
Iheanyi S. Iwueze
Department of Statistics, Faculty of Biological and Physical Sciences,
Abia State University, P.M.B. 2000, Uturu, Abia State, Nigeria
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 2 | Page No.: 189-195







ABSTRACT
In this research, we want to present the N(1, σ2) distribution when its values do not admit values less than or equal to zero. The 0.001 probability limits were used to give practical assurance that the values from N(1, σ2) are all positive. The truncated values are greater than zero if and only if 0<σ<0.30. The expression for the mean of the left-truncated N(1, σ2) distribution is in terms of the cumulative distribution function of the standard normal distribution, while that of the variance is in terms of the Chi-square distribution with one degree of freedom. The logarithmic transform of the left-truncated N(1, σ2) distribution was found to be approximately normal when σ<0.10.
PDF Abstract XML References Citation
How to cite this article
Iheanyi S. Iwueze, 2007. Some Implications of Truncating the N(1, σ2) Distribution to the left at Zero. Journal of Applied Sciences, 7: 189-195.
DOI: 10.3923/jas.2007.189.195
URL: https://scialert.net/abstract/?doi=jas.2007.189.195
DOI: 10.3923/jas.2007.189.195
URL: https://scialert.net/abstract/?doi=jas.2007.189.195
INTRODUCTION
Consider a normally distributed random variable X with a probability density function f (x) specified as
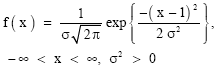 | (1) |
In many applications, the random variable X, which has a N(1, σ2) distribution do not admit values less than or equal to zero. We must therefore disregard or truncate all values of X#0 to take care of the admissible region of X>0.
Now, if the values of X below or equal to zero cannot be observed due to censoring or truncation, then the resulting distribution is a left-truncated normal distribution with probability density function f*(x) given by Uche (2003).
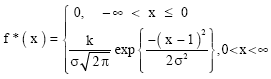 | (2) |
The distribution (2) is said to be truncated to the left at zero, k is the normalizing quantity and its value is obtained by noting that
| (3) |
Following Hald=s conventions (Hald, 1952; Rohatgi, 1976) the resulting distribution (2) that satisfies (3) can be written as
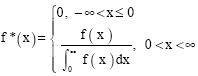 | (4) |
where f(x) is as defined in (1). For purposes of generality, Eq. (4) can be re-stated in terms of the standard normal distribution (Cohen, 1991; Johnson and Kotz, 1970; Schneider, 1986). It is important to note that Eq. (2) and (4) are the same and all computations in this research are based on (2).
For a review of prior research on estimation procedures/algorithms of the parameters of the truncated normal distribution (Johnson and Thomopoulos, 2004). Johnson and Thomopoulos (2004) after looking at the characteristics of the truncated population, also provided tables of the cumulative distribution function of the left-truncated normal distribution.
The focus of this research is on the characteristic parameters (mean and standard deviation) of the truncated population with a view to achieving positive values only. The restriction to be placed on σ for the achievement of positive values will be investigated. The N(1, σ2) assumption is always placed on the residuals of the multiplicative time series models in descriptive time series analysis. The residuals are also assumed to be positive. To linearize the multiplicative model, the logarithmic transformation is taken. A brief discussion of the logarithmic transformation of the left-truncated N(1, σ2) distribution is also presented.
MEAN AND VARIANCE OF THE TRUNCATED N(1, σ2) DISTRIBUTION
Using (2), we obtain
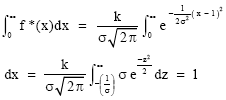 |
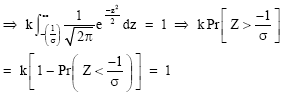 |
(were |
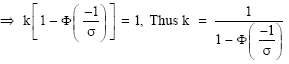 | (5) |
Thus,
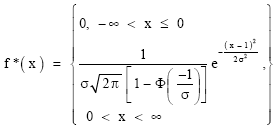 | (6) |
Note that
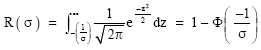 | (7) |
and Eq. (6) is a proper p.d.f. The expectation from is
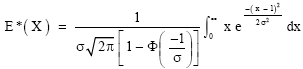 |
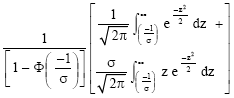 |
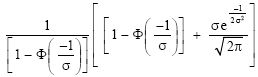 |
Thus,
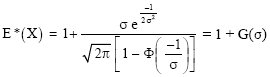 | (8) |
where
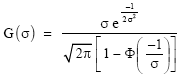 | (9) |
Note that,
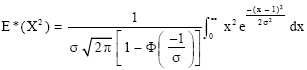 | (10) |
If we let ![]() , we obtain from (6) that
, we obtain from (6) that
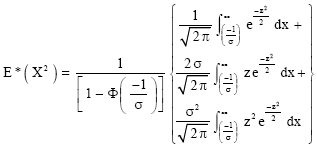 |
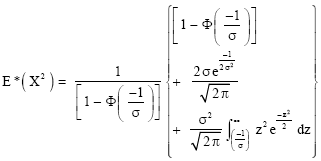 |
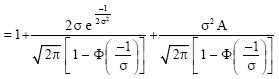 | (11) |
where,
| (12) |
The following equations are correct:
| (13) |
| (14) |
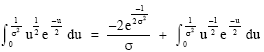 |
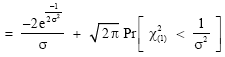 | (15) |
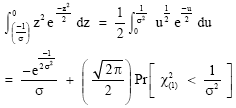 | (16) |
Using (13) and (14), we obtain
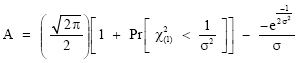 | (17) |
| (18) |
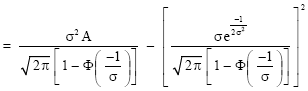 | (19) |
Finally, substituting (17) into (18), we obtain
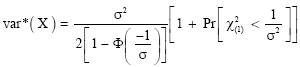 |
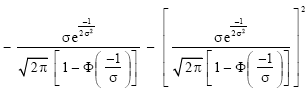 | (20) |
Our computations have shown that the expression for the mean of the left-truncated N(1, σ2) distribution is in terms of the cumulative distribution function (c.d.f.) of the standard normal Eq. (8), while that of the variance is in terms of the cumulative distribution function of the standard normal and the c.d.f. of the Chi-Square distribution with one degree of freedom Eq. 20. Our results for the variance agree with those of Barr and Sherill (1999).
PROPERTIES OF THE MEAN AND VARIANCE OF THE TRUNCATED N(1, σ2) Distribution
In most applications, the requirements needed are (i) f*(x), x#0, (ii) E* (X) = E(X) and var* (X) = var(X). Our derivations have shown that all these depend on the parameter σ. To investigate these requirements, we look for the values of σ for which (i) f*(0) ≈ 0, (ii) E*(X)-E(X) ≈ 0 and (iii) var(X) - var* (X) ≈ 0.
Figure 1 gives the shape of the distribution curve for some values of σ. The two curves for the original (non-truncated) and the truncated populations coincide for some values of σ, while for some values of σ the truncated curve do not admit values greater than zero when they are approximately the same. Generally, the truncated values are always greater or equal to the non-truncated values for all values of σ. We would, therefore, expect the two stochastic variables to behave alike in some interval σ0 (0, b). The quantity b will be determined by use of the three requirements stated above.
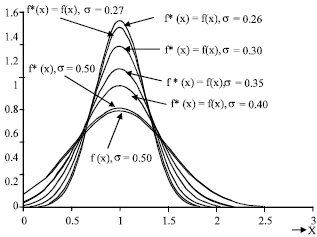 | |
| Fig. 1: | The curve shapes of the left-truncated N(1, σ2) distribution |
| Table 1: | Summary of results for f* (0), E* (X) - E (X), var (X) - var* (X) |
 | |
Our simulation results (all simulations in this paper were performed using MINITAB) will help determine the level of accuracy required for the two stochastic variables to behave alike in a prescribed interval.
Using Eq. 5, 8 and 20, results were obtained for 0.01≤≤2.0 and the results obtained are summarized in Table 1.
From Table 1 and using the three requirements stipulated, it is clear that the desired interval is the interval σ<0.30. It follows from our analysis that the 0.001 limits may be used to give practical assurance that the truncated values from the N(1, σ2) are all positive. The 0.001 probability limits (99.9% confidence limits) are practically equivalent to 3.2905σ limits and for the lower confidence limit to be positive we have 1 - 3.2905σ>0. This implies that σ<0.30 with the truncated values lying between 0.01 and 1.99 (0.01<X<1.99). It is also clear from this analysis that the admissible region, σ<0.30, is needed to ensure that the mean and variance of the truncated distribution remains, respectively, at the assumed values of 1 and σ2.
TIME SERIES APPLICATION
A general multiplicative model for descriptive time series analysis would be of the form
| (21) |
where, for time t, Xt denotes the observed value of the series, Tt is the trend, St the seasonal term, Ct the cyclic term and It is the irregular or random component of the series. The model (21) will be regarded to be adequate when the irregular component is purely random. If short period of time are involved, the cyclical component is superimposed into the trend (Chartfield, 1980), p.13 and we obtain a trend-cycle component denoted by Mt For our purposes, It to be denoted by et are independent, identically distributed normal errors with mean 1 and variance ![]() . Model (21) can then be written as
. Model (21) can then be written as
| (22) |
Descriptive modeling of the multiplicative time series model (22) generally involve the logarithmic transformation. Upon linearization of (22), we obtain
| (23) |
or
| (24) |
where ![]() . It is important to note that (24) is the additive time series model. For model (24), the variant assumption on the random component
. It is important to note that (24) is the additive time series model. For model (24), the variant assumption on the random component ![]() is that they are independent, identically distributed normal errors with mean zero and variance
is that they are independent, identically distributed normal errors with mean zero and variance ![]() .
.
It is evident that for the left-truncated N(1, σ2) distribution given by (6), we need to investigate the characteristics of
| (25) |
The probability density function of Y is given by ![]() . Thus
. Thus
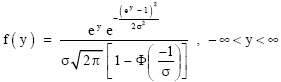 | (26) |
Equation (26) is a proper probability density function and its curve shapes for some values of σ are given in Fig. 2.
It is clear from Fig. 2 that the distribution of Y = loge X is skewed to the left with some symmetric and bell-shaped conditions for small values of σ. For all values of σ, the curve f (y) has one maximum point (y0) and one maximum value (f(y0)). To obtain the maximum point for a given value of σ, we consider f` (y) = 0. Now,
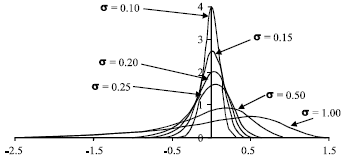 | |
| Fig. 2: | Curve shapes of the logarithm of the left-truncated |
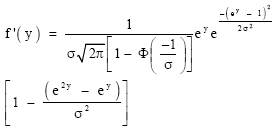 | (27) |
Equating ![]() we obtain
we obtain
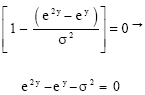 | (28) |
If we let w = ey, we obtain
| (29) |
That is,
Note that
and
Hence
and
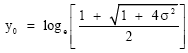 | (30) |
For our purposes (investigation of bell-shaped conditions), y0 . 0. Using the number of significant decimal places to determine the level of accuracy required, we obtain the summary listed in the last column of Table 1. We use 2 significant decimal places as the level of accuracy required to obtain that σ#0.07 for symmetry and bell-shaped conditions. However, if and when the accuracy requirement is 1 significant decimal place, we use σ≤0.23.
Bell-shaped frequency distributions will have
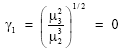 | (31) |
and
| (32) |
where
| (33) |
is the kth moment about the mean μy of Y = loge X. We must recall at this point that γ1 is a measure of skewness and γ2 is a measure of kurtosis. The solution of (33) cannot be solved easily with an analytic approach, we therefore resort to the Monte Carlo method.
Sample estimates of the moments about the mean are given by
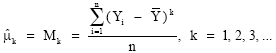 | (34) |
where n is the sample size. Artificial data was generated from the N(1, σ2) density function for the variable X and the X values obtained were subsequently used to generate from the model Y = loge X, where 0.07#σ#0.23. For each configuration of (n = 100, 0.07#σ#0.23), 1000 replications were performed. For want of space, we show the results of the first 30 replications for two configurations: (n = 100, σ#0.07) in Table 2 and (n = 100, σ#0.23) in Table 3.
We now consider the significance of skewness and kurtosis for samples of size n = 100. We must note that γ1 and γ2 measure nonnormality on the basis of skewness and kurtosis of the distribution, respectively. The 0.05 and 0.01 points of the sampling distributions of γ1 and γ2 are given in Duncan (1974) as Tables F and G, respectively. If a given sample has a value of γ1 and γ2 beyond the 0.05 point (a stricter test would use the 0.01 points) for that statistics the population may be deemed to be nonnormal. For samples of n = 100, the upper 0.05 point for γ1 is 0.389 and the upper 0.01 point is 0.567.
| Table 2: | Simulation results for skewness (γ1) and (γ2) kurtosis when σ = 0.07 |
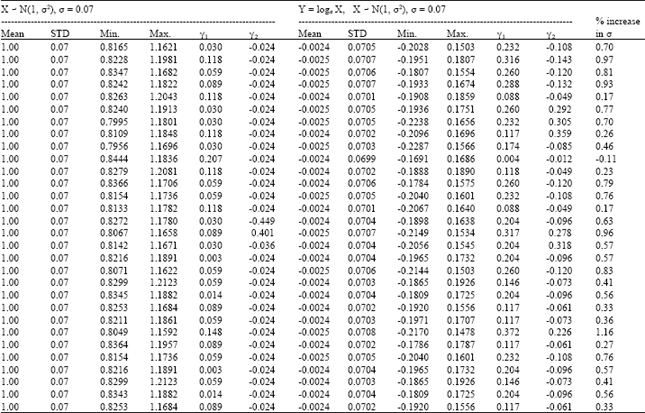 | |
| Table 3: | Simulation results for skewness (γ1) and (γ2) kurtosis when σ = 0.23 |
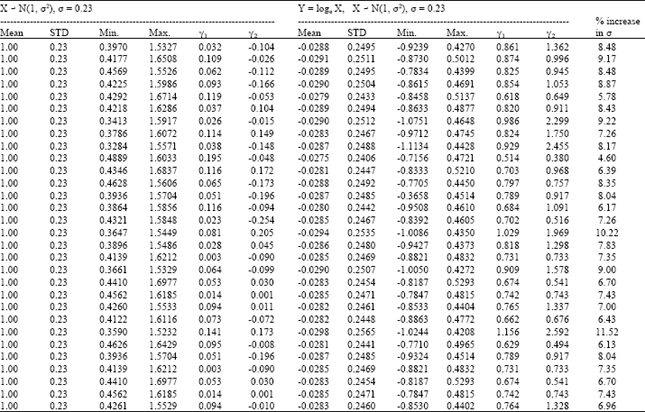 | |
Equivalently, the upper 0.05 point for γ2 is -0.65, for γ2<0 and 0.77 for γ2>0; while the upper 0.01 point is -0.82 for γ2<0 and 1.39 for γ2>0. It will be noted that a population distribution can have γ1 = 0 or γ2 = 0 without their being normal (Shewart, 1931). Sample values close to these normal values do not therefore prove normality; they merely do not lead to the rejection of the normal hypothesis.
It is clear from Table 2 that when σ = 0.07, both X and Y = loge X can be assumed to be normally distributed with var (X) . var (Y). On the other hand, we infer from Table 3 that when σ = 0.23, Y = loge X, cannot be assumed to be normal on the basis of the sample values of γ1 and/or γ2. Our search for normality of Y = loge X for X - N(1, σ2), 0.07#σ#0.23 showed that the sample value of γ1 indicates departure from normality from σ = 0.10. We conclude that when X - N(1, σ2), the logarithmic transform Y = loge X can be assumed to be normally distributed with mean zero and variance σ2, provided σ<0.10.
CONCLUSION
In this research, we have examined some implications of truncating the N(1, σ2) distribution to the left at zero. We observed that the truncated values are always greater or equal to the non-truncated values for all values of σ. However, the two stochastic variables behave alike in the interval σ<0.30. It follows from our analysis that the 0.001 limits may be used to give practical assurance that the truncated (truncation at zero) values from the N(1, σ2) distribution are all positive. In the interval σ<0.30, the truncated and the non-truncated variables have the same mean equal to 1 and variance equal to σ2.
The most important implication of truncating the N(1, σ2) distribution to the left at zero is in descriptive modelling of time series data, where the logarithmic transform of the truncated distribution is equally assumed to have mean zero and some finite variance. It was noted that the logarithmic transform will have mean zero and the same variance as both the original N(1, σ2) distribution and its truncated distribution in the interval σ<0.10.
The results of our study suggests that the logarithmic transforms of the normal distribution are worthy of future research. Part of this research must include the left-truncated N(1, σ2) distribution which has important applications in descriptive time series studies. Further work is needed to compute analytically the moments about the mean of the logarithmic transform. However, our results suggests one should exercise extreme caution with respect to the value of σ when linearizing multiplicative models in descriptive time series analysis.
REFERENCES
- Johnson, A.C. and N.T. Thomopoulos, 2004. Characteristics and tables of the left-truncated normal distribution. Proceedings of the Midwest Decision Sciences Institute, April 2004, Cleveland, pp: 133-139.
Direct Link