
Ani Shabriand
Not Available
Abdul Aziz Jemain
Journal of Applied Sciences
Year: 2006 | Volume: 6 | Issue: 4 | Page No.: 926-932







ABSTRACT
Generally, researchers are faced to identify the true statistical distributions for the analysis of a various hydrologic data sets. Using traditional statistical analysis methods one choose a hypothesized distribution to describe the observed data, estimate the distribution parameters and then apply the goodness of fit test such as the Chi Square test (CS) or Kolmogorov Smirnov (KS) test. For more accurate, several factors or criteria should be considered in selection of the best distribution. However when more than two criteria are used to identify the best distribution, it is more difficult and more subjective. In this paper, we propose a new Multi Criteria Decision Making method (MCDM) based on nonlinear programming for selection of the best distribution to fit a set of data. The Generalized Extreme Value (GEV), Generalized Pareto (GP), Pearson 3 (P3) and Lognormal 3 (LN3) are used and their goodness of fit has been examined by various test statistics. A numerical example is used to illustrate the applicability of the proposed approach.
PDF Abstract XML References Citation
How to cite this article
Ani Shabriand and Abdul Aziz Jemain, 2006. Application of Multi Criteria Method to Identify the Best-fit Statistical Distribution. Journal of Applied Sciences, 6: 926-932.
DOI: 10.3923/jas.2006.926.932
URL: https://scialert.net/abstract/?doi=jas.2006.926.932
DOI: 10.3923/jas.2006.926.932
URL: https://scialert.net/abstract/?doi=jas.2006.926.932
INTRODUCTION
In order to do effective planning, design and management of water resources engineering such as water supplies, hydropower, irrigation systems, etc., the statistics of annual streamflow series are required, which can be understood by conducting frequency analysis on annual streamflow. The purpose of Flood Frequency Analysis (FFA) is to select an appropriate distribution type for representing a hydrological variable of interest at a site or in a region. There is a wide range of flood frequency models developed in hydrology. In the open literature, there are a few studies to identify the probability type of annual streamflow in the world (Yue and Wang, 2004). The search for the proper distribution function has been subjective of several studies.
The commonly used procedure is to first choose a hypothesized distribution, then estimate the parameters of the hypothesized distribution using the moment method, the maximum likelihood method or L-moment method and finally apply the goodness of fit such as Kolmogorov-Smirnov test (KS) or Chi-square (CS) test to see if the hypothesized distribution can be rejected or not (Wang et al., 2004).
Cunnane (1985) discussed factors affecting the choice of a distribution for FFA, including the method of parameter estimation, treatment of outliers, inclusion of large historical flood values, data transformations and causal compositions of flood population. He concluded that distribution choice could not be based on theoretical arguments alone or one criterion.
Many researchers proposed several criteria good test statistics in selection of the best statistical distribution to fit the data. For example, Turkman (1985) used the Akaike’s Information Criteria (AIC) for the choice of extremal models and analyzed its effectiveness in choosing the most likely among the Gumbel, Frechet and Weibull distributions. Onoz and Bayazit (1995) considered the CS, KS, AD (Anderson-Darling) and PPCC tests for evaluating the suitability of seven distributions for the flood data from 19 stations all over the world. Kim and Heo (2002) used the statistic CS, KS, CvM (Cramer von Mises) and PPCC tests to see if the hypothesized of the Gamma, GEV, Gumbel, Log-Gumbel, Lognormal, Log- Pearson or Weibull distribution can be rejected or not to fit the annual maximum flood of Goan station in Korea. Zalina et al. (2002) applied the PPCC test, the Root Mean Square Error (RMSE), the relative root-mean square error (RRMSE) and the Min Absolute Error (MAE) to assess the capability of eight distributions to describe the annual extreme rainfall data of Peninsular of Malaysia.
In these procedures, the choice of the hypothesized distribution is often based on the rule of thumb. The selected statistical distributions for the same data may be different for different analysis. This will occur when two or more statistical distributions were tested by only one or two test statistics. However when more than two test statistics are used to identify the best distribution, it is more difficult and more subjective.
The selection of the “best” distribution from a set of test statistics is a multi-criteria decision making problem. Many methods have been proposed to solve a multi-criteria decision making problem such as the least deviation method (Xu and Da, 2004), linear goal programming method (Fan et al., 2004, 2005) and the fuzzy majority approach (Chiclana et al., 1998; Herrera et al., 2001).
In this study, a new method based on a non linear programming is proposed to solve multi criteria decision making problem. In the proposed approach, a non linear programming model is constructed to integrate the fuzzy preference relation and to compute the collective ranking values of the alternatives. Once the collective ranking values are known, the selection of the best distribution can be obtained.
Five selection test statistics, namely the MSEC (mean square relative error in cumulative distribution function, CDF), MAE, RMSE, KS and NIFL (normalized likelihood function index) test and four distributions, namely the Generalized extreme value (GEV), Generalized Pareto (GP), Pearson 3 (P3) and Lognormal 3 (LN3) distributions are considered in the illustration of the proposed approach. The performance of the new approach is compared to the fuzzy majority approach that proposed by Chiclana et al. (1998).
PROBABILITY DISTRIBUTION FUNCTIONS OF FLOOD FREQUENCY ANALYSIS
Four of the commonly distributions used in hydrology are considered in this study (e.g., Hosking, 1990; Hosking and Wallis, 1997; Sveinsson et al., 2002). The forms of the probability density function of these distributions are follows:
Lognormal (LN3):
| (1) |
Generalized Extreme Value (GEV):
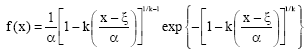 | (2) |
Pearson Type Three (P3):
| (3) |
Generalized Pareto (GP):
| (4) |
where, α, ξ and k are scale, location and shape parameters respectively. Parameters of these distributions are estimated by the L-moments method. We do not give here any equations for the parameter estimation of the considered distributions because they are well known and commonly appear in many publications (Rao et al., 1997; Sveinsson et al., 2002; Hosking, 1990; Hosking and Wallis, 1997).
GOODNESS OF FIT CRITERIA
Five criteria, which measure the relative goodness of fit test statistics, were employed for comparison of the probability distributions for fitting on a data set. The set of criteria as follows:
a. The Mean Square Relative Error (MSEC) In CDF statistic test.
The MSEC test is based on mean square distance between the hypothesized CDF and the empirical CDF (Whalen et al., 2002). The MAE is given by:
| (5) |
b. The Mean Absolute Error (MAE) statistic test
The MAE test is based on the mean absolute distance between the observed data values, xi and the estimated data values, ![]() , respectively (Zalina et al., 2002). The MAE is given by:
, respectively (Zalina et al., 2002). The MAE is given by:
| (6) |
c. The Root Mean Square Error (RMSE) statistic test
The RMSE test is based on the mean square distance between the observed data values, xi and the estimated data values, ![]() , respectively (Guo et al., 1996). The RMSE is given by:
, respectively (Guo et al., 1996). The RMSE is given by:
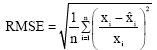 | (7) |
d. The Kolmogorov-Smirnov (KS) test statistics.
The KS test statistic is use to measure the maximum deviation between the hypothesized CDF and the empirical CDF at the same observation point or among a pair of consecutive observation points (Wang, 2004). The KS is given by:
| (8) |
e. The Normalized Likelihood Function Index (NLFI) test statistics.
The NLFI test statistic is the mean of the logarithm of the probability distribution function, f(x) (Jain and Singh, 1987). The NLFI test statistic is given by:
| (9) |
The smaller value of the test statistics in case of criteria (a)-(e) is the better the sample data fits the chosen distribution.
MAKING THE MEASUREMENT VALUE UNIFORM
In MCDM approach, the rating or the performance measurement value given by each test statistics to the distributions is used in the field. The higher the rating, the better the distribution satisfies the test statistics. The ratings assumed are given in the range between 0 and 1.
However, in our study the five criteria test statistics may take values out of the range [0, 1]. In addition, based on each of the five criteria, smaller the value, the better the distribution fit to the sample. There is need to standardize these measures such that they are all in the range of [0, 1] and the higher the measurement value, the better the fit. The transform function based on the Cauchy distribution function is used to standardize the measures (Wang et al., 2004). The Cauchy distribution function is given by:
| (10) |
where, v, is the test statistic value of a hypothesized distribution and t is a constant determined empirically to make sure that the performance measures will spread in the range [0, 1].
MULTIPLE CRITERIA
Multi Criteria Decision Making (MCDM) is an important part of modern decision science. It has been extensively applied to various areas such as economic analysis, urban or regional planning and forecasting etc. In a MCDM problem, we have a set of alternatives to be analyzed according to different purposes in order to select the best one (Chiclana et al., 2001). A decision maker is often faced with the problem of selecting or ranking alternatives associated with non-commensurate and conflicting attributes (Fan et al., 2004).
Presentation of the problem: Let X = {x1, x2, K, xn}, (n≥2) be a finite set of the distributions and E = {e1, e2, K, em}, (m≥2) be a finite set of test statistics. Let C = (c1, c2, K, cm) be the weight vector of the test statistics, where ![]() , ch, ≥ 0, h = 1, K, m and ch denotes the important degree of test statistic ch and is usually determined by the decision makers.
, ch, ≥ 0, h = 1, K, m and ch denotes the important degree of test statistic ch and is usually determined by the decision makers.
The problem concerned in this paper is to rank distributions or to select desirable distributions among a finite set X based on fuzzy preference relations.
The fuzzy majority approach: Chiclana et al. (1998) proposed the fuzzy majority approach to solve the Multi Criteria Decision Making (MCDM) problem for the aggregation and to select desirable of the information in decision making. The approach consist the three steps: (i) uniform the preference information through a transform function, (ii) aggregate the uniformed preference information into a collective one and (iii) rank alternatives or select the most desirable alternative of distributions by means of the weighted average operator.
In generally, the information provided by a set of criteria is supposed to be of a diverse nature. To make the information uniform, a transformation function is used to transform the preference utilities into the format of the preference relations. The transform function is called the preference degree of the alternative xi over xj is given by:
| (11) |
where, ![]() represents the measurement value given by the test statistics ek.
represents the measurement value given by the test statistics ek.
Since the important degree of each test statistics is not equal, hence the fuzzy majority criteria with the fuzzy quantifier such as most, at least half or as many as possible, is used to aggregate the uniformed preference information into a collective one. The collective fuzzy preference relation is obtained as follows:
| (12) |
where,![]() is the k th largest value in the set {p1ij,…, pmij} and Q(r) is given by:
is the k th largest value in the set {p1ij,…, pmij} and Q(r) is given by:
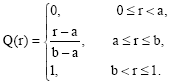 | (13) |
| (14) |
Thus by Eq. 13, the fuzzy preference relations, P1, K, Pm, are aggregated into a collective fuzzy preference relation as follows:
| (15) |
In order to the rank the distributions or select the most desirable distribution (s), the fuzzy quantifier also is used to compute the collective ranking values of distribution, i.e.,
| (16) |
where, ![]() is the collective ranking value of the I th distribution. From Eq. 16, we can obtain that the collective ranking value vector of the distributions is
is the collective ranking value of the I th distribution. From Eq. 16, we can obtain that the collective ranking value vector of the distributions is
| (17) |
According to the obtained ranking values, the ranking of the distributions or selection of the most desirable distribution(s) is done. The greater the ranking value ![]() is the better the corresponding alternative xi will be.
is the better the corresponding alternative xi will be.
The proposed approach: Suppose the collective ranking value of alternative xi is wi (i = 1, K, n)and wi is unknown variable where wi ≥ 0, ![]() . The problem in this research is how to determine the collective ranking values of alternatives based on the preference relation provided by the decision makers.
. The problem in this research is how to determine the collective ranking values of alternatives based on the preference relation provided by the decision makers.
In order to do that, we proposed the fuzzy preference relation (Chilana et al., 1998) where
| (18) |
From Eq. 18, the deviation degree between ![]() and
and ![]() is given by:
is given by:
The collective deviation degree ![]() as follows
as follows
| (19) |
To make the group consensus better, we can minimize zij (w) by assessing the collective ranking values wi(i = 1, K, n). Thus, the following multiple objective constrained optimization model:
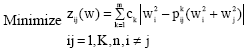 | (20a) |
| (20b) |
| (20c) |
Solution to the above minimization problem is found by solving the following non linear programming model:
| (21a) |
| (21b) |
| (21c) |
| (21d) |
| (21e) |
Where, sij is the weighting factor corresponding to positive deviation ![]() and
and ![]() is the weighting factor corresponding to positive deviation. By solving model (21), the collective ranking value vector,
is the weighting factor corresponding to positive deviation. By solving model (21), the collective ranking value vector, ![]() , can be obtained. The greater the ranking value
, can be obtained. The greater the ranking value ![]() is the better the corresponding alternative xi will be.
is the better the corresponding alternative xi will be.
Based on Eq. 19, the total deviation degree of group consensus is given by:
| (22) |
Obviously, the smaller the value of total deviation degree D(w) is the better the group consensus are.
ILLUSTRATIVE EXAMPLE
To illustrate the application of MCDM problem, the annual flood peaks series data of the station 3516422-Selangor in Peninsular Malaysia for the past 40 years (1961-2001) was analyzed. The data is given in Table 1.
| Table 1: | Recorded annual flood peaks series of the station 3516422-Selangor (values in m3 s-1) |
 | |
| Table 2: | Estimated parameters for candidate distributions |
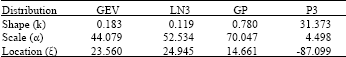 | |
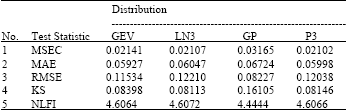
| Table 3: | Statistics calculated with Eq. 5-9 |
 | |
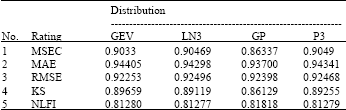
| Table 4: | The rating values obtained with Eq. 10 |
 | |
The parameters of the all distributions were estimated with the L-moments method. The estimated parameters of these four distributions are listed in Table 2.
For the data in Table 3, we then used Eq. 10 to transform them into values in (0, 1) with larger value indicating a better performance against each criteria. The constant values t of Eq. 10 used for the five rows of the data given in the Table 3 are 5, 1, 1, 1 and 0.05, respectively. The transformed performance measures obtained using Eq. 10 are given in the Table 4.
From Table 4, we can see that based on the MSEC test statistic alone, P3 distribution provides the best fit. If only the MAE test statistic is considered, the GEV best fit. If only the RMSE test statistic is considered, the GP distribution provides the best fit. The other results are shown in Table 4.
The fuzzy majority approach: To apply the fuzzy majority approach, a transform function given in Eq. 11 is used to transform the rating values into the formats of fuzzy preference relation. The fuzzy preference relation are given by:
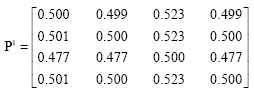 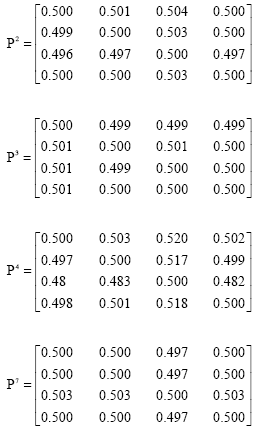 |
Since the important degree of each decision maker is not equal, the fuzzy majority criterion with the fuzzy quantifier “at least half” with the pair of values (0, 0.5) based on the Eq. 14 is used. The weighting vector c1 = 0.4, c2 = 0.4, c3 = 0.2, c4 = 0 and c5 = 0 using the Eq. 14. Then the collective fuzzy preference relation is:
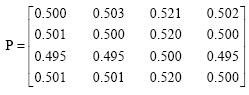 |
In order to rank the alternatives or select the most desirable alternatives, the fuzzy quantifier “most” with the pair (0.3, 0.8), i.e., the corresponding with the weighting vector c1 = 0, c2 = 0.4, c3 = 0.5 and c4 = 0.1 is found. From Eq. 17, we obtained that the collective ranking value vector of the alternatives is
| Table 5: | Comparative results of the two approaches |
 | |
According to the obtained ranking value vector w*, the ranking result of the four distributions is x1 > x4 > x2 > x3. This means that the GEV distribution, provides the best fit to describe the annual flood peaks series data of the station 3516422-Selangor in Peninsular Malaysia.
To obtain the total deviation degree of group consensus, i.e., D(w*), in Eq. 10, the sum of the entries of ranking value vector w* must has a sum of 1. However, the sum of the collective ranking value vector w* had a sum more than 1. The ranking value vector was scaled so that the sum the entries ranking value vector had a sum of 1. The total deviation degree of group consensus after scaled, i.e., D(w*) = 0.00807.
The proposed approach: In this study, the important degree of each test statistic is equal, i.e., c1 = K = C5 = 1/5. For simplicity, let sij and tij be equal to 1. Using Eq. 21a-e, we can set up the following non linear programming model:
 |
By solving the above non linear programming problem, we have the following results:
Therefore, the collective ranking value vector of alternatives is
According to the obtained ranking value vector w*, the ranking results of the four distributions is x1 > x4 > x2 > x3. The total deviation degree of group consensus, D(w*) can be obtained by substituted w* (i = 1, 2, 3, 4) in Eq. 10, i.e., D(w*)=0.00622.
The computational results of the nonlinear programming approach and the fuzzy majority approach after scaled are compared and shown in Table 5.
It can be noticed from above table that the two collective ranking value vectors obtained by the two approaches are similar. But it can be seen that the total deviation degree of the group consensuses obtained by two approach are different and D (w*) < D (w*). This illustrates that the group consensus of the proposed approach is better than one based on the fuzzy majority approach.
CONCLUSIONS
The search for the proper distribution function has been subjective of several studies. The best distribution choice could not be based on one theoretical argument alone or one criterion. However, when more than two criteria are used, it more difficult and more subjective.
In this study, we proposed a new Multi Criterion Decision Making (MCDM) approach for selection of the best distribution to fit a set of data. A numerical example is used to illustrate the use of the proposed method. The approach is based on the non linear programming which can be used to assess attribute weight and then to select the most desirable distributions. The five commonly distributions considered are: GEV, GL, LN3, GP and P3. For the distributions selection, five criteria test statistics were used.
The performance of the new approach is compared to the fuzzy majority approach. The result show that the new approach performs as well as the fuzzy majority approach.
The proposed approaches provides decision makers to improve quality of decisions by making its more explicit and efficient, especially in order to selection the best distribution in specific field of application.