
K. Khorshidian
Department of Statistics, Shiraz University, Shiraz, Iran
Asian Journal of Mathematics & Statistics
Year: 2008 | Volume: 1 | Issue: 1 | Page No.: 57-62







ABSTRACT
We obtain a Strong Law of Large Numbers (SLLN) for the reward process {Z(t), t≥0}, the cumulative reward gained by operating a Semi-Markov system during the time interval [0, t]. The important and striking point in this study is leaving the usual assumption that rewards for each state are of constant rates. In most of applications this frequently used assumption is not realistic, therefore we deal with reward functions of general forms. The SLLN obtained is in the sense that Limt→∞Z(t)/t = α, a.s. for some real value α. Mild conditions for this SLLN are existence of sojourn times means and integrability of reward functions with respect to sojourn time distributions. As it has been shown, the parameter α coincides with the shift parameter in asymptotic representation of E[Z(t)], t→∞.
PDF Abstract XML References Citation
How to cite this article
K. Khorshidian, 2008. Strong Law of Large Numbers for Nonlinear Semi-Markov Reward Processes. Asian Journal of Mathematics & Statistics, 1: 57-62.
DOI: 10.3923/ajms.2008.57.62
URL: https://scialert.net/abstract/?doi=ajms.2008.57.62
DOI: 10.3923/ajms.2008.57.62
URL: https://scialert.net/abstract/?doi=ajms.2008.57.62
INTRODUCTION
In this study we deal with long run rate of reward processes defined on a Semi-Markov process, when the reward functions are not necessarily of linear form. The main difference between this work and other similar subjects, is inherent in the structure of functionals that we have mentioned. A Semi-Markov Process (SMP), or equivalently a Markov-Renewal Process (MRP) is an extension of a Markov Chain (MC) tied with ordinary renewal processes for each state. The successive states visited by this process forms a Markov chain, while the sojourn time in each state is not a constant and probabistically depends on the current state and may depend on the next state to be visited. It is well known that given the sequence of the states, the sequence of the sojourn times are independent. More details on Semi-Markov processes can be found in Cinlar (1969 and 1975a and b), Pyke (1961a and b) and Teugels (1976).
For processes with regenerative structure, a cost or reward function is often introduced. The total cost or reward gained corresponding to the performance of the system as a function of the time is called a reward process. In last decades many authors have considered different aspects of reward processes. Some have dealt with mean value of these processes and because of complicated forms of exact solutions obtained, most of these authors have tried for limiting behavior of mean value in long run of the process.
The definition of a reward process on a Semi-Markov process, backs to the first given by Pyke and Schaufele in (1964) as:
(1) |
Where, Jn and ξn are the state and epoch of n-th transition and f is a real valued function. The mean and variance for these processes in univariate and multivariate case were obtained by Sumita and Masuda (1987) and Masuda and Sumita (1991), when they considered a reward process of the form:
(2) |
Where, Δn = ξn+1-ξn is the sojourn time at state Jn. ρ(k) is a constant at state k. Note that Eq. 2 is a special case of Eq. 1, when f is of constant rate and hence it is linear in Δn. They obtained exact formulas as well as asymptotic behavior for mean value of the process E[Z(t)], t≥0 in univariate and multivariate case. Soltani (1996), introduced the nonlinear reward process as:
(3) |
Where, γ is the age process. The function ρ in Eq. 3 is called a reward function, where ρ(j, τ) measures the excess reward when time τ is spent in the state j. A closed form for mean of this process, when the reward functions assumed to be polynomials in time was obtained by Soltani (1996). Khorshidian and Soltani (2002 and 2003), obtained E[Z(t)] and Var[Z(t)] the expected value and variance of Z(t), as well as Σ(t), the covariance matrix for a multivariate reward process with components as Eq. 3. Using Markov-renewal theory and for general ρ(.,.), Soltani and Khorshidian (1998), showed that
(4) |
Where, the constants α0 and α1 were fully specified. For reward functions of general form and in multivariate case, Khorshidian and Soltani 2002, used supplementary variables technique and showed that as t →∞,
(5) |
Moreover, they calculated the vectors A0 and A1 and matrices C0 and C1.
In probability theory it is well known that for a sequence of random variables {Xn, n = 1, 2, ...}, with partial means (partial sums) {Yn, n = 1, 2, ...}, if the limits exist and are constant values, limn→∞ E[Yn] does not necessarily coincides with limn→∞ Yn. In what follows we will show that under some mild conditions limt→∞ Z(t)/t = limt→∞ E[Z(t)]/t, this is the SLLN we purposed.
To arrive at the mentioned strong law for the process Eq. 3, since the reward functions ρ(.,.) assumed to have general forms, it is natural to impose some conditions on it. Most of the conditions we need are about integrability of ρ, just what has been done for calculating moments of Z(t), by Soltani and Khorshidian (1998) and Khorshidian and Soltani (2002).
NOTATION AND PRELIMINARIES
Let {J(t), t≥0} be a SMP with a MRP, {(Jn, ξn), n = 0, 1, 2, ...}. The state space of {Jn} is assumed to be E = {s0, s1, ..., sm}. Jn and ξn are the state and epoch of n-th transition n≥0 with ξ0 = 0. Also let Δn = ξn+1-ξn denotes the sojourn time at Jn. The transition probabilities are purposed to be
![]() , where
, where ![]() are transition probabilities of the embeded Markov chain and Fi(.) is the distribution of sojourn time at state i. The mean sojourn time at state i is:
are transition probabilities of the embeded Markov chain and Fi(.) is the distribution of sojourn time at state i. The mean sojourn time at state i is:
The invariant stationary distribution of the underlying MC is ![]() is the initial probability row vector with
is the initial probability row vector with ![]() .
.
The number of transitions in [0, t] is denoted by N(t). It is well known that if the SMP is irreducible, recurrent and the sojourn times have finite means, then
(6) |
The elapsed life of the process after the last transition is the age process ![]() .
.
Throughout the study we assume that the reward functions ρ in Eq. 3 are nonnegative. For reward functions with possibly negative values, without loss of generality and by adding a constant finite value M, all of the undergoing results goes true, provided that ![]() .
.
SLLN FOR REWARD PROCESSES
In this section, using limit theorems for MC`s and under integrability of reward functions ρ(J.,), with respect to the sojourn time distributions Fj(.), we will arrive at a SLLN for Z given by Eq. 3.
Let {(Jn, ξn); n = 0,1,2,...} ba an irreducible MRP, with finite state space E and corresponding SMP, {J(t), t≥0} with ![]() as the invariant stationary distribution of the underlying Markov chain {Jn, n≥0}. It is well known that when the state space is finite, the corresponding MC and MRP are positive recurrent and in this case,
as the invariant stationary distribution of the underlying Markov chain {Jn, n≥0}. It is well known that when the state space is finite, the corresponding MC and MRP are positive recurrent and in this case,
(7) |
for any real valued function f. In the next theorem we will drive more general limiting results for summands similar to Eq. 7, with a bivariate reward function ρ: Ex[0, ∞)→[0, ∞) instead of f and a MRP instead of the MC. Thereafter we will show that a SLLN holds for {Z(t), t≥0}, in the sense that limt→∞Z(t)/t exists, under the assumptions that
are finite for all j ε E.
Theorem 1
Suppose that {(Jn, ξn), n≥0} is an irreducible recurrent MRP with finite state space E and stationary distribution ![]() . Also suppose that max jεEmj and θ0(j) <∞, for all j ε E, then
. Also suppose that max jεEmj and θ0(j) <∞, for all j ε E, then
where, Z(t) is given by Eq. 3 and δ by Eq. 6.
Proof: First note that,
and therefore,
(8) |
Also irreducibility assumption and finiteness of E implies that, ![]() a.s., which gives
a.s., which gives
(9) |
Moreover,
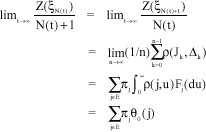 | (10) |
by the fact that N(t)→∞ as t →∞ and the argument will been given below for Eq. 10, So by Eq. 9 and 10
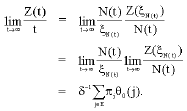 |
It remains to show that Eq. 10 holds in the sense that:
To do this, denote by Nn(i) the number of visits to state i during first n-th transitions of the MRP and by subsequence k(1, i), k(2, i),... those indices at them the process visits i. Also, by Yk(1,i), Yk(2,i) denote the sojourn times in state i, during the above subsequence. Given J0, J1, J2,..., the subsequence Yk(1,i), Yk(2,i) are IID with distributions Fi. Moreover, by Positive recurrence of the underlying MC, Nn(i)→∞ as n→∞ for all iεE and therefore by SLLN for IID random variables we have:
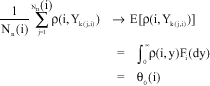 | (11) |
Thus,
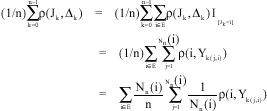 | (12) |
Since the MRP is assumed to be irreducible, recurrent with finite state space, we conclude that as n→∞, Nn(i)/n→πi and therefore Eq. 11 and 12 imply that:
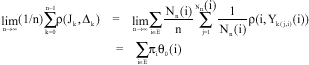 | (13) |
The proof is now complete.
Remark
As it has been expected, the limiting value α in Theorem 1, coincides with slope parameter α1 in Eq. 4, which has been derived by Soltani and Khorshidian (1998), for asymptotic representation of E[Z(t), t→∞. Also it coincides with elements of the vector A1, in Eq. 5 for multivariate {Z(t), t≥0, Moreover the assumptions on the reward functions and sojourn times for the above SLLN, are just as that which has been assumed for existence of E[Z(t)], t→∞ (Khorshidian and Soltani, 2002).
In the Theorem 1, finiteness of the state space is only used for embedded MC to have positive recurrent states. If in the infinite state space case, we impose conditions that by them, the states would be positive recurrent, then the result of this theorem hold. Therefore, we can arrive at the following corollary.
Corollary
Suppose that {(Jn, ξn), n≥0} is an irreducible positive recurrent MRP with infinite state space E and stationary distribution ![]() . Also suppose that mj<∞ and θ0(j)<∞, for all j ε E then
. Also suppose that mj<∞ and θ0(j)<∞, for all j ε E then
REFERENCES
- Khorshidian, K. and A.R. Soltani, 2002. Asymptotic behavior of multivariate reward processes with nonlinear reward functions. Bull. Iran. Math. Soc., 28: 1-17.
Direct Link - Khorshidian, K. and A.R. Soltani, 2003. Exact solutions for covariance matrix of multivariate reward processes with analytic reward functions. J. Sci. I.R. Iran, 14: 173-183.
Direct Link - Masuda, Y. and U. Sumita, 1991. A multivariate reward process defined on a semi-Markov process and its first-passage-time distributions. J. Applied Probab., 28: 360-373.
CrossRefDirect Link - Pyke, R., 1961. Markov renewal processes: Definitions and preliminary properties. Ann. Math. Stat., 32: 1231-1242.
Direct Link - Pyke, R., 1961. Markov renewal processes with finitely many states. Ann. Math. Stat., 32: 1243-1259.
Direct Link - Pyke, R. and R. Schaufele, 1964. Limit theorems for Markov renewal processes. Ann. Math. Stat., 35: 1746-1764.
Direct Link - Soltani, A.R., 1996. Reward processes with nonlinear reward functions. J. Applied Probab., 33: 1011-1017.
CrossRefDirect Link - Soltani, A.R. and K. Khorshidian, 1998. Reward processes for semi-Markov processes: Asymptotic behaviour. J. Applied Probab., 35: 833-842.
CrossRefDirect Link - Ushio, S. and M. Yasushi, 1987. An alternative approach to the analysis of finite Semi-Markov and related processes. Commun. Stat. Stochastic Models, 3: 67-87.
CrossRefDirect Link - Teugels, J.L., 1976. A bibliography on Semi-Markov processes. J. Comput. Applied Math., 2: 125-144.
Direct Link