
J.F. Ojo
University of Ibadan, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2010 | Volume: 3 | Issue: 4 | Page No.: 225-236







ABSTRACT
In this study, full and subset one-dimensional autoregressive integrated moving average bilinear models which are capable of achieving stationarity for all non linear series are proposed and were compared to determine which of them perform better. The parameters of the proposed models were estimated using Newton-Raphson iterative method and an algorithm is proposed to eliminate redundant parameters from the full models to have subset models. Akaike Information Criterion (AIC) was used to determine the order of the model. To determine the best model, the residual variance attached to the proposed full and subset models were studied. In the fitted models different sample sizes were used and the statistical properties of the derived estimates are investigated. It was found that the residual variance attached to the full bilinear model was smaller than the subset model and this was so because of the introduction of the d factor in our new models which has made us to capture trend and seasonality in the data, which in turn helps arrive at stationarity easily for any time series data set and at the same time made the full model a better model.
PDF Abstract XML References Citation
Received: April 15, 2010;
Accepted: July 02, 2010;
Published: July 28, 2010
How to cite this article
J.F. Ojo, 2010. On the Estimation and Performance of One-dimensional Autoregressive Integrated Moving Average Bilinear Time Series Models. Asian Journal of Mathematics & Statistics, 3: 225-236.
DOI: 10.3923/ajms.2010.225.236
URL: https://scialert.net/abstract/?doi=ajms.2010.225.236
DOI: 10.3923/ajms.2010.225.236
URL: https://scialert.net/abstract/?doi=ajms.2010.225.236
INTRODUCTION
The bilinear time series models have attracted considerable attention during the last years. They have found a variety of applications including those in economy, biology, ecology, software interfailure, signal processing etc.
An overview of various models and their application can be found by Granger and Anderson (1978), Pham and Tran (1981), Gabr and Rao (1981), Rao et al. (1983), Liu (1992), Gonclaves et al. (2000), Shangodoyin and Ojo (2003), Wang and Wei (2004), Boonchai and Eivind (2005), Bibi (2006), Doukhan et al. (2006), Drost et al. (2007), Usoro and Omekara (2008). The bilinear modes studied by the above researchers could not achieve stationarity for all nonlinear series. Rao et al. (1983) gave a set of sufficient conditions for the existence of a strictly stationary stochastic process conforming to the following bilinear model:
where, p is the order of the autoregressive component, q is the order of the moving average component, r is the upper limit of the lag difference for the observed variable X in the bilinear part of the model, 1 is the limit of the lag difference for the error part of the bilinear model, a1, a2,...,ap are the parameters of the autoregressive component, c1, c2,...,cp are the parameters of the moving average component and b1l,........., br1 are the parameters of the nonlinear component and et are independently and identically distributed as ![]()
In this study, we extend the work of Rao et al. (1983) to the proposed one-dimensional autoregressive integrated moving average bilinear and subset bilinear models, which are capable of achieving stationarity for all nonlinear series; this is an important improvement over other bilinear time series models.
In addition, bilinear time series are characterized by too many parameters, some of which are close to zero. In the proposed models, we address this problem by employing the concept of subsetting. Subsetting helps remove these redundant parameters, thereby leading to so-called subset bilinear models. Gabr and Rao (1981) worked on subset bilinear models and tested all the subsets of the best order of the full bilinear model before selecting the best subset. In this study, subsetting concept is introduced to the proposed one-dimensional autoregressive integrated moving average bilinear model to determine its usefulness in achieving a better model.
PROPOSED ONE-DIMENSIONAL BILINEAR TIME SERIES MODELS
We define one-dimensional autoregressive integrated moving average bilinear and subset bilinear time series models as follows:
Model 1 (M1)
where φ(B) = 1-φ1 B-φ2B2......-φpBp, θ(B) = 1-θ1B-θ2B2........-θqBq and
| (1) |
φ1,...,φp are the parameters of the autoregressive component; θ1,...,θq are the parameters of the associated error process; b11,........,br1 are the parameters of the non-linear component and θ(B) is the moving average operator. p is the order of the autoregressive component; q is the order of the moving average process; r1 is the order of the nonlinear component and ψ(B) = ∇d (B) is the generalized autoregressive operator. ∇d is the differencing operator and d is the degree of consecutive differencing required to achieve stationarity.
Model 2 (M2)
| (2) |
where, pi is the order of subset autoregressive component; qh is the order of subset moving average process and rjl is the order of subset nonlinear component.
In the models above, et are independently and identically distributed as ![]()
The Vector form of BL (p, d, q, r, 1)
It is convenient to study the properties of a process when the model is in the state space form because of the Markovian nature of the model Akaike (1974).
Let
 |
and vectors
and let
(Here T stands for the transpose of a matrix) t = …..-1, 0, 1,….. With this notation, we can write the model (1) in the vector form as:
| (3) |
STATIONARITY AND CONVERGENCE OF BL (p, d, q, r, 1)
Here, we give a sufficient condition for the existence of strictly stationary process and convergence conforming to the bilinear model (1). This we do through the following theorem.
Theorem 1
Let {et, t ε Z} be a sequence of i.i.d. random variables defined on a probability space c1,c2 such that Eet = 0 and
Let C be any column vector with components c1, c2, …, cp Ψ and B be two matrices of order pxp and Θ be matrix of order qxq such that:
The series of random vectors
converges absolutely almost surely as well as in the mean for every fixed t in Z. Further, if
then for every t in Z, {Xt, t ε Z} is a strictly stationary process conforming to the bilinear model:
| (4) |
Conversely, if {Xt, t ε Z} is a strictly stationary process satisfying:
for every t in Z for some sequence {et, t ε Z} of i.i.d. random variables with Eet = 0 and
and for some matrices Ψ, Θ, B, C of respective orders pxp, qxq, rxr and px1, with
then
for every t in Z.
Proof of theorem 1 is given in the Appendix.
Description of Algorithm for Fitting Proposed Full and Subset Bilinear Models
For the sake of simplicity, we will break the algorithm down into the following steps.
Step 1
Fit various order of autoregressive integrated moving average model of the form:
Step 2
Choose the model for which Akaike Information Criterion (AIC) is minimum among various order fitted in step 1.
Step 3
Fit possible subsets of chosen model in step 2 using 2q-1 subsets approach Haggan and Oyetunji (1980).
Step 4
Choose the model for which AIC is minimum among the fitted models in step 3 to have the best subset model and this will form the initial values.
Step 5
Fit various order of the proposed full bilinear model of the form
and choose the model for which AIC is minimum
Step 6
Fit possible subsets of chosen model in step 5 using 2q-1 subsets approach Shangodoyin and Ojo (2003).
Step 7
The model with the minimum AIC is the best subset proposed bilinear model.
Estimation of parameters of BL (p, d, q, r, 1)
The joint density function of (em, em+1,......,en), where m = max(r, 1), is given by:
| (5) |
Proceeding as in Rao (1981), the Jacobian of the transformation from (em, em+1,...,en) to (Xm, Xm+1,...,Xn) is unity, the likelihood function of (Xm, Xm+1,..., Xn) is the same as the joint density function of (em, em+1, ...,en). Thus maximising the likelihood function is equivalent to minimizing the function Q(G), which is as follows:
| (6) |
with respect to the parameter
For convenience, we shall write G1 = Ψ1, G2 = Ψ2,......,GR = Brl, where, R = p + q + r1. Then the partial derivatives of Q(G) are given by
| (7) |
| (8) |
where, the partial derivatives of et satisfy the recursive equations:
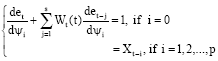 | (9) |
| (10) |
| (11) |
| (12) |
| (13) |
| (14) |
| (15) |
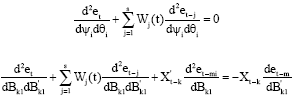 | (16) |
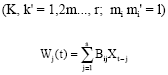 | (17) |
We assume that et = 0 (t = 1, 2, …, m-1) and
From these assumptions and Eq. (11) it follows that the second order derivatives with respect to Ψi (i = 0, 1, 2, …, p) and θi (i = 0, 1, 2, …, q) are zero. For a given set of values {Ψi}, {θi} and {Bi1} one can evaluate the first and second order derivatives using the recursive Eq. 9-11 and 17.
Let
and let H(G) = [d2Q(G)/dGidGj] be a matrix of second partial derivatives. Expanding V(G), near in a Taylor series, we obtain
Rewriting this equation and following Krzanowski (1998), we have
thereby obtaining an iterative equation given by
where G(k) is the set of estimates obtained at the kth stage of iteration. The estimates obtained by the above iterative equations usually converge. For starting the iteration, we need to have good sets of initial values of the parameters. This can be obtained as follows:
Suppose we wish to fit one-dimensional bilinear model BL(p, d, q, r, 1). We choose the coefficients of the autoregressive integrated moving average models (ARIMA) part of this model equal to the corresponding best subset ARIMA model. These coefficients are used as the initial values for starting the iteration of the Newton-Raphson iterative equation.
Estimation of the Parameters of Subset Bilinear (p, d, q, r, 1)
Let us assume that the sets of integers,![]() are fixed and known. Following Rao (1981), we can show that maximizing the likelihood function of
are fixed and known. Following Rao (1981), we can show that maximizing the likelihood function of ![]() is equivalent to minimizing the function
is equivalent to minimizing the function
with respect to the parameters
![]()
The partial derivatives of Q(G) are
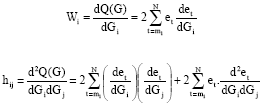 |
where the partial derivatives satisfy the recursive equations
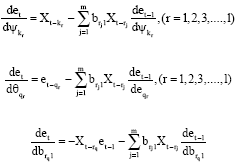 |
In the calculation of these partial derivatives, we set ![]() and
and
Let ![]() to evaluate the second order partial derivatives, let us approximate
to evaluate the second order partial derivatives, let us approximate
as is done in the Marquardt algorithm. Expanding ![]() in a Taylor series, we obtain
in a Taylor series, we obtain ![]()
Rewriting this equation, we get ![]() thereby obtaining the Newton-Raphson iterative equation:
thereby obtaining the Newton-Raphson iterative equation:
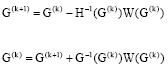 | (18) |
where G(k) is the set of estimates obtained at the kth iteration.
NUMERICAL EXAMPLE: THE WOLFER SUNSPOT DATA
To present the application of the models proposed, we will use a real time series dataset, the Wolfer sunspot, available in Box et al. (1994). The scientists track solar cycles by counting sunspots-cool planet-sized areas on the Sun where intense magnetic loops poke through the star’s visible surface. It was Rudolf Wolf who devised the basic formula for calculating sunspots in 1848; these sunspot counts are still continued.
As the Wolfer sunspot data set represent a non-stationary series, the bilinear models proposed in this paper may be applied. The Wolfer sunspot data set, available in Box et al. (1994), in this study is considered at two different sample size of 150 and 250. For the fitted model below we have used the algorithm and the estimation technique in the previous section.
| Table 1: | Goodness of fit of one-dimensional full and subset autoregressive integrated bilinear models at sample sizes of 50, 150 and 250. Two models are compared, namely M1: BL (p, 1, q, r, 1), M2: SBL (p, 1, q, r, 1). All models are significant at p<0.001 |
 | |
Fitted Model M1and M2 at sample size150
M1
Xt = 0.21742Xt – 1 + 0.172224Xt – 3 - 0.518088Xt – 4 - 0.218600Xt - 5 – 0.135334Xt - 6 – 0.269434Xt – 7 + 0.630377et – 1 - 0.119139et – 2 - 0.763971et – 3 - 0.000351Xt – 1et – 1 + 0.006676Xt – 2et - 1 - 0.001134Xt - 3et - 1 - 0.011233Xt – 4et – 1 – 0.003409Xt – 5et – 1 + 0.002608Xt – 6et – 1 – 0.020809Xt – 7et – 1 + 0.011283Xt – 8et – 1 + et
M2
Xt=- 0.217421Xt – 1 + 0.172224Xt – 3 – 0.518088Xt – 4 - 0.218600Xt – 5- 0.135334Xt – 6 – 0.269434Xt – 7 + 0.630377et – 1 - 0.119139et – 2 - 0.763971et – 3 - 0.012484Xt - 4et – 1 – 0.002564Xt - 5et – 1 + 0.005071Xt - 6et – 1 – 0.011200Xt - 7et – 1 + et
Fitted Model M1 and M2atsample size250
M1
Xt = - 0.712478Xt – 1 - 0.153047Xt – 2 + 0.032479Xt – 3 - 0.606080Xt - 4 – 0.351330Xt - 5 – 0.422284Xt – 6 - 0.407042Xt – 7 - 0.311950Xt - 8 + 0.809607et – 1 - 0.048903et – 2 - 0.673588et - 3 - 0.003340Xt - 1et - 1 - 0.008671Xt – 2et – 1 – 0.007744Xt – 3et – 1 - 0.005649Xt – 4et – 1 - 0.006420 Xt – 5et - 1 – 0.012716Xt – 6et - 1 - 0.006439Xt – 7et - 1 + et
M2
Xt =- 0.712478Xt – 1 - 0.153047Xt – 2 + 0.032479Xt – 3 - 0.606080Xt – 4- 0.351330Xt – 5 – 0.422284Xt – 6 - 0.407042Xt – 7 - 0.311950Xt - 8 + 0.809607et – 1 - 0.048903et – 2 – 0.673588et – 3 – 0.003128Xt - 1et – 1- 0.007883Xt - 2et – 1 – 0.009624Xt - 3et – 1 – 0.008877Xt - 5et – 1 - 0.013244Xt - 6et – 1 – 0.004914Xt - 7et – 1 + et
The fitted models’ residual variances, coefficient of determination(R-squared) and F-statistic are given in Table 1.
We could see the performance of the two models above using the residual variance attached to each model. The residual variance of full bilinear model is smaller than that of subset model. The proposed model gave us the best model at full model which is an improvement. The usual convention is that the subset model is always better than the full model. But in this proposed model, testing all subsets of the models is not necessary.
CONCLUSION
This study focused on new bilinear models that could handle all non-linear series. Bilinear models at different levels of sample sizes were considered using the non-linear real series. Full bilinear model emerged as the better model when compared with subset model. And this is an improvement in the model proposed. Moreover, estimation of parameters witnessed a unique, consistent and convergent estimator that has prevented the models from exploding, thereby making stationarity possible. The introduction of the d factor in our new models has made us to capture trend and seasonality in the data, which in turn helps arrive at stationarity easily for any time series data set and at same time made the full model a better model.
APPENDIX
Proof of Theorem 1
Here we prove the theorem 1 from section 4. For the sake of simplicity, we will break the proof down into the following steps.
Step 1
For almost sure convergence, we show that
| (A.1) |
for every i=1, 2, …….,p. This implies that
is absolutely convergent almost surely as well as in the mean
Step 2
We establish (A.1) for i = 1. The general case is clear. First, we note that for every t in Z, r 1 and s = 1, 2, …,p
where, K0 is a constant that depends only on Ψ, B, C and σ2.
Step 3
If r 2, then
for some constant K1>0
Step 4
Now, for any s = 1, 2, ….., p
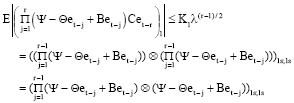 |
Consequently,
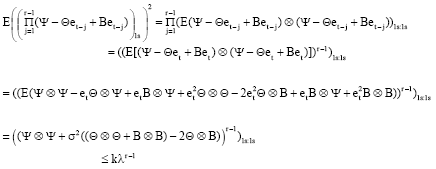 |
Hence
for a suitable choice of K1.
Since, λ<1, we have
for every i = 1, 2, …….,p.
Thus (A.1) is established.
It is obvious that the vector-valued stochastic process {Xt, t ε Z} defined by
is strictly stationary. Thus ![]() is a sufficient condition for strictly stationary of the model 2.4 Hence the proof.
is a sufficient condition for strictly stationary of the model 2.4 Hence the proof.
REFERENCES
- Akaike, H., 1974. Markovian representation of stochastic processes and its application to the analysis of autoregressive moving average processes. Ann. Inst. Statist. Math., 26: 363-387.
Direct Link - Bibi, A., 2006. Evolutionary transfer functions of bilinear process with time varying coefficients. Comput. Math. Appl., 52: 331-338.
Direct Link - Doukhan, P., A. Latour and D. Oraichi, 2006. A simple integer-valued bilinear time series model. Adv. Applied Prob., 38: 559-578.
Direct Link - Gonclaves, E., P. Jacob and N. Mendes-Lopes, 2000. A decision procedure for bilinear time series based on the asymptotic separation. Statistics, 33: 333-348.
CrossRef - Pham, T.D. and L.T. Tran, 1981. On the first order bilinear time series model. J. Applid Prob., 18: 617-627.
Direct Link - Gabr, M.M. and T.S. Rao, 1981. The estimation and prediction of subset bilinear time series models with application. J. Time Series Anal., 2: 89-100.
CrossRef - Rao, T.S., 1981. On theory of bilinear time series models. J. R. Statist. Soc. Series B, 43: 244-255.
Direct Link - Wang, H.B. and B.C. Wei, 2004. Separable lower triangular bilinear model. J. Applied Prob., 41: 221-235.
Direct Link