
J.N. Nmadu
Department of Agricultural Economics and Extension Technology, Federal University of Technology, Minna, Nigeria
E.S. Yisa
Department of Agricultural Economics and Extension Technology, Federal University of Technology, Minna, Nigeria
U.S. Mohammed
Department of Agricultural Economics and Extension Technology, Federal University of Technology, Minna, Nigeria
Trends in Agricultural Economics
Year: 2009 | Volume: 2 | Issue: 1 | Page No.: 17-27







ABSTRACT
The possibility of the type of spline function and joint points selected affecting the consistency of the ex-post and ex-ante forecasts were tested using cereal production (1961-2006) and percent contribution of agriculture to GDP (1961-2004) in Nigeria. Three types of model, that is, Linear-Quadratic-Linear, Quadratic-Quadratic-Linear and Linear-Quadratic-Quadratic, were used. The result indicated that there is no universality as to which model is appropriate, rather all possible models should be tried and the one that gives most consistent result when compared to observed data and other factors should be used.
PDF Abstract XML References Citation
How to cite this article
J.N. Nmadu, E.S. Yisa and U.S. Mohammed, 2009. Spline Functions: Assessing their Forecasting Consistency with Changes in the Type of Model and Choice of Joint Points. Trends in Agricultural Economics, 2: 17-27.
DOI: 10.3923/tae.2009.17.27
URL: https://scialert.net/abstract/?doi=tae.2009.17.27
DOI: 10.3923/tae.2009.17.27
URL: https://scialert.net/abstract/?doi=tae.2009.17.27
INTRODUCTION
Since, Fuller (1969) introduced the concept of spline or grafted polynomial, many researchers have utilized it to make ex-post and ex-ante forecast of economic time series data beyond the estimation period. Such studies include those by Phillip (1990), Rahman and Damisa (1999), Nmadu and Amos (2002), Nmadu and Phillp (2001) and Nmadu et al. (2004). For example Bormann et al. (2002) estimated lactation stage, age at milking, previous days open and days pregnant using quadratic polynomials by fitting joint points. Meyer (2005) successfully modeled growth of Australian Angus cattle using the spline function. Some other researchers have made innovations to the original model. Those include Fox and Grafton (2000), Parsons and Hunt (1981) and Marsh (1986). Fox and Grafton (2000) used capital and model selection criteria rather than trend to determine appropriate break points.
The concept is based on the visual examination of the scatter diagram of the available data series against trend in order to divide the data into sub-periods and to suggest suitable joint points to capture all the sub-periods into a single model (Fuller, 1969; Phillip, 1990; Meyer, 2005; Pierre et al., 1987). Since, the eventual model estimated is subject to the visual examination of the base data by the researcher, it therefore means that the appropriateness of the eventual estimated function and the forecast based on it is accurate to the extent of the accuracy of the researcher`s visualization. In this circumstance, the same data can be modeled along different lines depending on the researcher. Hence, there is need to find out if the quality of the model resulting from this modeling is affected by the type of function and other factors. The main objective of this study is to investigate whether the choice of joint points in a spline function and the type of model selected affects the forecasting ability of the resulting estimated coefficients.
MATERIALS AND METHODS
The data used in this research were mainly secondary data sourced from Earth Trend (2006). The data included cereal grains production in Nigeria in metric tones between 1961 and 2005, percent agriculture contribution to Nigerian GDP between 1965 and 2004 and aggregate fertilizer consumption by Nigerian farmers in metric tones between 1961 and 2001.
Normally, the available data is plotted against trend in order to divide the series into segments based on visual examination. Traditionally, the data is usually divided into three sub-periods and no attempt was made in this study to go beyond that.
There are two commonly used models, that is, Linear-Quadratic-Linear and Quadratic-Quadratic-Linear models. These two are preferred because it is normal to have linear portion as the terminal (Fuller, 1969; Phillip, 1990) as that enhances forecasting which is the main objective of using the system. However, an attempt was made to explore all possible models in order to show if the eventual model is acceptable for forecasting. Therefore, Linear-Quadratic-Quadratic, Linear-Linear-Quadratic, Linear-Linear-Linear and Quadratic-Quadratic-Quadratic models were tried. Linear-Linear-Quadratic was dropped because some of the coefficients were over-identified while Linear-Linear-Linear was dropped because the variables were over-identified and any of the linear regression models can be applied to a data series that is linear over the entire trend and there will be no need to divide it into sub-periods. In the case of Quadratic-Quadratic-Quadratic, the model was dropped because the variables were over-identified and the data series with this type of behavior is better estimated with higher polynomial instead of dividing into sub-periods.
The details of the models and the mean equation are shown below for the three models left. The detail of how the mean equations were obtained is shown for one of the models in Appendix.
Linear Quadratic Linear
A graphical examination of the data may show that it can be divided into three segments; hence the following trend function was suggested:
| (1) |
| (2) |
| (3) |
| Where: |
| Yt | = | Data series in year t |
| t | = | Trend |
| α's, β's and φ | = | Structural parameters to be estimated |
| JP1 and JP2 | = | Joint point 1 and 2, respectively |
Equation 1-3 are then reworked as shown below:
| (4) |
| (5) |
| (6) |
Equation 4-6, are then formed into a single equation for estimation as follows:
| (7) |
| Where: |
| Zo | = | |
| Z1 | = | |
| Z2 | = | |
| = | ||
| = | ||
| Ut | = | Error term assumed to be well behaved |
Quadratic Quadratic Linear
A graphical examination of a data series may reveal that it can be divided into different segments as the trend equation below:
| (8) |
| (9) |
| (10) |
| Where: |
| Qt | = | Data series in year t |
| t | = | Trend |
| α's, β's and φ | = | Structural parameters to be estimated |
| JP1 and JP2 | = | Joint point 1 and 2, respectively |
Equation 8-10 are then reworked as shown below:
| (11) |
| (12) |
| (13) |
Equation 11-13, are then formed into a single equation for estimation as follows:
| (14) |
| Where: |
| Zo | = | |
| Z1 | = | |
| Z2 | = | |
| = | ||
| = | ||
| Z3 | = | |
| = | ||
| = | ||
| μ's | = | Structural parameters to be estimated |
| Ut | = | Error term assumed to be well behaved |
Linear Quadratic Quadratic
A graphical examination of a data series may reveal that it can be divided into different segments as the trend equation below:
| (15) |
| (16) |
| (17) |
| Where: |
| GDt | = | Data series in year t |
| t | = | Trend |
| α's, β's and φ | = | Structural parameters to be estimated |
| JP1 and JP2 | = | Joint point 1 and 2, respectively |
Equation 15-17, are then reworked as shown below:
| (18) |
| (19) |
| (20) |
Equation 18-20 are then formed into a single equation for estimation as follows:
| (21) |
| Where: |
| Zo | = | |
| Z1 | = | |
| Z2 | = | |
| = | ||
| = | ||
| Z3 | = | |
| = | ||
| = | ||
| Z4 | = | |
| = | ||
| = | ||
| μ's | = | Structural parameters to be estimated |
| Ut | = | Error term assumed to be well behaved |
Equations 7, 14 and 21 are the mean equations; they are continuous with the various restrictions relating to each model.
The three final equations were applied to cereal grains production in Nigeria in metric tones between 1961 and 2005 and percent agriculture contribution to Nigerian GDP between 1965 and 2004. In addition, the models were applied to cereal grains production when either GDP or aggregate fertilizer consumption by Nigerian farmers in metric tones between 1961 and 2001 or both are added as explanatory variables. Ex-post forecast of the trend was then made for estimation period while ex-ante forecast was made to year 2020 and the forecasts compared with the observed data. The data were obtained from EarthTrend (2006). After the estimation of the models, the forecasting ability of each of them was assessed using Mean Square Error (MSE). MSE is given as:
| Where: |
| MSE | = | Mean Square Error |
| Yt | = | Observed value |
| yt | = | Estimated value |
| n | = | Sample size |
The model with the least MSE is adjudged better than the other.
RESULTS AND DISCUSSION
The estimates of the various explanatory variables using the different models are presented in Table 1-3 while the ex-post and ex-ante estimates of the data series are shows in Fig. 1-4. Table 4 gives the MSE for all the models.
The result in Table 1 (Linear-Quadratic-Linear) shows that all variables are significant in the trend of cereal grains production during the period under study and the estimates of the coefficients of GDP or fertilizer or both were not significant as explanatory variables in the trend of cereal production. Table 1 also shows that the trend of GDP was not well explained by the variables included in the model. The result in Table 2 (Quadratic-Quadratic-Linear) shows that all the variables were significant in the trend of cereal production and GDP but the estimates of the coefficients of GDP was not a significant explanatory variable in cereal production.
| Table 1: | Estimates of the coefficient for Linear Quadratic Linear model |
 | |
| (1) JP1 = 1965, JP2 = 1987; (2) JP1 = 1980, JP2 = 1988; Values in parenthesis are SE; *p<0.10; **p<0.05; ***p<0.01, ns: Not significant | |
| Table 2: | Estimates of the coefficient for the Quadratic Quadratic Linear model |
 | |
| (1) JP1 = 1973, JP2 = 1987; (2) JP1 = 1988, JP2 = 1998; Values in parenthesis are SE; *p<0.10; **p<0.05; ***p<0.01; ns: Not significant | |
| Table 3: | Estimates of the coefficient for the Linear Quadratic Quadratic model |
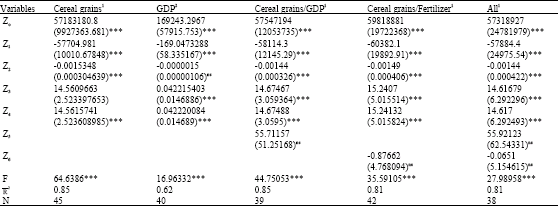 | |
| (1) JP1 = 1965, JP2 = 1987; 2: JP1 = 1980, JP2 = 1992; Values in parenthesis are SE; *p<0.10; **p<0.05; ***p<0.01; ns: Not significant | |
| Table 4: | Estimates of MSE for all the models |
 | |
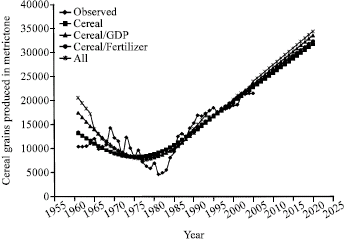 | |
| Fig. 1: | Ex-post and ex-ante forecast of cereal grains using the Linear Quadratic Linear model |
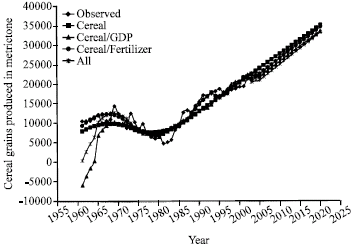 | |
| Fig. 2: | Ex-post and ex-ante forecast of cereal grains using the Quadratic Quadratic Linear model |
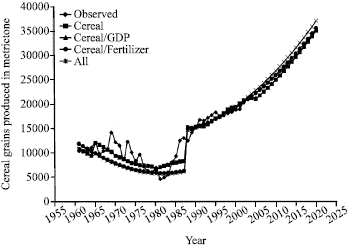 | |
| Fig. 3: | Ex-post and ex-ante forecast of cereal grains using the Linear Quadratic Quadratic model |
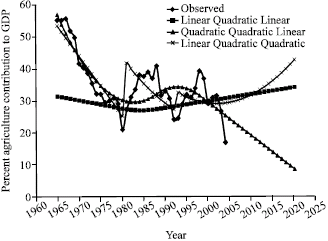 | |
| Fig. 4: | Ex-post and ex-ante forecast of per cent contribution of agriculture to GDP using various models |
The results shown in Table 3 indicate that the variables of the Linear-Quadratic-Quadratic model captured the trend in cereal production and GDP significantly. However, the estimates of the coefficient of GDP and fertilizer when added as explanatory variables are not significant in explaining the trend in cereal grains production. The non-significance of added explanatory variables in the trend equation is quite contrary to what Nmadu and Phillip (2001) and Nmadu et al. (2004) found in the case of sorghum. The result would seem to indicate that there is universality as to the appropriateness of the grafted model used. But that is sharply contrasted with the result of the ex-post and ex-ante forecast shown in Fig. 1-4, respectively. It would be noticed that similar results were obtained with models that have linear terminal but the result with Quadratic terminal is kinked at the joint points which is against one of the major requirement of the spline system (Fuller, 1969; Philip, 1990) even though the ex-ante forecast from the model compares favourably with the other models for cereal grains production and also compares favourably with results obtained from other series (Rahman and Damisa, 1999; Nmadu and Amos, 2002; Nmadu and Philip, 2001; Nmadu et al., 2004). The ex-post and ex-ante forecast for the GDP from the three models show some interesting results. While the Linear-Quadratic-Linear model show a slow upward trend, the Quadratic-Quadratic-Linear show a sliding trend and Linear-Quadratic-Quadratic show a rapid upward trend. However, the forecast from the Quadratic-Quadratic-Linear is most consistent with the observed trend. Given such scenario, it would seem that the choice of the spline model to use is not based solely on visual examination, but it will also depend on the nature of data series involved and the use to which the forecast would be put. While any of the models could be cautiously used for cereal grains production forecasting, other factors would have to be considered in choosing a model for forecasting GDP. In that regard, it is advised that all possible spline models should be tried and the one that gives best result should be utilized for further studies. For example, the result of the MSE in Table 4 shows that the best model is not uniform across. Different models may be recommended if type of spline system or number of explanatory variables in the various systems is considered. While QQL seams to be a better model with GDP and Cereal based splines; with regard to number of number of variables, the choice is a mixed bag. Changing of joint points has not shown any significant effect of the output of the models.
CONCLUSION
The effect of changing joint points and the type of spline function was investigated in this research. The result obtained show that the there was no universality as to the effect of the model and joint points chosen. Therefore, attempts should be made to model the data series with as many models as possible. The choice of the most acceptable should be based on the conformity of the ex-post and ex-ante forecasts to the observed data and economic sense.
APPENDIX
Full Details of the Grafting of Linear Quadratic Quadratic Model
A graphical examination of a data series may reveal that it can be divided into different segments as the trend equation below:
| (1) |
| (2) |
| (3) |
| Where: |
| GDt | = | Data series in year t |
| t | = | Trend |
| α's, β's and φ | = | Structural parameters to be estimated |
| JP1 and JP2 | = | Joint point 1 and 2, respectively |
The restrictions (Fuller, 1969) on the Eq. 1-3 are:
| αo + βoK1=α1 + β1K1 + φ1K12( | (4) |
| α1 + β1K2 + φ1K22 = α2 + β2 K2 + φ2K22 | (5) |
| βo = β1 + 2φ1 K1 | (6) |
| β1 + 2φ1k2 = β2 + 2φ2k2 | (7) |
From Eq. 1-3, there are eight parameters with four restrictions as shown in Eq. 4-7, therefore, four parameters were estimated. We retain the terminal parameters being the most recent, hence α2, β2, φ2 and φ2-φ1 were estimated while α1 , β1 , αo and βo were dropped. φ2-φ1 was estimated in order to study the transition from one phase to another in the data series. Equation 4-7 are now redefined in favour of the dropped parameters viz.:
By inspecting Eq. 4-7, it is obvious that it is better to start from Eq. 7, respectively because they have only one term, which we intend to drop i.e.,
(D1) β1 = β2 + 2φ2k2 - 2φ1k2 = β2 + 2k2(φ2-φ1) |
From Eq. 6, substituting (D1), we obtain
(D2) βo = β2 + 2K2(φ2-φ1) + 2φ1K2 |
We now estimate α1 from Eq. 5 substituting (D1) i.e.,
α1 = α2 + β2 K2 + φ2K22 - K2 {β2 + 2φ2k2 - 2φ1k2 = β2 + 2k2(φ2 - φ1)} - φ1K22 |
(D3) α1 = α2 - K22 (φ2 - φ1) |
Finally we estimate αo by making use of (D1), (D2) and (D3)
αo = α1 + K1 {β2 + 2φ2k2 - 2φ1k2 = β2 + 2k2(φ2 - φ1)} + φ1K12 - K1 { β2 + 2K2(φ2-φ1) + 2φ1K2} |
(D4) αo = α2 - K22 (φ2 - φ1)- K12φ1 |
| αo=α2 - K22 (φ2 - φ1)- K12φ1 | (8) |
| βo=β2 + 2K2(φ2-φ1) + 2φ1K2 | (9) |
| α1=α2 - K22 (φ2 - φ1) | (10) |
| β1=β2 + 2φ2k2 - 2φ1k2 = β2 + 2k2(φ2 - φ1) | (11) |
The mean equation can now be obtained by substituting α1 , β1 , αo and βo in Eq. 1-3. From Eq. 1, substituting for αo and βo
| Gdt = α2-K22 (φ2-φ1)- K12φ1 + t{ β2 + 2K2(φ2-φ1) + 2φ1K2} |
| (E1)GDt = α2 + β2 t + (2K2t - K22) (φ2- φ1) (2K1t - K12) φ1, t <= K1 |
From Eq. 2, substituting for α1 and β1,
| GDt= α2 - K22 (φ2 - φ1 + t{β2 + 2k2(φ2 - φ1)} + φ2t2 |
| (E2)GDt = α2 + β2 t + (2K2t - K22) (φ2- φ1)+ φ2t2 , K1< t ≤ K2 |
From Eq. 3, all coefficients were retained for forecasting purposes.
| (E3)GDt = α2 + β2t + φ2t2, t>K2 |
The grafted Eq. 12-14, are then formed by inspection of (E1), (E2) and (E3) above. The mean equation is continuous on the data set:
| (12) |
| (13) |
| (14) |
Equation 12-14, are then formed into a single equation for estimation as follows:
| GDt=μoZo + μ1Z1 + μ2Z2 + μ3Z3 + μ3Z3+ μ4Z4+ Ut | (15) |
| Where: |
| Zo | = | |
| Z1 | = | |
| Z2 | = | |
| = | ||
| = | ||
| Z3 | = | |
| = | ||
| = | ||
| Z4 | = | |
| = | ||
| = | ||
| μ's | = | Structural parameters to be estimated |
| Ut | = | Error term assumed to be well behaved |
REFERENCES
- Bormann, J., G.R. Wiggans, T. Druet and N. Gengler, 2002. Estimating effects of permanent environment, lactation stage, age and pregnancy on test-day yield. J. Dairy Sci., 85: 263-263.
Direct Link - Fox, K.J. and R.Q. Grafton, 2000. Nonparametric estimation of returns to scale: Method and application. Can. J. Agric. Econ., 48: 341-354.
CrossRef - Fuller, W.A., 1969. Grafted polynomials as approximating functions. Aust. J. Agric. Econ., 13: 35-46.
Direct Link - Meyer, K., 2005. Random regression analyses using β-splines to model growth of Australian angus cattle. Genet. Sel. Evol., 37: 473-500.
CrossRef - Nmadu, J.N. and D.O.A. Phillip, 2001. Forecasting the yield of sorghum in Nigeria using alternative forecasting models. Nig. Agric. J., 32: 52-64.
CrossRefDirect Link - Parsons, I.T. and R. Hunt, 1981. Plant growth analysis: A program for the fitting of lengthy series of data by the method of β-splines. Ann. Bot., 48: 341-352.
Direct Link - Pierre, N.R., C.S. Thraen and W.R. Harvey, 1987. Minimum cost nutrient requirements from a growth response function. J. Anim. Sci., 64: 312-327.
Direct Link