
I.S. Salawu
Department of Agronomy, Institute for Agricultural Research, Ahmadu Bello University, Zaria
Asian Journal of Agricultural Research
Year: 2007 | Volume: 1 | Issue: 2 | Page No.: 80-85







ABSTRACT
If X1, X2, . . . . ., XK represent the levels of k experimental factors and y is the mean response, then the inverse model at quadratic variable polynomial response function is defined by: Y = bo +b1 X+b11 X-1 in the single nutrient case where (X is replace by X-1 in the inverse model) fitting a response surface for N, P, K by the mathematical form of the inverse response surface gives: Y = b+ b1 X1 + b2 X2 + b3 X3 + b11 X1-1+ b22 X2-1+ b33 X3 -1+ b12X1X2 + b13X1X3 + b23X2X3. Arguments are given for preferring these surfaces to ordinary polynomials in the description of certain kinds of biological data. The fitting of inverse polynomials under certain assumptions is described and shown to involve no more labour than that of fitting ordinary polynomials. Complications caused by the necessity of fitting unknown origin to the Xi are described. The goodness of fit and coefficient of variations are used to compare both the ordinary and inverse polynomials to fertilizer recommendation and the inverse kind shown to have some advantages.
PDF Abstract XML References Citation
How to cite this article
I.S. Salawu, 2007. Transformed Inverse Model at Quadratic Variable in fertilizer Response. Asian Journal of Agricultural Research, 1: 80-85.
DOI: 10.3923/ajar.2007.80.85
URL: https://scialert.net/abstract/?doi=ajar.2007.80.85
DOI: 10.3923/ajar.2007.80.85
URL: https://scialert.net/abstract/?doi=ajar.2007.80.85
INTRODUCTION
In an experiment where one or more quantitative factors (X1, X2, . . . . ., XK) are tested each at two or more levels, it is often convenient to be able to summarize the data by fitting to it a suitable response surface. The yield, denoted by y, are to be expressed in terms of a suitable function f of the factor levels X1, X2, . . . . ., XK and parameter θ1, which may be wholly or partially unknown. A typical model may thus be written:
y2= f (x1i, x2i, . . . . ., θi) + ei |
where, x1i, x2i, . . . . . denote the factor levels for yield yi and ei is an error term. The ei’s will usually be assumed to have some structure (e.g., to be independent N (0, σ2) variates) but for the moment we shall ignore them and consider only the choice of f (.).
In biometry it is much common to find that there is no basic theory to give us a detailed guide to the choice of f (.) and this is the situation considered here. The commonest choice for f (.) in current use is the ordinary polynomial in which the θ’s are the coefficients of the various terms. (Nelder, 1966).
Nelson et al. (2003) listed the following for the general popularity of the quadratic model:
| • | It involves merely the addition of an extra term to the straight line relationship, which for most people, makes it the simplestcurvilinear relationship; |
| • | It has a simple define maximum at X = -b1/2b11 and |
| • | The method of least squares produces estimates of parameters without complex calculations. |
Another advantage is that the scope of yield response patterns that may be fitted within the polynomial family using least squares procedures is broad due to the possibility of making various transformations primarily of X variables (Colwell, 1979).
However the considerable simplicity found in an analysis using ordinary polynomials is accomplish by some disadvantages. Most importantly the polynomials are unbounded; i.e., as any x is increased indefinitely any polynomial containing it eventually takes value (either positive or negative) as large as we please. It does not allow for asymmetry around the optimum in the yield response pattern. This asymmetry often occurs in actual practice.
Nelder (1966) developed a group of empirical models called inverse polynomials, which he claimed are more flexible and realistic than ordinary polynomials.
MATERIALS AND METHODS
The data used for this research was a fertility trial of rice conducted in the Institute for Agricultural Research, (IAR) Samaru in the year 2002 and 2003 rainy season. The treatments consisted of three varieties and three levels each of nitrogen, phosphorus and potassium. These treatments combination were arranged in a split plot design with variety and nitrogen in the main plot and phosphorus and potassium in the sub-plot and it was replicated three times.
The model evaluated include:
| • | Quadratic model |
| • | Transformed inverse model at the quadratic variable |
The models were also evaluated and compared on the basis of their goodness of fit using coefficient of variation. Residual analysis resulting from each model was critically examined. In fitting the models, the regression coefficients that are not significant are dropped from the models.
RESULTS AND DISCUSSION
The results show that the two models fitted equally well, with coefficient of determination of about 88.5% and the precision to be expected from the models are equally similar, with coefficient of variation of about 10% in which the inverse polynomial at the quadratic variable performs better in both coefficient of determination and coefficient of variation for all the varieties considered.
Fitted Models for the Varieties
Models based on variety 1 for both inverse polynomial at quadratic variable and ordinary polynomial. The regression parameters included in the model are all significant at p≤0.05.
| (i) | Inverse polynomialat quadratic |
Y = 1516 + 16.7N+ 20.3P+ 5131N-1 - 0 .160NP |
| (ii) | Ordinary quadratic model |
Y= 1563 + 20.3N + 11.9P - 0.026N2 |
Models based on variety 2 for both inverse polynomial at quadratic variable and ordinary polynomial
| (i) | Inverse polynomialat quadratic |
Y = 1570 + 26.4N + 14.6P + 16.6K - 30082N-1 - 0.505NP |
| (ii) | Ordinary quadratic model |
Y = 1339 + 25.20N -1.1 P - 0.0988N2 |
Models based on variety 3 for both inverse polynomial at quadratic variable and ordinary polynomial.
| (i) | Inverse polynomialat quadratic |
Y = 1267 + 22.2N + 25.5P - 16538N-1 - 0.332NP |
| (ii) | Ordinary quadratic model |
Y = 1161 + 24.10N + 7.90 P- 0.109N2 |
Models based on combined varieties for both inverse polynomial at quadratic variable and ordinary polynomial
| (i) | Inverse polynomialat quadratic |
Y = 1451 + 25.6N + 20.6 P - 13430N-1 - 0.360NP |
| (ii) | Ordinary quadratic model |
Y = 1366 + 26.4N + 3.9P - 0.119N2 |
Comparing the results from fitting the models to each of the varieties, we found that the goodness of fit of the models are similar for variety 1 and 3 with high coefficient of determination. On the other hand, the fitted model resulting from data set for variety 2, is, R2 of about 70%. This may have been due to some differences in the collected data which may have been caused by some factors such as lack of homogeneity in plot, recording of wrong measurement from the field and etc. Also from the results, all the models seemed to be very comparable. Thus, other factors such as, the nature of the actual crop response and the relevant area of interest must be considered in selecting the best model (Table 1).
| Table 1: | Coefficient of Variation (CV) and coefficient of determination (R2) for the three varieties |
 | |
| Values are shown in percentage | |
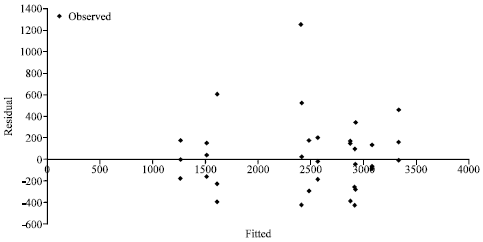 | |
| Fig. 1: | Residual versus the fitted values using inverse transformation model for the combined varieties |
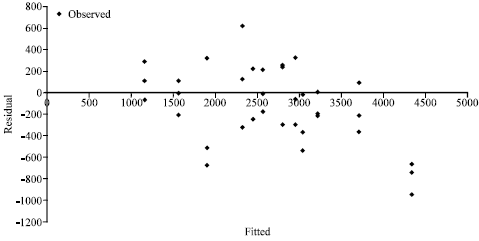 | |
| Fig. 2: | Residual versus the fitted values using quadratic model for the combined varieties |
Examine the Residuals
Figure 1 and 2 are the plot of residuals against the fitted values and they are based on the models fitted for the combined data on variety 1 and 3. The graphs show that there is no systematic pattern in the plots and hence the models are adequate.
Figure 1 and 2 study the aptness ofthe model which assist in knowing whether the model is appropriate. A residual plot against the fitted value is an effective means of studying the constancy of the error variance, particularly when the regression is non-linear (John and Wasserman, 1974).
Examine the Variation in the Regression Models
Figure 3 and 4 showed that the fitted models are good predictor of the response to the fertilizer recommendations in rice production. Also variations between the observed and fitted values are more reduced in transformed inverse which indicates that the models perform better than the ordinary polynomial model.
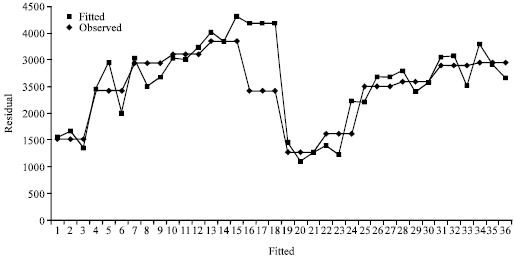 | |
| Fig. 3: | Observed and fitted values using inverse transformation model for the combined varieties |
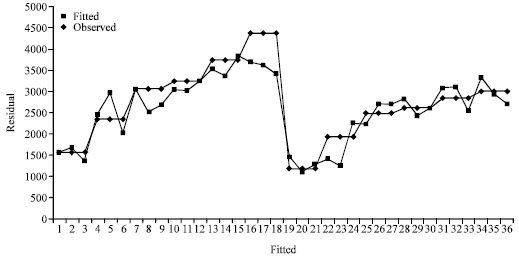 | |
| Fig. 4: | Observed and fitted values using quadratic model for the combined varieties |
CONCLUSIONS
Models were fitted for both transformed inverse polynomial at quadratic variable and the ordinary quadratic model for individual and combined varieties. The fitted model for the two polynomial function are of good fit with R2≥80% and CV≤18% results of the study indicated that the models are closed in terms of goodness of fit. The regression parameters in the models fitted are all significant at p≤0.05. The transformed inverse polynomial model is appropriate for certain purposes, but it appeared to have a slight superiority in statistical efficiency in predicting the yield response for the particular environmental condition under which the experiment was conducted (Nelson et al., 2003).
Concerning model selection, one cannot recommend a single model for all situation. The nature of the actual crop response and the relevant area of interest should be considered in choosing a model. It would seem that the transformed inverse polynomial would be a reasonable choice in many situation.
REFERENCES
- Nelder, J.A., 1966. Inverse polynomials, a useful group of multi-factor response functions. Biometrics, 22: 128-141.
CrossRefDirect Link