
H.J. Zainodin
School of Science and Technology, Universiti Malaysia Sabah, 88400 Kota Kinabalu, Sabah, Malaysia
A. Noraini
School of Science and Technology, Universiti Malaysia Sabah, 88400 Kota Kinabalu, Sabah, Malaysia
S.J. Yap
School of Science and Technology, Universiti Malaysia Sabah, 88400 Kota Kinabalu, Sabah, Malaysia
Trends in Applied Sciences Research
Year: 2011 | Volume: 6 | Issue: 11 | Page No.: 1241-1255







ABSTRACT
This study illustrated the procedures in selecting the best model when there are more than one independent variables. In this case, multiple regressions were used to analyze the data. First of all, all of the possible models are listed out. Then, in order to obtain the selected models, the multicollinearity test and coefficient test were carried out on all of the possible models. In this study, the alternative method was used to overcome multicollinearity, rather than the conventional method. After that, the best model was obtained by using the Eight Selection Criteria (8SC). Meanwhile, the normality test and randomness test were also carried out on the residuals of the best model. As a result, by getting the best model, the main factor that indicated the changes of percentage of body fat in men can be identified.
PDF Abstract XML References Citation
Received: March 01, 2011;
Accepted: June 28, 2011;
Published: September 06, 2011
How to cite this article
H.J. Zainodin, A. Noraini and S.J. Yap, 2011. An Alternative Multicollinearity Approach in Solving Multiple Regression Problem. Trends in Applied Sciences Research, 6: 1241-1255.
URL: https://scialert.net/abstract/?doi=tasr.2011.1241.1255
URL: https://scialert.net/abstract/?doi=tasr.2011.1241.1255
INTRODUCTION
Regression analysis is a statistical technique concerning about the study of the relationship between one dependent variable and one or more independent variable (Gujarati, 1999). Researchers have made heavy use of regression analysis in business, social sciences, biological sciences and many other fields. The linear regression analysis is used to find the influence of the independent variable on the dependent variable while the multiple regressions is used to find the influence of more than one independent variables on the dependent variable. An example of the study done on multiple regressions is by Matiya et al. (2005) in determining the factors influencing the prices of fish and its implications on development of aquaculture in Malawi. Reliable alternative approaches are also suggested to other existing methods in order to obtain better estimates, such as, Midi et al. (2009) had proposed a leverage based-near neighbors in the estimation of parameters in heteroscedastic multiple regression models. Besides that, the effect of processing parameters on the microstructures and properties of automobile brake drum using multiple regression analysis was also studied by Oluwadare and Atanda (2007).
A common problem in multiple regression is multicollinearity. As Zainodin and Khuneswari (2009a) had stated that multiple regression is a regression model with more than one explanatory variable. The general form of multiple regression is shown as follows:
| (1) |
where, Y is the dependent variable, Ω0 is constant term, Ωj is the j-th coefficient of independent variable Wj and Wj is the j-th independent variables (included the single independent variables, interaction variables, generated dummy variables and transformed variables) where j = 1, 2, ..., k. When there exist highly correlated independent variables in the model, then multicollinearity effects are said to exist. Various methods had been suggested to overcome this problem. El-Salam (2011) had proposed an estimation procedure for determining ridge regression parameter in terms of least Mean Square Error (MSE). In the presence of multicollinearity, models’ parameter estimation became inaccurate. Hence, Camminatiello and Lucademo (2010) had developed an extension of the principal component logistic regression to overcome this problem. Midi et al. (2010) had also proposed Robust Variance Inflation Factors (RVIFs) in the detection of multicollinearity due to high leverage points which were the sources of multicollinearity.
MATERIALS AND METHODS
Multiple regressions are used to analyse the data in this study. There are four phases in the model building procedures of multiple regressions, from listing down the all possible models to carrying out the goodness-of-fit on the residual of the best model. The model building procedures are shown in Fig. 1.
All possible models: According to Fig. 1, all of the possible models have to be listed out before analysis is carried out. Zainodin and Khuneswari (2009a) stated that the number of all possible models can be calculated as follows:
| (2) |
where, N is number of possible models and q is single independent variables which excluded the dummy variables.
Selected models
Multicollinearity test: In order to get the selected models, the multicollinearity test is carried out to remove multicollinearity source variables from each models and the procedures are shown in Fig. 2.
In this study, the alternative method is used in overcoming multicollinearity, rather than the conventional method. The multicollinearity source variables are variables with absolute correlation coefficient greater than 0.95 and they are marked with circles in the correlation coefficient matrix. There are three types of cases in the multicollinearity test and the removal steps of multicollinearity source variable are based on these three cases as follows:
| Case A: | The most common variable is removed first. Then, rerun the reduced model |
| Case B: | When more than one tie exists (or with frequency two and above), the variables with the highest frequency are considered first. Then, independent variable which has the smallest absolute correlation coefficient with Y is removed. Then, rerun the reduced model |
| Case C: | When only one tie exist (or with frequency one), the pair variables which have a higher correlation coefficient is considered first. Then, independent variable which has a smaller absolute correlation coefficient with Y is removed. Then, rerun the reduced model |
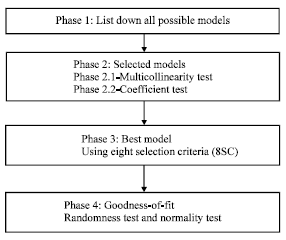 | |
| Fig. 1: | Model building procedures |
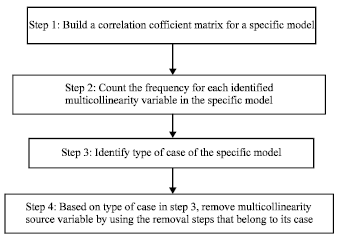 | |
| Fig. 2: | Multicollinearity test procedures |
Then, to get the frequency for a specific identified multicollinearity variable in the correlation coefficient matrix, the algorithm of counting the frequency is as follows:
| Step 1: | For each variable, draw a horizontal line until off-diagonal values |
| Step 2: | Then, the horizontal line is continued by drawing a vertical line on the lower part values from diagonal value and circle absolute values greater than 0.95 |
| Step 3: | Lastly, among all of the values cut by both horizontal and vertical lines, count the number of times the circle (s) has appeared (the diagonal values are not considered) |
Since the correlation coefficient matrix is symmetry, thus only the lower diagonal values are considered in counting the number of frequency. Thus, according to Fig. 2, after the frequency for each independent variables in a model are obtained, type of case can be identified and removal of multicollinearity source variable can be carried out. This Zainodin-Noraini multicollinearty remedial procedure is carried out to each of the possible model.
Coefficient test: After removal of multicollinearity source variables, according to Fig. 1, the next step is to perform coefficient test on the reduced model. Zainodin and Khuneswari (2009a) stated that coefficient test is used to test the coefficient of the corresponding variables. Variables which are insignificant are eliminated subsequently. For a specific j, the hypothesis for Coefficient Test is as below:
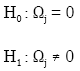 |
The decision is that the null hypothesis is rejected if |tcal| is greater than |tcritical| where
and |tcritical| is tα/2,(n-k-1). ![]() is the standard error for
is the standard error for ![]() and Ωj (H0) is the value of Ωj under H0 for j = 1, 2,…, k. The decision is to accept the null hypothesis. Thus, variable with the smallest |tcal| and is nearest to zero is eliminated from the models. The elimination process is repeated until there is no more insignificant variable in the models.
and Ωj (H0) is the value of Ωj under H0 for j = 1, 2,…, k. The decision is to accept the null hypothesis. Thus, variable with the smallest |tcal| and is nearest to zero is eliminated from the models. The elimination process is repeated until there is no more insignificant variable in the models.
Best model: After all of the selected models are obtained, models with the same independent variables are filtered out. After that, to get the best model, Eight Selection Criteria (8SC) is carried out on the selected models which have undergone filtration. Zainodin and Khuneswari (2009b) have discussed in detail the usage of the 8SC. The Akaike Information Criterion (AIC) (Akaike, 1974) and Finite Prediction Error (FPE) (Akaike, 1969) are developed by Akaike. The Generalised Cross Validation (GCV) is developed by Golub et al. (1979) while the HQ criterion is suggested by Hannan and Quinn (1979). The RICE criterion is discussed by Rice (1984) and the SCHWARZ criterion is discussed by Schwarz (1978). The SGMASQ is developed by Ramanathan (2002) and the SHIBATA criterion is suggested by Shibata (1981). The Eight Selection Criteria (8SC) is presented in Table 1.
| Table 1: | Eight selection criteria (8SC) |
 | |
| SSE = Sum of square error, k+1 = No. of parameters and n = No. of observations | |
Goodness-of-fit
Randomness test: Randomness test is used to test the randomness of residuals. The distribution of the residual can be obtained from the histogram and scatter plots of the residuals. Bin Mohd et al. (2007) stated that the randomness of residuals, ui (i = 1, 2, 3,…, n), can be checked by simple correlation coefficient. The procedures are as below:
Step 1: The null and alternative hypotheses are defined as follow:
| • | H0: The residuals, ui are randomly distributed |
| • | H1: The residuals, ui are not randomly distributed |
Step 2: Test statistic is calculated as follows:
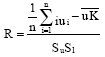 |
where,
and R is simple correlation coefficient and n is sample size. Since ui are independent on i, then random variable
follows a t-distribution with degree of freedom = n-p where p = k+1 which is the number of estimated parameters.
Step 3: The null hypothesis is accepted if |tcritical| is greater than |Tn| which means that the residuals ui are randomly distributed.
Normality test: According to Gujarati (1999) the normality of a regression model can be obtained by using the histogram of residuals and Normal Probability Plot (NPP). By plotting the histogram of residuals, the shape of the underlying probability distribution can be estimated. In the NPP, the variable of interest is normally distributed if a straight line fits the data well. Besides that, the Kolmogorov-Smirnov test and Shapiro-Wilk test are also used to test the normality of the residuals. Kolmogorov-Smirnov test is used when the number of observations is large while Shapiro-Wilk test is used when the number of observations is small. Both of these tests can be carried out by using the SPSS software. The null and hypotheses for normality test are as below:
| • | H0: The residuals, ui are normally distributed |
| • | H1: The residuals, ui are not normally distributed |
The decision is to accept the null hypothesis if the p-value from the SPSS output is greater than 0.05. Thus, the residuals are assumed to be normally distributed. Apart from this, some graphical plots, such as scatter plot, histogram, Q-Q plot and box plot can also used as supporting evidence for the normality test.
Data analysis
Data description: The data is obtained from Dr. A. Garth Fisher from the Human Performance Research Centre of Brigham Young University and contains the observations of 252 men (Johnson, 1996). In this study, nine variables are selected and analysed. They are the percentage of body fat using Siri’s equation, abdomen circumference, adiposity index, chest circumference, hip circumference weight, density, height and neck circumference. According to Bosy-Westphal et al. (2005), the Siri’s equation used in estimating the percentage of body fat is as follows:
| (3) |
where, the body density will be calculated as weight/volume. The descriptive statistics of these 9 variables are shown in Table 2.
The correlation among dependent variable, percent of body fat using Siri’s equation and the other 8 independent variables is presented in Table 3. However, due to limited space, the name of the variables in Table 3 are represented by their short forms, where their full names can be referred in Table 2.
| Table 2: | Descriptive statistics for all 9 variables |
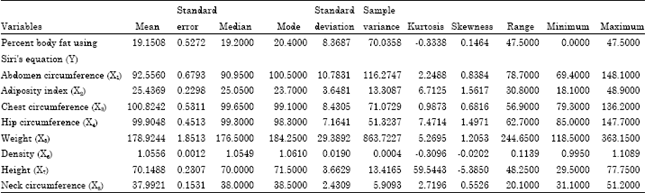 | |
| Table 3: | Correlation coefficient table for all 9 variables |
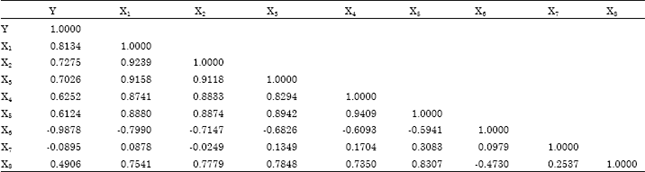 | |
Dummy transformation: Dummy variables are variables that take the values of 0 and 1 (Gujarati, 1999). Among the eight independent variables in Table 2, the latter three are transformed into dummy variables because density (X6) and height (X7) have negative skewness and among the other six independent variables which are highly correlated with dependent variable Y, neck circumference (X8) has the weakest correlation coefficient value. In addition, neck circumference can also used in identifying overweight and obese patients (Ben-Noun and Laor, 2006). Therefore, it is suitable to be selected as one of the variables for this study.
The transformation of independent variables into dummy variables can help to decrease the number of possible models in this study. This can be seen by using Eq. 1 and 2 if the three independent variables are not transformed into dummy variables, the number of independent variables are 8 and the number of possible models are 1024. However, if density, height and neck circumference are transformed into dummy variables, the number of possible models for 5 independent variables are 80 only.
After transformation, density (X6), height (X7) and neck circumference (X8) are represented by D, H and N, respectively. The mode for Density (D), Height (H) and neck circumference (N) is 1.061, 71.5 and 38.5, respectively. For those which are less than their respective modes are denoted as 0, while for those observations which are more than their respective modes are denoted as 1. For better understanding, partly of the data of dummy variables after transformation is presented in Table 4.
Procedures in getting the best model: After transformation, according to the model building procedures in Fig. 1, all of the possible models are listed out by using Eq. 1 and 2. Since, there are five single non-dummy independent variables in this study, thus the numbers of all possible models are 80. Then, the selected models can be obtained by carried out the multicollinearity test. For illustration purpose, model M53.0.0 is considered as follows:
| (4) |
However, due to limited space, model M53.12.0, which has eliminated 12 independent variables from the parent model is considered as follows:
| (5) |
Model M53.12.0. which has eliminated 12 independent variables from the parent model can be known from its model name, where 12 represents that 12 variables are eliminated in Phase 2.1 and zero shows that no variable is eliminated in Phase 2.2 from the parent model.
| Table 4: | Partly of the data of dummy variables after transformation |
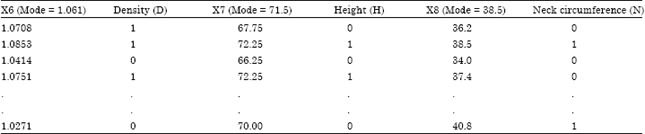 | |
For better understanding, the definition of model name is presented in Fig. 3. Besides that, the removal of multicollinearity source variables from model M53.12.0 is presented in Table 5.
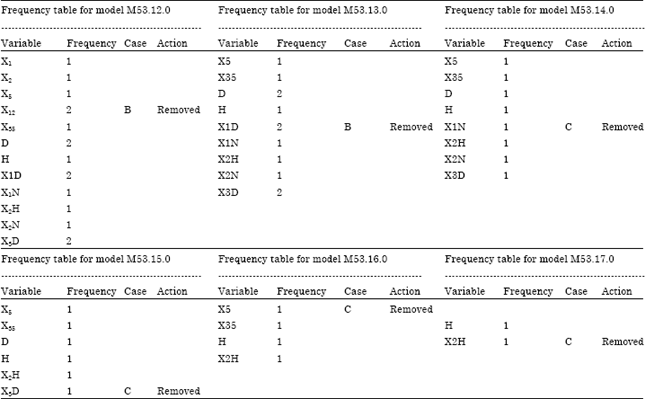
The frequency tables for several cases in removing the corresponding variable from model M53.12.0 until model M53.17.0 are shown in Table 6.
In Table 5, variable X12 is numbered as 13 because it is the 13-th variable removed from model M53.0.0. Model M53.12.0 belongs to Case B because there exists more than one tie, where variables X12, D, X1D and X3D has frequency of two respectively. Since variable X12 has the smallest absolute correlation coefficient with Y, which is 0.7505, so it is removed from model M53.12.0. Then, the analysis is rerun and a new model M53.13.0 is produced.
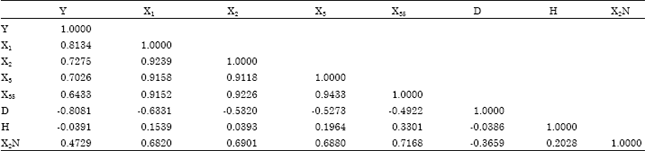
Besides that, for model M53.16.0, it belongs to Case C because there exists only one tie. This is due to variable X5, X35, H, X2H has frquency of one respectively. Then, the pair variables of X5 and X35 is considered first because it has a higher correlation coefficient than the pair variables of H and X2H, which are 0.9859. After that, X5 is removed from model M53.16.0 due to its smaller absolute correlation coefficient with Y than X35, which is 0.6124. Then, the analysis is rerun and a new model M53.17.0 is produced. The same removal steps are carried out on other multicollinearity source variables according to their types of cases. The way to count frequency and the removal steps based on related types of cases. Thus, after removal of 18 variables from model M53.0.0, the correlation coefficient table for variables in model M53.18.0 is shown in Table 7.
From Table 7, it can be observed that all of the absolute correlation coefficient values (excluded the diagonal values) are less than 0.95 and thus model M53.18.0 is said to be free from multicollinearity.
| Table 5: | Removal of multicollinearity source variables from Model M53.12.0 |
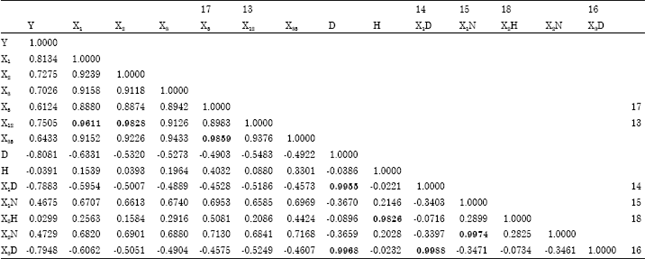 | |
| Bold values are cases which are in removing the corresponding variable from model | |
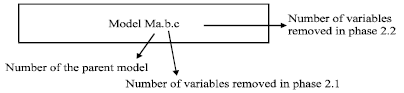 | |
| Fig. 3: | Definition of model name |
| Table 6: | Frequency tables from Model M53.12.0 until Model M53.17.0 |
 | |
| Table 7: | The correlation coefficient for variables in Model M53.18.0 |
 | |
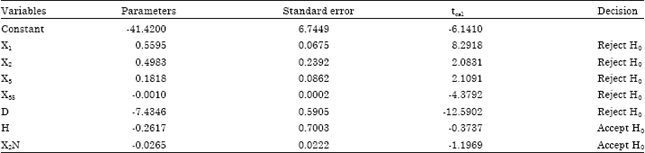
Then, according to Fig. 1, the coefficient test is carried out to remove insignificant variables from the models. Therefore, further analysis is taken on model M53.18.0, where Table 8 shows the tcal values for each variable in model M53.18.0.
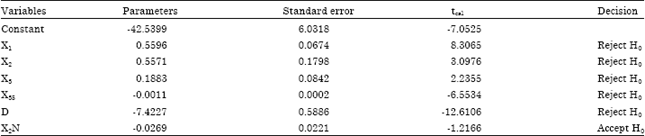
For the hypotheses of coefficient test for model M53.18.0, |tcritical| is t0.025, (252-7-1), which is 1.97. The decision is to accept the null hypothesis, where the |tcal| is smaller than |tcritical|, which shows that the corresponding variable of the specific coefficient has no contribution to the model. For M53.18.0, both of the corresponding variables of βH and β2N, H and X2N have |tcal| which are smaller than the |tcritical|, however only one variable is eliminated in each elimination step. Thus, only variable H is eliminated due to its |tcal| is nearer to zero than variable X2N. The analysis is rerun with the remaining variables and the new model is model M53.18.1. The resulting tcal values after eliminated variable H are shown in Table 9.
The |tcritical| is t0.025, (252-6-1), which is 1.97. The decision is to accept the null hypothesis, where the |tcal| is smaller than |tcritical|. Since only corresponding variables of β2N, X2N has |tcal| which is smaller than the |tcritical| and is nearest to zero, thus it is eliminated from model M53.18.1.
| Table 8: | The tcal values for each variable in model M53.18.0 |
 | |
| Table 9: | The tcal values for each variable in model M53.18.1 |
 | |
| Table 10: | The tcal values for each variable in model M53.18.2 |
 | |
The analysis is rerun with the remaining variables and the new model is model M53.18.2. The resulting tcal values after eliminated variable X2N are shown in Table 10.
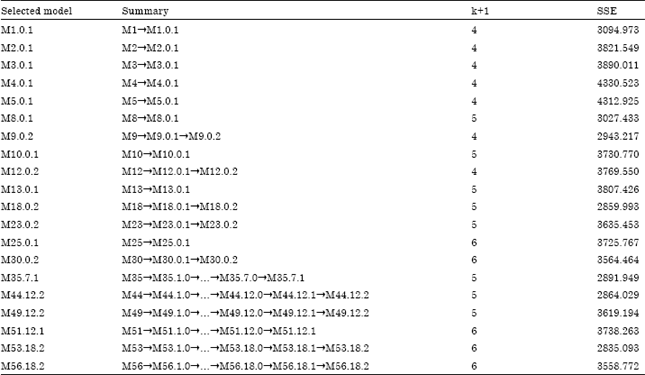
The |tcritical| is t0.025, (252-5-1), which is 1.97. Since, all of the variables have |tcal| that are greater than the |tcritical|, thus no variable is eliminated from model M53.18.2. Therefore, model M53.18.2 is said to be free from multicollinearity and insignificancy. Besides that, p-values can also used in eliminating insignificant variables, variables with the highest p-values and greater than 0.05 are eliminated from the model one by one. Similar procedures are carried out for other 79 possible models. Table 11 shows the summary for selected models.
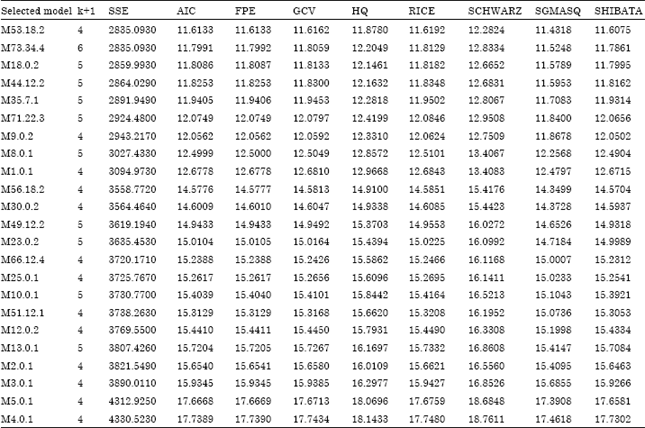
All the selected models in Table 11 have filtered out models with the same independent variables, where the first appeared name of the model is taken. For example, model M53.18.2 has the same independent variables with model M57.25.3, model M75.22.3 and model M80.40.4, thus model M53.18.2 is taken to carry out the analysis. Table 12 shows the corresponding selection criteria values for each selected models.
From Table 12, model M53.18.2 is found to be the best model because it has most of the minimum values among the others in 8SC. Model M53.18.2 can be written as in the equation as follow:
| (6) |
where, X1 represents the abdomen circumference, X2 is the adiposity index, X3 is the chest circumference, X35 is the first-order interaction variables of chest circumference and weight, D represents density and u is the residual.
| Table 11: | Summary for selected models |
 | |
| Table 12: | The corresponding selection criteria values for each selected models |
 | |
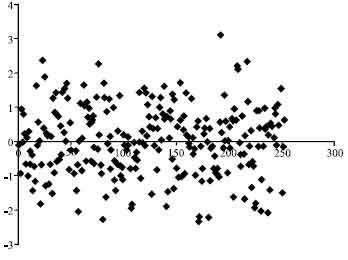 | |
| Fig. 4: | Scatter plot of standardized residual |
According to Fig. 1, after the best model is obtained, the goodness-of-fit is carried out on the residuals of the best model. In this case, the randomness test is carried out to verify the randomness of residuals. The hypothesis of randomness test is as follow:
| • | H0: The observations ui are random |
| • | H1: The observations ui are not random |
where, I = 1, 2,…, 252
The null hypothesis is accepted if |Tn| is less than |tcritical|, where |tcritical| = tα, n-k-1. The calculation of Tn and the result is Tn equals to -0.0013, where k equals to 5 as can be seen in Eq. 6 that there are five independent variables in the best model. From the t-distribution table, at α = 0.05, |tcritical| = 1.65. Since |Tn| = 0.0013 is less than |tcritical|, the null hypothesis is accepted and the residuals ui are randomly distributed. Besides that, the scatter plot for the standardized residual in Fig. 4 also shows that the residuals are randomly distributed because no obvious pattern is observed.
Then, the normality test is also carried out to test the normality of the residuals in the best model. In this study, Kolmogorov-Smirnov is used to test normality since the number of observations are large, which are 252 men.
The hypothesis of normality test is shown as follow:
| • | H0: The standardized residual is normally distributed |
| • | H1: The standardized residual is not normally distributed |
The decision is that the null hypothesis is rejected if the p-value is less than 0.05. Table 13 shows the SPSS output of the Kolmogorov-Smirnov Test on the standardized residual.
Since the p-value in Table 13 is 0.2000, which is greater than 0.05, thus the null hypothesis is accepted and residuals are said to be normally distributed. Besides that, the bell-shaped histogram of standardized residual in Fig. 5 also shows that the residuals are normally distributed.
| Table 13: | Kolmogorov-smirnov test on standardized residual |
 | |
| Table 14: | The final coefficient values of model M53.18.2 |
 | |
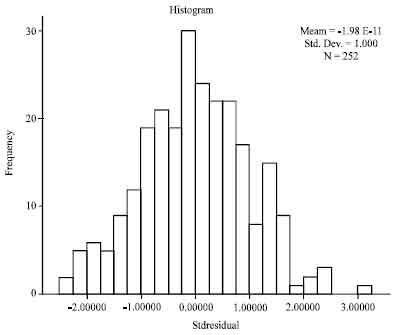 | |
| Fig. 5: | Histogram of standardized residual |
Therefore, the residuals of the best model are said to be random and normally distributed.
DISCUSSION
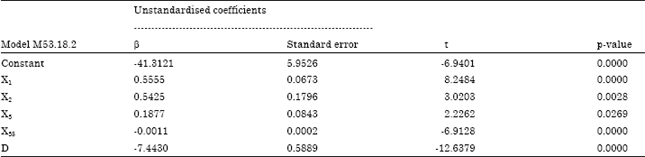
This study showed that model M53.18.2 is the best model, where the equation is shown as in Eq. 6 to represent the factors that affect the percentage of body fat in men. Table 14 shows the final coefficient values of model M53.18.2.
As can be seen from Table 14, the positive coefficient values show that the percentage of body fat in men by using the Siri’s equation (Y) will increase if the corresponding variables increase, while the negative coefficient values show that the percentage of body fat in men (Y) will decrease if the corresponding variables decrease. Thus, the increment in abdomen circumference (X1), adiposity index (X2) and chest circumference (X3) will cause increment on percentage of body fat by Siri’s equation (Y) in men. However, the increment in Density (D) and first-order interaction variables of chest circumference and weight (X35) will cause decrement on percentage of body fat by the Siri’s equation (Y) in men. This increment in Density (D) is found to bring the most decrement or influence (β = -7.4430) but a very minor change (β = -1.1x10-3) on the percentage of body fat in men.
CONCLUSION
As a conclusion, the body density is found to be the main factor that contributed negatively in estimating the percentage of body fat in men, followed by the positive relationships of the other main factors, namely, the abdomen circumference, adiposity index and chest circumference. The interaction variable between the chest and the body weight only caused a very minor negative effect on the percentage of body fat. It is also suggested that further analysis can be carried out by including the Brozek’s equation, which is also used in estimating percentage of body fat in human. Comparisons can then be made on the efficiency of both the Siri’s equation and Brozek’s equation in estimating the percentage of body fat.
REFERENCES
- Akaike, H., 1969. Fitting autoregressive models for prediction. Ann. Inst. Stat. Math., 21: 243-247.
CrossRefDirect Link - Akaike, H., 1974. A new look at the statistical model identification. IEEE Trans. Autom. Control, 19: 716-723.
CrossRefDirect Link - Ben-Noun, L. and A. Laor, 2006. Relationship between changes in neck circumference and cardiovascular risk factors. Exp. Clin. Cardiol., 11: 14-20.
Direct Link - Bin Mohd, I., S.C. Ningsih and Y. Dasril, 2007. Unimodality test for global optimization of single variable functions using statistical methods. Malaysian J. Math. Sci., 1: 205-215.
Direct Link - Bosy-Westphal, A., S. Danielzik, C. Becker, C. Geisler and S. Onur et al., 2005. Need for optimal body composition data analysis using air-displacement plethysmography in children and adolescents. J. Nutr., 135: 2257-2262.
Direct Link - Camminatiello, I. and A. Lucademo, 2010. Estimating multinomial logit model with multicollinear data. Asian J. Math. Stat., 3: 93-101.
CrossRefDirect Link - Golub, G.H., M. Heath and G. Wahba, 1979. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics, 21: 215-223.
Direct Link - Hannan, E.J. and B.G. Quinn, 1979. The determination of the order of an autoregression. J. R. Stat. Soc. Ser. B: (Methodol.), 41: 190-195.
CrossRefDirect Link - Johnson, R.W., 1996. Fitting percentage of body fat to simple body measurements. J. Stat. Educ., Vol. 4, No. 1.
Direct Link - Matiya, G., Y. Wakabayashi and N. Takenouchi, 2005. Factors influencing the prices of fish in central region of malawi and its implications on the development of aquaculture in malawi. J. Applied Sci., 5: 1424-1429.
CrossRefDirect Link - Midi, H., A. Bagheri and A.H.M.R. Imon, 2010. The application of robust multicollinearity diagnostic method based on robust coefficient determination to a non-collinear data. J. Applied Sci., 10: 611-619.
CrossRef - Midi, H., S. Rana and A.H.M.R. Imon, 2009. Estimation of parameters in heteroscedastic multiple regression model using leverage based near-neighbors. J. Applied Sci., 9: 4013-4019.
CrossRefDirect Link - Abd El-Salam, M.E.F., 2011. An efficient estimation procedure for determining ridge regression parameter. Asian J. Math. Stat., 4: 90-97.
CrossRefDirect Link - Oluwadare, G.O. and P.O. Atanda, 2007. Effect of processing parameters on the microstructures and properties of automobile brake drum, J. Applied Sci., 7: 2468-2473.
CrossRefDirect Link - Rice, J., 1984. Bandwidth choice for nonparametric regression. Ann. Stat., 12: 1215-1230.
Direct Link - Shibata, R., 1981. An optimal selection of regression variables. Biometrika, 68: 45-54.
ASCIDirect Link - Zainodin, H.J. and G. Khuneswari, 2009. A case study on determination of house selling price model using multiple regression. Malaysian J. Math. Sci., 3: 27-44.
Direct Link