
S.K. Rajesh Kanna
Rajalakshmi Institute of Technology, Chennai, India
A.D. Jaisree
Anna University, Chennai, India
Asian Journal of Scientific Research
Year: 2015 | Volume: 8 | Issue: 2 | Page No.: 149-156







ABSTRACT
The green revolution motivated many researchers to carry out forecasting study in the agricultural cropping systems to yield maximum profitability. The profitability can be improved by optimizing unpredictable variables, involved in the cropping systems. Thus a need arises to forecast the unpredictable variables. In this study, the unpredictable variables have been successfully forecasted for cropping productivity using Ant Colony Algorithm. Rainfall, temperature and irrigation are the major variables considered for maize cropping systems in this research. The details of the rainfall, temperature and irrigation have been collected for eight years and twelve months and given as input to the Minitab software to generate the mathematical equation. This mathematical equation has been used as the objective function equation for ant colony algorithm. Thus the ant colony algorithm can generate the best optimal yielding period for maize crop cultivation and also it can be used to forecast the optimal combination of variables that can yield best productivity. This model has helped farmers to make efficient resource allocation decisions with the aim of forecasting productivity and profitability of maize cropping systems.
PDF Abstract XML References Citation
Received: April 02, 2014;
Accepted: January 06, 2015;
Published: April 03, 2015
How to cite this article
S.K. Rajesh Kanna and A.D. Jaisree, 2015. Optimizing the Yield of Maize Cropping Systems Using Ant Colony Algorithm. Asian Journal of Scientific Research, 8: 149-156.
DOI: 10.3923/ajsr.2015.149.156
URL: https://scialert.net/abstract/?doi=ajsr.2015.149.156
DOI: 10.3923/ajsr.2015.149.156
URL: https://scialert.net/abstract/?doi=ajsr.2015.149.156
INTRODUCTION
Cropping systems is an assemblage of components united by some form of interdependence and operates within a prescribed boundary to achieve a profitable productivity in the field of agriculture. Different cropping systems have adopted different strategies to maximize net profitability, productivity, income, stability, diversity, flexibility and time-dispersion. To achieve these benefits, the parameters that have been related to the cropping systems such as irrigation, rainfall, climatic conditions, temperature, fertility of land, application of fertilizers, monsoon behaviour, marketing facilities, prices, availability of labourers, etc have to be controlled. In general, the controls can also be done only through experimentation and on-farm trials. These trial methodologies might not be suitable for all conditions, as the output depends on parameters like experience of the examiner, territory, type of crop, type of land, type of irrigation, etc. Therefore, these methodologies cannot be adopted universally, because they may have having many shortcomings.
In recent years, it has been found that mathematical relations have to be formed using mathematical models to control these parameters. In many applications, researchers proved that the mathematical models can provide optimal results and can be the suitable alternative to trial and experimentations. In developing countries like India, these models have not been much used on cropping systems as a tool to predict and forecast the profitability in the cropping systems.
Mathematical models can be used as decision making tools only when all the required data are given in input. In view of above, for the problems with non-linear relations, may not be possible to provide all the required data such as rainfall, irrigation, temperature, etc., to the mathematical models. In this scenario, mathematical models are failing in producing the desired results. These issues have been addressed by many researchers by considering different non-linear problems and found that the evolutionary algorithms can be used to produce optimal results for the non-linear problems with the unpredictable input parameters. In this study, Ant Colony Algorithm has been used to predict long-term productive and environmental effects of different cropping systems.
In this study, the data related to rainfall, temperature and irrigation facility have been collected from thirty farmers for eight years (2005-2013) in the town Karur, southern region of Tamilnadu, India. These data have been given as input to the developed Ant Colony Algorithm module. The module had been developed to identify the best period for the maize crop cultivation and the best parameters required for better yields. Thus the obtained result will help the farmers to cultivate the maize with maximum profit.
Jehle and Reny (1998) explained that the main objective of the cropping systems is to maximize the output, so as to reap more profits. Such behaviour can be modelled using, profit function approaches, production function approaches, cost function approaches, mathematical optimization and dynamic programming. Varian (1992) used the Hotteling’s lemma, the derivative of the profit function with respect to input price, demand factor and output price Stockle et al. (2003) noted that simulation models can underestimate the yield of maize by up to 27%, without necessarily undermining reasonability of estimates obtained. Jha et al. (2004) considered the climate changes on the river basin and discussed the impacts of climatic changes on crops. Di Luzio et al. (2008) developed a temperature dataset for his analysis. Zhang et al. (2009) developed an approach to solve the uncertainties using genetic algorithm and Bayesian model. They proved that the genetic algorithm produces comparable results. Cantelaube and Terres (2005) developed a model to predict the changes in the seasons and proved that the seasonal forecasting will yield more profit for crops. Ines and Hansen (2006), studied the effect and impact of rainfall and level of rainfall for crop yield, using simulation models. Alva et al. (2004) developed a model for potato crop and predicated the optimal parameters that yields maximum in potato cultivation. Dillon (1992) and Dillon and Hardaker (1993) developed a management strategy for the small scale farmers to yield maximum profit and analysed the various factors which affected the profits. Giardini et al. (1998) developed a mathematical model to simulate two Cropping Systems. The models used for the profit maximization were EPIC and CropSyst. Grabisch (2003) introduced a model based on the probability approach for crop cultivation. Fleisher (1990) discussed the various factors and the parameters, which influenced agriculture. Jehle and Reny (1998) developed an economic theory for agriculture management and resource management. Kelton et al. (2003) simulated a model for agriculture management. Kothari (1999) developed a model for simulating profit using quantitative approach for agriculture. Lordanova (2007) introduced the concept of Monte Carlo model for agriculture profitability. Staggenborg and Vanderlip (2005) developed a simulation model and proved that the simulation models can be best suited for predicting profits for cropping systems.
From the available literature it is clear that the researchers are using different parameters to produce better yields in crops. Therefore, the attempt in this study is to use, rainfall, temperature and irrigation for crop yield maximization.
MATERIALS AND METHODS
In the most of the countries, maize farmers are commercial and therefore driven by the profit motive. Therefore, a necessity arises for an analytical model that leads to more profit.
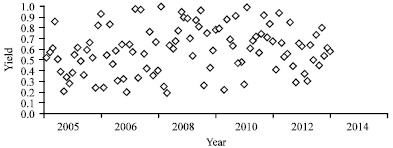 | |
| Fig. 1: | Minitab Scatter data plot |
Some of the commonly used tools used for profit maximization are mathematical models, dynamic programming, simulation analysis, evolutionary methods, intelligent methods, etc. Most of these models cannot predict input variables to achieve optimal output and deficient in their ability to capture variables in the dynamically changing environments.
So, in this study, Ant Colony Algorithm has been used to forecast and optimize the maize crop cultivation. The data collected from the maize farmers have been given as input to the Minitab software. This software generated a non-linear mathematical equation. The scatter data obtained from the software are given in Fig. 1.
This mathematical equation generated through the Minitab software was used as the objective function for the Ant Colony Algorithm module. The concept of Ant Colony Algorithm was used to identify the shortest route. The optimal values from a large search space have been widely applied to optimize the non-linear functions bounded with constraints. The various stages of the Ant Colony Algorithm module are explained in the following sections.
Ant colony algorithm: Ant Colony Algorithm (ACO) uses the behaviour of ants for selecting the nearest path to achieve the target food by applying a stochastic decision policy. This has been used in this research to optimize the maize cropping systems. A comprehensive review on ant algorithms can be found in Dorigo and Blum (2005) study and the various stages of ACO are as follows.
ACO network generation: The first stage is the generation of finite-sized virtual colony of artificial ants. These virtual ants should be allowed to search an optimal solution in the solution region using pheromone updating rule. The solution region should consist of all possible values of rainfall, irrigation and the temperature of the region considered for the research along with the time period. The range of values and the interval between the variables will vary from application to application. In this research, the variable values have been selected based on the feasibility analysis. In the ACO network, first column of nodes are allotted for the generated artificial ants, i.e., in single iteration, one hundred ants are allowed to pass through the input node. Second column having 90 nodes of rainfall values normalized between zero and one in the interval of 0.001 cm. Third column of the ACO network has 90 nodes with temperature values normalized between zero and one in the interval of 1°C. Fourth column of the ACO network has two nodes allotted for irrigation facilities, i.e., zero and one for negligible irrigation and well irrigation facilities, respectively. The last column is the target node for the objective function which is used to calculate the fitness value.
The formulated ant colony network is shown in Fig. 2. Each node in the network should be linked with other nodes in the adjacent columns of the network.
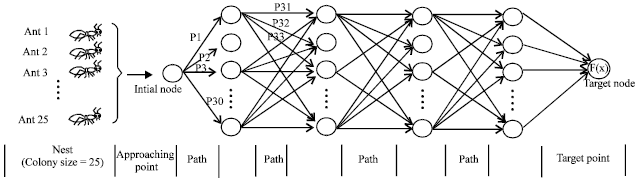 | |
| Fig. 2: | ACO Network |
The link value is called as the pheromone value, which is proportional to the number of ants travelled in the path. The number of ants in the initial layer is determined based on the desired accuracy and as the number of ants increases with proportional increases in computational time along with the better solution.
ACO network inilization: The number of parameters to optimize for the problem will determine the number of nodes and the number of links in the network. After the network formation, their nodes and link values were initialized properly by conducting sensitivity analysis. The initial link or pheromone values are selected as 0.01, to prevent from premature convergence and stagnation in a particular path. As the input parameters are having different units, these parameters are normalized in the range of zero to one. Once the node and link values are set, then artificially generated ants are allowed to search in the network. The ants path are controlled by pheromone updating rule.
Pheromone updating rule: With increased number of ant passes, the pheromone value of the path proportionally increases. Practically, the ant will select the shortest path for its travel the path having more pheromone value, comparatively. When the selected parameters violated the constraints or the selected system, it leads less profit. When the pheromone value of the path gets decreased, it indicates that the other ants do not to proceed in that unfeasible path. Furthermore, this pheromone evaporates over time, thereby avoiding the global stagnation. In this study, the ants are divided into five sub-colonies of equal size (five) and each colony uses different heuristic information to guide their search. Thus the search space increases and also the stagnation condition avoided. Figure 3 presents a decision-making process of ants choosing their trips.
From Fig. 3, there are two paths for the ants, namely ‘path A’ and ‘path B’ to reach the target point. Former is the shortest path and the latter is the longest. When ants meet at their decision-making point, some ants might choose path A and some others might choose path B, randomly. Assuming the ants are crawling at the same speed, those ants choosing path A (shorter) arrive at target point B quicker than those choosing side path B (longer). The ants who choose by chance, the short path are the first to reach the nest. Therefore the short path receives more pheromone than the longer one. Thus this process increases the probability for further ants to select the short path (path A) than the longer path (path B).
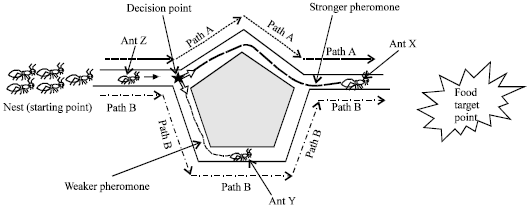 | |
| Fig. 3: | A decision-making process of ants choosing their trips |
In ACO, the pheromone value of the path/link has to be updated based on the number of ant passage, i.e., based on the objective function value and the pheromone is calculated using the Eq. 1:
τijk (t+1) = Δτijk + (1-ρ) τijk (t) | (1) |
whereas, ‘ρ’ denotes the evaporation rate of the pheromone and is set as 0.01 in this study based on the sensitivity analysis result. ‘τ’ and ‘t’ represent the pheromone value of the path and trails, respectively. The Δτ represents the proportional change in the gear parameters selected in the ‘t’ and ‘t+1’ trial. ‘i', ‘j’ and ‘k’ represent the rainfall, temperature and irrigation, respectively. Thus the pheromone values of the link connecting the nodes have been updated to new value. These values only help the forthcoming ants to take decision using ‘ant moving rule’.
Ants moving rule: ‘Ant moving rule’ help the ants to travel from the nest to the target point in the shortest route. The two conditions of ant moving rule are as follows:
| • | For initial iteration, ants can select any of the random paths |
| • | For remaining iterations, the probability of the kth ant choosing the path is given by Eq. 2: |
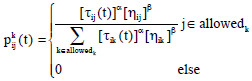 | (2) |
where, ‘α’ and ‘β’ are important parameters, which determine the relative influence of the trail pheromone and the heuristic information. Based on the number of ant passage, the pheromone has to be updated using updating rules.
Global updating rule: In ACO, to avoid the local stagnation, the best path selected by the ant has to be retained for further refined search. Therefore, the global pheromone updating rule is given by Eq. 3. These updating have to be done after a complete iteration:
| (3) |
where, τmax and τmin are, respectively the upper and lower bounds imposed on the pheromone and Δbest belongs to the best tour, which yields better surface finish.
Objective function: The objective of this study is to identify the optimal crop that will provide maximum profit by satisfying the constraints. After applying ACO operators, the best value path should be stored separately in the database. Such iterations are continued till the termination criterion achieved.
Stopping rule: There are many termination conditions for ants to stop their travelling, in this research termination conditions are set as follows:
| • | Maximum number of iteration has been set to 200 |
| • | If continuous 5 iterations produce same result |
Finally, all the best values are used to construct the global ACO network and same procedure is repeated to identify the global best value. ACO uses the random values for identifying the optimal parameters for gear design and based on these parameters, only the basic dimensions are calculated. So the obtained results need to be validated for the feasibility. This is achieved in this work by comparing with the data collected from the farmers and was found that the ACO values are in line with the real time data.
Experimental implementation: For this research, the study area was Karur, which is located in the Namakkal District, Tamilnadu, southern region of India. The data, which directly affect the cropping systems are called the primary data such as annual rainfall, irrigation and temperature for the district. The data, which have indirect impact on the cropping systems are called secondary data such as irrigation facilities, yielding season, market demand, water resources, fertilizers, distribution centres, etc. Lists of questionnaires were prepared, pre-tested, refined before interviews were held for the selected maize farmers. A survey of 30 maize farmers was done. Larger deviations in the survey have been removed to reduce the errors. Finally, 22 maize farmers’ data were found to be similar. Average of the 22 maize farmers data have been taken for the analysis.
In the developed ACO model, inputs (X1, X2......Xn) used were the rainfall, irrigation and temperature. The objective function can be the minimization or maximization function. The objective is to improve the yield, the maximization objective function had been used. The model was then run to produce results (Yi) in the form of maximum yield and in-turn maximum profit. The ACO steps were re-run for 200 times to achieve high degree of accuracy.
RESULTS
Results of simulated yield showed that the highest yield of maize averaging at 58 bags/h and the lowest yield with only 20 bags/h which are more or less in-line with actual yields reported in the zones considered in the study. The average district simulated yield was estimated at 34 bags/h, which is also consistent with the actual district average. Comparison between actual and simulated maize yields revealed that simulated values are in line with the actual values and therefore they can be used for planning and decision making.
Thus this model helps the farmers to predict the suitable period for maize cultivation, which can yield profitability. The model also forecast the parameters in the future, so the cultivation decisions can be taken by the farmers. The model also suggest the farmers, how to control the parameters along with the seeding period. It also identifies the optimal set of parameters, which gives maximum yield, based on the past history. With this model, the farmers can take the decision to maximize their profit. The sample output module is given in the Fig. 4.
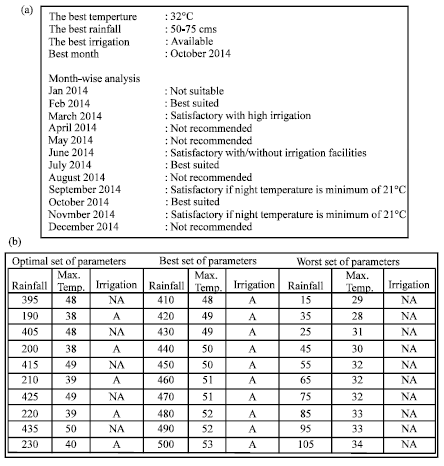 | |
| Fig. 4(a-b): | Genetic output |
DISCUSSION
In this research, non-linear variables such as rainfall, temperature and irrigation have been successfully forecasted for cropping productivity using Ant Colony Algorithm. As the results are tested with the test data set and found satisfactory, the module can be used for the agricultural forecasting to help farmers to make efficient resource allocation decisions. Most of the researchers are used quantitative approach, Monte Carlo model, genetic algorithm dynamic programming, heuristic and hybrid methods (Lordanova, 2007; Zhang et al., 2009) for forecasting but this study used ACO as it is the generalized model for most of the cropping system. Some of the researchers developed the model for the seasonal forecasting (Cantelaube and Terres, 2005) but the developed model can forecast the entire year. As the developed model considers the major influencing parameters, it can be at par.
CONCLUSION
The forecasted results obtained from the developed ACO module for maize yield have been in-line with the actual data. Thus the developed module is considered having been validated. The developed module is efficient and consistent forecasts of productivity and profitability in cropping systems. It will help the farmers to take wise decision in cropping, to achieve maximum profitability. It is also recommended that the various crops have to be considered to improve farmers’ access to information on alternative crops and their risks, uncertainties associated with cropping systems. Further research is also required to test the models in different locations, soil types, management styles and scales of production.
REFERENCES
- Giardini, L., A. Berti and F. Morari, 1998. Simulation of two cropping systems with EPIC and CropSyst models. Ital. J. Agron., 1: 29-38.
Direct Link - Staggenborg, S.A. and R.L. Vanderlip, 2005. Crop simulation models can be used as dryland cropping systems research tools. Agron. J., 97: 378-384.
Direct Link - Stockle, C.O., M. Donatelli and R. Nelson, 2003. CropSyst, a cropping systems simulation model. Eur. J. Agron., 18: 289-307.
CrossRef - Jha, M., Z. Pan, E.S. Takle and R. Gu, 2004. Impacts of climate change on streamflow in the upper Mississippi river Basin: A regional climate model perspective. J. Geophys. Res.: Atmos., Vol. 19.
CrossRef - Di Luzio, M., G.L. Johnson, C. Daly, J.K. Eischeid and J.G. Arnold, 2008. Constructing retrospective gridded daily precipitation and temperature datasets for the conterminous United States. J. Applied Meteorol. Climatol., 47: 475-497.
Direct Link - Zhang, X., R. Srinivasan and D. Bosch, 2009. Calibration and uncertainty analysis of the SWAT model using genetic algorithms and Bayesian model averaging. J. Hydrol., 374: 307-317.
CrossRef - Cantelaube, P. and J.M. Terres, 2005. Seasonal weather forecasts for crop yield modelling in Europe. Tellus A, 57: 476-487.
CrossRef - Ines, A.V. and J.W. Hansen, 2006. Bias correction of daily GCM rainfall for crop simulation studies. Agric. Forest Meteorol., 138: 44-53.
CrossRef - Dorigo, M. and C. Blum, 2005. Ant colony optimization theory: A survey. Theor. Comput. Sci., 344: 243-278.
CrossRefDirect Link