
Robin Rohit
Department of CSE, Alagappa University, India
LiveDNA: 968.25218
Ramaraj Eswarathevar
Department of CSE, Alagappa University, India
Asian Journal of Scientific Research
Year: 2019 | Volume: 12 | Issue: 3 | Page No.: 340-345







ABSTRACT
Background and Objective: In Mobile Ad hoc Network (MANET), existing buffer management techniques did not consider the coverage and connectivity parameters to select optimum nodes as buffer nodes. The assigned buffer space should reflect the packet drop probability of the nodes. Hence the main objective of this work was to design an optimum buffer node selection and queue management mechanism for nodes in MANET. Materials and Methods: In this study, a Buffer Node Selection for Queue Management using Honey Bee (BFN-HB) algorithm for MANET has been proposed. In this technique, Queue Management Nodes (QMN) were selected based on the coverage and connectivity. These nodes maintain separate queues depending on the priority of traffic. During data transmission, when the packet dropping probability becomes higher than a threshold value, the buffer space of that node was adjusted. On the other hand, if the neighbor density changes than a small bound, then the buffer space of all the neighbor nodes were dynamically updated. Results: The proposed BFN-HB algorithm is simulated in network simulator and the performance is evaluated in terms of the metrics end-to-end delay, packet delivery ratio, packet loss and throughput and simulation results have shown that BFN-HB algorithm has reduced delay and packet loss with increased throughput and packet delivery ratio. Conclusion: It can be concluded that BFN-HB has been considered as the best approach for queue management in MANET.
PDF Abstract XML References Citation
Received: October 24, 2018;
Accepted: December 13, 2018;
Published: June 15, 2019
Copyright: © 2019. This is an open access article distributed under the terms of the creative commons attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
How to cite this article
Robin Rohit and Ramaraj Eswarathevar, 2019. Optimum Buffer Node Selection for Queue Management in MANET Using Honey Bee Algorithm. Asian Journal of Scientific Research, 12: 340-345.
DOI: 10.3923/ajsr.2019.340.345
URL: https://scialert.net/abstract/?doi=ajsr.2019.340.345
DOI: 10.3923/ajsr.2019.340.345
URL: https://scialert.net/abstract/?doi=ajsr.2019.340.345
INTRODUCTION
Multi-hop MANETs have received increasing attention over the last decade. In MANETs, each node acts as a user as well as a router. Wireless link can be built by a node with other nodes inside their signal transmission range. In MANETs, the link failure between nodes can occur more frequently due to their intrinsic nature: free mobility, insufficient power and limited signal transmission range1. Ad Hoc architecture has many benefits, such as self reconfiguration, ease of deployment, among others. It inherited the traditional problems of wireless communications, such as bandwidth optimization, power control and transmission quality enhancement2. Queuing mechanisms have been implemented in MANETs to solve the Quality of Service (QoS) issues. The most commonly used queuing mechanisms were Priority Queuing (PQ) and First in First out (FIFO) queuing2. There were many variations introduced in the research of QoS paradigm about how these queues are managed at processing hops3. A queue is used to store traffic until it can be processed or serialized. Both switch and router interfaces of MANETs have ingress (inbound) queues and egress (outbound) queues. When the queue size reaches beyond its permissible limits, packet drops occurs which drastically bring down the network performance4. The combative technique used to handle queue at a router to link was known as Active Queue Management (AQM) technique5. In WFQ-SPBN6, traditional WFQ technique was applied. Virtual queue mechanisms7,8 have been developed for congestion control and prioritized scheduling. In dynamic buffer management scheme3, the buffer space has been dynamically allocated based on utilized buffer size and the number of neighbors. But it should consider the packet drop probability also. The packet drop probability depends on the buffer size and the neighbor density9. Two algorithms have been proposed10 as an enhancement to the Source Tree Reliable Multicast (STRM) protocol. Algorithm-1 has mitigated buffer overflow in the sender while algorithm-2 has decreased the amount of duplicated packets among the multicast group members. In Hop-aware and Energy-based Buffer management scheme (HEB)11, the buffer space was separately divided for real-time and non real-time packets. The buffer management scheme12 contains aggregated streaming data of various streams of packets with interdependencies. In dynamic buffer management scheme3, a dynamic buffer space was allocated to all neighboring nodes. The buffer space was dynamically adjusted based on the fraction of the allocated node buffer of the neighbors and the difference between the allocated and utilized buffer space.
Different optimization techniques such as Ant Colony Optimization (ACO), Particle Swarm Optimization (PSO)13 and Genetic Algorithm (GA)14 were used to provide optimum solutions. Honey bee algorithm15 was an emerging soft computing technique inspired from the foraging behavior of honey bees. Since there were plenty of works using ACO and PSO algorithms exist, the honey bee algorithm was preferred in this study to handle the buffering problem in MANET. So the main objective of this study was to design an optimum buffer node selection and queue management mechanism for nodes in MANET. To meet this objective, an optimal buffer node selection technique has been proposed for queue management in MANET. In this technique, optimum buffer nodes (OBN) were selected based on coverage and connectivity.
MATERIALS AND METHODS
Buffer node selection using honey bee algorithm: A buffer node selection using honey bee (BFN_HB) algorithm for queue management in MANET has been proposed in this study. In this algorithm, buffer nodes were selected based on the parameters coverage and connectivity by using the honey bee algorithm.
Honey bee algorithm was a multi-objective optimization technique inspired from the foraging behavior of honey bees. In honey bee algorithm, the bees were categorized into three different groups: scout bees, onlooker bees and employed bees. The scout bees explore the new food sources better than the old one. The onlooker bees wait on the dance floor for the waggle dance of the employed bees. The food source is selected based on the type of dance which employed bee performs. The employed bees were the worker bees that perform the nectar collection15.
These nodes maintain separate queues depending on the priority of traffic. Here 3 types of traffic were considered: real-time video traffic, voice traffic and non-real time best effort traffic with priorities 3, 2 and 1, respectively.
In this scheme, nodes were known as food sources. A node (a food source) with more nectar was selected as optimum buffer node. The nectar was calculated based on the parameters packet drop probability, coverage and connectivity.
Preliminaries: Then initial buffer space was allocated for each neighbor based on Eq. 1:
| (1) |
Where:
| ABS | = | Allocated buffer space |
| pr | = | Priority of traffic |
| TBS | = | Total buffer size |
| ND | = | Neighbor density |
The packet drop probability was estimated using Eq. 27:
| (2) |
Where:
| Q | = | Load factor |
| Ctx | = | Transmission capacity (in packets/second) |
| D | = | Propagation delay |
| z | = | Queue size |
The node coverage (NC) was estimated based on the relative node speed and node degree using Eq. 3:
| (3) |
Where:
| Si | = | Relative speed of the node |
| NDi | = | Node degree |
| α and β | = | Constants |
In Eq. 3, Si was estimated based on the distance among the nodes at time t and the NDi was related to the direct wireless link among the nodes at time t.
The connectivity between the nodes was estimated using Eq. 4:
| (4) |
From this equation, it can be observed that the connection value for each node was estimated as the sum of the connectivity intensities between the node and its neighbors.
Buffer node selection algorithm: The amount of nectar in a node Ni can be calculated as:
| (5) |
Food sources were computed (optimized) in such a way that the Euclidian distance of each food location to other food locations should be approximately the same.
The average fitness value of a node was calculated using Eq. 6:
| (6) |
where, wij was the relationship weight of each of the neighbors Nj of node Ni.
Then the optimization process can be stated as maximize Ci.
After the initialization process has been completed, the search procedure of the scout, onlooker and employed bees were repeated to produce a new population of the buffer nodes. The memory of the employed bees which stores buffer nodes (solutions) should be updated depending upon the local or visual information and the results of the tests performed via Eq. 6 (used to calculate the nectar amount) for the quality of the new buffer nodes (novel solutions).
When the amount of available nectar Xi calculated for buffer node was superior as compared to the previous (stored in the memory of the bee), the bee memorizes the new nectar amount and forget the previous (will be replaced). If not, the location of the earlier buffer node was maintained in its memory without any modification. The employed bees share the quantity of nectar of different nodes and their directions with other bees on the dancing floor through various dancing patterns when they return to the hive after completing the search process. When an onlooker bee watches the dance of bees that are dancing on the dance floor, it analyzed the nectar amount by observing the type of dance that employed bees perform. The next buffer node was selected based on their probability associated with the nectar quantity.
The probability Pi of visiting the onlooker bees to the node Ni was calculated as:
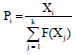 | (7) |
where, k indicate the regions of the network.
The onlooker has found the neighborhood food source or the candidate solutions in the region of j using:
| (8) |
Where:
| aij | = | Size of the patch of neighborhood for jth food position |
| var | = | random uniform variable, which accepts values between [1, 1] |
| Table 1: | Simulation parameters |
 | |
The new solutions were also assessed based on the nectar amount.
Employed bees check the quantity of nectar in candidate positions. The new location was memorized and the existing position stored in her memory was forgot (modify the position array in their memory) subject to the fitness of the candidate’s position. Candidate position was qualitative if the nectar quantity in it is higher than the previous one.
Buffer space adjustment: When a source node wants to transmit a data packet to destination, the packet drop probability (Pdrop) was estimated at its neighbor node using Eq. 2.
If Pdrop is greater than a threshold value Pdth, then ABS of the relevant node has been adjusted. On the other hand, if neighbor density changes than a small bound, ABS of all the neighbor nodes were dynamically updated.
Experimental design: The proposed buffer node selection for queue management using Honey Bee Algorithm (BFN-HB) has been simulated in NS2 and compared with the Fuzzy Active Queue Management (FAQM)9 algorithm. The simulation settings and parameters were summarized in Table 1.
RESULTS
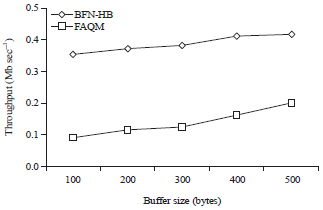
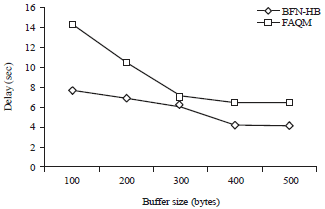
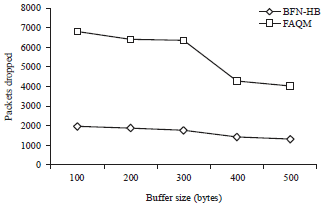
In simulation experiments, the buffer size has been varied as 100, 200, 300, 400 and 500 bytes. The Fig. 1 presented the throughput obtained for both the algorithms. The throughput is estimated by averaging the data received for each flows in terms of Mb/sec. Results in Fig. 2 showed the end-to-end delay measured for both the algorithms. It was estimated by averaging the difference in receiving and sending times of packets. The Fig. 3 demonstrated the packet delivery ratio obtained for both the algorithms. It was estimated as the ratio of successfully received data packets to the total number of packets sent. The data in Fig. 4 illustrated the average packet loss measured for both the algorithms.
It can be seen from Fig. 1, the throughput of Queue Management using Honey Bee Algorithm (BFN-HB) increased from 0.35-0.41 and the throughput of Fuzzy Active Queue Management (FAQM) increased from 0.09-0.19 Mb sec–1.
 | |
| Fig. 1: | Throughput measured for buffer node selection using Honey Bee (BFN-HB) and Fuzzy Active Queue Management (FAQM) algorithms |
 | |
| Fig. 2: | Delay measured for buffer node selection using honey Bee (BFN-HB) and Fuzzy Active Queue Management (FAQM) algorithms |
 | |
| Fig. 3: | Packet delivery ratio measured for Buffer Node Selection using Honey Bee (BFN-HB) and Fuzzy Active Queue Management (FAQM) algorithms |
In Fig. 2, the delay of BFNHB decreased from 7.6- 4.1 and the delay of FAQM decreased from 14.3-6.4 sec.
| Table 2: | Percentage wise improvement of BFN-HB |
 | |
 | |
| Fig. 4: | Packet loss measured for buffer node selection using Honey Bee(BFN-HB) and Fuzzy Active Queue Management (FAQM) algorithms |
In Fig. 3, the packet delivery ratio of BFNHB increased from 0.64- 0.76 and the delivery ratio of FAQM increased from 0.33-0.65. In Fig. 4, the packet loss of BFNHB decreased from 1968-1303 and the packet loss of FAQM decreased from 6826-4057 packets.
As shown in Table 2, BFN-HB achieves performance improvement in terms of all the metrics, when compared to FAQM.
DISCUSSION
As the buffer size increases, since more packets can be stored and transmitted, the packet loss will tend to reduce thereby increasing the throughput and packet delivery ratio. Since BFN-HB considers packet drop probability for buffer space adjustment, it minimizes the packet drops due to queue overflow. Moreover, it minimized the packet losses due to disconnections by considering the coverage and connectivity of nodes. Hence it achieved comparatively higher throughput and delivery ratio.
In FAQM, the packets in the active queues were discarded based on the packet drop probability only. It did not consider the packet losses due to network disconnections. Moreover the priority of traffic was not handled by FAQM. So it suffers from more packet losses and hence attains reduced throughput and delivery ratio, when compared to BFN-HB. In priority packet queuing mechanism2, packet drop probability was not considered. Since centrally communicating node has been designated as the QMN3, it might not cover all the overloaded nodes. Moreover due to frequent mobility of nodes, the QMN might go out of coverage. In PQ based on Type of Service (ToS)4, only the VoIP data traffic has been considered. Moreover, it did not discuss about the mobility and topology changes of MANET. In WFQ-SPBN6, traditional WFQ technique was applied which was not suitable for highly dynamic environments like MANET. The virtual queue mechanisms8,9 have considered only the congestion window for dropping the congested packet ignoring the network conditions. Because of these reasons, the packet loss will be high in these schemes leading to the degraded throughput and packet delivery ratio.
However the proposed BFN-HB methodology has been tested with nodes having constant network size and mobility. Hence the future work focuses on testing the methodology by varying the node speeds and network sizes.
CONCLUSION
In this study, a Buffer Node Selection for Queue Management using Honey Bee Algorithm has been proposed. In this algorithm, queue management nodes are selected based on the coverage and connectivity. These nodes maintain separate queues depending on the priority of traffic. During data transmission, when the PDP becomes higher than a threshold value, the buffer space of that node is adjusted. On the other hand, if the neighbor density changes than a small bound, then the buffer space of all the neighbor nodes are dynamically updated. By simulation results, it has been shown that the BFN-FB minimizes the delay and increases delivery ratio.
SIGNIFICANCE STATEMENT
This study discovered the queue management issues in MANET that can be beneficial for streaming applications in mobile communications. This study will help the researchers to uncover the critical areas of buffer node selection and priority assignment that many researchers were not able to explore. Thus a new theory on honey bee algorithm may be arrived at.
REFERENCES
- Tang, S. and W. Li, 2006. QoS provisioning and queue management in mobile Ad hoc networks. Proceedings of the Wireless Communications and Networking Conference, Las Vegas, NV. USA., April 3-6, 2006, IEEE. USA., pp: 400-405.
CrossRefDirect Link - Momanyi, E.O., V.K. Oduol and S. Musyoki, 2015. QoS performance comparison of FIFO and priority packet queuing mechanisms in MANETs. J. Sustainable Res. Eng., 1: 39-44.
Direct Link - Aamir, M. and M.A. Zaidi, 2013. A buffer management scheme for packet queues in MANET. Tsinghua Sci. Technol., 18: 543-553.
CrossRefDirect Link - Momanyi, E.O., V.K. Oduol and S. Musyoki, 2014. First in first out (FIFO) and priority packet scheduling based on type of service (TOS). J. Inform. Eng. Applic., 4: 22-36.
Direct Link - Bedi, S., G.S. Aujla and S. Vashist, 2015. Active queue management in MANETs-A primer on network performance optimization. Int. J. Emerg. Trends Technol. Comput. Sci., 4: 181-188.
Direct Link - Kaur, G. and T.P. Singh, 2015. A weighted fair queue based SBPN (WFQ-SBPN) algorithm to improve Qos for multimedia application in mobile Ad hoc networks. Int. J. Comput. Applic., 112: 13-17.
Direct Link - De Coppi, N., J. Ning, G. Papageorgiou, M. Zorzi, S.V. Krishnamurthy and T. La Porta, 2012. Network coding aware queue management in multi-rate wireless networks. Proceedings of the 21st International Conference on Computer Communications and Networks (ICCCN), Munich, Germany, July 30-August 2, 2012, IEEE. USA., pp: 1-7.
CrossRefDirect Link - Ambika, I., V.P. Sadasivam and P. Eswaran, 2014. An effective queuing architecture for elastic and inelastic traffic with different dropping precedence in MANET. EURASIP J. Wireless Commun. Network., Vol. 2014.
CrossRefDirect Link - Natsheh, E., A.B. Jantan, S. Khatun and S. Shamala, 2007. Fuzzy active queue management for congestion control in wireless Ad-hoc. Int. Arab J. Inform. Technol., 4: 50-59.
Direct Link - Alahdal, T., R. Alsaqour, M. Abdelhaq, R.A. Saeed and O. Alsukour, 2013. Reliable buffering management algorithm support for multicast protocol in mobile ad-hoc networks. J. Commun., 8: 136-150.
Direct Link - Lai, W.K., M.L. Weng and Y.H. Lin, 2014. Improving MANET performance by a hop‐aware and energy‐based buffer management scheme. Wireless Commun. Mobile Comput., 14: 704-716.
CrossRefDirect Link - Scalosub, G., P. Marbach and J. Liebeherr, 2013. Buffer management for aggregated streaming data with packet dependencies. IEEE. Trans. Parallel Distrib. Syst., 24: 439-449.
CrossRefDirect Link - El-Abd, M., 2011. Opposition-based artificial bee colony algorithm. Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, Dublin, Ireland, July 12-16, 2011, ACM., New York, USA., pp: 109-116.
CrossRefDirect Link - Islam, O., S. Hussain and H. Zhang, 2007. Genetic algorithm for data aggregation trees in wireless sensor networks. Proceedings of the 3rd IET International Conference on Intelligent Environments (IE07), September 24-25, 2007, Ulm, Germany, pp: 312-316.
CrossRefDirect Link - Ahmad, M., A.A. Ikram, R. Lela, I. Wahid and R. Ulla, 2017. Honey bee algorithm-based efficient cluster formation and optimization scheme in mobile ad hoc networks. Int. J. Distrib. Sensor Networks, Vol. 13, No. 6.
CrossRefDirect Link