
Moawad El-Fallah Abd El-Sallam
Department of Statistics and Mathematics and Insurance, Faculty of Commerce, Zagazig University, Egypt
Asian Journal of Mathematics & Statistics
Year: 2013 | Volume: 6 | Issue: 2 | Page No.: 57-66







ABSTRACT
A common problem in autoregressive regression models is outliers, which produces undesirable effects on the least squares estimators. Many regression estimation techniques have been suggested to deal with this problem. The majority of such techniques are developed from the classical least squares. Some other robust approaches have been investigated in the regression case both on theoretical and empirical grounds. However, the behavior of these alternative methods has not received more attention in the context of time series. In this study, we present a comparative simulation study for three robust alternatives to the least squares estimator under innovation and additives outliers. The empirical study indicated that, the Reweighted Least Squares estimator (RLS) seems to be very reasonable because of having smaller "total" root normalized absolute bias and "total" root normalized variance. The RLS estimator was recommended as worthy robust alternative to the least squares estimator in the case of autoregressive models with the two kinds of outliers schemes.
PDF Abstract XML References Citation
Received: April 15, 2013;
Accepted: June 12, 2013;
Published: July 18, 2013
How to cite this article
Moawad El-Fallah Abd El-Sallam, 2013. Methods of Estimation for Autoregressive Models with Outliers. Asian Journal of Mathematics & Statistics, 6: 57-66.
DOI: 10.3923/ajms.2013.57.66
URL: https://scialert.net/abstract/?doi=ajms.2013.57.66
DOI: 10.3923/ajms.2013.57.66
URL: https://scialert.net/abstract/?doi=ajms.2013.57.66
INTRODUCTION
When estimating the parameters of an autoregressive (AR) model, a desirable quality of the underlying algorithm is to provide protection against gross errors occurring during the collection or recording of the data. Two distinct kinds of outliers-schemes are considered in regression literature; namely the innovation outliers and the additive outliers. In the Innovation Outliers (IO) scheme, the AR process is perfectly observed and gross errors are incorporated in the error distribution which is assumed to be non-normal. While, when the Additive Outliers (AO) scheme is preferable, the errors are normally distributed. However, the observations contain an additive effect not related to the AR process. In both outlier configurations, a heavy-tailed distribution, frequently assumed to have infinite variance, is involved. Although under the IO-model, the Least Squares (LS) estimator is known to be consistent (Yohai and Maronna, 1977), its Mean Squared Error (MSE) performance in the presence of outliers has been questioned. As a result, robust GM-estimators are developed by Denby and Martin (1979) and Simpson et al. (1992). In addition, M-estimates in the case of innovations with finite variance are proposed and studied with its asymptotic properties by Campbell (1982). Other alternative robust approaches such as the Functional Least Squares (FLS) estimator (Chambers and Heathcote, 1981), the Least Median of Squares (LMS) (Rousseeuw, 1984) and the Reweighted Least Squares (RLS) of Rousseeuw and Leroy (1987) are considered in regression literature. Also, finite-sample properties for most estimators cited above are reported in regression to the presence of heavy tails error distributions. However, similar results for these robust estimators in the context of time series are very limited. Hence, a finite-sample comparison of the performance of some robust estimators in time series is of interest.
In this study, we present a comparative simulation study for the LMS and RLS in the case of AR-models with outliers and in order to assess their performance, diverse sampling situations are considered. In addition, results corresponding to the Trimmed Least Squares (TLS) estimator of Ruppert and Carroll (1980) and the LS-estimator are also reported.
ROBUST ESTIMATORS FOR AR-MODELS WITH OUTLIERS
Consider the autoregressive model AR (P) of order P:
| (1) |
where, α (α1, α2,. .., αp)΄ is a parameter vector and the errors et are independent and identically distributed random variables.
Assumed that the stationary condition:
| (2) |
for every complex w, with |w|≤1 holds.
The three types of simulated noise used on the observed process Zt are described as follows:
| • | No. outliers: The observed process is Zt = yt and the errors et follows the standard normal N (0, 1) distribution |
| • | IO-scheme: The AR-process is again perfectly observed. However, the errors now follow a heavy-tailed distribution |
| • | AO-scheme: The observed process is Zt = yt+ut where yt as in the no-outliners case and independent of ut and the additive effects ut are independent and identically distributed with: |
| (3) |
where, 0<ε<1 is the proportion of contamination, F0 denotes a distribution which is generated at zero and the additive-effect distribution, denoted the additive effect distribution denoted by D is heavy-tailed.
The aim in this study, is to obtain the estimate ![]() of the parameter vector α∈Rp based on the data Zt (t = 1,. .., T) and the corresponding AR-residuals are:
of the parameter vector α∈Rp based on the data Zt (t = 1,. .., T) and the corresponding AR-residuals are:
The robust estimators included in the study are:
| • | The LMS which minimizes the criterion: |
| (4) |
where "med" denotes the median.
| • | The RLS with corresponding objective function: |
| (5) |
where the final weights:
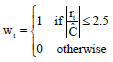 | (6) |
are computed from the LMS-residuals rt and their final scale estimate is:
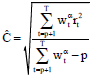 | (7) |
For the definition of the initial weights ![]() , refer to Rousseeuw and Leroy (1987).
, refer to Rousseeuw and Leroy (1987).
It is of interest in regression case to note that, despite the fact that both estimators share the same (slow) rate of convergence to their asymptotic distribution, the RLS- estimator is far more efficient than the LMS in samples of size as large as T = 200 (Lucas, 1997). The robustness properties of the LMS and the RLS estimator in the context of regression can be found by Rousseeuw and Leroy (1987). The same authors provide an indication on the robustness of these estimators in the context of time series by employing the LMS and RLS methods in order to fit AR (1) and AR (2) models. Lucas (1997) showed that, the influence function of the LMS-estimator under the AO- scheme is bounded, but that the corresponding breakdown point may fall below on half and confirmed its dependence on the order of the AR-model.
| • | The q% TLS-estimator with corresponding objective function: |
| (8) |
where, ![]() denotes the ordered squared LS-residuals and the value of h must be determined based on trimming the data values. For example, the 20% trimmed LTS estimator is defined to minimize the function
denotes the ordered squared LS-residuals and the value of h must be determined based on trimming the data values. For example, the 20% trimmed LTS estimator is defined to minimize the function ![]() . Chen (2002) defined h in the range:
. Chen (2002) defined h in the range:
and recommended that the breakdown value for the TLS-estimator is T-h/T, when h = [(3T+P+1)/4]. The calculation of TLS estimator is based on a preliminary LS-fit. Then the data yielding the 100q% largest squared residuals are removed. Thus the TLS-estimator is defined to be the LS- estimator which corresponds to the reduced data set. In the simulation study, we use q = 0.20, whereas the ordinary LS-estimator corresponds to the limiting case q = 0.
Monte carlo simulation: The model and the sampling situations included in simulation study are chosen so as to ensure a feasible comparison of the estimators. Specifically, we have incorporated models of different orders and a wide range of shapes for the IO and AO simulated noise. The random number generation is implemented using the IMSL subroutines computer package.
More details are provided as follows:
| • | Model and parameter choices: The AR-model (1) with p = 2, 3 and αj (-1)j+1 0.8j, j = 1, 2, αj (-1)j+1 0.6j, j = 1, 2, 3, are, respectively utilized |
| • | Simulated distributions: The specific shapes of simulated noise under the IO-scheme correspond to the following innovation-distribution: |
| • | The symmetric stable distribution with shape parameter, a, denoted by S (a). The values of, a, are limited to the interval [0, 2]. The smaller the value of a, the thicker the tails of the distribution. For a = 1, the Cauchy distribution results, whereas, the normal (a = 2) is the only member of the family with finite variance. In any other case, S (a) has finite moments of order only less than a |
| • | The λ-contaminated normal distribution-CN (λ, μ, σ)-where: |
| (9) |
with 0<λ<1 and -∞<μ<+∞, σ2>1. This is a standard model for thick-tailed distributions possessing a N (0, 1). The distribution is symmetric for all λ and σ when μ = 0 but asymmetric otherwise.
| • | The Student’s -tv distribution with v degrees of freedom |
The three families of distributions considered above have the advantage of containing the standard normal distribution as a limiting case (a→2, λ→0, v→). This enables to study the behavior of the estimators as we depart from the N (0,1) model and approach alternative (heavier-tailed) innovation distributions. When simulating the AO-scheme, the distribution D in Eq. 3 is taken to belong to any of the three categories mentioned above (in the case of CN (λ, μ, σ), λ = 1 is used).
Also, the AR-values yt are adjusted to have variance equal to one. In this case, the necessary tuning constants are determined by Hamilton (1994) and correspond to the asymptotic variance of the AR-values, which for p = 3 is given by:
| (10) |
Where:
 |
Also, if we set α1 = 0, (α2 = α3 = 0) in (10), the corresponding variance for p = 0 (p = 1) results.
| • | Random number generation: The subroutine DRNSTA is used for stable random numbers whereas, when N (0, 1) variates the subroutine DRNNOR is called. In the CN (λ, μ, σ) case, the standard normal variates are transformed to σ with probability λ simulated by the subroutine DRNUN which produces random numbers in (0, 1). The same subroutine is used to simulate the proportion ε in Eq. 3. For tv sampling situations, we have utilized the normal/chi-squared method, with chi-squared generated by calling DRNGAM-as a special case of the gamma distribution |
In order to reduce dependence of the results on initial process values, a block of 100 variates is generated according to Eq. 1 and the last p are used as starting values for calculating the observations involved in the estimation process.
RESULTS OF COMPARISONS
The results presented in this section correspond to 1000 replications. With each replication, the methods are applied to 100 standardized observations Zt|med|Zt|.For selected cases, we have generated samples (up to 2000) and our conclusions is that the discussion reported below would not be changed if a higher number of replications was used. In the left entries of Table (1-3) the "total" root normalized absolute bias is reported, whereas in the right entries, the "total" root normalized variance is reported, respectively defined by:
Where:
and:
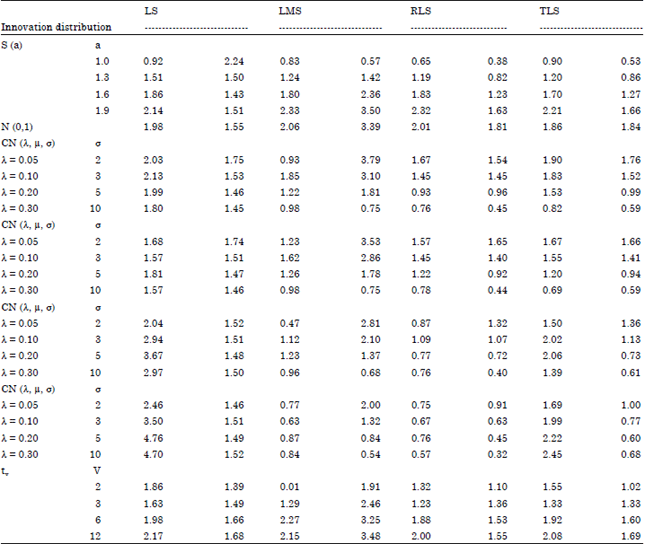
| Table 1: | IO-Scheme: Total root normalized absolute bias (left entry) and total root normalized variance (right entry) of AR (2)-estimators for standard normal, symmetric stable distributions with shape a, λ-contaminated normal distributions with mean μ = 0, 2, 5, 10 and standard deviation σ and student's tv distribution with v degrees of freedom |
 | |
Where:
with ![]() mj denoting the estimate of
mj denoting the estimate of ![]() j (j = 1, 2,…, p) in the mth replication, m = 1, 2,. .., 1000. The "total" root normalized mean-squared error is defined by:
j (j = 1, 2,…, p) in the mth replication, m = 1, 2,. .., 1000. The "total" root normalized mean-squared error is defined by:
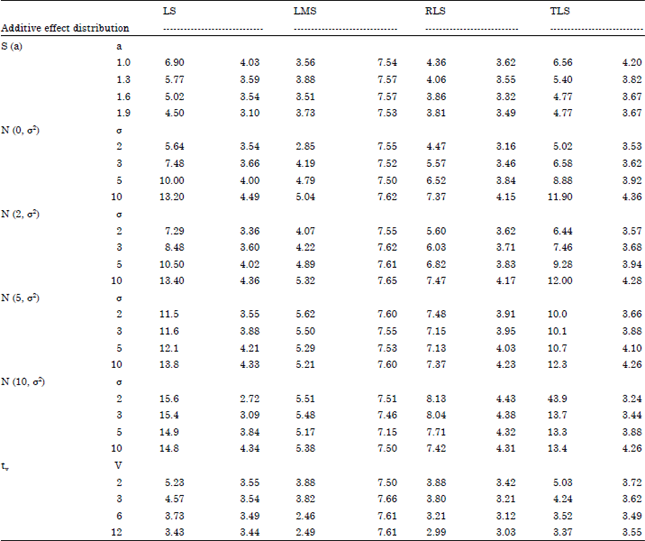
| Table 2: | AO-Scheme: Total root normalized absolute bias (left entry) and total root normalized variance (right entry) of AR (3)-estimators with proportion of contamination ε = 0.01 symmetric stable distributions with shape a, normal distributions with mean μ = 0, 2, 5, 10 and standard deviation σ and student’s tv distribution with v degrees of freedom |
 | |
Where:
The following results based on the simulation results.
IO-Scheme (Table 1): The RLS estimator has (overall) the smallest bias, whereas, the LS is the least reliable method under this criterion, particularly in the presence of considerable skewness (when a = 1.9 or near to 2). In such skewed situations, the LMS-estimator should be preferred but under symmetric (or nearly symmetric) errors, the LMS and TLS-estimators are comparable with respect to bias. Also, within the family of symmetric-stable error-distributions, the bias of the estimators decreases, as the tail-length of the underlying distribution increases. This phenomenon is in agreement with theoretical results-pertaining to the LS and M-estimators- which indicate consistency rates related to Campbell (1982).
| Table 3: | AO-Scheme: Total root normalized absolute bias (left entry) and total root normalized variance (right entry) of AR (3)-estimators with proportion of contamination ε = 0.05 for symmetric stable distributions with shape a, normal distributions with mean μ = 0, 2, 5, 10 and standard deviation σ and student's tv distribution with v degrees of freedom |
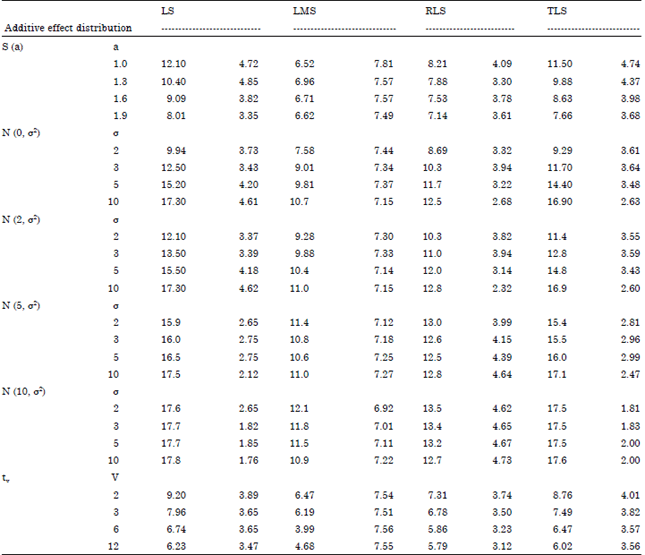 | |
Turning to variability we observe that the RLS, also, is the most preferable method, whereas, the LS and the LMS are less efficient. However, the last estimator should be used instead of the LS when asymmetric heavy-tailed innovations are expected. With the exception of the LS-method, the estimated variance is a decreasing function of the tail length of the innovation distribution. Thus, previous results (Denby and Martin, 1979) indicating that heavy-tailed innovation distributions improve the accuracy of certain estimators can be possibly extended to the robust methods considered here.
To concluded, the presence of considerable skewness increases the bias of the LS-estimator but leaves the variance practically unaffected. On the contrary the variance (and in many cases the bias) of the LMS and RLS-estimators is reduced with increasing asymmetry. Furthermore, the LMS estimator is the worst among the estimators considered in terms of estimated TRMSE. However, when the underlying error-distributions is extreme-tailed, the last estimator is on the whole more reliable than the LS-estimator which, naturally, is very efficient (or near) at the standard normal model. Finally, the TLS and the RLS-estimators are both fairly accurate estimators but the latter estimator should be preferred since it is more bias-robust in the presence of skewness.
AO-Scheme (Table 2-3): In this case, the effect of additive outliers on the estimated bias increases with properties of contamination ε and it seems impossible to remove. This drastic effect of additive outliers is also obtained by Sejling et al. (1994) in their simulation study of recursive robust estimators. Interesting enough, comparison of biases favors the LMS and the RLS robust estimators over all additive-effect distributions. For the former estimator, this behavior is obviously connected with the specific type of outliers as it does not appear neither in the regression context nor in the IO- case. Among the other two less reliable estimators in terms of bias, the TLS has some advantage under symmetric (or nearly symmetric) additive effects for ε = 0.01. This advantage, however practically, disappears with increasing skewness and proportion of contamination. On the other hand, the bias of the LMS and RLS estimators is significantly affected by the order of the AR-model. Hence, we my conjecture that, the breakdown point of these methods is reduced compared to the regression setup and depends on the order p (Denby and Martin, 1979).
Based on efficiency, it is evident however that, the LMS is the least efficient method. The other three methods appear to be (overall) comparable, since no estimator clearly dominates the others, with the exception of the RLS which is less efficient with increasing skewness for ε≥0.05. Although, the effect of increasing skewness on the bias of the estimators is of considerable size for all methods (particularly for small σ), the LMS and RLS-estimators are comparatively more robust in this respect. The same effect on the efficiency of all four estimators is not equally significant. It appears however that, the presence of skewness considerably enhance the efficiency of the LS, the TLS-estimator for ε≥0.05 but at the same time, as it has already been mentioned, exerts a somewhat deteriorating effect on the variance of the RLS-estimator.
CONCLUSION
Robust autoregressive-model estimators occupy a particularly important area in time - series methodology. In this paper, we present a simulation study of three robust alternatives to the LS estimator under innovation and additive outliers. The simulation results indicate that, under the IO-scheme, the reweighted least squares and the trimmed least squares estimators perform well and the general conclusion is that in most cases, the estimators are not seriously affected by this type of outliers. Also, the results suggest that:
| • | The consistency rates of the LMS and RLS estimators under stable innovations are a decreasing function of the shape parameter a of the distribution (possibly of order related to a-1) |
| • | The presence of heavy tails improves the asymptotic efficiency of all robust estimators considered, regardless of whether or not the variance of the innovations exists |
Turning to the results under the AO-scheme, we have observed that, the effect of additive outliers on all four estimators considered is significant and with the exception of the least median of squares, of increasing importance as the proportion and the shape of contamination changes. The least median of squares estimator is competitive in the presence of considerable heavy-tail contamination, especially, when the additive-effect distribution is asymmetric. Overall, however, the reweighted least squares appears to be the most efficient method. In addition, the least squares estimators under both outliers schemes and although it is quite efficient near the standard normal model, exhibits less satisfactory performance on the whole. Finally, the findings of this study indicate that, in the case of auto regression with outliers, the RLS method should be considered as worthy robust alternative to the least squares method.
REFERENCES
- Campbell, K., 1982. Recursive computation of M-estimates for the parameters of a finite autoregressive process. Ann. Stat., 10: 442-453.
Direct Link - Chambers, R.L. and C.R. Heathcote, 1981. On the estimation of slope and the identification of outliers in linear regression. Biometrika, 68: 21-23.
CrossRef - Denby, L. and R.D. Martin, 1979. Robust estimation of the first-order autoregressive parameter. J. Am. Stat. Assoc., 74: 140-146.
Direct Link - Lucas, A., 1997. Asymptotic robustness of least median of squares for autoregressions with additive outliers. Commun. Stat. Theory Methods, 26: 2363-2380.
CrossRef - Rousseeuw, P.J., 1984. Least median of squares regression. J. Am. Stat. Assoc., 79: 871-880.
CrossRefDirect Link - Ruppert, D. and R.J. Carroll, 1980. Trimmed least squares in the linear model. J. Am. Stat. Assoc., 75: 828-838.
Direct Link - Simpson, D.G., D. Ruppert and R.J. Carroll, 1992. On one-step GM estimates and stability of inferences in linear regression. J. Am. Stat. Assoc., 87: 439-450.
Direct Link - Sejling, K., H. Madsen, J. Holst, U. Holst and J.E. Englund, 1994. Methods for recursive robust estimation of AR parameters. Comput. Stat. Data Anal., 17: 509-536.
CrossRefDirect Link - Yohai, V.J. and R.A. Maronna, 1977. Asymptotic behavior of least squares estimates for autoregressive process with infinite variance. Ann. Stat., 5: 554-560.
Direct Link