
A.C. Okoroafor
Department of Mathematics, Abia State University, Uturu, Nigeria
B.O. Osu
Department of Mathematics, Abia State University, Uturu, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2008 | Volume: 1 | Issue: 2 | Page No.: 126-131







ABSTRACT
Explicit steepest decent type stochastic method is constructed for approximating the solution of an evolution equation governed by a maximal monotone operator in Hilbert space. The approximating scheme is shown to converge strongly to the global equilibrium of the equation.
PDF Abstract XML References Citation
How to cite this article
A.C. Okoroafor and B.O. Osu, 2008. The Solution by Stochastic Iteration of an Evolution Equation in Hilbert Space. Asian Journal of Mathematics & Statistics, 1: 126-131.
DOI: 10.3923/ajms.2008.126.131
URL: https://scialert.net/abstract/?doi=ajms.2008.126.131
DOI: 10.3923/ajms.2008.126.131
URL: https://scialert.net/abstract/?doi=ajms.2008.126.131
INTRODUCTION
Let H be a real Hilbert space with inner product (.,.) and norm ||.||. If T is a mapping with domain D(T) in H and values in H, then T is said to be monotone if
| (1) |
We shall be interested in an important class of monotone operators which consists of the gradient of convex functions:
Let f be a convex lower semi continuous function from H into (–∞, + ∞].
We assume that f ≠ +∞ and let D(f) = {x ∈ H: f(x)< + ∞} be the effective domain of f.
For x ∈ D(f), the set ∂f(x) = {t∈ H: f(y)-f(x)≥(t, y-x)∀ y ∈ Df(x)} is called the sub differential of f at x. The set ∂f(x) is closed and convex.
Definition 1
A selection n for a set-valued map T is single-valued mapping satisfying φ(x) ∈Tx or each x ∈ D(T).
It is well known that the operator x → ∂f(x) is maximal monotone in the sense that it admits no proper monotone extension.
In recent times interest has been on the approximation methods for the solution of evolution equation involving monotone operators that can abstractly be written in the Hilbert spaces H in the form
| (2) |
Where, h(t) is absolutely continuous from [0, T] into H and x0 ∈ D(∂f).
Early results in the qualitative theory of evolution equations associated with maximal monotone operators (Brezis, 1971), show that for any initial value x(0) = x0 ∈D(∂f), we can, in principle, obtain unique solutions x(t) ∈D(∂f), t∈(0,T] such that the trajectory in D(∂f) followed by the attracted to the stationary solution {x*: ∂f(x*) = h} in D(∂f), which is the equilibrium of the system.
Consequently, constructive techniques have been developed for approximating the stationary solution x* of equations involving maximal monotone operator (Brezis, 1971; Chidume, 1995).
This study introduces a stochastic iteration approach for the derivation of discrete time approximations for the solution of the evolution equation of the type in (2) in Hilbert space. The stochastic sequence arising from this approach is shown to converge strongly to a unique solution of the system (2).
Preliminaries
We assume that H is a real separable Hilbert space with inner product (.,.) and norm || ||.
A random vector in H is a measurable mapping defined on a probability space (Ω, T, P) and taking values in H.
If u, v are random vectors in H and y is fixed vector in H, then ||u||, (u, v), (y, u) are real-valued random variables in the usual sense.
Let E denote the expectation operator. If E||u||< ∞, then Eu is defined by the requirement E(y,u) = (y, Eu) ∀ y ∈ H.
Definition 2
A stationary solution x* ∈ D(∂f), i.e., {x*: ∂f(x*) = h}, is an attractor of x(0) = x0 if there is a sequence of points in D(∂f) stating at x(0) = x0 and converges to x*.
A result due to Chidume (1995) shows that solution x* is an attractor of an initial point x0 ∈ D(∂f) as follows:
Theorem 1
Let {ak} be a real sequence such that:
![]()
![]()
![]()
Then the sequence ![]() generated by x0 ∈ D(∂f) and defined iteratively by
generated by x0 ∈ D(∂f) and defined iteratively by ![]() for ∂f0 ∈ ∂f(xK), a single valued selection of ∂f remains in D(∂f) and converges strongly to {x*:∂f(x*) = h}.
for ∂f0 ∈ ∂f(xK), a single valued selection of ∂f remains in D(∂f) and converges strongly to {x*:∂f(x*) = h}.
The sequence {xk} is thus intimately related to the dynamical behaviour of the solution of the system (1).
We will not repeat the proof here, rather we consider a sequence of random vectors gk, computed from different data points pj ∈ H, for each k and j = 1,.,.,.N in such a way that gk strongly approximates ∂n fK ∈ ∂f(xK) and consistent in mean square in the sense that the distance between the time and estimated gradient vectors are minimized as follows:
Definition 3
The sequence of random vectors gk
strongly approximates ![]() if
if
| (3) |
is consistent with ∂fk in mean square if
| (4) |
Here N is the number of data points x1,...,xN.
We will show in the next section that when gk strongly approximates ∂fk for each k, a search for {x*:∂f(x*) = h} from x(0) = x0 ∈ D(f) along xk+1 = xk-ak[gk-h] approximates the search along ![]() .
.
This is expected to lead to the stationary solution x* rather faster.
Convergence Theorem for the Iterative Scheme
Theorem 2
Assume that the sequence {ak}k≥0 of positive number satisfies the conditions;
|
and {gk} is a sequence of random vectors satisfying (3) and (4).
Then the stochastic sequence {xk}k≥0 in H defined iteratively from x0 ∈ D(∂f) by xk+1 = xk-ak[gk-h] converges strongly to the unique solution {x*: ∂f(x*) = h}∈ H almost surely.
Proof:
Let |
then {VK} is a sequence of independence random variable. From (3) EVK = 0 for each k, thus the sequence of partial sums
But
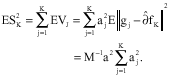 |
The convergence of the series ![]() in theorem 1 (iii) then implies
in theorem 1 (iii) then implies
Thus by Martingale convergence theorem (Whittle, 1976) we have
so that
Hence by theorem 1
converges strongly to the unique solution {x*: ∂f(x*) = h}∈ H.
Let {TK(xj)} be a complete orthonormal basis of H associated with the data points x1,x2,.,.,.xN. Then:
Definition 4![]() is linear least square estimable in terms of some discrete function values computed from data point x1,x2,.,.,.xN if the data points are suitably chosen such that:
is linear least square estimable in terms of some discrete function values computed from data point x1,x2,.,.,.xN if the data points are suitably chosen such that:
| (5) |
If H is n-dimenensional Euclidean space a convenient basis for f, considered in (Okoroafor and Ekere, 1999) with concrete examples, is the set {tj} in Rn satisfying
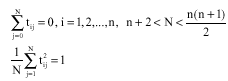 |
This yields the same result.
For the convex function f with
Let ![]() be a single valued selection of ∂f. For every u ∈ H and
be a single valued selection of ∂f. For every u ∈ H and ![]() (u) ∈ ∂f(u). Taylor theorem implies that
(u) ∈ ∂f(u). Taylor theorem implies that
| (7) |
for v ∈ H. Where o ( . ) indicates terms which can be ignored in the limit and L(u) is the second derivative of f if it exists.
Remark 1
Where the second derivative of f does not exist in any sense, we consider the Taylor theorem of the form
| (8) |
Where, 0(||.||) indicates terms which can be ignored relative to v in the limit and ignore all second conditions since they have no influence on the convergence analysis of the method as we shall see in the sequel. For completeness assume the second derivative exists in some sense.
Let y(xj) = f(xk + T(xj))-f(xk), xk ∈ D(f)) for a fixed k and j = 1,2,...,N.
Definition 5
The non observable random errors of approximation on the data points x1,x2,.,.,.xN, is the sequence of random variables {e(xj)} satisfying Ee(xj) = 0 for each j and Ee(xj)e(xj) = σ2δij where 0<σ2<∞.
A convenient basis for the function (7) is the complete orthonormal basis ‹Tr› in H, so that he approximation function is given by:
| (9) |
which is identifiable with (7).
The discrete function values y(xj), for each j, are real valued independent observable random variables performed on xj ∈ H whose distribution is that of e(xj). If at the point xk ∈ H, for each k, the data points x1,x2,.,.,.xN suitably chosen so that
| (10) |
then
Theorem 3
A strong approximation of ![]() at xk that is consistent is the random vector
at xk that is consistent is the random vector
| (11) |
which is the least square approximation computed from different data points x1,x2,.,.,.xN.
Proof: Assume
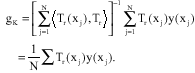 |
Then
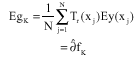 |
So that
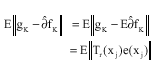 |
and
moreover,
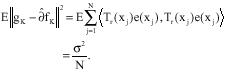 |
Hence
Thus gk strongly approximates ![]() and also is consistent in mean square to
and also is consistent in mean square to ![]() at xK.
at xK.
Then the stochastic iterative scheme generated by the stochastic sequence {gK} is then given as follows:
Let xK be an estimate of x*;
| (a) | Compute | |
| (b) | Compute aK | |
| (c) | Compute xK+1 = xK-aK[gK-h] | |
| (d) | Check for convergence: | |
| Is ||xK+1-xK||<δ, δ>0 ? | ||
| Yes: | xK+1 = xK | |
| No: | Set k = k + 1 and return to (b) | |
CONCLUSION
In this study, we have constructed a steepest decent type stochastic sequence in a separable Hilbert space. This sequence has been shown to converge strongly to the solution of an evolution equation.
Where, ∂f is the maximal monotone operator in the Hilbert space.
REFERENCES
- Chidume, C.E., 1995. Iterative solution of nonlinear equations with strongly accretive operators. J. Math. Anal. Applic., 192: 502-518.
CrossRefDirect Link