kim, J. Lee, K. Kim, E. Shin and M. Huh, 1998. FORM: A feature-oriented reuse method with domain-specific reference architectures. Ann. Software Eng., 5: 143-168.
Direct Link - Mili, A., S. Chmiel, R. Gottumukkala and L. Zhang, 2001. Managing software reuse economics: An integrated ROI-based model. Ann. Software Eng., 11: 175-218.
CrossRefDirect Link - Wang, Z.J., D.C. Zhan, X.F. Xu, M.R. Yang and Z. Chen, 2007. Code generator for enterprise software and applications based on business object association model. Comput. Integr. Manuf. Syst., 13: 1021-1029.
Direct Link