
B.H. Lavenda
Universit� degli Studi Camerino 62032 (MC), Italy
J. Dunning- Davies
Department of Physics, University ofHu11, Hull HU6
Journal of Applied Sciences
Year: 2005 | Volume: 5 | Issue: 5 | Page No.: 928-937







ABSTRACT
Like Jaynes’ maximum entropy formulation, the Tsallis entropy is to be maximised ’with respect to all that is known about the system’. However, instead of customary averages, the averaging is performed with ‘escort’ probabilities resulting in Student’s t-distribution, as opposed to exponential distributions in Jaynes’ formalism. The same class of non-exponential distributions, possessing ‘fat’ tails, is said to be derived from so-called ‘superstatistics’. Here it is shown that there is neither motivation nor need to introduce a ‘super’ statistics.
PDF Abstract XML References Citation
How to cite this article
B.H. Lavenda and J. Dunning- Davies, 2005. Are Superstatistics and Nonextensive Statistical Mechanics Viable?. Journal of Applied Sciences, 5: 928-937.
DOI: 10.3923/jas.2005.928.937
URL: https://scialert.net/abstract/?doi=jas.2005.928.937
DOI: 10.3923/jas.2005.928.937
URL: https://scialert.net/abstract/?doi=jas.2005.928.937
INTRODUCTION
In 1988, a study appeared[1] which supposedly introduced, with no recognisable preamble, a new entropy expression into the field of statistical thermodynamics. As has been shown on several occasions[2-4], the said expression had been known to information scientists since the late 1960’s. However, its introduction to statistical thermodynamics has spawned a plethora of articles which are aimed primarily at determining the exponent in the Tsallis entropy for individual systems. That would mean that each such system would have its own thermodynamics. As this is quite impossible, the entropy cannot depend upon a parameter that is different for different systems. While the apparent claim of novelty in the 1988 study is definitely questionable, some of the subsequent studies which make use of it do little other than provoke qualms over the validity of their content. Here attention will be restricted to just three such articles which, at first sight, might seem aimed at extending the field of statistical thermodynamics.
BECK AND COHEN’S ‘SUPERSTATISTICS’
Beck and Cohen[5] attempted to generalise the Boltzmann factor in order to obtain a more general statistics, which they termed ‘superstatistics’. They did this by performing a Laplace transform on the probability density function (pdf) of an intensive variable f(β), where β is the inverse temperature. The criteria used for choosing f(β) were:
| (i) | it must be normalised: |
| (1) |
| (ii) | it must be such that its Laplace transform: |
is normalised, or at least is normalised with respect to a density of states ρ(E):
| (iii) | the superstatistics should reduce to BG-statistics when there are no fluctuations in β. |
In thermodynamics, there are two types of variable: extensive and intensive. In mathematical statistics they correspond to observable and estimable variables, respectively[6,7]. Estimable variables relate the pdf of the extensive variables to the properties of the physical system. They are referred to as the ‘state of nature’ in mathematical statistics. Estimable variables, like the inverse temperature, change due to the nature of the physical interaction and therefore, cannot be considered random variables in the frequency sense. Estimable variables cannot be treated in the limit-of-frequency sense; rather they must be interpreted in the subjective sense that some values of β are more ‘probable’ than others.
If the parameter’s value is completely unknown insofar as it can take on any conceivable value from 0 to ∞, Jeffreys’ rule for choosing the prior is to take its logarithm as uniform so that[8]:
| (2) |
Since the integral of the prior is infinite, it is improper. Jeffreys uses ∞ to represent the probability of a certain event rather than 1. The indeterminacy for predicting whether the value will fall within the interval (0, b),![]() representation of ignorance.
representation of ignorance.
However, Beck and Cohen[5] do not imply that their f(β) is a prior pdf. Transforming an improper pdf into a proper pdf may be done by using Bayes’ theorem[9]. The method uses a likelihood function which essentially inverts the roles of the observable and estimable variables. Due to the additivity of the observable variables, the likelihood function will be a product of the individual probabilities. The likelihood function takes us from an improper, uninformative, pdf to a proper, informative one. This is the meaning of f(β).
Bayes’ theorem may be written as[7]:
| (3) |
where, L(β, ![]() ) is the log-likelihood function which transforms the prior pdf f(β) into the posterior pdf f(β,
) is the log-likelihood function which transforms the prior pdf f(β) into the posterior pdf f(β, ![]() ), where,
), where, ![]() is the average energy of the sample. Since the posterior pdf is normalised, we obtain the explicit expression for B(
is the average energy of the sample. Since the posterior pdf is normalised, we obtain the explicit expression for B(![]() ) as:
) as:
where, L(β) is the Legendre transform of the entropy with respect to the energy and Jeffreys’ improper prior pdf has been introduced in the second expression.
Now to consider the examples treated by Beck and Cohen. According to them, the most relevant example of superstatistics is the gamma pdf:
| (4) |
This Gamma pdf for the inverse temperature has been derived from Bayes’ theorem (3) already by Lavenda[7], Eq. (4.97), where, 2c =3N is the effective number of degrees of freedom and b = 1/E0 is a fixed parameter. Setting their f(β) = e-L(β)/β, it is seen that:
Since L(β) is the Legendre transform of the entropy, it is also the logarithm of the partition function, so that:
which leads to the thermal equation of state:
| (5) |
where, β0 = bc = 3N/2E0 in the notation adopted here. The entropy is the Legendre transform of L so that, if c is large enough for Stirling’s approximation to hold:
| (6) |
This means that:
| (7) |
where, β is given by (5) and
It is imperative to emphasise that absolutely no reference to superstatistics has been made here! Fluctuations in intensive variables occur in BG-statistics. In fact, for b![]() >>1 the thermal equation of state (5) reduces to the thermal equation of state of an ideal gas with 2c degrees of freedom, β = c/
>>1 the thermal equation of state (5) reduces to the thermal equation of state of an ideal gas with 2c degrees of freedom, β = c/![]() and (6) gives the energy dependency of the entropy of an ideal gas, S= clog
and (6) gives the energy dependency of the entropy of an ideal gas, S= clog ![]() and. Superstatistics supposedly enters when Beck and Cohen identify B with the Tsallis distribution where c = 1/(q-1) and q is the exponent in the Tsallis entropy. They write B = exp{-clog(1+b
and. Superstatistics supposedly enters when Beck and Cohen identify B with the Tsallis distribution where c = 1/(q-1) and q is the exponent in the Tsallis entropy. They write B = exp{-clog(1+b![]() )} and expand it for small b
)} and expand it for small b![]() . Yet their resulting expansion is not in powers of b
. Yet their resulting expansion is not in powers of b![]() ! The parameter b = β0/c = β0(q-1), which in the present notation is b = 1/E0, the inverse of the total energy. The expansion is:
! The parameter b = β0/c = β0(q-1), which in the present notation is b = 1/E0, the inverse of the total energy. The expansion is:
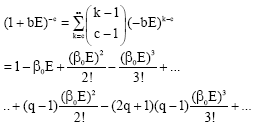 |
and not their Eq. 14 in which ![]() may be factored out of the sum. This has fatal consequences for their conclusion, in their Eq. 25, that the Tsallis entropy exponent
may be factored out of the sum. This has fatal consequences for their conclusion, in their Eq. 25, that the Tsallis entropy exponent ![]() which already looked suspicious since it excluded values of q<1.
which already looked suspicious since it excluded values of q<1.
The log-normal pdf for the inverse temperature was derived[7], where there is a 1/Ti missing. This term is due to the Jacobian of the transformation on going from 4.114 to 4.115. It was derived from an error law for the temperature for which the geometric mean is the most probable value of the temperature measured. The geometric mean value of the temperature is the lowest temperature attainable when two bodies at different initial temperatures are placed in thermal contact and where the processes of heat withdrawal and injection and conversion into work are all carried out reversibly. Again there is no mention, or need, of superstatistics.
Beck and Cohen[5] first example has been left until last because it illustrates two general principles. Firstly, Beck and Cohen[5] choose a uniform prior pdf in an interval a to a + b. According to Jeffreys’ first rule, a uniform prior is appropriate when the parameter involved may conceivably assume all values from-∞ to +∞. Since the temperature is non-negative, β may assume values from 0 to ∞ and for such a parameter, Jeffrey[8] suggests taking its logarithm uniform, (2).
Secondly, the Legendre transform, as already mentioned, is equivalent to the Laplace integral here but this is not justified in this case because it is not a thermodynamic system with a large number of degrees of freedom. Consider the following Laplace-type integral:
| (8) |
Under change of variable β = mγ, the integral becomes:
where, a′ = a/m, b′= b/m and φ(γ) = γE-logγ.
The function φ has a minimum at ![]() or equivalently
or equivalently ![]() which is the thermal equation of state for a system of 2m degrees of freedom. Expanding φ(γ) up to second order in the small difference
which is the thermal equation of state for a system of 2m degrees of freedom. Expanding φ(γ) up to second order in the small difference ![]() gives:
gives:
where, a further change of variable, ![]() has been introduced.
has been introduced.
It might be noted that, no matter how small b is, m may be taken so large that the value of the integral is altered only slightly when the limits of integration are replaced by ±∞[10]. Thus, finally:
For large m, the numerator is Stirling’s approximation to m! up to order 1/m. Hence, the final expression for the entropy is:
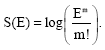 |
Therefore, the Legendre transform may be used instead of evaluating the Laplace transform for values of m for which Stirling’s approximation holds. Only in this case may the principles of statistical thermodynamics be used[7]. This does not apply to Beck and Cohen’s uniform distribution. Finally, it might be noted that (8) is essentially the Gamma pdf (4) in the case of large b and so the normalisation condition (1) is irrelevant.
THE NONEXTENSIVE STATISTICAL MECHANICS OF BECK
There is always a certain delight in seeing old ideas from a new perspective, but there is no delight in seeing professed ‘new’ ideas that are not new. The notion of ‘superstatistics’, as discussed above[5] grew out of an idea that if one began with a stationary Maxwell distribution and introduced a randomised operational temperature, then a new process could be derived which had something to do with the so-called Tsallis distribution[11]. This distribution had been obtained as a stationary condition for maximising a nonadditive entropy of degree q with respect to the energy constraint[12]. The generalisation to ‘superstatistics’ then consisted in replacing the exponential in the Maxwell distribution by e-βH, where, H is any generic Hamiltonian and using an arbitrary probability distribution for the conjugate β one could obtain a new probability distribution for H by integrating the product of the two probability distributions over all values of β. The physical justification of this procedure has been questioned above already.
The actual idea of randomising temperature is not new as Beck would have us believe; it was discussed by Lavenda[13]. It is based on subordination, which is discussed by Feller[14]. If X(t) represents a brownian motion then, by randomising the operational time t, a variety of new processes may be derived. That is, if the displacements of brownian motion are governed by the pdf:
where, x is the random variable and t0 the parameter, then exchanging their roles leads to a Lévy pdf:
| (9) |
for the randomised time, t, where, x0 is the parameter. The two pdf are related by the transform x2/t0 = x0 2/t. The Cauchy process is then said to be subordinated to brownian motion[14]:
where, the two processes are evaluated at the same time.
The Maxwell speed, u(T), in a single dimension and the temperature, T, stand in the same relation as the displacement of a brownian motion process, X(t) and the time, t[13]. The Cauchy distribution for the speed is, therefore, subordinated to the Maxwell distribution in one dimension[13]. Therefore, Beck[11] does not have to suppose that the fluctuations in the inverse temperature, β, follow a χ2 distribution given by his Eq. 2:
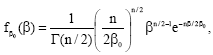 | (10) |
which , on the strength of equipartition, u02β0 = n, could be written:
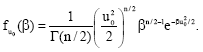 | (11) |
By what is shown to be an incorrect association of Tsallis’ distribution with the subordinated process, Beck finds n = 2/(q-1), where, q is the degree of the nonadditive entropy or what is commonly known as the Tsallis exponent. A single mode of (10) exists at β = (1-2/n)β0. The single mode vanishes, therefore, for all q≥2. Hence, a qualitative change in the behaviour of the process might be expected for q<2 and q≥2. That no behavioural change has been predicted casts doubt on the association of half the number of degrees of freedom with the inverse of (q-1).
It follows from the Lévy transform:
| (12) |
that the n-dimensional Maxwell speed distribution,
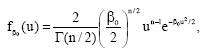 | (13) |
corresponds to the χ2 distribution for inverse temperature (11) and not Beck’s one dimensional Maxwell pdf (Eq. 21). What has happened is that, in a space of n dimensions, the starting point was a Markov process, u(β), whose stationary transition probability is given by (13). A host of new processes may be derived by randomising the temperature or its inverse, β>0, corresponding to a new random variable B(β) whose pdf is (11). The process b(β) is called the ‘directing’ process[14]. The pdf of the new process u(b(β)) will be given by:
| (14) |
where, β has been set equal to β0 to ensure that the two processes are in thermal equilibrium and B(..,..) is the beta function. Contrary to what has been claimed[9], (14) is not Tsallis’ canonical probability distribution Eq. 9[11]:
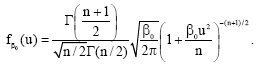 | (15) |
From symmetry consideration, all odd order moments of (15) are zero. In particular, the second moment is:
| (16) |
which does not reflect equipartition that follows from (13) (Eq. 25).
For a generic value of n, (14) is a special case of the inverse beta pdf:
| (17) |
where, x = (u/u0)1/2. In economics, (17) is known as the Pareto pdf since ‘it was thought (rather naively from a modern statistical standpoint) that income distributions should have a tail with density ~ Ax-α as x → ∞ and (17) fulfils this requirement[14].
In a single dimension, (14) is the half-Cauchy pdf for a positive variate. Just as the Cauchy process for the displacement is subordinated to brownian motion in one dimension when time is randomised, the Cauchy process for the kinetic energy is subordinated to the Maxwellian in a single dimension when the temperature, or its inverse, is randomised[13].
In n = 3 dimensions, (14) is[13]:
| (18) |
This is the pdf of the length of a random velocity vector in ![]() in
in ![]() dimensions. It is related to the density:
dimensions. It is related to the density:
| (19) |
in a fixed direction by[14]:
| (20) |
where, the prime denotes differentiation with respect to the argument. The pdf (19) has (2 m-1) degrees of freedom. For m = 1, (19) reduces to the Cauchy pdf, while for m = 2, implying that the distribution has three degrees of freedom, (18) is obtained from (20). Hence, (18) is the density of the length v of a random velocity vector in n = 3 dimensions[13].
Although (10) is valid for any n>0, Beck’s ‘conditional’ pdf for the speed is Eq. 13, corresponding to his Eq. 6, with n = 1. For any n ≠ 1, there is an incompatibility in the dimensions of the two distributions. This is responsible for the seemingly close appearance of the pdf of the subordinated process with the Tsallis distribution. In other words, if Beck’s Eq. 6 is meant to be the speed distribution, it does not reflect the dimensionality of the χ2 pdf for β, (10). Rather Beck finds that the subordinated process is governed by Student’s t-distribution, (15). The first factor tends to unity as n → ∞ and for every fixed u[15]:
so that in the limit as n → ∞
| (21) |
This is the n = 1 Maxwellian of (13) which is the conditional pdf with which Beck started!
What has happened is that the derivation of the Student t-pdf (15) formally resembles subordination but, in reality, has nothing to do with it. Suppose[16] that (n + 1) random variables u and u1, u2,...., un are independent and identically distributed according to the normal distribution with zero mean and standard deviation ![]() The distribution of u is given by (21), while the distribution of the square root of the average of the sum of squares,
The distribution of u is given by (21), while the distribution of the square root of the average of the sum of squares, ![]() is
is
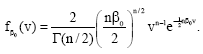 | (22) |
On account of the independence of the random variables u and v, their joint pdf will be given by:
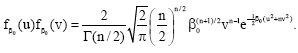 | (23) |
The probability that u/v≤t is the integral of (23) over the region v>0 and u≤tv. Introducing the transformation u = xy and v = y, whose Jacobian is y, gives:
Its derivative yields Student’s t-pdf:
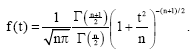 | (24) |
It is simply a coincidence that the χ2 pdf which Beck chose to represent fluctuations in the inverse temperature, (10), has the same form as Maxwell’s density for the speed ![]() Surprisingly, the Student t-distribution (24) is independent of the variance, 1/β0. Although this is important insofar as testing hypotheses of the mean of a population is concerned, because it is independent of the variance, it nevertheless implies that information has been lost (Eq. 28 and 30).
Surprisingly, the Student t-distribution (24) is independent of the variance, 1/β0. Although this is important insofar as testing hypotheses of the mean of a population is concerned, because it is independent of the variance, it nevertheless implies that information has been lost (Eq. 28 and 30).
The reason why Beck has β0 as a parameter in his pdf (15) is that he obtained:
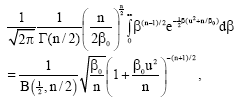 |
using (10) instead of (11). Had he used (11), he would have obtained:
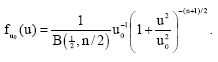 |
The two are the same if equipartition holds:
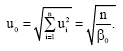 | (25) |
In general, the estimator of the variance, ![]() will be different from the variance β0-1. The estimator is β-1 and usually this temperature will be different from the temperature, β0-1, of the reservoir. In other words, the statistic for the Student distribution,
will be different from the variance β0-1. The estimator is β-1 and usually this temperature will be different from the temperature, β0-1, of the reservoir. In other words, the statistic for the Student distribution, ![]() is not distributed as a normal random variable as it would be had the statistic been given by
is not distributed as a normal random variable as it would be had the statistic been given by ![]() The actual variance may be completely unknown and it suffices to know only the sample variance in order to make statistical predictions. Nevertheless, as the number of degrees of freedom increases, it is expected that the distribution of t will be very similar to that of a standard normal variable; that is, it is a ‘consistent’ estimator. Accordingly, the χi2 in Beck’s Eq. 3, which are distributed as χ2, may be identified with the kinetic energies of the individual particles and the left-hand side should be n/β and not β itself.
The actual variance may be completely unknown and it suffices to know only the sample variance in order to make statistical predictions. Nevertheless, as the number of degrees of freedom increases, it is expected that the distribution of t will be very similar to that of a standard normal variable; that is, it is a ‘consistent’ estimator. Accordingly, the χi2 in Beck’s Eq. 3, which are distributed as χ2, may be identified with the kinetic energies of the individual particles and the left-hand side should be n/β and not β itself.
The whole idea of ‘superstatistics’ is that the exponential pdf[17]:
| (26) |
is actually a conditional pdf and specifying a normalised pdf for what was previously a mere parameter by the χ2 pdf:
| (27) |
leads to a new distribution of E which is precisely the Tsallis pdf. However, (27) is no arbitrarily chosen pdf for the inverse temperature, but rather the directing process which results when the parameter of the original distribution is randomised.
Consider the usual case of a power law for the structure function[7]:
which leads to equipartition because the partition function is Z(β) = β-m . Then the process which is subordinated to the exponential pdf (26) has a pdf:
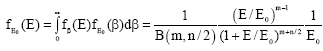 | (28) |
which is still the inverted beta pdf Eq. 14. This is because the Lévy transform:
| (29) |
in (26) produces a randomised inverse temperature which is distributed according to (27) with n = 2m degrees of freedom. Consequently, the inverse beta pdf (28) is the Fisher-Snedecor pdf with equal degrees of freedom, m = n/2, or what is more commonly known as the Pareto distribution. The transformation to a new process by randomising the operational temperature cannot change the number of degrees of freedom of the system.
‘F-superstatistics’[5,17] is not a directing process but, rather, a subordinated process that is obtained from (11) and (13) by averaging the product of these densities over a common value of the kinetic energy, viz.[11] :
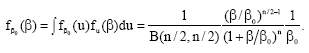 | (30) |
Since it is necessary that both the original and directing processes have the same number of degrees of freedom, (30) is a symmetrical inverse beta distribution, which necessarily has the same number of degrees of freedom. Comparing (30) with (28) it is seen easily that they are interchangeable on the strength of the Lévy transformation (29). Reference to a Tsallis distribution in β space is completely inappropriate.
The symmetry of the inverse beta pdf (30) means that we are dealing with a composite system comprised of two subsystems with the same number of degrees of freedom. The total energy Et = E0 + E, formed from two subsystems with energies E0 and E, is fixed. Thus, the inverse beta pdf (28) is transformed into the beta pdf which may be written as the composition law[13]:
for the structure function.
Thus, it may be concluded that the statement “Of course, other distribution functions f(β) can also be considered which may lead to other generalised statistics”[18] is devoid of meaning when the original process is distributed according to (26). More importantly, as has been concluded elsewhere, “subordination can be considered as the probabilistic origin of power laws in physics”[13].
TOUCHETTE AND BECK’S
‘ASYMPTOTIC SUPERSTATISTICS’
The basic idea contained in Touchette and Beck’s[19] study is to obtain ‘fat’ tail power distributions by a ‘mixing’ of Boltzmann factors. Precisely why such a mixing will produce fat tail power laws is left to the reader’s imagination.
A ‘mixing’ distribution, f(β), is used to obtain a new ‘distribution’, B(E), via a Laplace transform:
| (31) |
where, E is the energy and β its conjugate intensive parameter, as in (ii) of section 2. Both f(β) and B(E) are claimed unimodal but this is both unnecessary and misleading since it is required only that they be monotone[13]. In the article under discussion here, the Laplace integral was evaluated in the high energy, E → ∞, β →0, limit using Laplace’s method. However, when the inverse transform is considered:
| (32) |
along the vertical line ![]() β = b, in the region of existence of B(E), it is surprising to learn that the same method may be applied only in the opposite limit as E → 0, β→ ∞ . This appears all the more disconcerting since no information is lost in a Laplace transformation: A distribution is determined uniquely by its Laplace transform and vice-versa. Both should yield the same expressions in the same asymptotic limit.
β = b, in the region of existence of B(E), it is surprising to learn that the same method may be applied only in the opposite limit as E → 0, β→ ∞ . This appears all the more disconcerting since no information is lost in a Laplace transformation: A distribution is determined uniquely by its Laplace transform and vice-versa. Both should yield the same expressions in the same asymptotic limit.
Any relation giving the asymptotic behaviour of B(E) in terms of f(β) is known as a Tauberian theorem, whereas the inverse relation is termed Abelian[14]. The behaviour of B(E) as E → ∞ completely determines the behaviour of f(β) near the origin and vice-versa. Without loss of generality, power laws may be considered for both f(β) and B(E), one of which must be monotonically increasing and the other monotonically decreasing. For the Laplace transform (31) to exist, it is necessary that the exponent in:
| (33) |
be confined to the semi-open interval [0, ∞). This gives:
| (34) |
which is the tail distribution that Touchette and Beck derive by Laplace’s method in the limit as E → ∞. They are quick to point out that (34) has the same asymptotic form as Tsallis’ q-exponential distributions[18], where, m = (q-1)-1.
However, the Laplace transform (31) defines a generating function, B(E) and not a normalisable probability density. The conjugate distribution is the χ2 distribution[16]:
| (35) |
characterised by the ‘parameter’, E0 and not the probability distribution[19]:
where:
since the integral diverges. Hence, a simple Laplace transform on the ‘density of states’, f(β), will not lead to a power-tail distribution.
However, the χ2-distribution (35) for the inverse temperature may be derived from the χ2-distribution for the energy by Bayes’ theorem of inverse probability[5]. Moreover, it is the distribution of the directing process which transforms the χ2-distribution:
| (36) |
for the energy into a beta distribution of the second kind for the energy. This is accomplished again through sudordination[14], in which the parameter β0 is replaced by the lower limit on the energy distribution[13].
Once again, the Lévy transformation (Eq. 12):
where, the subscripted quantities refer to the heat reservoir, enters the deliberations, since it provides the relation between the two χ2-distributions, (35) and (36). By analogy with Brownian motion, where a distribution of particles may be considered, or, equivalently, a single particle whose motion in time is followed, the conjugate variables of position and time become those of energy and temperature in thermodynamics[13]. The ‘pure’ spatial process, where the initial position replaces the time parameter, is the Cauchy distribution and the Cauchy process is subordinated to the Brownian motion[13]. Analogously, in thermodynamics, the beta density of the second kind is subordinate to the χ2-distribution (36), since[13]:
| (37) |
where, as before, B(.,.) is the beta function. For E0<<E, the beta density (37) transforms into the Pareto density:
The energy E0 is then interpreted as the smallest energy for which the distribution is valid, corresponding to the minimum income in Pareto’s distribution of income above a given value.
Touchette and Beck claim that Laplace’s method will only work on the inverse t ransform (32) in the limit as β → ∞ and E → 0, i.e., the low temperature limit. The distribution they find by using Laplace’s method is:
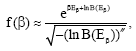 |
where, the prime denotes differentiation with respect to the argument, which is the implicit solution to:
| (38) |
However, βE + lnB(E) has a minimum at Eβ = m/β and not a maximum as contended by the authors. Hence, Laplace’s method will not work regardless of which asymptotic limit is being considered. It is surprising also that the authors find it necessary to work in the opposite asymptotic limit when discussing the inverse transform. As noted ealier, no information is lost upon taking the Laplace transform, or its inverse and so the two should correspond to the same asymptotic limit.
As is well-known, the inverse Laplace transform (32) may be performed by contour integration. There is a pole of order m at the origin and B(E) → 0 as E → ∞. If the pole at the origin is enclosed by a contour Cm, Cauchy’s theorem gives:
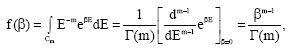 |
which is the density (33) with which we started.
It seems sensible now to enquire into the physical meaning of f(β) and B(E). According to the process of subordination, the primary process is the χ2-distribution (36) for the energy. The directing process is governed by the inverse temperature distribution (35). This is analogous to randomising time in Brownian motion where the Brownian motion process for the increments of a Brownian particle is transformed into a Lévy distribution for the random increments in time.
Equilibrium statistical mechanics teaches that the fundamental quantity is the improper probability distribution, or ‘structure’ function[20]:
| (39) |
representing the density of states in phase space. The conjugate probability distribution is the exponential law
| (40) |
where, the generating function is:
| (41) |
The functions f(β), (33) and B(E), (34), refer to the inverse of the generating function, (41) and the inverse of the structure function, (39), respectively. Hence, they are devoid of any physical content.
Khinchin[20] contends that the conjugate distribution (40) may be approximated by the normal distribution on the strength of the central limit theorem. Setting:
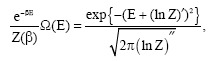 | (42) |
and evaluating it at the mean energy, ![]() in the high temperature limit gives the important result:
in the high temperature limit gives the important result:
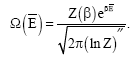 | (43) |
Now, introducing this explicitly into (43) gives[7]:
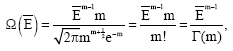 |
which is precisely Stirling’s expression for m!
The reason for this is that the normal law (43) applies in the limit where the number of degrees of freedom of the system has been allowed to increase without limit. Alternatively, if a finite number of degrees of freedom is maintained and the conjugate distribution is identified with the χ2-distribution (36) for the energy, then the expression for the density of states is found to be:
| (44) |
without any approximation. Obviously, if (44) was evaluated at E ![]() , Stirling’s approximation
, Stirling’s approximation ![]() would be obtained once again.
would be obtained once again.
At this point it is appropriate to enquire after the distinction between the χ2-and normal distributions as far as the processes are involved. This is a matter for order statistics. The probability that one of the (n-1) molecules has energy falling in the interval from E1 to E1 + dE1 is (n-1)dE1/E1. There are then (n-2) molecules remaining, (m-1) of which have energies ≤dE1, while (n-m-1) have energies ≥dE1. The probability that (m-1) have energies ≤E1 is (E1/E)m-1, while those having energies>E1 is (1-E1/E)n-m-1. The product of the three factors is proportional to the β density of the first kind:
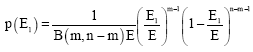 |
The mean energy of the molecules with energies ≤E1 is simply the fraction (m/n) of the total energy. If n is so large that the equipartition result for the total energy, E = n/β, may be used and n → ∞, the β density of the first kind will transform into the χ2-distribution (36). The mean value ![]() = m/β is again given by the equipartition result, which is entirely independent of the asymptotically infinite total number of particles n.
= m/β is again given by the equipartition result, which is entirely independent of the asymptotically infinite total number of particles n.
CONCLUSIONS
Here attention has been drawn to discrepancies appearing in discussions of so-called ‘superstatistics’ which were introduced into the statistical mechanical literature following Tsallis’s study[1]. The Tsallis entropy is a pseudo-additive entropy of degree-q[2] which has been known and used by information scientists for many years. In fact, the basic relation,
| (45) |
which Tsallis[21] used as a definition of a nonextensive thermodynamic system, is not the definition of nonextensivity at all! For q = 1, the solution of the functional equation is S(x) = logx, while for q ≠ 1, the solution is S(x) = (xq-1)/(1-q). The x and y in (45) are sets of probabilities and not extensive thermodynamic variables. The major hurdle in characterising information theoretic entropies is that the set of random quantities is not independent of the set of their probabilities. Equality (45) has no meaning as a definition of a nonextensive entropy unless a prescription is given that relates the set of probabilities to the set of random quantities. Furthermore there is no reason to think that this prescription would be unique or that it will preserve the functional form of (45).
Equation 45 has been shown many years ago by Hardy, Littlewood and Pólya[22] to characterise the generators of homogeneous means which constitute an equivalent class. Two generators are said to be equivalent if there exists a linear relation between them:
| (46) |
where, α and β are constants. If ![]() where λ>0, (32) becomes:
where λ>0, (32) becomes:
and if S(1) = 0, then β(λ) = S(λ). Hence, if λ = y, (46) becomes:
Interchanging x and y and eliminating S(xy) = S(yx) between the two expressions gives:
Introducing this into (34) gives the pseudo-additive relation for the generators of the power means. For reasons given by Rényi[23], it is the negative logarithm of these means which should be identified with information theoretic entropies-and not the generators of these means which, at most, may be considered as pseudo-additive entropies[3].
REFERENCES
- Lavenda, B.H., 2004. On the definition of fluctuating temperature. Open Syst. Inform. Dyn., 11: 139-146.
Direct Link - De Souza, A.M.C. and C. Tsallis, 1997. Student`s t- and r-distributions. A unified derivation from an entropic variational principle. Physica, 236: 52-57.
Direct Link