
M. P. Iwundu
Department of Mathematics and Statistics, Faculty of Physical Science and Information Technology, University of Port Harcourt, Nigeria
O. P. Efezino
Department of Mathematics and Statistics, Faculty of Physical Science and Information Technology, University of Port Harcourt, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2015 | Volume: 8 | Issue: 1 | Page No.: 19-34







ABSTRACT
The adequacy of variable selection techniques on model building is examined using the drying characteristics of fresh grains. Three selection techniques (forward selection, backward elimination and stepwise methods) are employed each of which identifies a series of models assumed to be adequate. From the resulting models for each technique, the most suitable model is determined using standard assessment criteria namely, R2, R2adj, PRESS, AIC and Cp-statistic. In addition to the standard assessment criteria, the D-optimality criterion is examined and presented as a criterion for measuring the goodness and adequacy of regression models. Results show that under the forward selection and stepwise regression methods, each assessment criterion locates the same model. Variation seems to exist using backward elimination technique.
PDF Abstract XML References Citation
Received: June 15, 2015;
Accepted: August 06, 2015;
Published: October 19, 2015
How to cite this article
M. P. Iwundu and O. P. Efezino, 2015. On the Adequacy of Variable Selection Techniques on Model Building. Asian Journal of Mathematics & Statistics, 8: 19-34.
DOI: 10.3923/ajms.2015.19.34
URL: https://scialert.net/abstract/?doi=ajms.2015.19.34
DOI: 10.3923/ajms.2015.19.34
URL: https://scialert.net/abstract/?doi=ajms.2015.19.34
INTRODUCTION
Response Surface Methodology (RSM) as an important branch of experimental design and a critical technology in developing new processes plays a vital role in model building. According to Myers and Montgomery (2002), Response Surface Methodology (RMS) is seen as a combination of statistical and mathematical techniques useful for developing, improving and optimizing processes. Carley et al. (2003) observed the usefulness of RSM in model calibration and validation. As pointed out by Kadane and Lazar (2004), model selection plays a major role in modern scientific enterprise. The question of model selection then becomes apparent as the variables that affect the outcome of interest become a major concern.
Building statistical model of a response as a function of multiple explanatory variables is a common practice in various professions. Gerritsen et al. (1996) observed its usefulness in risk estimation. Generally, variable selection and model-building techniques are used to identify the best subset of regressors to include in a regression model (Montgomery et al., 2001; Myers, 1990; Burnham and Anderson, 2001a; Hobbs and Hilborn, 2006; Ward, 2008; Lee and Ghosh, 2009; Olden and Jackson, 2000). Leaving out important regressors introduces bias into the parameter estimates, while including unimportant variables weakens the prediction or estimation capability of the model. In model building, the process of identifying and fitting an appropriate response surface model from experimental data requires some use of experimental design fundamentals. As pointed out by Burnham and Anderson (2001b), three general principles guild model-based inferences and these principles are simplicity and parsimony, several working hypotheses and strength of evidence.
Kadane and Lazar (2004) presented a review of methods and criteria for model selection with emphasis on Bayesian and frequentist approaches. Evaluating all possible regressions can be computationally burdensome hence various methods have been developed for evaluating only a small number of subset regression models by either adding or deleting regressors one at a time. These methods are generally referred to as stepwise-type procedures and can be classified into three broad categories namely (i) forward selection method, (ii) backward elimination method and (iii) stepwise regression method. Sauerbrei et al. (2007), Ward (2008), Lee and Ghosh (2009) and Raffalovich et al. (2008) employed the step-type procedures in selecting best subset of regressors. Carley and Kamneva (2004) used the simulated annealing method for searching the best subset of regressors. Hastie et al. (2009) used the Sequential Search (SS) method to find optimal subsets of variables for a specified model size.
The various stepwise procedures are among popular and widespread techniques of model selection. They provide systematic ways of searching through models. With these procedures new models are obtained at each stage by adding to or deleting from the model one variable at each previous stage. Although, the stepwise procedures were originally designed to aid in variable selection problems for regression models, they have been applied to generalized linear models as seen in Lawless and Singhal (1978) as well as to contingency tables as in Agresti (1990). An advantage of using the stepwise procedures is that they are readily available in most statistical packages.
Unfortunately, as reported in Weisberg (1985), none of the stepwise regressions corresponds to a specified criterion for choosing a model. Hence, the selected model need not be optimal in any other sense than that it is the result of the algorithm applied to the dataset. In fact, Graybill (1976) demonstrated that forward selection and backward elimination might not result in the same final model while working on the same dataset. Other frequentist procedures include the risk inflation criterion and the covariance inflation criterion (Donoho and Johnstone, 1994; Foster and George, 1994; Tibshirani and Knight, 1999).
The aim of this study is to access the adequacy of three stepwise procedures in model building using the drying characteristics of fresh grains (melon seed). This problem shall be viewed from a regression context. As noted in Foster and Georges (1994), variable selection problem in regression is a two stage process involving the selection of a best subset of predictors and the estimation of the model coefficients by least squares.
MATERIALS AND METHODS
Stepwise procedures shall be employed to identify models that suitably describe the relationship between drying characteristics of fresh grains. The adequacy of the resulting models shall be tested using standard assessment criteria namely, Cp-statistics, Akaike Information Criteria (AIC), R2 statistics, R2adj statistics, MSE and PRESS. Furthermore, D-optimality criterion shall be introduced as an assessment criterion for testing for adequacy of regression models and its performance shall be compared with those of the standard assessment criteria.
Stepwise-type procedures: The stepwise-type procedures are based on three different strategies, namely Forward Selection (FS), Backward Elimination (BE) and Stepwise Regression (SR).
Forward selection: Forward selection strategy begins with the assumption that there are no regressors in the model other than the intercept. An effort is made to find an optimal subset by inserting regressors into the model one at a time. The first regressor selected for entry into the model is the one that has the largest simple correlation with the response variable y. Suppose that regressor is x1, this is also the regressor that will produce the largest value of the F-statistic for testing significance of regression. This regressor is entered if the F-statistic exceeds a preselected F-value, say Fin (or F-to-enter). The second regressor chosen for entry is the one that now has the largest correlation with the response variable after adjusting for the effect of the first regressor entered on y. We refer to these correlations as partial correlations.
In general, at each step the regressor having the highest partial correlation with y (or equivalently the largest partial F-statistic given the other regressors already in the model) is added to the model if its partial F-statistic exceeds the preselected entry level Fin. The procedure terminates either when the partial F-statistic at a particular step does not exceed Fin or when the last candidate regressor is added to the model. The technique is evaluated using the F-test defined by:
| (1) |
where, RSSp and RSSp+j are the residuals sum of squares of the models with p and p+j variables, S2p+j is the variance of the model built with p+j variables and Fin is used as a stop criterion.
Backward elimination: Backward elimination method proceeds in the opposite way. It begins with a model that includes all K candidate regressors. Then the partial F-statistic (or t-statistic, which is equivalent) is computed for each regressor as if it were the last variable to enter the model. The smallest of these partial F-statistic is compared with a preselected value, Fout (or F-to-remove) and if the smallest partial F-value is less than Fout, that regressor is removed from the model. At this instance, a regression model with K-1 regressors is fitted, the partial F-statistic for this new model calculated and the procedure repeated. The backward elimination algorithm terminates when the smallest partial F-value is not less than the preselected cut-off value Fout. The technique is evaluated using the F-test defined by:
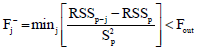 | (2) |
where, Fout is used as stop criterion.
Stepwise regression: Stepwise regression is the modification of forward selection in which at each step all regressors entered into the model previously are reassessed via their partial F-statistic or t-statistics. A regressor added at an earlier step may now be redundant because of the relationship between it and regressors now in the equation. If the partial F-statistic for a variable is less than Fout, that variable is dropped from the model. The stepwise regression requires two cut-off values, Fin and Fout.
Assessment criteria
R-square (R2): R-square is a measure of the proportion of variability in the data set that is accounted for by a regression model. It assumes that every independent variable in the model helps to explain variation in the dependent variable (y) and thus gives the percentage of explained variation if all independent variables in the model affect the dependent variable (y). The R2 statistic is defined as:
![]()
| SST | = | Σi (yi- |
| SSR | = | Σi ( |
| yi and | = | Original and modeled data values |
Adjusted R-square (R2adj): In least squares regression, increasing the number of regressors in the model leads to increase in R2. Hence, R2 alone cannot be employed as a meaningful comparison of models. The adjusted R-square, R2adj, tells us the percentage of variation explained by only those independent variables that truly affect the dependent variable (y) and penalizes for adding independent variable (s) that do not belong to the model.
The adjusted R-square is defined as:
| (3) |
where, n is the sample size and p is the model parameter.
Akaike information criterion: Akaike Information Criterion (AIC) measures the relative quality of a statistical model for a given set of data. Consequently, AIC provides a means for model selection as it estimates the quality of each model, relative to the other models.
The Akaike Information Criterion (AIC) is given as:
| (4) |
where, n denotes the sample size, p denotes the number of parameters and
![]()
Operationally, one computes AIC for each of the identified models and selects as best, the model with the smallest AIC value.
For small sample sizes (i.e., n/p<~40), the second-order Akaike Information Criterion (AICc) is used and is defined by:
| (5) |
The second-order Akaike Information Criterion (AICc) is simply AIC with a correction for finite sample sizes. As sample size increases, the last term of the AICc approaches zero and the AICc tends to yield the same conclusions as the AIC (Burnham and Anderson, 2002).
Predicted residual sum of squares: The Predicted Residual Sum of Squares (PRESS) can be used as a data validation procedure. It provides insight into the quality and potential influence of individual observations on the estimates. The PRESS statistic, derived from the jackknifed residuals ei = ![]() is defined as:
is defined as:
| (6) |
where, ![]() is the estimated dependent variable when the regression model is fitted to a sample of n-1 observations with the ith observation omitted.
is the estimated dependent variable when the regression model is fitted to a sample of n-1 observations with the ith observation omitted.
Mallow’s Cp statistic: Mallow’s Cp statistic is defined as a criterion for assessing fits when models with different numbers of parameters are being compared. It is given by:
| (7) |
where, RSS (p) is the error sum of squares for the p-term model and ![]() = MSE (for the full model). The Cp statistic will tend to be close to or smaller then p if the p-parameter model is adequate.
= MSE (for the full model). The Cp statistic will tend to be close to or smaller then p if the p-parameter model is adequate.
D-optimality criterion: The use of D-optimality criterion as model adequacy technique has not been well established in the literature. The D-optimality criterion is a determinant criterion and provides low variance estimates for parameters and low correlation estimates among parameters. A design is D-optimal if it maximizes the determinant of the information matrix and equivalently minimizes the variance-covariance matrix. By definition, a design, say ξ*, is D-optimal if for all designs ξi, i = 1, 2, …
det M(ξ*) = max {det M(ξi)}; i = 1, 2, … | (8) |
where, det(.) is the determinant and M(.) is the information matrix.
RESULTS
The experimental data set used in assessing the adequacy of variable selection techniques in model building comprises of drying characteristics of fresh grains tabulated in Appendix A. The key variables are time, temperature and moisture content. The data was analyzed using SPSS 21 and series of models resulted using each of the stepwise-type techniques. The analyses for forward selection techniques are presented in Table 1-5.
| Table 1: | SPSS 21 outputs for forward selection |
 | |
| aPredictors: (constant), TEMP. MC, bPredictors:(constant), TEMP. MC, MC, cPredictors:(constant), TEMP. MC, MC, MC. MC, dPredictors: (constant), TEMP. MC, MC, MC. MC, TEMP, ePredictors:(constant), TEMP. MC, MC, MC. MC, TEMP, TIME. TEMP, fPredictors: (constant), TEMP. MC, MC, MC. MC, TEMP, TIME. TEMP, TEMP. TEMP, df: Degree of freedom | |
| Table 2: | Variables entered/removeda |
 | |
| aDependent variable: DRYING.RATE | |
| Table 3: | ANOVAa |
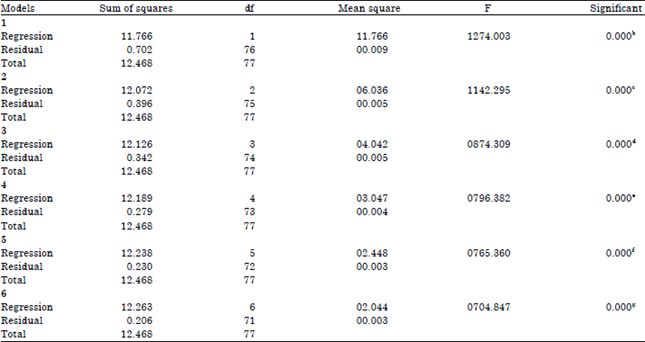 | |
| aDependent variable: DRYING.RATE, bPredictors: (constant), TEMP.MC, cPredictors: (constant), TEMP.MC, Mc, dPredictors: (constant), TEMP.MC, MC, MC.MC, ePredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, fPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, gPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, TEMP.TEMP, df: Degree of freedom | |
| The analysis for backward elimination techniques are presented in Table 6-9. | |
| The analysis for stepwise regression techniques are presented in Table 10-14. | |
| From the statistical analysis, the resulting models using the forward selection method are |
| • | y = ao+a23x2x3+e |
| • | y = ao+a3x3 +a23x2x3+e |
| Table 4: | Coefficientsa |
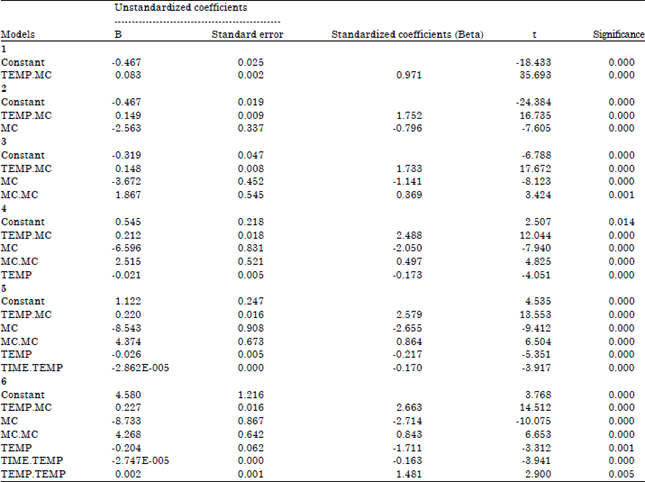 | |
| aDependent variable: DRYING.RATE | |
| • | y = ao+a3x3+a23x2x3+a33x32+e |
| • | y = ao+a2x2+a3x3+a23x2x3+a33x32+e |
| • | y = ao+a2x2+a3x3+a12x1x2+a23x2x3+a33x32+e |
| • | y = ao+a2x2+a3x3+a12x1x2+a23x2x3+a2x22+a3x32+e |
The resulting models using the backward elimination method are
| • | y = a0+a1x1+a2x2+a3x3+a12x1x2+a13x1x3+a23x2x3+a11x12+a22x22+a33x32+e |
| • | y = a0+a1x1+a2x2+a3x3+a12x1x2+a23x2x3+a11x12+a22x22+a33x32+e |
| • | y = a0+a1x1+a2x2+a3x3+a12x1x2+a23x2x3+a11x12+a33x32+e |
| • | y = a0+a1x1+a2x2+a3x3+a23x2x3+a11x12+a33x32+e |
The resulting models using the stepwise regression method are
| • | y = ao+a23x2x3+e |
| • | y = ao+a3x3+a23x2x3+e |
| • | y = ao+a3x3+a23x2x3+a33x32+e |
| • | y = ao+a2x2+a3x3+a23x2x3+a33x32+e |
| Table 5: | Excluded variablesa |
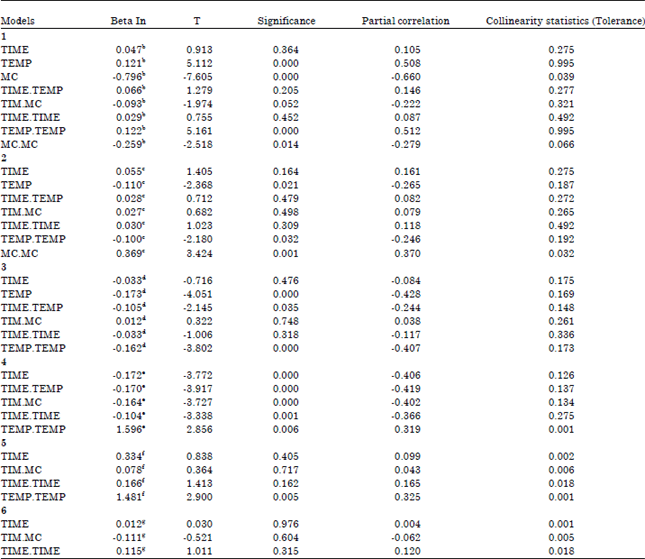 | |
| aDependent Variable: DRYING.RATE, bPredictors in the Model: (constant), TEMP.MC, cPredictors in the Model: (constant), TEMP.MC, MC, dPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, ePredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, fPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, gPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, TEMP.TEMP | |
| Table 6: | SPSS 21 outputs for backward elimination (variables entered/removeda) |
 | |
| aTolerance: 0.000 limits reached, bPredictors: (constant), MC.MC, TEMP.TEMP, TIME.TIME,TEMP.MC, TIME.TEMP, TIM.MC,MC, TEMP, TIME | |
| • | y = ao+a2x2+a3x3+a12x1x2+a23x2x3+a33x32+e |
| • | y = ao+a2x2+a3x3+a12x1x2+a23x2x3+a2x22+a3x32+e |
| Table 7: | Model summaryd |
 | |
| aDependent Variable: DRYING.RATE, bPredictors: (constant), MC.MC, TEMP.TEMP, TIME.TIME, TEMP.MC, TIME.TEMP, TIM.MC, MC, TEMP, TIME, cPredictors: (constant), MC.MC, TEMP.TEMP, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, dPredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, ePredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP | |
| Table 8: | ANOVAa |
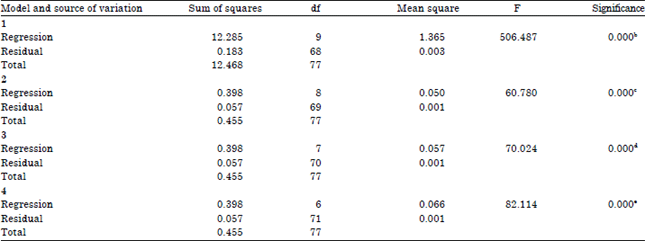 | |
| aDependent variable: DRYING. RATE, bPredictors: (constant), MC.MC, TEMP.TEMP, TIME.TIME, TEMP.MC, TIME.TEMP, TIM.MC, MC, TEMP, TIME, cPredictors: (constant), MC.MC, TEMP.TEMP, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, dPredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, ePredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP | |
| Table 9: | Coefficientsa |
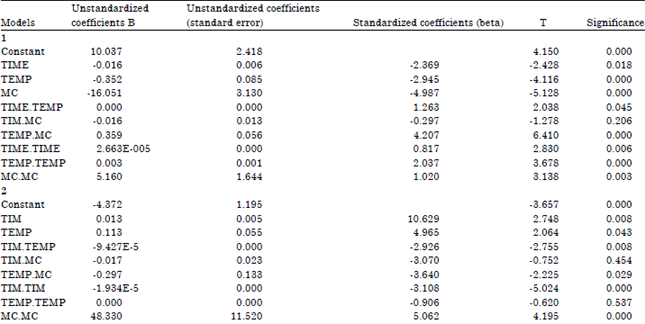 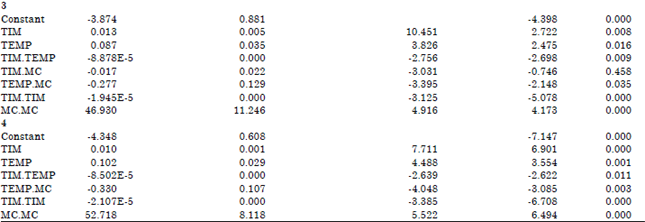 | |
| aDependent Variable: DRYING.RATE, bPredictors: (constant), MC.MC, TEMP.TEMP, TIME.TIME, TEMP.MC, TIME.TEMP, TIM.MC, MC, TEMP, TIME, cPredictors: (constant), MC.MC, TEMP.TEMP, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, dPredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP, TIM.MC, ePredictors: (constant), MC.MC, TIM.TIM, TIM.TEMP, TEMP.MC, TIM, TEMP | |
| Table 10: | SPSS 21 outputs for stepwise regression variables entered/removeda |
 | |
| aDependent variable: DRYING. RATE | |
| Table 11: | Model summary |
 | |
| aPredictors: (constant), TEMP.MC, bPredictors: (constant), TEMP.MC, MC, cPredictors: (constant), TEMP.MC, MC, MC.MC, dPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, ePredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, fPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, TEMP.TEMP, df: Degree of freedom | |
The assessment of the adequacy of each model using the selected criteria are presented in Table 15-17.
| Table 12: | ANOVAa |
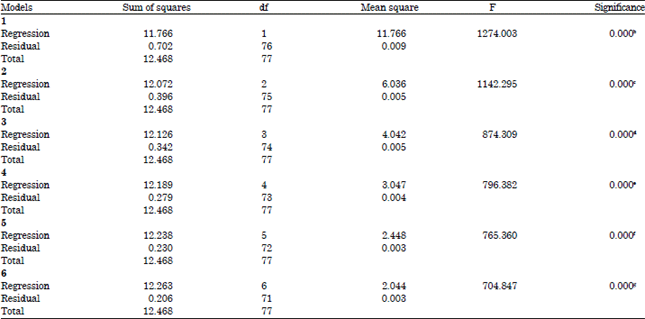 | |
| aDependent Variable: DRYING.RATE, bPredictors: (constant), TEMP.MC, c Predictors: (constant), TEMP.MC, MC, dPredictors: (constant), TEMP.MC, MC, MC.MC, ePredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, fPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, gPredictors: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, TEMP.TEMP, df: Degree of freedom | |
| Table 13: | Coefficientsa |
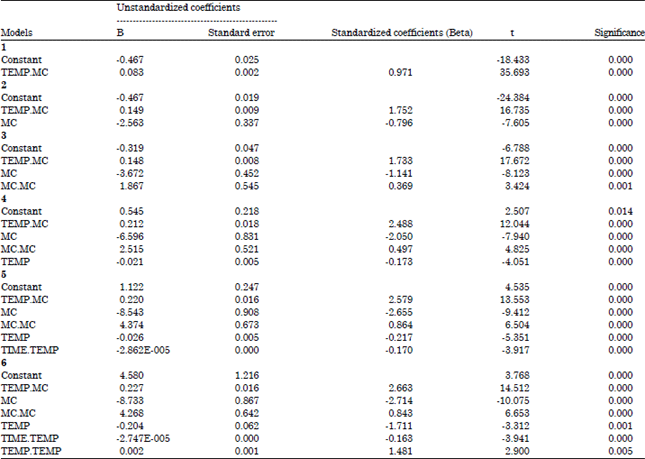 | |
| aDependent variable: DRYING.RATE | |
| Table 14: | Excluded variablesa |
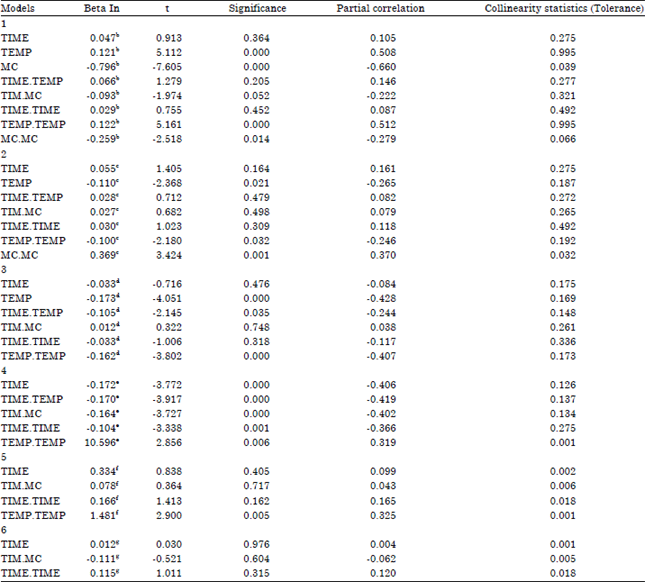 | |
| aDependent variable: DRYING.RATE, bPredictors in the Model: (constant), TEMP.MC, cPredictors in the Model: (constant), TEMP.MC, MC, dPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, ePredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, fPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, gPredictors in the Model: (constant), TEMP.MC, MC, MC.MC, TEMP, TIME.TEMP, TEMP.TEMP | |
| Table 15: | Assessment of adequacy of the models obtained using forward selection method |
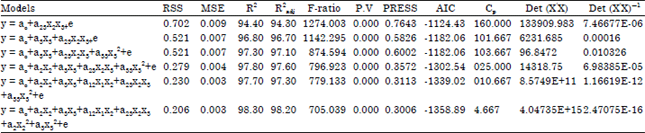 | |
| RSS: Error sum of square for the p-term model, MSE: Error sum of square for full model, AIC: Alkaike information criterion, PRESS: Predicted residual sum of square, R2: R-square, R2adj: Adjusted R-square | |
| Table 16: | Assessment of adequacy of the models obtained using Backward Elimination method |
 | |
| RSS: Error sum of square for the p-term model, MSE: Error sum of square for full model, AIC: Alkaike information criterion, PRESS: Predicted residual sum of square, R2: R-square, R2adj: Adjusted R-square | |
| Table 17: | Assessment of adequacy of the models obtained using stepwise regression |
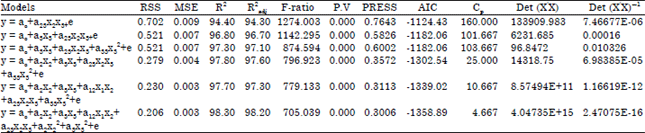 | |
| RSS: Error sum of square for the p-term model, MSE: Error sum of square for full model, AIC: Alkaike information criterion, PRESS: Predicted residual sum of square, R2: R-square, R2adj: Adjusted R-square | |
DISCUSSION
In assessing the adequacy of variable selection techniques on model building using the drying characteristics of fresh grains, each of the forward selection, backward elimination and stepwise regression methods identified a series of models assumed to be adequate. From the resulting models for each technique, the most suitable model was determined using six assessment criteria. For forward selection method, the predicted R2 and adjusted R2 criteria identified the model:
y = ao+a2x2+a3x3+a12x1x2+a23x2x3+a22x22+a33x32+e
as best out of a series of five models. The measure of the proportion of variability in the data set that is accounted for by the regression model is 98.30 and 98.20%, respectively. The least PRESS value of 0.3006 was also associated with the same model. The AIC further confirmed the model as most suitable. The Cp statistic as well as the D-optimality criterion identified the same model as best. These results were also true for the stepwise regression.
There seemed to be no perfect agreement using the assessment criteria for the backward elimination method. The predicted R2, adjusted R2, AIC and D-optimality criteria identified the model:
y = a0+a1x1+a2x2+a3x3+a12x1x2+a13x1x3+a23x2x3+a11x12+a22x22+a33x32+ei
as best. However, variations existed with the PRESS and Cp statistic assessment criteria.
Hence, for the experimental data used, all assessment criteria considered identified the same model as best for the forward selection method as well as the stepwise regression method but several models were identified by the assessment criteria using the backward elimination method. The D-optimality criterion has been successfully employed as a new criterion for assessing the adequacy of regression models. Its discriminating ability is as with the R2adj, PRESS, AIC and Cp-statistic.
| Appendix A: | Drying rate of melon seed |
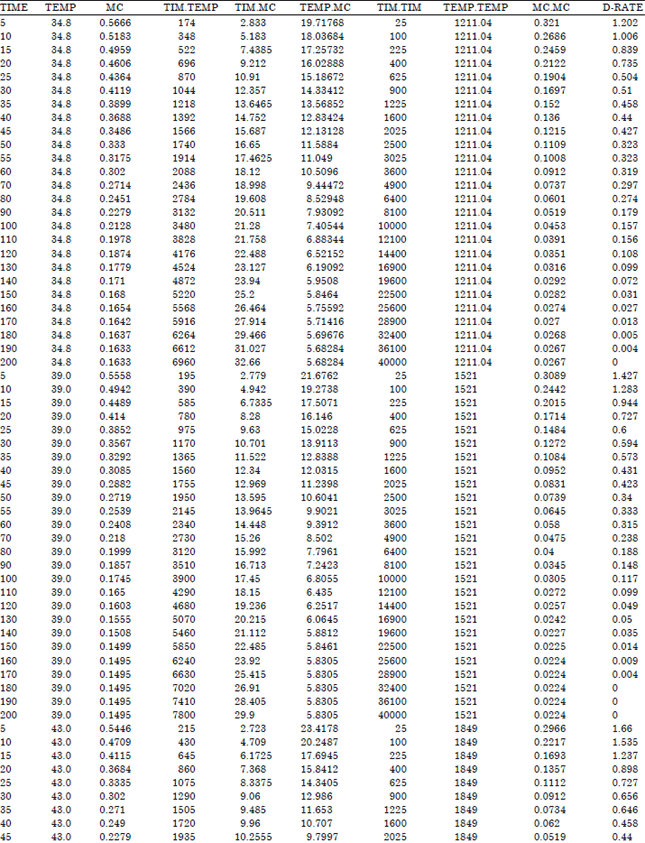 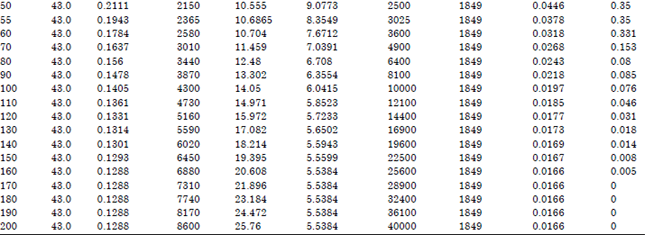 | |
REFERENCES
- Burnham, K.P. and D.R. Anderson, 2001. Kullback-Leibler information as a basis for strong inference in ecological studies. Wildlife Res., 28: 111-119.
CrossRefDirect Link - Donoho, D.L. and I.M. Johnstone, 1994. Ideal spatial adaptation by wavelet shrinkage. Biometrika, 81: 425-455.
CrossRefDirect Link - Foster, D.P. and E.I. George, 1994. The risk inflation criterion for multiple regression. Ann. Stat., 22: 1947-1975.
Direct Link - Gerritsen, J., J.M. Dietz and H.T. Wilson Jr, 1996. Episodic acidification of coastal plain streams: An estimation of risk to fish. Ecol. Applic., 6: 438-448.
CrossRefDirect Link - Hobbs, N.T. and R. Hilborn, 2006. Alternatives to statistical hypothesis testing in ecology: A guide to self teaching. Ecol. Applic., 16: 5-19.
CrossRefDirect Link - Kadane, J.B. and N.A. Lazar, 2004. Methods and criteria for model selection. J. Am. Stat. Assoc., 99: 279-290.
CrossRefDirect Link - Lawless, J.F. and K. Singhal, 1978. Efficient screening of nonnormal regression models. Biometrics, 42: 318-327.
CrossRefDirect Link - Lee, H. and S.K. Ghosh, 2009. Performance of information criteria for spatial models. J. Stat. Comput. Simulation, 79: 93-106.
CrossRefDirect Link - Myers, R.H. and D.C. Montgomery, 2002. Response Surface Methodology: Process and Product Optimization Using Designed Experiments. 2nd Edn., Wiley, New York, ISBN: 978-0-471-41255-7, Pages: 824.
Direct Link - Olden, J.D. and D.A. Jackson, 2000. Torturing data for the sake of generality: How valid are our regression models? Ecoscience, 7: 501-510.
Direct Link - Raffalovich, L.E., G.D. Deane, D. Armstrong and H.S. Tsao, 2008. Model selection procedures in social research: Monte-Carlo simulation results. J. Applied Stat., 35: 1093-1114.
CrossRefDirect Link - Sauerbrei, W., P. Royston and H. Binder, 2007. Selection of important variables and determination of functional form for continuous predictors in multivariable model building. Stat. Med., 26: 5512-5528.
CrossRefDirect Link - Tibshirani, R. and K. Knight, 1999. The covariance inflation criterion for adaptive model selection. J. R. Stat. Soc. Ser. B, 61: 529-546.
Direct Link - Ward, E.J., 2008. A review and comparison of four commonly used Bayesian and maximum likelihood model selection tools. Ecol. Modell., 211: 1-10.
CrossRefDirect Link