
U.M. Okeh
Department of Industrial Mathematics and Applied Statistics, Ebonyi State University, Abakaliki, Nigeria
LiveDNA: 234.16012
I. Onyeagu Sidney
Department of Statistics, Nnamdi Azikiwe University Awka, Anambra, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2020 | Volume: 13 | Issue: 1 | Page No.: 14-20







ABSTRACT
Background and Objectives: Receiver Operating Characteristic (ROC) analysis has been used as a popular technique of comparing the performance of two paired diagnostic tests data while the Area under the Curve (AUC) summarizes the overall activities between two ROC curves. This study was aimed at assessing a difference in the AUCs of paired data where each non-diseased and diseased subject are both subjected to 2 diagnostic test procedures as well as to tackle the problem of exchangeability of the labels between two diagnostic tests within subject which characterizes previous studies. Materials and Methods: A modified Wilcoxon Signed-Rank Test to accommodate the presence of tied absolute values of differences for assessing a difference in the AUCs in a continuous matched pair of data was proposed. A real data was analyzed to compare the proposed test and that of standard test as well as the 2 diagnostic tests. Results: Test reveals that the p-values for 2 h 70 g OGTT and 2 h 100 g OGTT for the non-diseased subjects are, respectively 0.6124 and 0.8975 while that of diseased subjects are, respectively 0.6345 and 0.8765. The estimates of AUC1 and AUC2 for diagnostic tests are 0.668 and 0.887, respectively. Conclusion: Result showed that the proposed test is more powerful than the standard test. Also 2 h 100 g OGTT diagnostic test is superior to 2 h 70 g OGTT diagnostic test at a time that the specificity is greater than 0.7.
PDF Abstract XML References Citation
Copyright: © 2020. This is an open access article distributed under the terms of the creative commons attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
How to cite this article
U.M. Okeh and I. Onyeagu Sidney, 2020. Comparison of Two Diagnostic Test Procedures Using Modified Wilcoxon Signed Rank Test. Asian Journal of Mathematics & Statistics, 13: 14-20.
DOI: 10.3923/ajms.2020.14.20
URL: https://scialert.net/abstract/?doi=ajms.2020.14.20
DOI: 10.3923/ajms.2020.14.20
URL: https://scialert.net/abstract/?doi=ajms.2020.14.20
INTRODUCTION
In nonparametric inference, they first derived the Area Under the Curve (AUC) test1 and proposed a test where paired data accounted for correlations2. Similarly, they constructed a nonparametric area test to compare two empirical AUC estimates2. The AUC is defined as the probability that the observed value of the diagnostic test will be greater for a randomly selected diseased individual than for a randomly selected non-diseased individual if higher values of a diagnostic test are associated with diseased subjects, while lower values are associated with non-diseased3. They developed a totally nonparametric approach to compare two correlated AUCs of two diagnostic tests for paired samples of subjects by using the theory of generalized U statistics3. In other words, they developed a conventional fully nonparametric approach leading to an asymptotically normal test statistic3. The test by DeLong et al.3 is limited by the fact that the AUC has an unbiased non-parametric estimator called the indicator variable that requires the comparison of all the number of subjects responding positive and negative, thus working with very large number of observations, so that computational time could be long. When the comparison of AUCs of two Receiver Operating Characteristic (ROC) curves was done, it can be estimated that which 1 of 2 diagnostic tests is more suitable for discriminating non-diseased subjects from diseased subjects4. To overcome the challenges occasioned by the area test of DeLong et al.3 which requires large sample sizes, a permutation test which thrives when the sample size is small was also proposed. In carrying out permutation tests involving diagnostic tests, two authors proposed a method for detecting any differences at every operating point between two ROC curves5. Similarly, other authors proposed a method that is sensitive to the difference in AUCs in diagnostic performance6. These tests assume the same condition of exchangeability of the diagnostic test results under the null hypothesis, but differ in the sense that the permutation test by Bandos et al.6 has an easy-to-implement and precise approximation and better detects different ROC curves if they differ with respect to the AUC while it was aimed to increase the power to detect a crossing alternative5. Specifically, Bandos et al.6 based their permutation test on the difference in areas and derived exact and asymptotic permutation test methods to test the equality of 2 correlated ROC curves which are designed to have increased power to detect difference in the AUC. The test of Bandos et al.6 directly tests for an equality of AUCs. This approach implicitly assumes that both diagnostic test procedures are exchangeable within subject and requires an appropriate transformation, such as ranks, for diagnostic test procedures differing in scale. Bandos et al.6 compared the performance of their test to that of DeLong et al.3 through simulation and found that the permutation test had greater power than the nonparametric test developed by DeLong et al.3 when there was moderate correlation between diagnostic tests, large AUCs and small sample sizes. Bandos et al.6 test is limited by the fact that it requires the exchangeability of the diagnostic test procedures and do requires also the transformations of the original data if test results are measured on different scales. Therefore, it requires diagnostic tests that are measured on identical scales. Therefore, it is less powerful in settings in which the diagnostic test results are skewed since it requires diagnostic tests that are measured on identical scales7. In order to obtain exact test in clinical trials which requires a given small sample size, Harris and Hardin8 proposed Wilcoxon Signed Rank (WSR) test. This is because large-sample results are not acceptable in many clinical trials studies. The WSR is the nonparametric counterpart to the two sample paired t-test for paired samples. The test is based on the signed ranks of a random sample from a population which is continuous and symmetric around the median. This statistic uses the ranks of the absolute differences between the paired samples along with the sign of the difference. It uses the relative magnitudes of the data. This statistic can also be used to test for symmetry and to test for equality of location for paired samples. The WSR test statistic utilizes both the magnitudes and signs of differences unlike the sign test proposed by Braun and Alonzo7 which utilizes only the signs of the differences between each observation and ignoring the magnitudes of these observations. Therefore, WSR test is expected to be more powerful test than the sign test. The essential assumptions for the WSR test are continuous and symmetric population distribution. Current study was aimed to assess a difference in the AUCs of paired data where non-diseased and diseased subject are both subjected to two diagnostic test procedures as well as to tackle the problem of exchangeability of the labels between two diagnostic tests within subject.
MATERIALS AND METHODS
Estimation of AUC: Given two diagnostic tests having N non-diseased subjects and M diseased subjects, let Xm and Ym (m = 1, 2) represents the subjects that are non-diseased and diseased in the mth diagnostic test, respectively. Then where, i = 1, 2,..., N and where, j = 1, 2,..., m are, respectively the corresponding bivariate test results for the two diagnostic tests with N non-diseased and M diseased subjects. Therefore, the marginal Fm (xm), Gm (ym) (m = 1, 2) corresponds to the bivariate cumulative distribution functions given as F (x1, x2) and G (y1, y2). The AUC is equal P (Y>X), which is the probability that the diseased subjects whose test results are positive is greater than the non-diseased subjects whose test results are negative9. Let AUCm (m = 1, 2) represents the AUCs of the ROC curves for the two diagnostic tests. The null hypothesis of the equality of two AUCs were tested3,6. Using the method of trapezoidal rule, the AUC for empirical ROC curve is computed9, but Hanley and McNeil1 demonstrated that AUC obtained using the trapezoidal rule under an empirical ROC curve is equivalent to the Mann-Whitney U statistic for comparing test results from two samples. According to Hanley and McNeil1, the AUC for a given diagnostic test is given by:
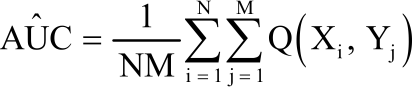 | (1) |
Where:
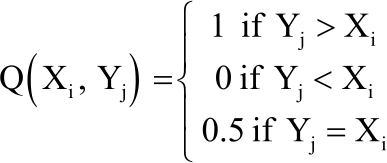 |
Where:
| Q | = | Indicator function comparing Xi and Yi |
| N | = | Number of non-diseased subjects |
| M | = | Number of diseased subjects |
| Xi | = | Test result of the ith non-diseased subject |
| Yj | = | Test result of jth diseased subject |
For mth diagnostic test the AUC is given by:
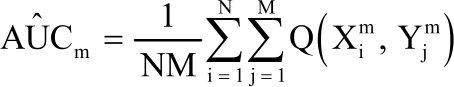 | (2) |
When the sampled test results are paired, represented as is given by:
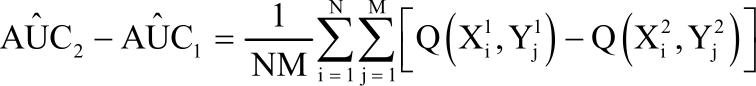 | (3) |
This shows the difference in the AUCs between two diagnostic tests.
Proposed method: The comparison of namely AUC1 and AUC2 which are, respectively the AUCs of two diagnostic test procedures having a total number of n subjects. The procedure is such that a total number of N non-diseased subjects and M diseased subjects each received both diagnostic tests. Let the test results of diagnostic tests 1 and 2 for the non-diseased subject be:
Xi1 and Xi2 |
where, i = 1,...N.
Also let the test results of diagnostic tests 1 and 2 for the diseased subject be:
Yj1 and Yj2 |
where, j = 1,..., M.
Also let X = {(X11, X12), (X21, X22),..., (XN1, XN2)} denotes pairs of vector of measurement on non-diseased subjects and let Y = {(Y11, Y12), (Y21, Y22),..., (YM1, YM2)} be the pairs of vector of measurement on diseased subjects. Therefore, the difference in AUCs given as AUCΔ = AUC2-AUC1 is estimated nonparametrically as:
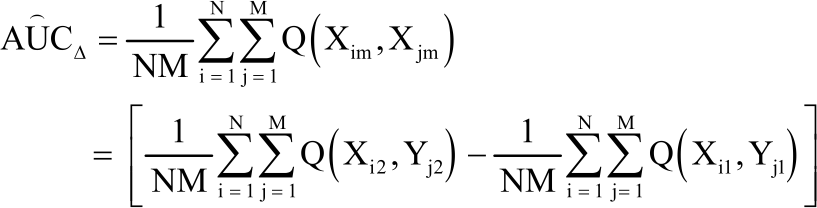 | (4) |
Where:
Q ( Xim, Yjm) = Sij2 - Sij1 = Sijm |
and:
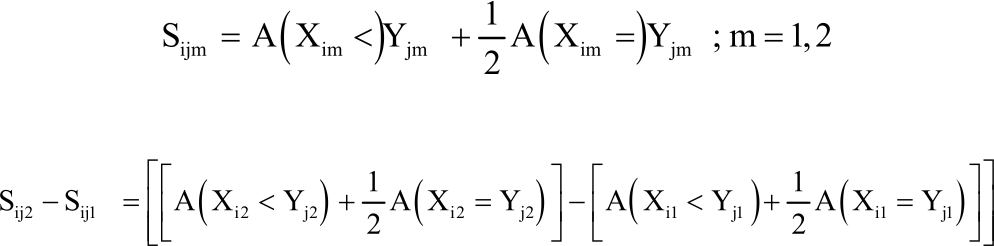 |
Consider according to Hanley and McNeil1, that this indicator function is:
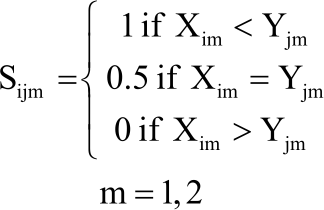 | (5) |
In other to test the null hypothesis H0: AUC2-AIC1 = 0, the M and N subjects were combined to have n subjects and let S1 = {S11, S12,..., S1N, S1,N+1, S1,N+2,..., S1n} be n measurements arising from diagnostic test 1 while the subscripts p = 1, 2,..., N shows test results for the non-diseased subjects while q = N+1, N+2,..., n shows test results for the diseased subjects. Based on this arrangement within diagnostic test 1, the comparison of every subject’s test result to every other subject’s test result. Thus:
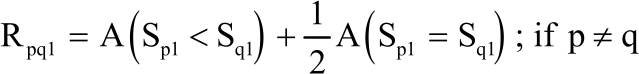 | (6) |
This implies that every diseased subject is compared to all non-diseased subjects and all (M-1) other diseased subjects. Similarly, every non-diseased subject is compared to all diseased subjects and all (N-1) other non-diseased subjects. Also let S2 = {S21, S22,..., S2N, S2,N+1, S2,N+2,..., S2n} be n measurements arising from diagnostic test 2 while the subscripts p = 1, 2,..., N shows test results for the non-diseased subjects while q = N+1, N+2,..., n shows test results for the diseased subjects. Similarly within diagnostic test, comparison was done to every subjects test result to every other subjects test result, that is:
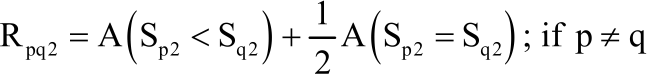 | (7) |
Given the above definitions, therefore, Rpq = 1-Rpqm, m = 1, 2.
To test the null hypothesis that AUCΔ = 0, which is similar to testing the null hypothesis that the difference between paired samples is a distribution that is symmetric around zero, adoption of the transformation in Eq. 5 whose indicator function is [1, 0.5, 0] and adjust for the presence of ties (zero difference) by mapping from the diagnostic pairs and disease status [0, 1] to [1, 0, -1]. Given the specifications, generalization of the estimate of AUCΔ as:
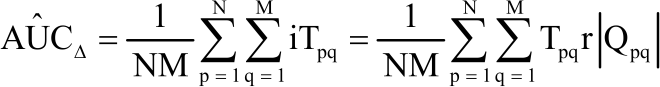 | (8) |
Where:
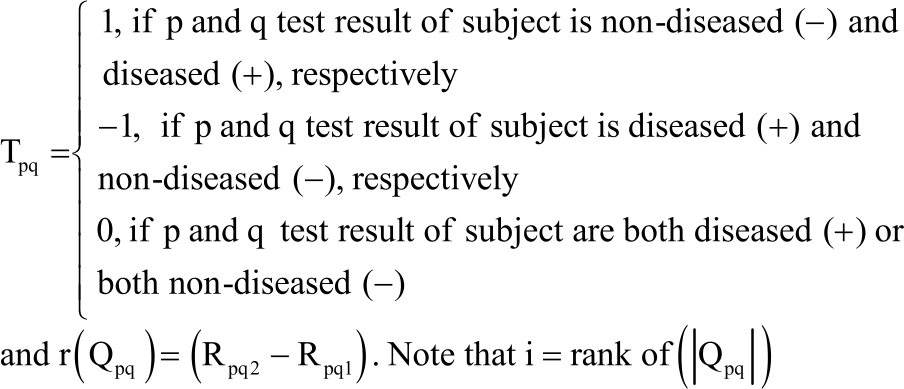 |
Note that Qpq is the difference between the sample pairs of S1 being measurements arising from diagnostic test 1 and S2 being measurements arising from diagnostic test 2.
This is based on the exchangeability of the diseased and non-diseased labels of the subjects within each diagnostic test. The indicator function Tpq takes value 1 at the calibrated cut-off point c of a given diagnostic test if subject test result p is non-diseased and subject test result q is diseased. It takes -1 if subject test result p is diseased and subject test result q is non-diseased. Values of 0 represents cut-offs at which both subject test results p and q are diseased or non-diseased. The AUC is equivalent to two-sample Wilcoxon Test Statistic10 and can be used to carry out test of symmetry around zero for paired samples. Based on that finding, the Eq. 5 which is the modified Wilcoxon Signed Rank test statistic is equivalent to difference in AUCs and can be used as a test statistic for the test of symmetry around zero. This modified Wilcoxon Signed Rank test is more powerful than the modified sign test statistic Oyeka11 proposed by Braun and Alonzo7 for comparing correlated ROC curves as it utilizes both the signs, Tpq and the absolute ranks of Qpq. When both diagnostic tests results are measured continuously, testing the hypothesis that AUCΔ = 0 is equal to testing the null hypothesis that r(qpq) is a symmetric distribution around zero. The null hypothesis was tested that AUCΔ = 0 by computing AUCΔ for every permutation of tested Tpq, the signs of the rank of |Qpq| Given that our permutation of Tpq requires exchanging the labels of non-diseased subject’s test results p and diseased subject’s test result q, it is the same as permuting among the subjects, the vector of test results of diseased/non-diseased labels. Therefore, the link between the true diseased status of a given subject as well as its test results arising diagnostic tests 1 and 2 are dislodged under this type of permutation arrangement. This permutation test is therefore valid if either one of the AUC of the diagnostic tests is equal to t, where t is a number in between 0.5 and 1 inclusive.
Data collection and study area: The study area used for this study was from Alex Ekwueme University Teaching Hospital, Abakaliki, Ebonyi state, which is a Tertiary Care Teaching Hospital with referrals from 13 General hospitals from 13 local government areas, 40 private hospitals and dispensaries. The data collection was approved by the Research and Ethics Committee. Records revealed that antenatal mothers with 24-28 weeks gestation period were the category of pregnant women who were involved in the study and whose data were recorded. As a procedure all pregnant women passed through a fasting and after lunch plasma glucose evaluation during the first antenatal visit in first trimester. As a protocol for screening of Gestational Diabetic Mellitus (GDM) subjects, all antenatal mothers that falls within this category of gestation period were given a 50 g Oral Glucose Challenge Test (OGCT) irrespective of the presence or absence of risk factors.
Available record showed that 50 g glucose was given as a solution in 200 mL water which was consumed within 5 min. This was done not minding whether the antenatal mothers fasted or not. They were not allowed to eat and drink for a period of 1 h. Blood sample was taken from them after 1 h. Those whose plasma glucose measurements after 1 h were >140 mg dL–1 was considered as diseased while those whose measurements after 1 h were recorded as <140 mg dL–1 was considered as non-diseased subjects. Out of a total of 2850 subjects screened in 2 years (January, 2016-December, 2017) period, 166 subjects tested positive for GDM. A total of 166 subjects received screening within this period and who tested positive for GDM. Using a simple random sampling method, a total of 60 pregnant women underwent two types of diagnostic tests for the in depth confirmation of Gestational Diabetic Mellitus (GDM) such that their test results were paired or matched to each other. These diagnostic tests are a 75 g Oral Glucose Tolerance Test (OGTT) and a 100 g OGTT. The data is used to evaluate the feasibility of the proposed permutation test at a nominal level of 0.05. The characterization and criteria adopted for diagnosing antenatal mothers who underwent either 75 g OGTT/100 g OGTT were 2 h OGTT characterization while the criteria was >155 mg dL–1 for one to be considered diseased/positive (coded 1) for GDM while <155 mg dL–1 is considered non-diseased/negative (coded 0) for GDM. Exchangeability of the measured test results is a vital condition to achieve result given that these results are paired. If the null hypothesis is true, then can be inferred that the subjects test results in diagnostic 1 and 2 are exchangeable and so the permutation test is applied on raw scores and are not ranked. It showed that there exist a number of pairs with tied test results, even though the test results are continuous. The null hypothesis is that the 2 h 75 g OGTT contributes the same diagnostic information or accuracy as the 2 h 100 g OGTT. That is, AUC1 and AUC2 of the 2 diagnostic tests are equal. The real data if analyzed will evaluate the performance of the proposed estimates. It will compare the performance of the 2 diagnostic tests in terms of ROC curves between the 2 diagnostic tests and a crossing ROC curve will emerge. The crossing ROC curves will have the areas for the 2 diagnostic test procedures. In applying the data, the diagnostic test results need to have a bivariate binormal distribution. Most powerful test does not exist for testing bivariate normal distribution12. Therefore, for each test result, one resorted to checking only the univariate normality.
RESULTS
Checking for univariate normality of two diagnostic test results by Shapiro-Wilk test reveals that the p-values for the diagnostic tests 1 and 2 for the non-diseased subjects are, respectively 0.6124 and 0.8975 while that of diseased subjects for the diagnostic tests 1 and 2 are, respectively 0.6345 and 0.8765 as present in Fig. 1.
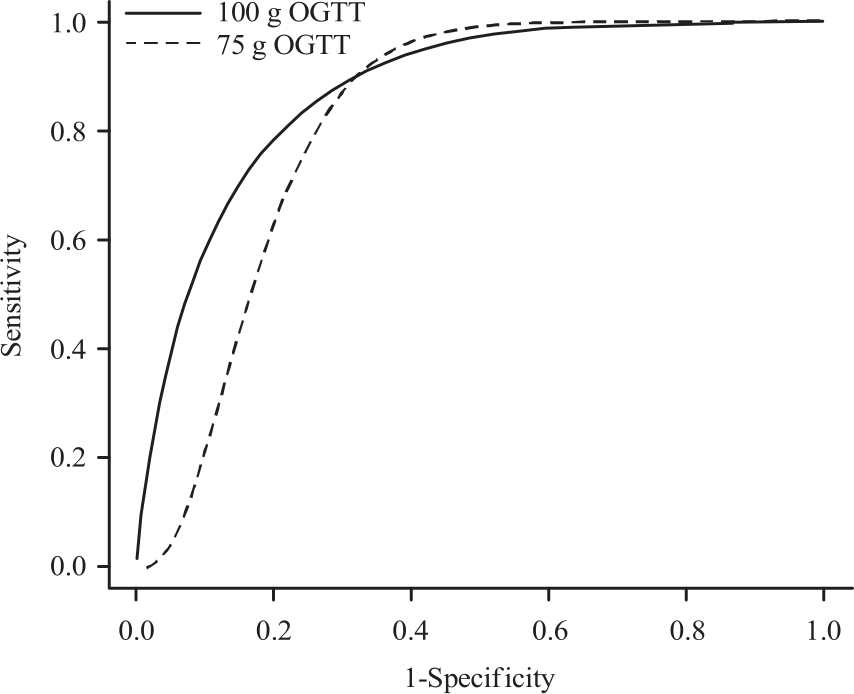 |
| Fig. 1: | Crossed ROC curves for two diagnostic tests taken from data on GDM ROC: Receiver operating characteristic, GDM: Gestational diabetic mellitus, OGGTT: Oral glucose tolerance test |
The estimates of AUC1 and AUC2 for diagnostic tests are 0.668 and 0.887, respectively. Hence, using the proposed permutation test, the p-value of 0.0312 is rejected at a nominal level of 0.05. Using the standard permutation test, the null hypothesis is also rejected since the p-value is 0.0387.
DISCUSSION
The proposed permutation test compared the performances of two diagnostic tests for paired sample design. It conducted exact permutation test by implementing an algorithm derived for the purpose based on proposed modified Wilcoxon Signed Rank test statistic. In comparing paired ROC curves, current design is to have increased power to detect a difference in the AUC. The proposed permutation test which is based on between-subject permutations of the labels of the subjects within each diagnostic test for detecting differences between ROC curves was necessary to tackle the problem of exchangeability of the labels between two diagnostic tests within subject. The proposed test is designed to assess a change in the AUCs in a continuous matched pair of data from 2 diagnostic tests having both diseased and non-diseased subject in each of the test where permutations are made between subjects particularly by shuffling the diseased and non-diseased labels of the subjects within each diagnostic test. It will be recalled that to have appropriate test
size and increased statistical power, the necessary conditions are that the sample size for subject labels must be at most 60, the average of two AUCs must be at least 0.80 and the correlation within subjects test results should be 0.4 at least3. Therefore, at small average AUC, low correlation between diagnostic tests and at sample size higher than 60, the method by DeLong et al.3 has improved test size and greater power than our permutation test otherwise permutation has improved test size and greater power. Venkatraman and Begg5 found that for noncrossing ROC curves, the statistical power of DeLong et al.3 is higher than that of Venkatraman and Begg5 because the procedure of Venkatraman and Begg5 is designed to detect differences in ROC curves as against detecting differences only in AUCs. In other words, when ROC curves cross, the power of a given test is higher because it detects difference in ROC curves, but if ROC curves do not cross, the test that compares only the equality of AUCs has higher power e.g., DeLong et al.3 test. Therefore, Venkatraman and Begg5 test has lower power for noncrossing ROC curves as it detect differences in ROC curves while in the same scenario, DeLong et al.3 test has higher power as it detects differences in AUCs. The permutation test though tests the null hypothesis of equality of AUCs, it is designed to detect a difference in AUC as it compares the correlation in ROC curves when the ROC curves cross each other. While our permutation test formally tests a difference in ROC curves and detects a difference in AUC, it has higher power than DeLong et al.3 conventional test that only detects difference in AUCs. Result showed that this proposed test has comparable power to the test conducted by Bandos et al.6 as well as Braun and Alonzo7, who also proposed permutation tests , but has superior operating characteristics in some ranges of parameters owing to the pattern of between subjects permutations as well as the fact that this proposed test is designed to consider the signs of values as well as the absolute ranks of values. Braun and Alonzo7 considered only the signs of values. This permutation test is slightly conservative but has an excellent power to detect a crossing alternative based on simulation results. Using the real data to illustrate the feasibility of the proposed permutation test showed that the null hypothesis of equality of diagnostic information is rejected on account of one diagnostic test showing superiority over another and the proposed test showing higher power over existing tests. These results are consistent with the findings obtained by the proposed permutation test by previous authors5,6.
CONCLUSION
In applying the real data, the proposed permutation test is more powerful than the comparison test since it has the more likelihood of rejecting the null hypothesis. Graph of ROC curves showed that 2 h 100 g OGTT diagnostic test is superior at a time that the specificity is greater than 0.7. As soon as the specificity decreases, the disparity between the two diagnostic tests procedures reduces. Also since the null hypothesis for the univariate normal is rejected given the disparity in the p-values of the diagnostic tests for non-diseased and diseased as well as the values of AUCs, the 2 diagnostic test procedures did not contribute equivalent diagnostic information.
The proposed test can be a very suitable alternative to the comparison test that only consider the direction of values (signs of differences). The strength of proposed test is that it has easy implementation to discriminate diagnostic test procedures even by non-statisticians. Since the MWSR test is easy to compute as well as easy to communicate to the potential uses of the procedure, this test can be used conveniently.
SIGNIFICANCE STATEMENT
The use of Modified Wilcoxon Signed Rank test as permutation test will circumvent the difficulties or reduce the computational burden associated with estimating the difference between two AUCs in a paired sample design. The method of comparing ROC curves using this test statistic is designed to assess a difference in AUCs for paired samples and it provides meaningful information than when ROC curves cross and has the same AUCs. Adjustment for the presence of tied absolute value of difference or zero value in the test statistic helps to increase the power and accuracy of tests since no data is lost due to absence of zero difference. Also the proposed test offers reliable statistical inferences for small sample sizes. Since permutations are made within each diagnostic test between subjects, the validity of the permutation test holds even when both diagnostic tests are measured on different scales. This permutation procedure in diagnostic tests research will resolve the problem of exchangeability of the labels between two diagnostic tests within subject which characterized previous existing tests. This study will help the researcher to uncover the critical areas of diagnostic tests comparisons that many other researchers were not able to explore. Thus a new theory based on between subject’s label permutation patterns within each diagnostic test may be arrived at.
ACKNOWLEDGMENT
Authors would like to thanks the Asian Journal of Mathematics and Statistics for publishing this article FREE of cost and to Karim Foundation for bearing the cost of article production, hosting as well as liaison with abstracting and indexing services and customer services.
REFERENCES
- Hanley, J.A. and B.J. McNeil, 1982. The meaning and use of the area under a Receiver Operating Characteristic (ROC) curve Radiology, 143: 29-36.
CrossRefDirect Link - Hanley, J.A. and B.J. McNeil, 1983. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology, 148: 839-843.
CrossRefDirect Link - DeLong, E.R., D.M. DeLong and D.L. Clarke-Pearson, 1988. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics, 44: 837-845.
CrossRefDirect Link - Sumi, N.S. and M.A. Hossain, 2012. A study on parametric approaches to compare areas under two correlated ROC curves. Bangladesh J. Scient. Res., 25: 61-71.
Direct Link - Venkatraman, E.S. and C.B. Begg, 1996. A distribution-free procedure for comparing receiver operating characteristic curves from a paired experiment. Biometrika, 83: 835-848.
CrossRefDirect Link - Bandos, A.I., H.E. Rockette and D. Gur, 2005. A permutation test sensitive to differences in areas for comparing ROC curves from a paired design. Statist. Med., 24: 2873-2893.
CrossRefDirect Link - Braun, T.M. and T.A. Alonzo, 2008. A modified sign test for comparing paired ROC curves. Biostatistics, 9: 364-372.
CrossRefDirect Link - Harris, T. and J.W. Hardin, 2013. Exact Wilcoxon signed-rank and Wilcoxon Mann-Whitney ranksum tests. Stata J., 13: 337-343.
CrossRefDirect Link - Bamber, D., 1975. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J. Math. Psychol., 12: 387-415.
CrossRefDirect Link - Pardo, M.C. and A.M. Franco-Pereira, 2017. Non parametric ROC summary statistics. REVSTAT-Statist. J., 15: 583-600.
Direct Link - Wang, C.C., 2015. A MATLAB package for multivariate normality test. J. Statist. Comput. Simulat., 85: 166-188.
CrossRefDirect Link